1. 시각화의 위치
데이터 사이언스에서 시각화는 부수 도구가 아니라 데이터의 복잡한 차원을 이해 가능하고 소화 가능하며 실행 가능한 통찰로 번역하는 핵심 단계다. 그래프 데이터는 특히 시각화 의존도가 높다. 노드 수가 수백을 넘어가면 표 형태의 raw 데이터로는 패턴을 식별할 수 없으며, 관계의 다층적 구조는 시각적 표현 없이는 stakeholder에게 전달되지 않는다. 이 챕터의 thesis는 다음과 같다. 그래프 시각화의 가치는 "보기 좋은 그림"이 아니라 stakeholder에게 그래프 저장 방식의 가치 자체를 입증하는 도구라는 데 있다.
이전 챕터에서 Neo4j에 데이터를 임포트하는 네 가지 방법을 다뤘다면, 이 챕터는 그렇게 적재된 데이터를 어떻게 보여줄 것인가의 문제를 다룬다. Neo4j Bloom과 Power BI라는 두 도구가 각각 그래프 전용성과 BI 인프라 통합이라는 다른 축에서 답을 제시한다.
2. Neo4j Bloom의 정체
Neo4j Bloom은 Neo4j에 저장된 데이터를 시각화·탐색하기 위한 그래프 전용 도구다. Bloom이 설계상 가지는 가장 큰 특징은 양면적 사용자 친화성이다. 비기술 사용자에게는 point-and-click 인터페이스로 쿼리 작성 부담 없이 데이터를 탐색할 수 있게 하고, 기술 사용자에게는 정교한 Cypher 쿼리를 동일 인터페이스 안에서 실행할 수 있게 한다. 두 사용자층이 같은 도구를 다른 방식으로 사용한다.
라이선스 측면에서 Neo4j Desktop 버전에는 Bloom이 무료로 포함되지만, 조직 환경에서 Neo4j Server를 운영한다면 별도 라이선스 키가 필요하다.
Neo4j Browser와의 차이도 명확히 짚을 가치가 있다. Browser는 라벨을 클릭하면 해당 라벨의 첫 25개 노드를 즉시 매치해 보여주는 반면, Bloom은 데이터 탐색을 시작하기 위해 초기 Cypher 쿼리를 요구한다. 이 진입 장벽은 단점이 아니라, 명확한 탐색 의도를 가진 시각화 도구로서의 설계 결정이다.
3. Perspective: 시각화의 추상화 단위
Bloom의 Perspective는 "어떤 노드·관계·속성을 사용자에게 노출할 것인가"를 정의하는 시각화 구성 단위다. 데이터베이스에 존재하는 모든 정보를 모든 사용자에게 보여줄 필요는 없다. Bloom은 노드·관계·속성을 선택적으로 제외할 수 있는 유연성을 제공한다.
이 기능의 실용적 가치는 머신러닝 운영에서 분명하게 드러난다. 새 ML 모델을 개발하면서 모델 출력을 노드 속성으로 데이터베이스에 기록할 때, 이 내부 속성이 일반 사용자에게 노출되면 혼란을 일으키거나 인지 부하를 가중시킨다. Perspective를 통해 ML 개발 단계의 속성을 사용자 시야에서 제거할 수 있다. ML 개발과 사용자 경험을 분리하는 추상화 layer의 역할을 한다.
4. 시각화 포맷팅: 4대 제어 축
Bloom의 시각화는 네 축으로 제어된다.
| 제어 대상 | 의미 |
|---|---|
| 노드의 아이콘 | 노드 유형의 직관적 식별 |
| 노드 원의 크기 | 속성 값에 따라 동적 변경 |
| 관계의 굵기 | 관계 속성에 기반한 강도 표현 |
| 관계의 색상 | 관계 유형 구분 |
이 네 축을 정적으로 설정할 수도 있고, rules-based formatting으로 데이터에 따라 동적으로 변경되도록 할 수도 있다. 후자가 그래프가 커질수록 더 중요해지는 이유는 다음 절에서 다룬다.
5. Rules-based Formatting: 주의 설계의 도구
그래프가 커지면 노드 유형의 시각적 구분이 점차 어려워진다. 라벨별 단순 색상 구분으로는 수백 개 노드 중 의미 있는 패턴을 식별할 수 없다. Rules-based formatting은 이 문제를 사용자의 시선을 가장 의미 있는 부분으로 유도하는 attention design으로 해결한다.
전형적 적용 예시 두 가지를 보면 메커니즘이 분명해진다.
- Degree 기반 크기 변경: 연결 수가 10 이상인 노드의 크기를 4배로 확대. 그래프의 hub node가 시각적으로 즉시 식별된다.
- 속성 키워드 기반 색상 변경: Recipe Title에 'mexican'이 포함된 노드를 녹색으로 변경. 의미적 카테고리가 색으로 분리된다.
두 예시 모두 데이터의 어떤 속성이 시각 속성으로 매핑되는지를 규칙으로 명시한다. 이 매핑이 명시적일수록 시각화는 stakeholder에게 신뢰 가능한 도구가 된다.
6. 점진적 탐색: Expand와 Dismiss Other Nodes
대규모 그래프에서 모든 노드를 동시에 표시하는 것은 비현실적이다. Bloom은 점진적 탐색(incremental exploration) 모델을 제공한다.

이 사이클은 그래프 탐색의 인지적 부담을 분할한다. 한 번에 하나의 관심 영역만 시야에 두고, 그곳에서 한 단계씩 관계를 따라가며 새로운 연결을 발견한다. 데이터 탐색을 일회성 시각화가 아닌 대화형 프로세스로 전환하는 것이 Bloom의 핵심 사용 모델이다.
7. Scene Actions: Cypher 기반 정밀 제어
수동 Expand의 한계는 분명하다. 한 노드가 수백·수천 개의 다른 노드와 연결된 경우, 단순 확장은 캔버스를 즉시 클러터로 채운다. Scene Actions는 Cypher를 사용해 캔버스에 표시될 패턴을 정밀하게 제어하는 메커니즘이다.
전형적 사용 시나리오는 두 노드 사이의 공통점만 표시하는 것이다. 두 레시피 노드가 선택되었을 때, 모든 연결을 펼치는 대신 두 레시피가 공통으로 사용하는 재료만 표시하는 Scene Action을 정의할 수 있다. 결과적으로 시각화는 "두 레시피가 어떻게 연관되는가"라는 질문에 직접 답하는 형태로 좁혀진다.
수동 Expand와 Scene Actions의 차이는 다음과 같다.
| 측면 | 수동 Expand | Scene Actions |
|---|---|---|
| 제어 수단 | 우클릭 메뉴 | Cypher 쿼리 |
| 확장 범위 | 선택된 관계 전체 | 쿼리가 정의한 패턴만 |
| 적합 그래프 크기 | 소규모 | 대규모 |
| 클러터 위험 | 높음 | 낮음 |
| 의미 있는 패턴 추출 | 어려움 | 쉬움 |
Scene Actions가 대규모 그래프 시각화의 차별점이 되는 이유는, 시각화가 단순한 보기가 아니라 질문에 대한 답으로 기능하게 만들기 때문이다.
8. Bloom 시각화 워크플로 정리
Bloom 사용의 표준 워크플로는 다음과 같이 단계화된다.
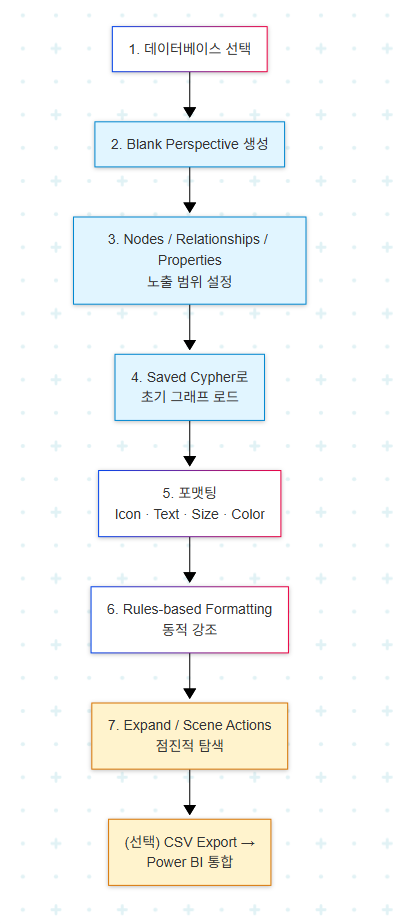
세 단계의 성격이 다르다는 점이 중요하다. 1~3은 셋업으로 일회성 작업이며, 4~6은 시각적 정의로 데이터 도메인 지식이 필요하고, 7~8은 반복적 탐색으로 사용자 질문에 따라 매번 다르게 흐른다.
9. Power BI 통합: 한계와 가치
Bloom이 그래프 전용 도구라면, Power BI는 일반 BI 도구로 그래프 시각화에 접근하는 다른 경로다. 두 도구의 통합 가능성과 제약을 짚는다.
핵심 제약은 명확하다. Power BI는 Neo4j 데이터베이스에 대한 동적 API 연결을 지원하지 않는다. 따라서 Neo4j 데이터를 Power BI에서 시각화하려면 먼저 CSV로 export한 뒤 Power BI에 import해야 한다. 데이터의 실시간성이 손실된다.
이 한계에도 불구하고 Power BI 통합이 의미를 가지는 이유는 조직 인프라 측면의 실용주의다. 많은 조직이 이미 Power BI를 기술 스택의 일부로 운영하고 있다. 새로운 시각화 도구를 도입하는 것보다 기존 도구를 활용하는 편이, 특히 PoC(proof-of-concept) 단계에서는 의사결정이 빠르고 조직 채택 비용이 낮다.
Power BI에서 그래프를 시각화하는 표준 절차는 다음과 같다.
- Bloom에서 결과를 CSV·Excel로 export
- Microsoft Store에서 Power BI Desktop App 설치
- 관계 CSV 파일 import
Get more visuals에서Drill Down Graph시각화 패키지 설치- 컬럼 매핑:
start_node_property→ Source Node,end_node_property→ Target Node, 관계 값 → Value - bar chart 등 다른 시각화와 결합해 BI식 drill down 분석 수행
10. Bloom과 Power BI의 비교
두 도구는 같은 그래프 데이터를 다루지만 사용 맥락이 다르다.
| 측면 | Neo4j Bloom | Power BI |
|---|---|---|
| 연결성 | Neo4j와 네이티브 통합 | 동적 API 미지원, CSV 경유 |
| 그래프 전용성 | 그래프 시각화 특화 | 일반 BI, 그래프는 추가 패키지 |
| 사용자층 | 데이터 분석가, 개발자 | 비즈니스 사용자 |
| 점진적 탐색 | Expand·Scene Actions 강력 | 제한적 |
| 드릴다운 | 그래프 내부 확장 | 다른 차트와 결합한 BI식 드릴다운 |
| 조직 채택 용이성 | 별도 도구 도입 필요 | 기존 인프라 활용 가능 |
| PoC 적합성 | 그래프 분석 깊이 우선 시 | 빠른 의사결정·기존 도구 재활용 시 |
이 둘을 양자택일로 다루기보다 분석 단계에 따른 역할 분담으로 보는 것이 적절하다. Bloom은 그래프 본연의 구조를 깊이 탐색하는 단계에서, Power BI는 결과를 비즈니스 stakeholder에게 통합 대시보드로 전달하는 단계에서 강점을 발휘한다.
11. 정리
Neo4j Bloom의 시각화 워크플로는 Perspective 정의, Saved Cypher 기반 초기 로드, 정적·동적 포맷팅, Expand와 Scene Actions를 통한 점진적 탐색의 다섯 단계로 구성된다. Rules-based formatting은 그래프 규모가 커질수록 사용자의 주의를 의미 있는 곳으로 유도하는 attention design의 도구가 되고, Scene Actions는 단순 확장의 클러터를 피하면서 Cypher의 정밀도를 시각화에 결합한다. Power BI 통합은 그래프 데이터를 기존 BI 인프라에 연결하는 실용주의적 경로이며, 동적 연결 미지원이라는 한계를 조직 채택 용이성으로 보완한다. 두 도구는 양자택일이 아닌 분석 단계별 역할 분담으로 사용된다.
결론: 그래프 시각화의 가치는 그림의 미려함이 아니라, 그래프 저장 방식 자체의 가치를 stakeholder에게 입증하는 데 있다.
참고 자료
- Graph Data Science with Python and Neo4j
— Chapter 5: Visualizing Graph Networks.
