1. 논문 주제
- Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
2. 핵심 포인트
-
Pre-trained representations : 기계 학습에서 흔히 사용되는 개념입니다. 이는 일반적으로 대규모 데이터셋에서 사전에 학습된 모델의 가중치입니다. 이러한 모델은 일반적으로 대규모 자연어 처리 (NLP) 작업이나 컴퓨터 비전과 같은 작업을 수행하는 데 사용됩니다.
-
explicit class labels such as ImageNet or OpenImages : "Explicit class labels"는 이미지 분류나 객체 검출과 같은 작업에서 사용되는 레이블을 의미합니다. 이 레이블은 주로 이미지에 대한 카테고리 또는 클래스를 나타냅니다. 예를 들어, ImageNet은 유명한 이미지 데이터셋 중 하나로, 수백만 장의 이미지를 1,000개 이상의 다양한 클래스로 분류한 것입니다. 각 이미지는 해당하는 클래스 레이블로 레이블링되어 있습니다. 이러한 레이블은 각 이미지가 어떤 카테고리에 속하는지를 나타냅니다. OpenImages 역시 비슷한 방식으로 작동합니다. 이 데이터셋은 수백만 장의 이미지를 수천 개의 클래스로 분류하여 레이블링한 것입니다. 이러한 데이터셋을 사용하여 모델을 학습하고, 새로운 이미지에 대한 클래스 레이블을 예측할 수 있습니다.
-
The aligned visual and language representations : 시각적인 정보와 언어적인 정보를 함께 표현하는 방법을 의미합니다. 이러한 표현을 구축하고 사용함으로써, 이미지와 텍스트 간의 관계를 이해하고 다양한 작업을 수행할 수 있습니다. 복잡한 텍스트 및 텍스트+이미지 쿼리를 사용한 교차 모달 검색을 가능하게 합니다.
-
human annotation : 사람이 데이터셋을 만들거나 정제하는 과정에서 직접적으로 개입하는 것을 의미합니다. 이는 데이터의 품질을 향상시키고 모델의 성능을 향상시키는 데 중요한 역할을 합니다. 복잡한 모델을 훈련시키기 위해서는 정확하고 일관된 데이터가 필요합니다. 따라서 훈련 데이터의 품질을 보장하는 데 중요한 역할을 합니다.
-
Contrastive Learning : 특히, 이 방법은 유사한 데이터 포인트는 서로 가깝게, 서로 다른 데이터 포인트는 멀게 배치하여 데이터 표현을 학습합니다. 이를 통해 모델은 유사한 데이터 간의 상관 관계를 강화하고, 다른 데이터 간의 차이를 구별하는 법을 배우게 됩니다. 대비 학습의 핵심 아이디어는 두 개의 입력을 사용하여 학습합니다. 하나는 '양성 쌍(positive pair)'으로 레이블링되며, 이는 서로 유사한 샘플을 나타냅니다. 다른 하나는 '음성 샘플(negative sample)'이며, 이는 서로 다른 샘플을 나타냅니다. 모델은 양성 쌍을 더 가깝게, 음성 샘플을 더 멀게 배치함으로써 데이터 표현을 학습합니다. 대비 학습은 시각적인 표현 학습에서 많이 사용되며, 특히 이미지나 텍스트와 같은 데이터에서 유용합니다. 예를 들어, 이미지 데이터에서는 비슷한 이미지가 서로 가깝게, 서로 다른 이미지가 멀게 배치하여 이미지 특징을 학습할 수 있습니다. 이러한 방법은 사전 학습된 모델을 초기화하는 데 사용될 수 있거나, 특정 작업에 대한 표현을 fine-tuning하는 데 사용될 수 있습니다. 최근에는 대비 학습이 자연어 처리와 같은 다른 영역에도 적용되고 있습니다.
-
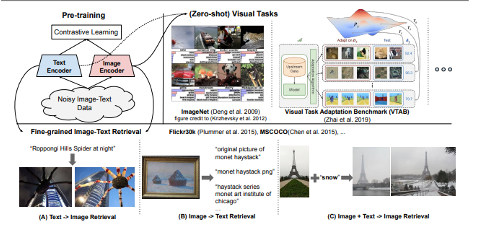
Without any fine-tuning, ALIGN powers zero-shot visual classification and cross-modal search including image-to-text search, text-to-image search and even search with joint image+text queries. : ALIGN은 시각과 언어 정보를 공유된 잠재 공간에 매핑함으로써 시각과 언어 간의 상호작용을 모델링합니다. 이를 통해 이미지와 텍스트 간의 유사성을 측정하고, 다양한 검색 작업에 활용할 수 있습니다. 이러한 표현은 세밀한 조정 없이도 다양한 시각-언어 작업에 효과적으로 적용될 수 있습니다.
-
visual-semantic embeddings : 이미지와 해당 이미지에 대한 설명 또는 캡션을 함께 임베딩하여, 이미지와 텍스트 간의 유사성을 측정할 수 있습니다. 이를 통해 이미지 검색, 이미지 캡션 생성, 이미지 분류 등 다양한 작업을 수행할 수 있습니다. 이러한 모델은 이미지와 텍스트를 입력으로 받아 공통된 잠재 공간에 매핑합니다. 이를 위해 시각적 특징 추출기와 자연어 처리 모델이 함께 사용될 수 있습니다.
-
A Large-scale ImaGe and Noisy-text embedding ⇒ Align : 주어진 이미지와 해당 이미지에 대한 텍스트 설명 또는 캡션과 같은 텍스트 데이터를 함께 사용하여, 이미지와 텍스트 간의 상호작용을 모델링하고 이를 공통된 잠재 공간에 매핑합니다.
-
Leveraging images and natural language captions is another direction of learning visual representations. : 일반적으로, 이미지와 자연어 캡션은 서로 보완적인 정보를 제공합니다. 이미지는 시각적인 정보를 담고 있으며, 캡션은 이미지에 대한 의미적인 설명을 제공합니다. 이러한 정보를 함께 사용하여 시각적 표현을 학습하면, 모델은 이미지와 텍스트 간의 상호작용을 이해하고 이미지와 텍스트 간의 유사성을 측정할 수 있습니다.
-
advanced models emerge with cross-modal attention layers : 교차 모달 어텐션 레이어는 다양한 모달리티(예: 이미지, 텍스트) 간의 상호작용을 모델링하기 위한 레이어입니다. 이 레이어는 이미지와 텍스트와 같은 서로 다른 모달리티 간의 유사성을 측정하고 상호작용을 효과적으로 처리할 수 있습니다.
-
they are orders of magnitudes slower and hence impractical for image-text retrieval systems in the real world. : 이러한 고급 모델은 일반적으로 실행이 느리기 때문에 실제 세계의 이미지-텍스트 검색 시스템에서는 실용적이지 않을 수 있습니다.
-
Closely related to our work is CLIP (Radford et al., 2021), which proposes visual representation learning via natural language supervision in a similar contrastive learning setting : ALIGN과 밀접한 관련이 있는 CLIP(Radford et al., 2021)은 비슷한 대조적 학습 설정에서 자연어 지도를 통한 시각적 표현 학습을 제안합니다. 두 방법 모두 이미지와 텍스트 간의 상호작용을 모델링하여 시각적 표현을 학습하려고 합니다.
-
One advantage of ALIGN is that the model is trained on
noisy web image text data with very simple filters, and none
of the filters are language specific. Given that, we further lift
the language constraint of the conceptual caption data processing pipeline to extend the dataset to multilingual (covering 100+ languages) and match its size to the English dataset
(1.8B image-text pairs). : ALIGN의 장점 중 하나는 모델이 매우 간단한 필터를 사용하여 잡음이 많은 웹 이미지 텍스트 데이터로 훈련되었으며, 이 필터들은 모두 언어 특정적이지 않다는 것입니다. 이를 고려하여, 우리는 개념적 캡션 데이터 처리 파이프라인의 언어 제약을 해제하여 데이터셋을 다국어로 확장하고(100개 이상의 언어 포함), 영어 데이터셋의 크기(18억개의 이미지-텍스트 쌍)와 일치시켰습니다.
3. 수식

4. 궁금한 사항들
- 핵심 로직과 그에 따른 코드 설계 방식에 대한 궁금증
- 이 주제를 활용해서 다국어 텍스트와 이미지를 매칭하는 것에 대한 가능성
