1. 챕터의 위치
이전 챕터에서 Bloom과 Power BI를 통해 Neo4j 그래프를 시각화하는 방법을 다뤘다면, 이 챕터는 그 시각화의 입력이 되는 데이터 자체를 어떻게 풍부하게 만들 것인가의 문제를 다룬다. 이 챕터의 thesis는 다음과 같다. 그래프 데이터의 가치는 노드와 관계의 양만으로 결정되지 않는다. LLM을 활용해 텍스트 속성을 요약·임베딩으로 변환하고, 그 결과를 다시 그래프에 적재하는 enrichment 사이클이 분석 가능성의 한계를 결정한다.
ChatGPT는 2022년 OpenAI가 출시한 LLM으로, 업계 다수가 NLP 모델 효능의 변곡점으로 평가한다. 이 챕터의 실용적 관심은 ChatGPT 자체의 기술적 새로움이 아니라, 이 도구를 Neo4j와 결합해 데이터 강화 도구로 사용하는 패턴에 있다.
2. 데이터 강화의 의미
ChatGPT를 데이터 강화 도구로 본다는 것은 다음 다섯 역량을 그래프 데이터에 적용한다는 의미다.
- 텍스트 프롬프트의 이해
- 새로운 데이터 생성
- 데이터 평가 코드 제공
- 텍스트 데이터 증강
- 그 외 다수의 텍스트 처리 능력
이러한 강화가 비즈니스 가치로 이어지는 경로는 단순하다. 강화된 데이터에서 도출되는 통찰이 숨겨진 패턴과 상관관계를 드러내고, 그것이 전략적 의사결정에 기여한다. 강화는 그 자체로 목적이 아니라, 분석과 의사결정의 입력 품질을 끌어올리는 수단이다.
ChatGPT 사용 경로는 두 가지다. 브라우저 인터페이스(https://chat.openai.com/)는 즉시 실험에 적합하고, Python의 OpenAI 라이브러리는 자동화된 파이프라인 통합에 적합하다. Knowledge cutoff 한계는 명시적으로 인지되어야 한다. 모델은 훈련 데이터 시점 이후의 정보를 모르며, 최신 정보가 필요한 작업에서는 검색 보완이 필수다.
3. 특허 데이터: 그래프 + LLM의 이상적 도메인
이 챕터는 특허 데이터셋을 사례로 사용한다. 특허가 그래프 + LLM 조합에 적합한 이유는 세 가지로 정리된다.
| 특성 | 그래프·LLM 적합성 |
|---|---|
| 방대함 (vast) | 단일 문서가 아닌 거대한 corpus가 분석 단위 |
| 상호 연결 (interlinked) | 특허는 선행 특허를 인용하고 후속 특허에 인용된다. 자연스러운 그래프 구조 |
| 밀도 높고 기술적 (dense, technical) | 비전문가에게 어렵다. LLM이 요약과 임베딩 생성에서 가치를 발휘 |
특허는 발명자의 아이디어를 공개하는 대신 발명자에게 법적 권리를 부여하는 IP(intellectual property) 형태다. 데이터 모델 측면에서 특허는 세 핵심 요소로 표현된다.
| 요소 | 정의 |
|---|---|
| Assignee | 특허의 소유권을 보유한 개인·기업·대학 |
| Inventor | 아이디어를 처음 구상한 개인 또는 그룹 |
| Topic | 특허가 속한 기술 분야·주제 |
이 세 요소는 그래프에서 각각 노드 종류가 되며, Document 노드와의 관계(ASSIGNED_TO, INVENTED_BY, IS_IN)로 연결된다.
4. ChatGPT 강화의 네 갈래
특허 데이터에 ChatGPT를 적용하는 방향은 네 가지로 정리된다.
- 간결한 특허 요약 (Concise Patent Summaries)
- 주제 확장 (Topic Expansion)
- 발명자·양수인 프로파일 (Profile of Investors)
- 특허 간 유사도 식별 (Identify Similarities Between Patents)
이 챕터의 본격적 워크플로는 첫 번째 방향인 요약 생성으로 시작된다. 요약이 만들어진 뒤 그것을 임베딩으로 변환하면 네 번째 방향인 유사도 분석으로 자연스럽게 이어진다.
5. 핵심 활용 사례: 간결한 특허 요약
특허는 길고 복잡하며, 비전문가에게 혼란을 주는 용어로 가득하다. 이 본질적 접근성 문제를 ChatGPT가 해결한다. 핵심 패턴은 단순하다. 특허 abstract를 ChatGPT에 입력으로 넣고, 비전문가 언어로 100토큰 이내 요약을 받아낸다.
전형적 프롬프트는 다음과 같다.
Summarize the following patent abstract in laymen's terms in fewer than 100 tokens.이 프롬프트에는 세 가지 제약이 명시되어 있다. 입력 대상(patent abstract), 표현 수준(laymen's terms), 길이 제약(fewer than 100 tokens). 이 제약이 출력의 일관성과 후속 처리 가능성을 보장한다.
생성된 요약을 다시 Neo4j에 기록하는 단계가 enrichment 사이클의 핵심이다. Pandas DataFrame으로 받은 요약을 update_node_summary() 같은 함수가 Cypher의 SET a.Summary = $summary로 노드에 추가한다. 결과적으로 Document 노드는 원본 abstract와 LLM 생성 summary를 모두 속성으로 가지게 된다. 두 형식의 공존이 의도다.
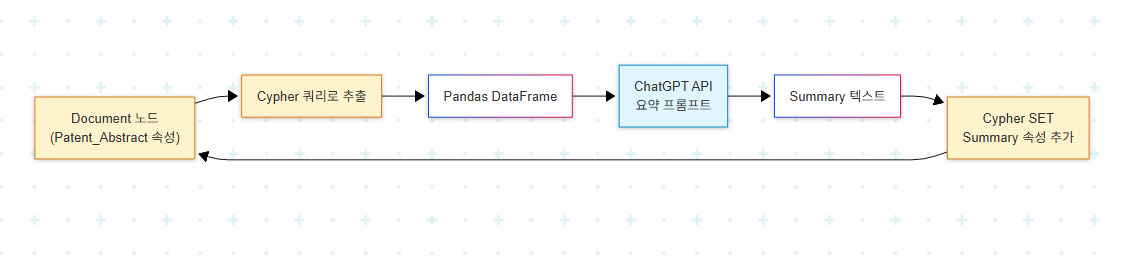
이 사이클이 enrichment의 표준 패턴이다. 그래프에서 텍스트를 꺼내 LLM에 보내고, 결과를 그래프에 다시 적재한다. Neo4j는 단순한 결과 저장소가 아니라 enrichment의 시작점이자 종착점이다.
6. 임베딩의 본질
요약 생성이 텍스트의 길이를 줄이는 작업이라면, 임베딩 생성은 텍스트를 수치 벡터로 변환하는 작업이다. 두 작업의 목적이 다르다.
요약은 사람이 읽기 위한 형식이고, 임베딩은 기계가 분석하기 위한 형식이다. 두 형식 모두 보존하는 것이 enrichment 패턴의 핵심이다.
임베딩의 정의를 정리하면 다음과 같다. 텍스트의 본질과 의미를 응축된 수치 표현으로 담아내는 방식이다. 결과적으로 나오는 숫자 배열은 사람이 직접 보면 의미를 알 수 없으나, 그 숫자들 속에 deep neural network가 학습한 표현 구조가 응축되어 있다. OpenAI 모델은 이 벡터를 해석해 질의 응답, 유사도 매칭, 그 외 다양한 분석을 가능하게 한다.
요약 텍스트를 OpenAI의 ada 모델로 임베딩하는 것이 이 챕터의 표준 절차다. 결과는 고차원 벡터(수천 차원)로, Neo4j 노드 속성으로 저장하거나 별도 벡터 인덱스에 적재된다.
7. 차원 축소: 시각화의 전제
임베딩의 차원이 수천에 이르면 분석에는 유용하나 시각화에는 부적합하다. 인간의 시지각은 2~3차원에 한정된다. 따라서 시각화 단계 진입 전에 차원 축소가 필수가 된다.
PCA(Principal Component Analysis)는 선형 변환 기법으로, 원본 데이터를 새로운 좌표계로 투영한다. 수천 차원 벡터를 2차원으로 축소해 차트에 표시 가능한 형태로 만든다. PCA는 분산을 최대로 보존하는 축을 차례로 선택하는 방식이라 차원 축소 후에도 데이터의 구조적 차이가 어느 정도 보존된다.
다만 PCA는 선형 기법이라는 한계가 있다. 비선형적 의미 구조는 PCA로 평탄화될 수 있다. 이 챕터는 PCA를 표준 도구로 제시하지만, 실무에서는 t-SNE·UMAP 같은 비선형 차원 축소가 임베딩 시각화에 더 적합한 경우가 많다.
8. K-means 클러스터링
차원 축소가 시각화를 위한 변환이라면, K-means 클러스터링은 임베딩 공간 내에서 그룹을 발견하는 분석이다. 임베딩이 고차원 벡터이므로, 그 벡터들을 클러스터링하면 데이터 내부의 본질적 그룹이나 커뮤니티가 드러난다.
K-means는 단순성과 효율성으로 널리 사용되는 클러스터링 알고리즘이다. 사용자가 미리 지정한 K개의 중심점을 기준으로 각 데이터 포인트를 가장 가까운 중심에 할당하고, 중심을 재계산하는 과정을 반복한다. 임베딩에 적용하면 의미적으로 유사한 특허들이 동일 클러스터로 묶인다.
클러스터링의 결과는 단순한 라벨이 아니다. 이 라벨이 그래프의 또 다른 enrichment 속성으로 Neo4j에 다시 기록될 수 있고, Bloom의 rules-based formatting에서 색상 규칙으로 활용될 수 있다. enrichment의 결과가 다음 enrichment의 입력이 되는 사슬이 만들어진다.
9. 전체 워크플로
지금까지의 단계를 하나의 파이프라인으로 정리하면 다음과 같다.
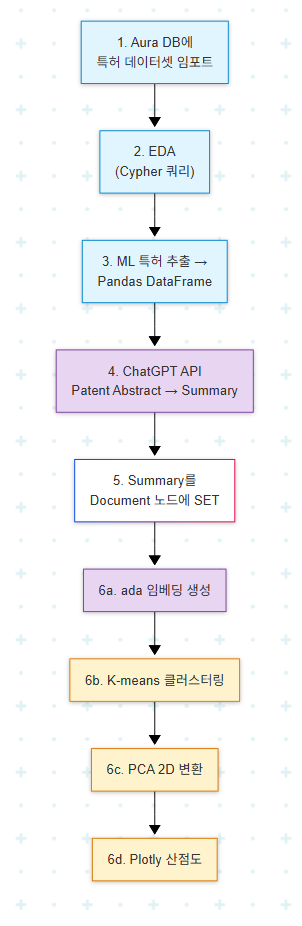
워크플로는 세 단계 성격으로 분리된다. 셋업 단계(1-3)는 일회성, LLM 단계(4·6a)는 외부 API 호출, 분석 단계(6b-6d)는 로컬 계산이다. 운영 측면에서 LLM 단계가 가장 비용·latency 부담이 크므로 캐싱과 배치 처리 설계가 중요하다.
10. NLP 처리 단계의 비교
워크플로의 핵심 단계를 입출력 관점에서 정리하면 다음과 같다.
| 단계 | 입력 | 출력 | 도구 | 목적 |
|---|---|---|---|---|
| 요약 | 긴 특허 초록 | 100토큰 이내 요약 | ChatGPT | 비전문가 접근성 향상 |
| 임베딩 | 요약 텍스트 | 고차원 수치 벡터 | OpenAI ada | 의미·문맥의 수치 표현 |
| 클러스터링 | 임베딩 벡터 | K개 커뮤니티 라벨 | K-means | 유사 특허 그룹화 |
| 차원 축소 | 고차원 벡터 | 2D 좌표 | PCA | 시각화 가능성 확보 |
| 시각화 | 2D + 커뮤니티 라벨 | 산점도 | Plotly | 패턴·통찰 발견 |
이 표의 순서는 임의가 아니다. 각 단계의 출력이 다음 단계의 입력이 되는 데이터 흐름이며, 임베딩이라는 중간 표현을 거쳐야만 클러스터링과 차원 축소가 가능하다. 임베딩이 텍스트와 분석 사이의 다리 역할을 한다.
11. EDA Cypher 패턴
워크플로의 두 번째 단계인 EDA에서 자주 사용되는 Cypher 패턴을 정리한다.
// 노드 개수 카운트
MATCH (a:Document)
RETURN count(a) AS Number_Documents
// Topic별 문서 수 Top-N
MATCH (a:Topic)<-[:IS_IN]-(b:Document)
RETURN a.name AS Topic_Name, count(b) AS topic_count
ORDER BY topic_count DESC
LIMIT 5
// 조건부 필터링 + 다중 조인 (ML 특허만)
MATCH (c:Topic)<-[:IS_IN]-(a:Document)-[:ASSIGNED_TO]->(b:Assignee)
WHERE c.name = 'Machine Learning'
RETURN id(a) AS ida, a.title, b.name, a.abstract
LIMIT 300마지막 패턴이 enrichment 워크플로의 진입점이 된다. 특정 Topic에 속한 Document들을 abstract 속성과 함께 추출해 Pandas로 옮기면, 그것이 LLM 입력 dataset이 된다.
12. 정리
ChatGPT 기반 enrichment의 핵심은 그래프 → LLM → 그래프의 사이클이다. 특허 abstract를 추출해 ChatGPT로 비전문가용 요약을 생성하고 그 결과를 다시 그래프 노드 속성으로 적재한다. 요약은 다시 임베딩으로 변환되고, 임베딩은 K-means 클러스터링과 PCA 차원 축소를 거쳐 시각화된다. 텍스트와 임베딩이 함께 보존되는 이중 표현 구조가 분석의 유연성을 만들고, 그래프는 enrichment의 입력이자 종착점으로 기능한다.
결론: enrichment는 그래프 데이터에 LLM의 텍스트 지능을 한 번 주입하는 일회성 작업이 아니라, 원본을 보존한 채 강화 결과를 누적하는 사이클이다.
참고 자료
- Graph Data Science with Python and Neo4j
— Chapter 6: Enriching Neo4j Data with ChatGPT.
