1. 논문 주제
- CLIP: Connecting text and images
2. 핵심 포인트
-
a neural network called CLIP (Contrastive Language–Image Pre-training) : CLIP(대조적 언어-이미지 사전 훈련)는 단순히 인식하려는 시각적 카테고리의 이름을 제공함으로써 다양한 시각 분류 작업에 적용할 수 있습니다. 이는 CLIP이 "제로 샷(zero-shot)"이나 심지어 "퓨 샷(few-shot)" 학습을 수행할 수 있도록 하여, 명시적으로 훈련되지 않은 객체나 개념을 인식하는 데 도움이 됩니다. 이 유연성은 CLIP의 주요 장점 중 하나로, 다양한 도메인에서 다양한 시각적 이해 작업에 뛰어난 성능을 발휘할 수 있습니다.
-
CLIP models can then be applied to nearly arbitrary visual classification tasks. For instance, if the task of a dataset is classifying photos of dogs vs cats we check for each image whether a CLIP model predicts the text description “a photo of a dog” or “a photo of a cat” is more likely to be paired with it. : 결과적으로 CLIP 모델은 거의 임의의 시각 분류 작업에 적용될 수 있습니다. 예를 들어, 데이터셋의 작업이 강아지와 고양이의 사진을 분류하는 것이라면, 각 이미지에 대해 CLIP 모델이 "강아지의 사진" 또는 "고양이의 사진"이라는 텍스트 설명이 더 연결될 가능성이 있는지를 확인합니다.
-
CLIP pre-trains an image encoder and a text encoder to predict which images were paired with which texts in our dataset. We then use this behavior to turn CLIP into a zero-shot classifier. We convert all of a dataset’s classes into captions such as “a photo of a dog” and predict the class of the caption CLIP estimates best pairs with a given image. : CLIP은 이미지 인코더와 텍스트 인코더를 사전 훈련하여 데이터셋에서 어떤 이미지가 어떤 텍스트와 연결되었는지를 예측합니다. 그런 다음 이 동작을 사용하여 CLIP를 제로 샷 분류기로 변환합니다. 데이터셋의 모든 클래스를 "개의 사진"과 같은 캡션으로 변환하고, CLIP가 주어진 이미지와 가장 잘 연결될 것으로 추정하는 캡션의 클래스를 예측합니다.
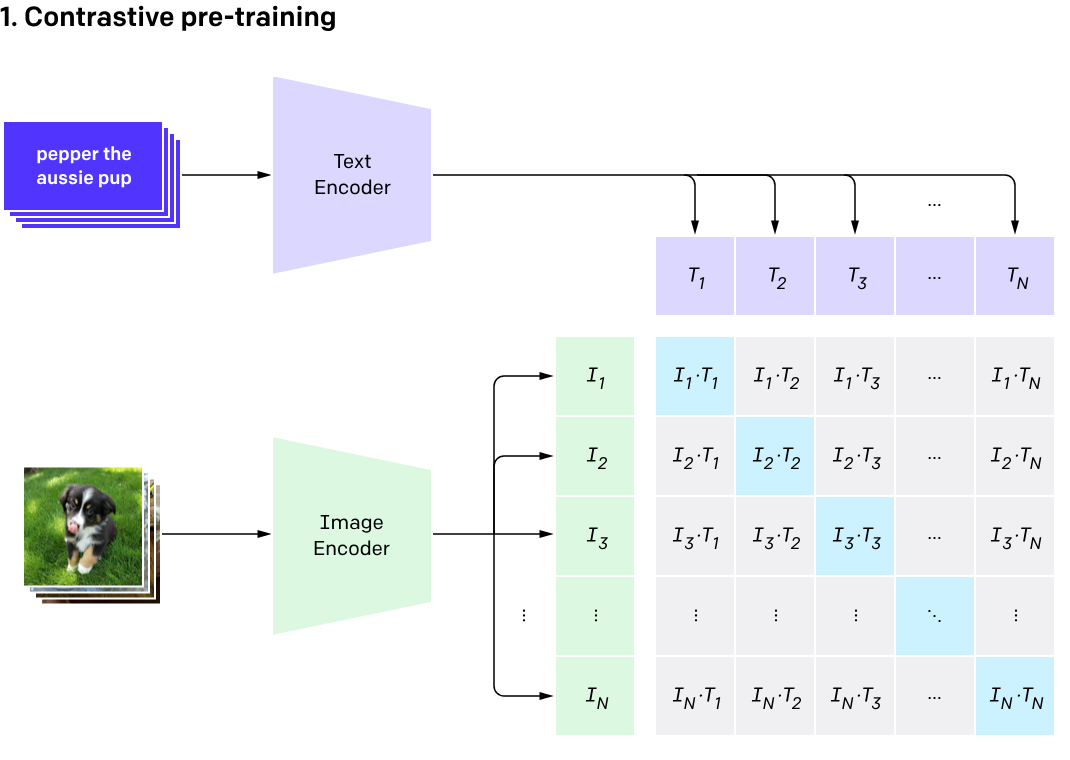
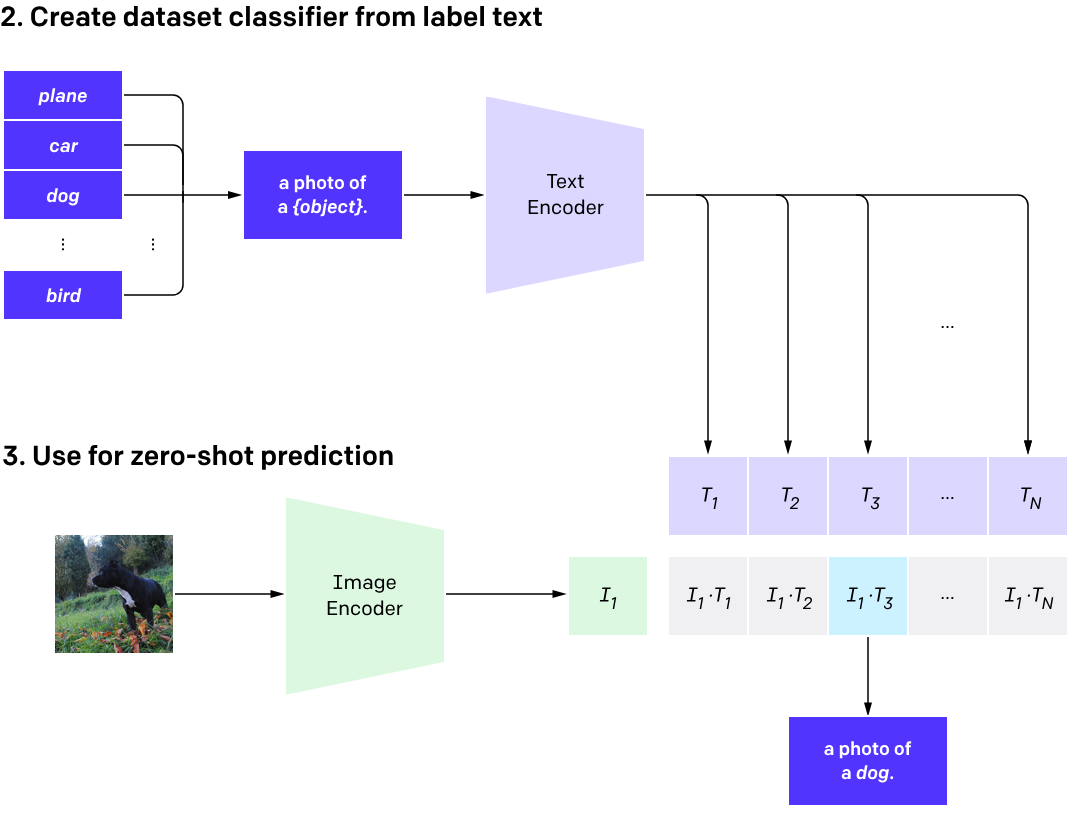
-
CLIP was designed to mitigate a number of major problems in the standard deep learning approach to computer vision:
-
비용이 많이 드는 데이터셋: 딥 러닝은 많은 데이터가 필요하며, 시각 모델은 기존에는 수작업으로 레이블이 지정된 데이터셋에서 훈련되었습니다. 이러한 데이터셋은 구축 비용이 많이 들며 사전 결정된 시각적 개념의 제한된 수에 대한 감독만을 제공합니다. 예를 들어, ImageNet 데이터셋은 25,000명 이상의 작업자가 22,000개의 객체 범주에 대해 1400만 개의 이미지를 주석 처리하는 데 필요했습니다. 반면에 CLIP는 이미 인터넷 상에서 공개되어 있는 텍스트-이미지 쌍에서 학습합니다. 비싼 대규모 레이블이 지정된 데이터셋의 필요성을 줄이는 것은 이전 연구에서 광범위하게 연구되었습니다. 특히 자기 지도 학습, 대조적 방법, 자기 학습 접근 방법 및 생성 모델링 등의 방법이 사용되었습니다.
-
한정된 범위: ImageNet 모델은 1000가지 ImageNet 범주를 예측하는 데 뛰어나지만, 이것이 바로 그 모델의 한계입니다. 다른 작업을 수행하려면 ML 전문가가 새로운 데이터셋을 구축하고 출력 헤드를 추가하고 모델을 세밀하게 조정해야 합니다. 반면, CLIP는 추가적인 훈련 예제가 필요하지 않고도 다양한 시각 분류 작업을 수행할 수 있도록 조정될 수 있습니다. CLIP를 새로운 작업에 적용하려면, 우리가 해야 할 일은 단순히 CLIP의 텍스트 인코더에 작업의 시각적 개념의 이름을 "알려주는" 것이며, 이것은 CLIP의 시각적 표현의 선형 분류기를 출력합니다. 이 분류기의 정확도는 종종 완전히 지도된 모델과 경쟁력이 있습니다.
-
While CLIP usually performs well on recognizing common objects, it struggles on more abstract or systematic tasks such as counting the number of objects in an image and on more complex tasks such as predicting how close the nearest car is in a photo. On these two datasets, zero-shot CLIP is only slightly better than random guessing. Zero-shot CLIP also struggles compared to task specific models on very fine-grained classification, such as telling the difference between car models, variants of aircraft, or flower species.
-
CLIP also still has poor generalization to images not covered in its pre-training dataset. For instance, although CLIP learns a capable OCR system, when evaluated on handwritten digits from the MNIST dataset, zero-shot CLIP only achieves 88% accuracy, well below the 99.75% of humans on the dataset. Finally, we’ve observed that CLIP’s zero-shot classifiers can be sensitive to wording or phrasing and sometimes require trial and error “prompt engineering” to perform well.
-
CLIP은 일반적인 객체를 인식하는 데는 잘 작동하지만, 이미지 내 객체의 수를 세는 것과 같은 보다 추상적이거나 체계적인 작업 또는 사진에서 가장 가까운 자동차가 얼마나 가까운지 예측하는 것과 같은 보다 복잡한 작업에서는 어려움을 겪습니다. 이 두 데이터 셋에서 제로 샷 CLIP는 무작위 추측보다 약간 더 나은 성능을 보입니다. 또한, 제로 샷 CLIP는 자동차 모델의 차이, 항공기의 변형, 또는 꽃의 종류와 같이 매우 미세한 분류에서 작업별 모델과 비교하여 어려움을 겪습니다.
-
또한, CLIP는 사전 훈련 데이터셋에 포함되지 않은 이미지에 대한 일반화 능력이 여전히 부족합니다. 예를 들어, CLIP는 능력있는 OCR 시스템을 학습하지만, MNIST 데이터셋의 손으로 쓴 숫자를 평가할 때, 제로 샷 CLIP의 정확도는 88%로, 이는 데이터셋에서 인간의 99.75%에 미치지 못합니다. 마지막으로, 우리는 CLIP의 제로 샷 분류기가 단어나 구문에 민감할 수 있으며, 때로는 잘 작동하기 위해 시행착오적인 "프롬프트 엔지니어링"이 필요할 수 있다는 것을 관찰했습니다.
참고 ) Zero-shot: 비전 분야에서 zero-shot이란 이전에 한번도 보지 못한 물체에 대한 분류를 예측하는 방식을 말한다.
