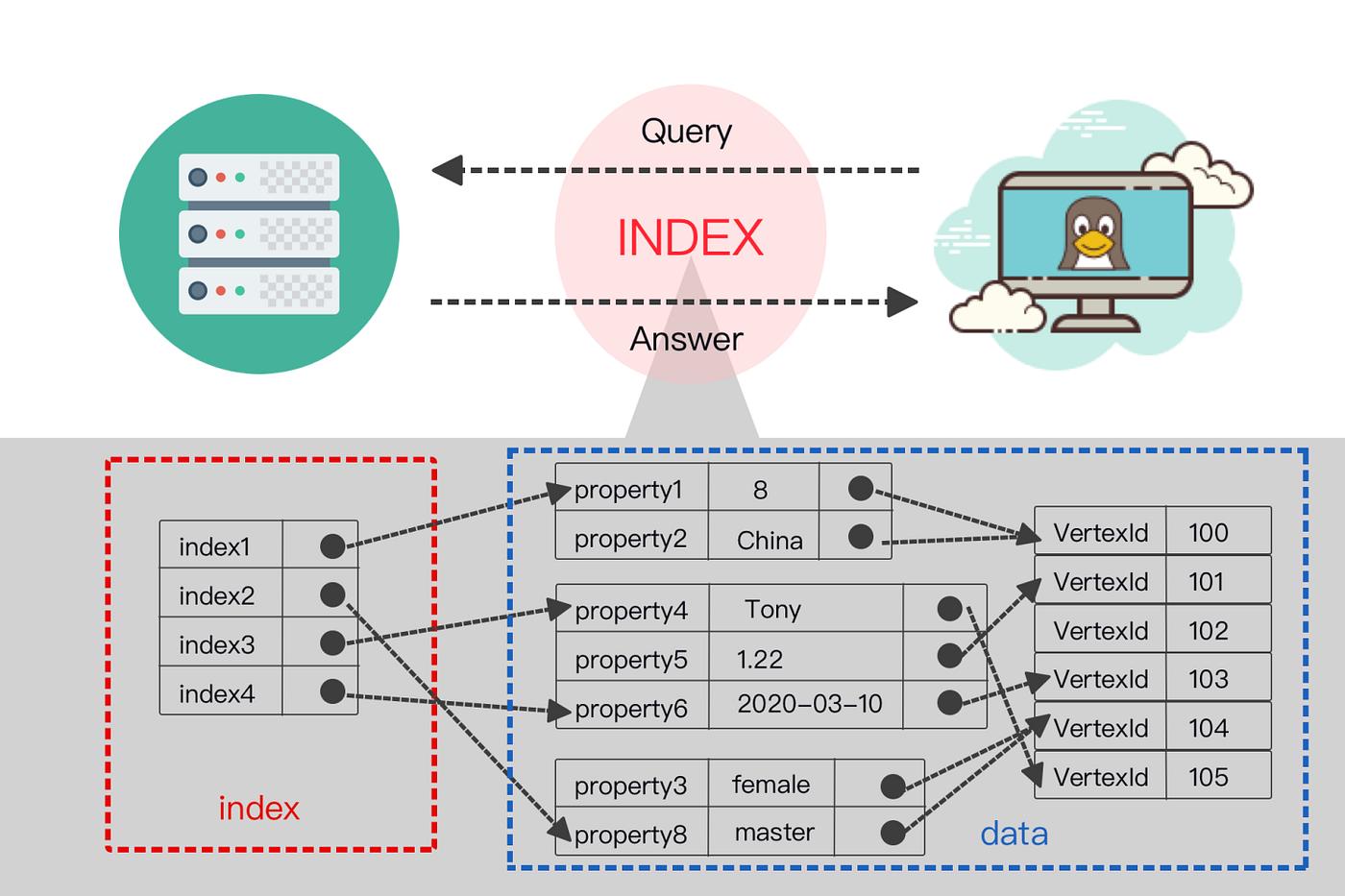
Neo4j 시리즈의 앞선 글들에서 그래프 데이터 모델의 구조와 노드·관계의 저장 방식을 다루었다. 모델이 정의되었다면 다음 단계는 그것을 질의하는 언어다. Cypher는 그래프 데이터베이스 질의를 위한 declarative query language로, SQL이 관계형 데이터베이스에서 차지하는 역할을 그래프 영역에서 수행한다. Neo4j는 Cypher를 openCypher 프로젝트로 오픈소스화하여 그래프 질의 언어의 표준으로 확산시키려는 작업을 이어오고 있다.
이번 글의 thesis는 다음과 같다. Cypher의 본질은 패턴 매칭이며, 성능은 인덱싱과 graph projection 선택에서 갈린다. MATCH/WHERE/RETURN의 문법은 한 시간이면 익히지만, 같은 쿼리를 수십 배 빠르게 만드는 결정은 인덱스 설계, projection 전략, EXPLAIN/PROFILE을 통한 실행 계획 분석에 달려 있다.
1. Cypher의 정체성: Declarative Graph Query Language
Cypher는 노드와 관계의 패턴을 ASCII art 형태의 문법으로 기술하는 선언적 질의 언어로 정의된다. 사용자는 "어떻게 데이터를 가져올지"가 아니라 "무엇을 가져올지"를 기술하며, 실행 계획 수립은 데이터베이스 엔진이 담당한다.
기본 구문 요소는 세 가지로 구성된다.
| 요소 | 역할 | SQL 대응 |
|---|---|---|
MATCH | 노드·관계 패턴 매칭 | SELECT + JOIN |
WHERE | 매칭 결과를 속성 조건으로 필터링 | WHERE |
RETURN | 반환할 데이터 지정 | SELECT projection |
노드는 소괄호로, 관계는 대괄호와 화살표로 표기한다.
// 특정 인물이 출연한 영화 중 평점이 높은 작품 조회
MATCH (p:Person {name: 'Keanu Reeves'})-[:ACTED_IN]->(m:Movie)
WHERE m.rating > 8.0
RETURN m.title, m.rating
ORDER BY m.rating DESC
LIMIT 10MATCH 절은 매칭할 패턴을 정의하지만, 어떤 요소를 결과로 반환할지는 RETURN 절이 결정한다. 두 절의 분리는 그래프 traversal과 결과 projection을 개념적으로 구분하는 Cypher의 설계 원칙이다. LIMIT은 반환 행 수를 제한하여 서버 부하를 방지하는 안전장치 역할을 한다.
2. 패턴 매칭의 동작 흐름
Cypher 쿼리가 어떻게 실행되는지 단계별로 시각화하면 다음과 같다.
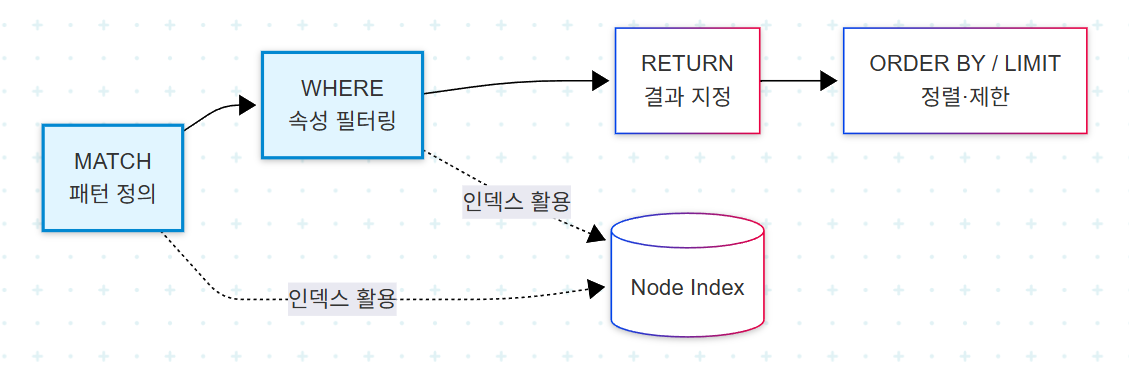
MATCH가 패턴의 시작점을 찾을 때 인덱스가 존재하면 인덱스 스캔으로 진입한다. 인덱스가 없으면 해당 라벨의 모든 노드를 순회하는 label scan이 발생한다. WHERE 절에서 사용되는 속성 역시 인덱스 활용 여부가 성능을 결정한다.
관계 방향 처리
Neo4j는 내부적으로 모든 관계에 방향을 저장하지만, 쿼리에서는 방향을 명시하지 않아도 된다. 양방향 traversal이 필요하면 화살표 없이 -[:REL]- 형태로 작성한다.
// 방향 무관 매칭
MATCH (a:Person)-[:KNOWS]-(b:Person)
RETURN a, b3. 인덱싱: 성능의 분기점
인덱싱은 그래프 데이터베이스에서 성능을 결정짓는 가장 중요한 단일 요소다. 인덱스가 없으면 데이터베이스는 요청된 속성을 찾기 위해 모든 노드를 스캔해야 하며, 이는 데이터 규모가 커질수록 비현실적인 비용을 발생시킨다.
// 인덱스 생성 (Neo4j 5.x 문법)
CREATE INDEX person_name_idx FOR (p:Person) ON (p.name);
// 관계 속성에도 인덱스 생성 가능
CREATE INDEX rel_since_idx FOR ()-[r:KNOWS]-() ON (r.since);WHERE 절에서 사용되는 모든 속성은 인덱싱해야 한다. 이를 누락하면 노드 라벨 전체를 순회하는 비용이 발생하여, 데이터 규모에 따라 데이터베이스 자체가 응답 불능 상태에 빠질 수 있다. 노드뿐 아니라 관계의 속성도 인덱싱 대상이 된다는 점은 RDB와 구분되는 특징이다.
4. Degree Functions: 연결 정도의 정량화
그래프 분석에서 가장 기초적인 측정값은 노드의 연결 수, 즉 degree다. Cypher는 이를 함수 형태로 제공한다.
| Degree 종류 | 의미 |
|---|---|
| Outgoing Degree | source 노드에서 나가는 관계의 총 수 |
| Incoming Degree | source 노드로 들어오는 관계의 총 수 |
| Degree | incoming + outgoing 합계 |
// 가장 영향력 있는 사용자 Top 10 (팔로워 수 기준)
MATCH (u:User)
RETURN u.name, COUNT { (u)<-[:FOLLOWS]-() } AS followers
ORDER BY followers DESC
LIMIT 10Degree는 그 자체로도 분석 지표가 되지만, PageRank·중심성 계산 등 고급 알고리즘의 입력으로 작동한다.
5. Graph Projections: 알고리즘 실행을 위한 별도 표현
Neo4j의 native graph 저장 방식은 traversal에는 최적화되어 있으나, 모든 그래프 알고리즘에 효율적이지는 않다. PageRank, community detection, similarity 계산 등은 인접 행렬과 같은 다른 자료구조에서 훨씬 빠르게 동작한다. 이 간극을 메우는 것이 graph projection이다.
Graph projection은 Neo4j Graph Data Science(GDS) 라이브러리가 관리하는, 알고리즘 실행에 최적화된 in-memory 표현이다. 관계형 데이터베이스의 "view" 개념과 유사하나, 메모리에 알고리즘 친화적 포맷(예: adjacency matrix)으로 적재된다는 점이 다르다.
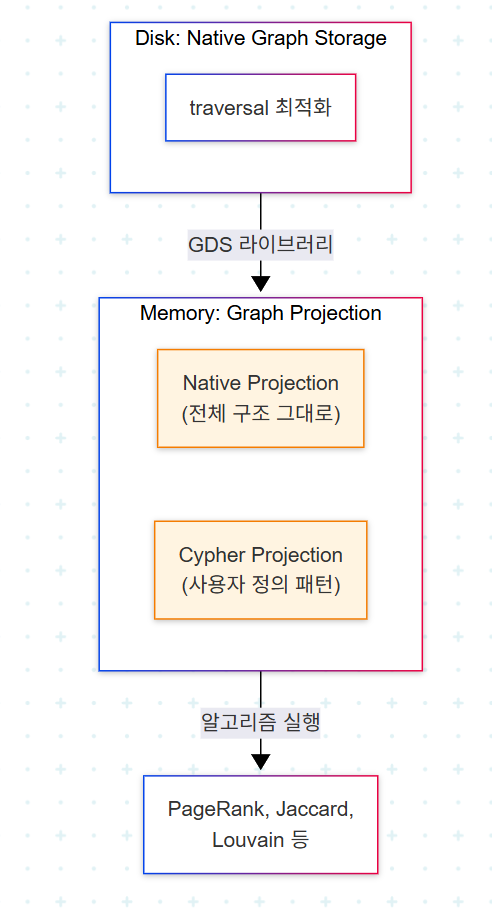
두 가지 Projection 방식
| 항목 | Native Projection | Cypher Projection |
|---|---|---|
| 정의 방식 | 기존 라벨·관계 타입 그대로 사용 | Cypher 쿼리로 패턴 정의 |
| 계산 효율 | 가장 효율적 | 상대적으로 낮음 |
| 유연성 | 낮음 (전체 구조 기반) | 높음 (서브셋·가공 가능) |
| UNDIRECTED 지원 | 가능 | 불가 |
| 적합 상황 | 대규모 전체 그래프 분석 | 서브셋·필터링된 분석 |
Native projection은 기존 그래프 구조와 라벨을 그대로 사용하며 계산상 가장 효율적이다. Cypher projection은 사용자가 메모리에 적재할 노드·관계 패턴을 자유롭게 정의할 수 있는 유연성을 제공하지만, 'UNDIRECTED' 지정이 불가능하다는 제약이 있다. 일부 알고리즘은 무방향성을 요구하기 때문에 이 제약은 알고리즘 선택을 제한할 수 있다. 또한 대규모 데이터셋에서는 Cypher projection 방식 자체가 실행 불가능할 수도 있다.
// Native projection 예시
CALL gds.graph.project(
'socialGraph',
'User',
'FOLLOWS'
);
// Cypher projection 예시 (활성 사용자만)
CALL gds.graph.project.cypher(
'activeUsers',
'MATCH (u:User) WHERE u.lastLogin > date("2025-01-01") RETURN id(u) AS id',
'MATCH (u1:User)-[:FOLLOWS]->(u2:User) RETURN id(u1) AS source, id(u2) AS target'
);Projection 실행 전 노드 개수를 사전에 카운트하여 메모리 적재 규모를 예측하는 것이 권장되는 관행이다.
6. Jaccard Similarity: Projection 활용 예시
Jaccard Similarity 알고리즘은 두 노드가 공유하는 연결의 교집합 비율로 유사도를 계산한다. 공통 이웃이 많을수록 두 노드는 유사한 것으로 판정된다.
// User-Product 그래프에서 유사 사용자 탐색
CALL gds.nodeSimilarity.stream('userProductGraph')
YIELD node1, node2, similarity
RETURN
gds.util.asNode(node1).name AS user1,
gds.util.asNode(node2).name AS user2,
similarity
ORDER BY similarity DESC
LIMIT 20이 방식은 중복 레코드 식별, 추천 시스템의 user-user 유사도 계산, entity resolution 등에서 활용된다. 전통적인 RDB에서는 self-join을 통해 구현 가능하나 관계 수가 증가하면 비용이 급격히 상승하므로, 그래프 알고리즘 기반 접근이 명확한 이점을 제공하는 영역이다.
7. 쿼리 분석: EXPLAIN과 PROFILE
그래프 데이터베이스에서는 관계 traversal의 깊이가 한 단계 증가할 때마다 탐색 비용이 지수적으로 증가할 수 있다. 따라서 쿼리 실행 전 실행 계획을 검토하는 것은 옵션이 아니라 표준 절차다.
| 명령 | 실행 여부 | 제공 정보 |
|---|---|---|
EXPLAIN | 미실행 | 예상 실행 계획·접근 패턴 |
PROFILE | 실행 | 실행 계획 + 단계별 통계(db hits 등) |
// 실행 없이 계획만 확인
EXPLAIN
MATCH (p:Person)-[:ACTED_IN]->(m:Movie)
WHERE p.name = 'Tom Hanks'
RETURN m.title;
// 실제 실행 + 통계
PROFILE
MATCH (p:Person)-[:ACTED_IN]->(m:Movie)
WHERE p.name = 'Tom Hanks'
RETURN m.title;EXPLAIN은 쿼리를 실행하지 않고 데이터베이스가 어떤 노드·관계·속성에 접근할지를 보여주는 반면, PROFILE은 실제 실행과 함께 각 단계의 db hits 통계를 제공한다. 비용이 큰 쿼리를 사전에 식별하는 것이 핵심 목적이다.
8. 장시간 실행 쿼리 관리
잘못 작성된 쿼리는 데이터베이스 전체에 영향을 줄 수 있다. Neo4j는 실행 중인 쿼리 조회와 취소 메커니즘을 제공한다.
// 현재 실행 중인 쿼리 조회
SHOW TRANSACTIONS;
// 특정 트랜잭션 취소
TERMINATE TRANSACTION "transaction-id";쿼리 취소는 협력적 연산(cooperative operation)이다. 데이터베이스는 일정 간격으로 중단 여부를 확인하며, 이 때문에 일부 연산은 종료 요청 후에도 한동안 응답하지 않을 수 있다. 가능한 모든 쿼리는 실행 전 최적화하고, 자원 한계를 사전 설정하여 취소 자체가 필요한 상황을 줄이는 편이 낫다. 극단적인 경우 데이터베이스 재시작이 transient state를 정리하고 새 설정을 적용하는 방법이 된다.
9. 한계 및 트레이드오프
Cypher와 Neo4j 기반 분석은 강력하지만 몇 가지 구조적 제약을 갖는다.
첫째, 깊은 traversal의 비용 폭발 위험. Cypher는 다중 hop 질의를 간결하게 표현할 수 있지만, 변수 길이 패턴(-[*1..5]-)은 노드의 평균 degree가 클 경우 지수적 비용을 발생시킨다. EXPLAIN으로 사전 점검이 가능하지만, 데이터 분포에 따라 실제 비용은 추정치와 크게 달라질 수 있다.
둘째, Graph projection의 메모리 의존성. GDS의 projection 기반 알고리즘은 그래프를 메모리에 적재한 후 실행된다. 대규모 그래프에서는 projection 자체가 불가능하거나 OOM을 발생시킬 수 있으며, Cypher projection 방식은 native projection보다 더 빠르게 메모리 한계에 도달한다. 'UNDIRECTED' 미지원 등 알고리즘 호환성 제약도 함께 존재한다.
셋째, 인덱스의 양면성. 인덱스는 읽기 성능을 극적으로 개선하지만 쓰기 비용을 증가시킨다. 빈번한 쓰기가 발생하는 노드 속성에 인덱스를 다수 설정하면 ingestion 처리량이 저하된다. 인덱싱 대상 선정은 워크로드의 read/write 비율을 기준으로 결정해야 한다.
10. 정리
native graph 데이터베이스의 가치는 전통적 RDB에서 발견이 어려운 패턴을 드러내는 능력에 있다. Cypher는 이 능력을 활용하기 위한 표준 인터페이스이며, 그 운용은 다음 네 가지 축으로 압축된다.
- MATCH/WHERE/RETURN 패턴 매칭 문법의 정확한 이해
- 인덱싱을 통한 조회 성능의 orders of magnitude 단위 개선
- Graph projection 선택(native vs Cypher)에 따른 알고리즘 실행 효율 조정
- EXPLAIN/PROFILE을 통한 사전·사후 실행 계획 분석
이 네 축의 균형이 그래프 데이터베이스 프로젝트의 성패를 가른다.
결론: Cypher의 문법은 패턴 매칭이지만, 그 성능은 인덱스와 projection 설계에서 결정된다.
참고 자료
- Graph Data Science with Python and Neo4j
— Chapter 4: Cypher Query Language.
