Expert Emulation: 자연어로 Knowledge Graph에 질문하기
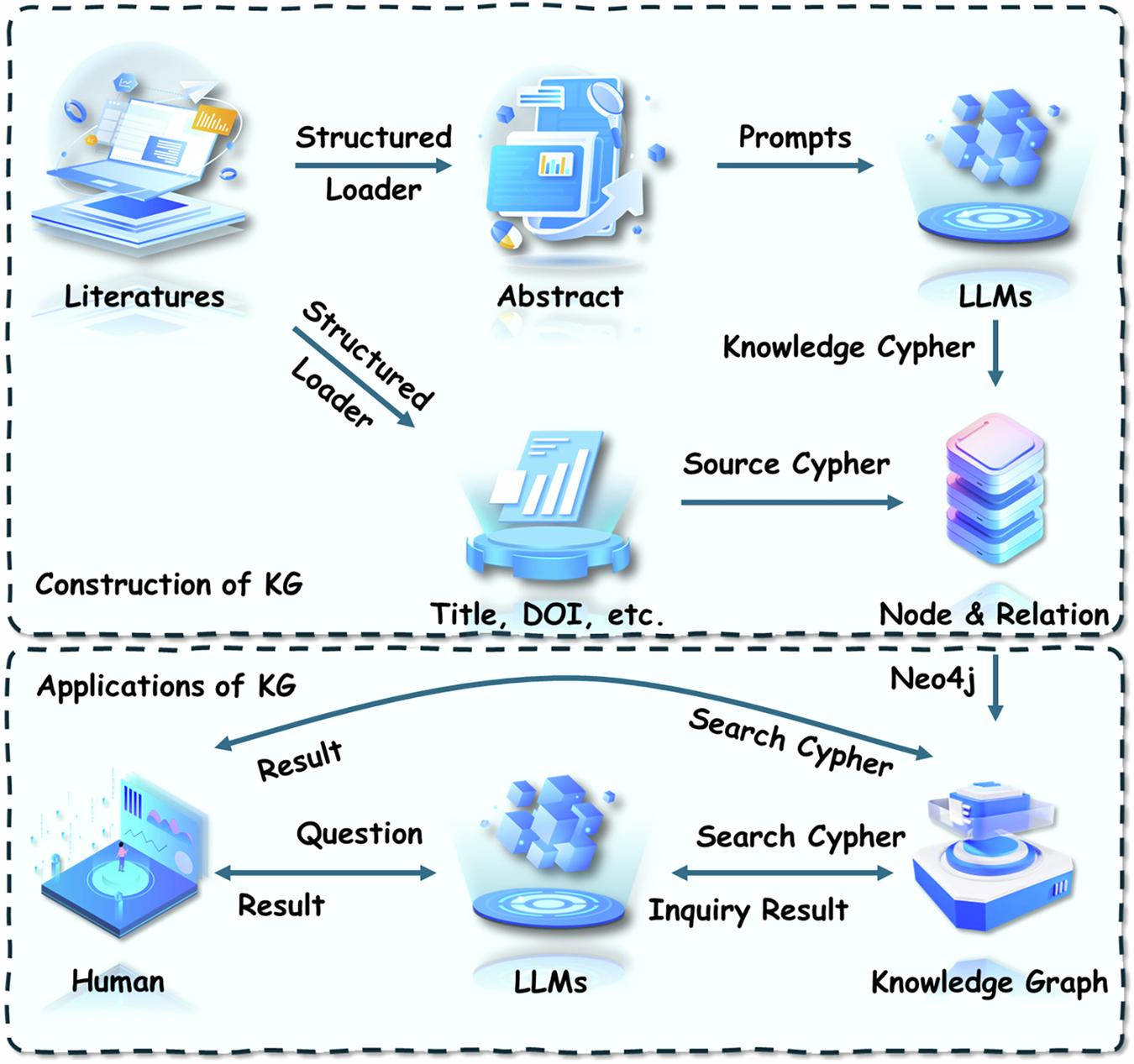
GraphRAG 시리즈는 지금까지 knowledge graph의 구축, 엔티티 추출, 관계 모델링, 그래프 분석 알고리즘을 다루어 왔다. 그러나 잘 구축된 KG라 하더라도 그것을 실제로 활용하는 단계에서는 새로운 병목이 발생한다. KG 질의는 전통적으로 Cypher나 SPARQL 같은 기술적 언어를 다룰 줄 아는 사람에게만 열려 있는 영역이었으며, 도메인 전문가의 일반적 toolkit 바깥에 있다. 분석가가 질문을 정의하면 데이터 엔지니어가 쿼리를 작성하고 결과를 다시 분석가에게 전달하는 이 핸드오프 구조는 의사결정 속도를 결정적으로 떨어뜨린다.
이번 글의 thesis는 다음과 같다. 자연어 질의 시스템의 본질은 "정답을 생성하는 것"이 아니라 "올바른 질문을 형식화하는 것"이며, 그 구현은 RAG가 아니라 expert emulation 패러다임에서 출발해야 한다. LLM은 도메인 전문가의 답변을 흉내내는 것이 아니라 도메인 전문가의 추론 과정을 흉내내야 한다.
1. RAG의 구조적 한계
RAG는 LLM에 외부 컨텍스트를 주입하여 답변 품질을 높이는 표준적 접근이다. 그러나 KG 질의 도메인에서 RAG는 몇 가지 결정적 한계를 드러낸다.
RAG의 성공은 retrieval 단계의 효과성에 전적으로 의존한다. 모델의 출력은 retrieval 단계의 품질만큼만 좋을 수 있으며, 이는 모델이 응답에 대해 표현하는 confidence와 무관하다. retrieval이 불완전할 때 LLM은 충분한 컨텍스트 없이 답변을 생성해야 하는 상황에 놓인다.
문제의 본질은 다음과 같다.
| 항목 | RAG 작동 조건 | KG 질의 도메인의 현실 |
|---|---|---|
| 정보 단위 | 독립적이고 fine-grained한 passage로 분할 가능 | 정보가 관계 traversal로 흩어져 있음 |
| 누락 허용도 | 일부 누락이 부분적 영향 | 단 하나의 핵심 증언 누락이 반대 결론을 유도 |
| 평가 기준 | semantic similarity | 정확한 사실 매칭 |
| 실패 양상 | "모름" 응답 | plausible but inaccurate 답변 생성 |
retrieved passage의 granularity가 부적절하거나 retriever가 관련성을 정확히 평가하지 못하면, LLM에 제공되는 컨텍스트는 fragmented 상태가 된다. 이 fragmented context는 모델을 잘못된 가정으로 밀어붙이며, 결과적으로 그럴듯하지만 부정확한 세부사항을 생성하게 만든다. 법 집행, 의료 진단, 컴플라이언스 감사처럼 단일 사실의 누락이 결론을 뒤집는 영역에서 이 실패 양상은 단순한 품질 저하가 아니라 시스템적 위험이다.
2. 패러다임 전환: 답을 생성하기에서 질문을 형식화하기로
Expert emulation 접근은 질문-답변 시스템에 대한 패러다임 전환에서 출발한다. 초점은 답변을 생성하는 것에서 올바른 질문을 던지는 것으로 이동한다. 자연어 질문을 KG에 직접 실행 가능한 formal query로 변환하는 것이 핵심 과제가 된다.
이 전환의 의미는 다음과 같다. 쿼리는 본질적으로 KG의 구조와 상호작용하도록 설계된 formal question이다. 정확하고 사실에 기반한 데이터 retrieval은 이 형식화의 품질에 의해 보장된다. LLM은 더 이상 "답을 아는 존재"로 동원되지 않으며, "전문가가 질문을 어떻게 구조화하는지를 모방하는 존재"로 재정의된다.

이 4단계 파이프라인 — Intent Detection, Schema-to-LLM 변환, Reasoning-First Query Generation, Summarization — 이 expert emulation의 골격이다. 각 단계는 전문가가 질문을 받았을 때 실제로 수행하는 인지 과정의 분해이며, LLM은 이 분해된 작업 각각을 수행하도록 prompt engineering된다.
3. Intent Detection: 질문의 유형 분류
전문가가 만족스러운 답변을 제공하기 위해 가장 먼저 수행하는 작업은 질문의 의도를 파악하는 것이다. 같은 단어로 표현된 질문이라도 사용자가 원하는 결과 형태(목록인가, 단일 사실인가, 추세인가, 시각화인가)에 따라 다른 파이프라인이 동원되어야 한다.
이 분류 단계는 semantic understanding에 의존하며, 이는 LLM이 가장 잘 수행하는 작업 중 하나다. 좋은 classification prompt는 다음 요소를 모두 갖추어야 한다.
| 요소 | 역할 |
|---|---|
| Clear instructions | 분류 작업의 목적과 출력 형식 명시 |
| Defined categories | 카테고리 정의와 범위 |
| Examples | 각 카테고리의 대표 예시 |
| Boundary cases | 카테고리 경계의 모호한 예시 |
| Expected output format | 파싱 가능한 출력 구조 |
| Fallback options | 분류 불가 시 동작 (catch-all class) |
boundary 근처의 예시를 의도적으로 포함하면 모델이 카테고리 간 뉘앙스를 학습한다. 가장 효과적인 boundary 샘플은 운영 중 발생한 misclassification 사례에서 추출된다. 또한 fallback 카테고리를 두지 않으면 모델이 분류를 강제로 수행하게 되어 오분류 비율이 증가한다.
Single-stage vs Multi-stage 트레이드오프
| 항목 | Single broad prompt | Multistage classification |
|---|---|---|
| 관리 복잡도 | 낮음 | 높음 |
| 정확도 | 카테고리 수 증가 시 저하 | 단계별 정밀도 향상 가능 |
| 유연성 | 카테고리 조정 시 전체 재검토 | 단계별 독립 조정 |
| 적합 상황 | 초기 단계, 카테고리 수 적음 | 카테고리 빈번 조정, 높은 정확도 요구 |
초기 단계에서는 single broad prompt로 시작하여 실제 사용 데이터를 수집하고, 분할이 필요한 시점이 명확해진 후 multistage로 전환하는 점진적 접근이 권장된다.
4. Schema-to-LLM 변환: Technical에서 Conceptual로
자연어를 Cypher로 변환하려면 LLM이 KG의 구조를 이해해야 한다. 그러나 Neo4j가 자동 생성하는 technical schema를 그대로 프롬프트에 주입하는 것은 비효율적이다. technical schema는 구현 특화 요소, 중복 라벨, 메타데이터를 포함하며 이들 중 다수는 도메인 질문 답변에 무관하다.
conceptual schema는 technical schema의 distilled subset이다. 도메인의 본질적 모델을 전달하는 엔티티와 관계만 남기고, 기술적 복잡성과 무관한 메타데이터를 제거한 표현이다.
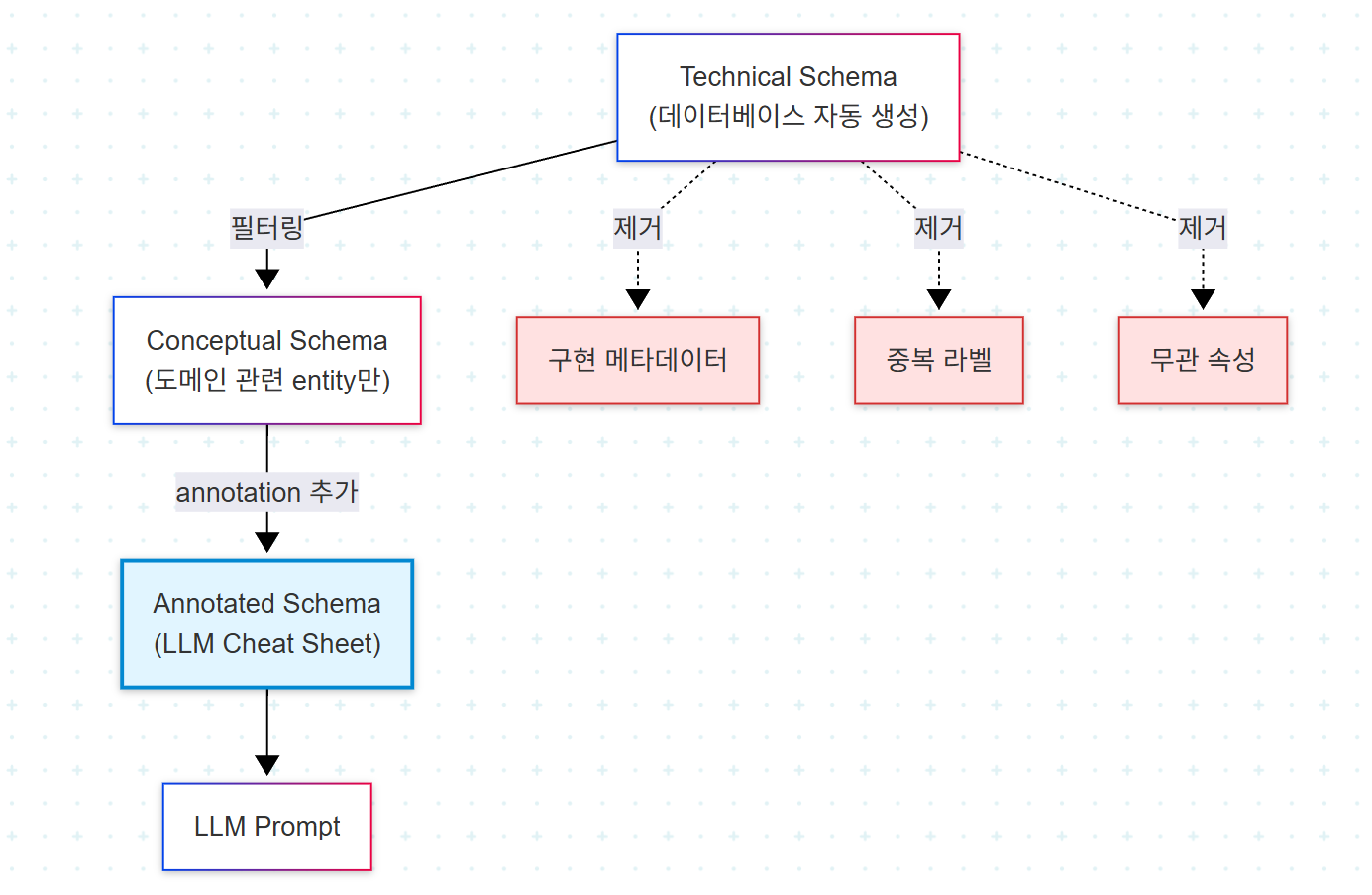
LLM은 focused, relevant data를 받을 때 더 효율적으로 작동한다. 전체 technical database schema의 복잡한 구조는 모델을 혼란시켜 잘못된 쿼리 생성으로 이어질 수 있다.
Schema Annotations: Cheat Sheet 생성
낯선 데이터를 다루는 전문가는 KG 구조에 익숙해지기 위해 문서와 data dictionary를 참조한다. 이 과정에서 용어, 약어, 관계의 의미를 정리한 일종의 cheat sheet를 만든다. 이 cheat sheet 생성 과정은 schema annotation으로 시스템화된다. 노드 클래스, 관계 타입, 속성에 자연어 설명을 체계적으로 부착하면, annotated schema는 LLM에게 더 정확한 쿼리 변환을 가능하게 하는 가이드가 된다.
# Conceptual + Annotated Schema 예시
nodes:
Person:
description: "범죄 사건의 관계자(피해자, 용의자, 증인 등)"
properties:
role: "사건 내 역할. 가능 값: victim, suspect, witness"
relationships:
WITNESSED:
description: "Person이 특정 Event를 목격함"
domain: Person
range: Event
properties:
reliability: "증언의 신뢰도. 0.0-1.0 범위"5. Reasoning-First Query Generation: "Time to Think"
복잡하거나 미묘한 질문을 받았을 때, LLM은 데이터 패턴의 shortcut에 의존하여 결론을 서두를 수 있다. 이 문제를 해결하는 표준 기법이 chain-of-thought prompting과 scratchpad 기법이다. 두 접근 모두 모델에게 "time to think"를 부여하는 것이 목적이며, 최종 출력 생성 이전에 더 많은 computational resource를 문제 해결 과정에 투입하도록 유도한다.
Order Matters: Reasoning이 Answer보다 먼저 와야 하는 이유
가장 중요한 통찰은 답변과 추론의 출력 순서가 결과 품질을 결정적으로 좌우한다는 점이다.
LLM은 한 번에 하나의 토큰을 생성하며, 이전 토큰의 선택에 효과적으로 commit한다. LLM이 답을 먼저 제공하고 그 다음 추론을 작성하도록 지시받으면, 모델은 처음 생성한 답에 그대로 고정될 수 있다. 모델이 학습한 텍스트 코퍼스는 일정 수준의 logical coherence와 internal consistency를 보이기 때문에, 일단 답이 정해진 후 생성되는 추론은 사후 정당화(post-hoc justification)에 해당한다.
| 출력 순서 | 결과 양상 |
|---|---|
| Answer → Reasoning | 사전 결정된 답에 맞춘 정당화. 토큰 누적으로 초기 오류가 전파됨 |
| Reasoning → Answer | 단계별 추론이 누적되어 최종 답에 영향. 투명하고 검증 가능한 사고 흐름 |
토큰이 순차적으로 생성되면서 reasoning과 context는 누적적으로 쌓인다. 초기 단계에서 오류가 발생하면, 이후 토큰이 그 오류 위에 추가로 생성되면서 오류가 전파된다. 따라서 step-by-step reasoning을 먼저 출력하게 한 후 최종 답변을 생성하도록 prompt를 설계해야 한다.
다만 예외가 있다. 분류(classification) 태스크에서는 답을 먼저 생성한 후 그 선택의 근거를 제시하게 하는 편이 합리적일 수 있다. 분류 시스템이 어떤 근거로 그렇게 선택했는지, 특히 오분류 시 어떤 논리로 잘못된 결론에 도달했는지를 사후 분석하는 것이 목적이기 때문이다.
Prompt 구조와 Hallucination 방지
쿼리 생성 prompt에는 다음과 같은 구조적 장치가 도입된다.
<schema>
... conceptual schema with annotations ...
</schema>
<instructions>
1. 먼저 질문에 답하기 위해 traverse해야 할 관계들을 모두 나열하세요.
2. 각 관계가 schema에 존재하는지 확인하세요.
3. step-by-step reasoning을 작성하세요.
4. 최종 Cypher 쿼리를 생성하세요.
</instructions>
<question>
{user_question}
</question>
<previous_error>
{optional: 이전 시도의 실패 메시지}
</previous_error>
질문 재확인: {user_question}HTML-like 태그로 사용자 질문을 감싸는 것은 모델이 질문의 경계를 명확히 인식하도록 돕는다. 또한 instruction prompt 끝부분에서 질문을 한 번 더 반복하면 context와 intent가 강화된다. 언어 모델이 본질적으로 local context를 global context보다 우선시하지는 않지만, 특정 작업에서 가까이 있는 토큰이 더 관련성이 높다고 학습하면 그 가중치를 부여하게 된다.
<previous_error> 필드는 재시도 메커니즘의 핵심이다. 데이터베이스가 반환한 에러 메시지를 다음 시도의 입력으로 주입하면, 모델은 이전 결정을 검토하고 오류 없는 쿼리를 생성할 수 있다.
Hallucination 방지의 가장 효과적인 기법 중 하나는 모델에게 traverse하려는 관계를 "out loud" 나열하게 하는 것이다. 모델이 schema에 존재하지 않는 관계를 환각으로 만들어내는 경우가 있는데, 사용할 관계를 명시적으로 나열하는 단계를 거치면 이 유형의 hallucination이 크게 감소한다.
6. Summarization: 데이터와 사용자 이해의 간극
Summarization 단계는 파이프라인에서 독특한 위치를 차지한다. 사용자가 찾고 있는 실제 데이터에 접근하는 최초이자 유일한 컴포넌트다. 이 단계는 raw data와 사용자 이해 사이의 간극을 메우는 역할을 한다.
핵심 설계 원칙은 다음과 같다. 결과 표시는 시각적 그래프 표현과 텍스트 summary의 dual nature를 가진다. graph visualization은 관계와 구조를 보여주는 데 탁월하지만, 가치 있는 정보는 종종 노드 속성이나 결과의 더 넓은 맥락에 존재한다. summary는 시각화를 반복하지 않고 보완해야 한다.
| 영역 | Graph Visualization | Text Summarization |
|---|---|---|
| 강점 | 관계·구조의 직관적 표현 | 속성·집계·트렌드 전달 |
| 약점 | 속성 세부의 표현 어려움 | 관계 토폴로지 전달 어려움 |
| 역할 분담 | 구조를 보여줌 | 시각적으로 드러나지 않는 패턴 강조 |
또한 summarization은 사용자 의도에 묶여 있어야 한다. 요청되지 않은 인사이트를 생성하면 사용자 경험이 산만해진다. 효과적인 summary는 시각적으로 즉시 명백하지 않은 인사이트와 패턴을 강조하는 데 집중한다.
7. Expert Emulation 전체 프레임워크
여러 컴포넌트를 통합하면 expert emulation 프레임워크는 다음 pillars 위에 구축된다.
- 사용자 질문 유형의 이해와 적절한 라우팅 (Intent Detection)
- LLM이 효과적으로 사용할 수 있는 형태로 도메인 지식을 추출·표현 (Conceptual Schema + Annotations)
- 쿼리 구성에 대한 전문가의 추론 패턴 구현 (Reasoning-First Generation)
- 결과를 의미 있고 actionable한 방식으로 제시 (Summarization)
이 프레임워크의 적용 범위는 KG 질의에 국한되지 않는다. 전문가 지식을 복잡한 데이터 구조에 체계적으로 적용해야 하는 모든 도메인으로 일반화 가능한 원칙이다.
8. 정리
이 챕터의 핵심은 RAG의 한계를 인식하고 expert emulation 패러다임으로 전환하는 것이다. "어떤 도전 과제든 전문가라면 어떻게 할 것인가"를 묻고, 그 접근을 구현 가능한 단계로 분해하는 것이 시스템 설계 원칙이 된다. KG 시스템에서 이 원칙은 4단계 파이프라인으로 구체화된다.
- Intent Detection: 질문 유형 분류로 적절한 처리 경로 선택
- Schema-to-LLM 변환: technical schema를 conceptual + annotated schema로 정제
- Reasoning-First Query Generation: time to think를 부여하여 사후 정당화 방지
- Summarization: 시각화와 보완 관계를 유지하며 사용자 의도에 묶인 인사이트 제공
Prompt engineering의 본질은 LLM에 time to think를 주는 것이며, technical schema를 LLM-friendly 포맷으로 변환하는 작업은 불필요한 요소 제거, contextual annotation 추가, LLM의 처리 방식과 align되는 구조화의 결합이다.
결론: 자연어 KG 질의의 핵심은 답을 생성하는 것이 아니라 올바른 질문을 형식화하는 것이며, 이는 expert emulation을 통해 구현된다.
참고 자료
- Knowledge Graphs and LLMs in Action. Manning, 2024 — Chapter 14: KG questions with natural language.
