이번 글의 thesis는 다음과 같다. 그래프 ML의 성공은 vectorization의 품질에 달려 있으며, 그 품질은 해석가능성과 자동화 사이의 의식적 trade-off로 결정된다. Manual feature engineering, semiautomated 접근(ReFeX), fully automated 표현 학습(GNN)은 동일 스펙트럼의 세 지점이지, 우열을 가릴 대상이 아니다. 어느 지점을 선택할지는 도메인의 설명가능성 요구, 데이터 규모, 컴퓨팅 자원, 도메인 전문성에 따라 달라진다.
그래프 ML의 근본 도전은 다음과 같이 압축된다 — 그래프 요소(노드, 관계, 전체 그래프)를 ML 알고리즘이 처리할 수 있는 벡터로 효과적으로 표현하는 방법. 이 표현 단계는 vectorization 또는 featurization으로 불리며, 모델이 얼마나 잘 학습하고 예측할 수 있는지를 결정한다.
1. Feature Engineering의 Spectrum
ML 알고리즘은 그래프 구조를 직접 처리할 수 없다. 대신 수치 입력 벡터를 요구한다. 이 벡터의 품질은 다운스트림 작업의 성능에 직접적인 영향을 미친다.
vectorization을 구현하는 방식은 자동화 정도에 따라 스펙트럼을 이룬다.
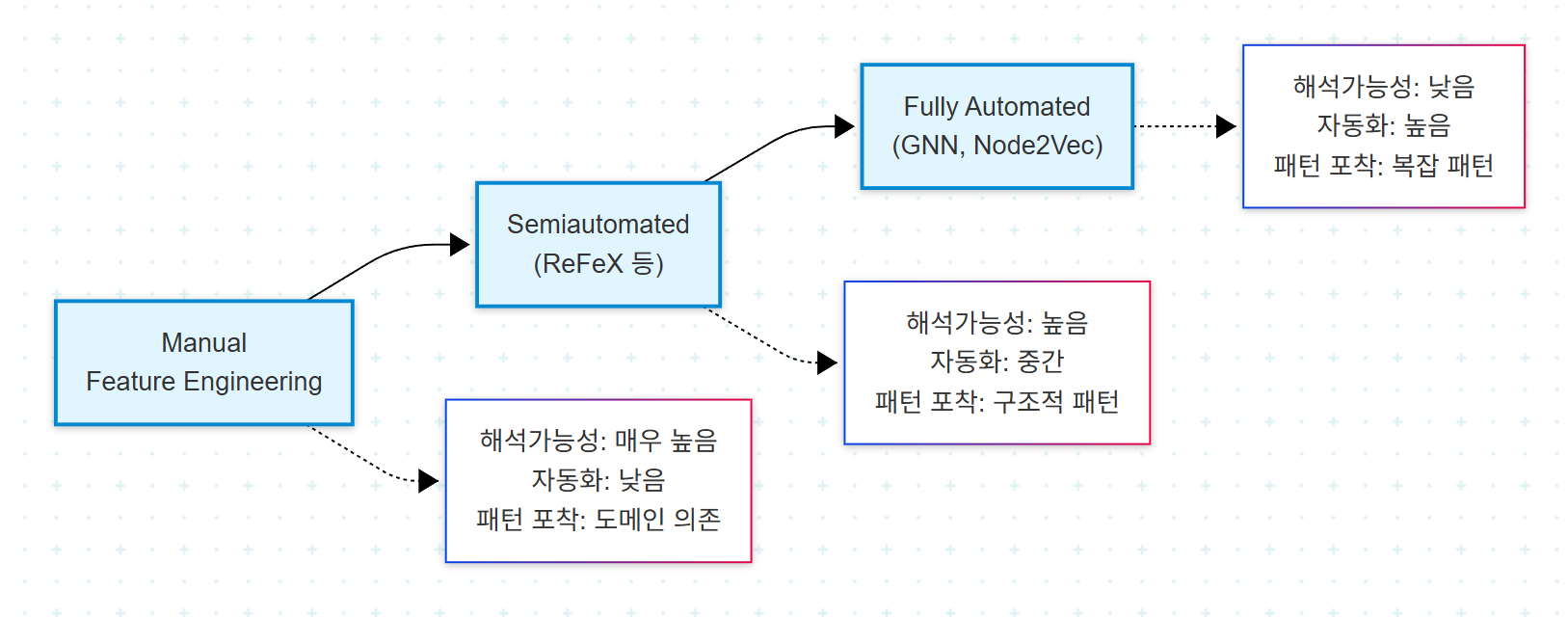
| 접근 | 해석가능성 | 자동화 | 패턴 포착력 | 핵심 트레이드오프 |
|---|---|---|---|---|
| Manual | 매우 높음 | 낮음 | 도메인 지식 의존 | labor-intensive |
| Semiautomated | 높음 | 중간 | 구조적 패턴에 한정 | 도메인 지식 통합 어려움 |
| Fully Automated | 낮음 | 높음 | 복잡 패턴 포착 가능 | black-box |
핵심 명제는 다음과 같다. 자동화가 진행될수록 해석가능성은 감소한다. Manual feature는 매우 해석 가능하지만 만드는 데 노동 집약적이고, semiautomated feature는 해석가능성과 효율 사이의 균형을 이루며, fully automated feature는 생성에는 효율적이지만 해석이 어렵다.
2. Manual Feature Engineering이 여전히 가치 있는 이유
자동화된 표현 학습이 발전한 시대에도 manual feature engineering은 두 가지 핵심 이유로 여전히 가치 있다.
첫째, 인간이 이해하고 검증할 수 있는 해석 가능한 features를 생산한다. 금융 사기 탐지, 의료 진단처럼 의사결정의 근거를 설명해야 하는 도메인에서 이는 단순한 편의가 아니라 규제 요건이다.
둘째, 무엇이 그래프 표현을 효과적으로 만드는지에 대한 통찰을 제공하며, 자동화된 접근의 설계에 정보를 준다. GNN을 설계하더라도, manual feature에 대한 이해는 어떤 구조적 패턴이 의미 있는지에 대한 사전 지식을 제공한다.
추가로 한 가지 결정적 장점이 있다 — LLM과의 호환성이다. 수동으로 추출된 features는 그래프에 대한 자율적 추론을 위한 LLM과 호환된다. 이 features는 잘 이해된 그래프 알고리즘과 속성에 기반하기 때문에, LLM이 효과적으로 이를 해석하고 추론할 수 있다. GraphRAG 시스템에서 LLM이 그래프 분석 결과를 자연어로 설명해야 할 때, manual feature는 그 자체로 의미를 가진 토큰의 집합이 된다.
3. Manual Node Features: 7대 카테고리
Manual node feature는 노드의 영향 범위에 따라 두 그룹으로 나뉜다.
| 그룹 | 정의 | 대표 features |
|---|---|---|
| Local features | 노드의 one-hop neighborhood 또는 ego-centered network(egonet) 고려 | degree, triangles, density |
| Global features | 전체 네트워크 또는 그 큰 부분에서 노드의 역할 측정 | geodesic, closeness, betweenness, PageRank |
egonet은 특정 노드와 그 직접 이웃들로 구성된다. egonet의 중심은 ego이고, 주변 노드들은 alter라고 불린다. global features에는 betweenness centrality, closeness centrality, PageRank, Eigenvector centrality 같은 centrality 지표들이 속한다. 이 측정들은 네트워크 내 노드의 영향력과 노드가 다른 노드들에 의해 어떻게 영향받을 수 있는지를 포착한다.
Local Features
Degree. 노드의 degree는 그 노드가 몇 개의 이웃을 가지는지를 나타낸다. in-degree, out-degree와 함께 global degree는 노드의 직접 연결에 대한 더 나은 표현을 제공한다.
Triangles. 그래프 이론에서 triangle은 세 노드가 모두 연결된 서브그래프다. 노드의 egonet에 triangle이 존재한다는 것은 대상 노드가 그 이웃들과 강한 연결을 가지고 있다는 표시다. 직관적으로, 가까운 사람들을 생각해보면 — 친구들은 아마 서로도 친구일 것이다. Triangle은 밀접하게 연결된 개인들의 그룹이 가진 영향력을 드러낸다.
Density. Density는 그래프의 노드들이 얼마나 연결되어 있는지를 측정한다. egonet 내의 density는 이웃들이 서로 얼마나 영향을 주고받을 수 있는지를 나타낸다.
Global Features
Geodesic / Shortest Path. geodesic path 또는 shortest path는 두 노드 간의 최소 거리를 나타낸다. 두 노드 간에 더 많은 경로가 존재하고 그 경로들이 짧다면, 사기 행동이 대상 노드에 영향을 미칠 가능성이 더 높다. 다만 geodesic path 계산은 computationally expensive하다. Dijkstra 알고리즘은 가장 작은 tentative distance를 가진 미방문 노드를 반복적으로 선택함으로써 그래프 내 노드 간의 최단 경로를 찾는다.
Closeness Centrality. 노드가 다른 모든 노드들과 얼마나 "가까운지"를 나타낸다. 네트워크 내 노드에서 다른 모든 노드까지의 평균 거리를 측정한다. 더 낮은 g(vi) 값은 노드가 일반적으로 네트워크의 다른 노드들에 더 가깝다는 것을 나타낸다.
사기 탐지 도메인의 직관적 해석은 이렇다. 사기 노드가 g(vi)에 대해 낮은 값을 가질 때, 사기는 네트워크를 통해 쉽게 퍼지고 다른 노드들을 더 빠르게 오염시킬 수 있다. closeness centrality는 farness의 역수다 — 네트워크에서 더 중심에 있는 노드에 더 높은 값을 할당하기 때문이다.
주의할 점은 closeness centrality가 노드에 대해 계산될 때, 전체 네트워크를 사용하지 않는다는 것이다. 그 노드에서 도달 가능한 네트워크의 부분만 사용한다. 따라서 disconnected component가 있는 그래프에서는 다른 component의 노드와의 거리는 계산에 포함되지 않는다.
Betweenness Centrality. closeness가 노드가 다른 노드들에 얼마나 빠르게 도달할 수 있는지를 측정하는 반면, betweenness는 노드가 다른 노드들 사이의 다리(bridge) 역할을 얼마나 자주 하는지를 측정한다. 구체적으로, 다른 노드 쌍들 사이의 최단 경로에 노드가 나타나는 횟수를 정량화한다.
네트워크에서 어떤 노드 쌍이든, 정보나 영향력은 그들 사이의 최단 경로를 따라 흐를 가능성이 높다. 특정 노드가 이 최단 경로들에 빈번하게 나타난다면, 그 노드는 높은 betweenness centrality를 가지며 따라서 많은 다른 노드들 간의 정보 흐름을 잠재적으로 제어한다. 1에 가까운 값은 노드가 많은 최단 경로에 나타나며 따라서 정보 흐름을 제어할 잠재력이 높음을 나타낸다.
Closeness vs Betweenness 핵심 차이
| Metric | 측정 대상 | 핵심 질문 | 사기 탐지 직관 |
|---|---|---|---|
| Closeness | 다른 노드들과의 평균 거리 | "얼마나 빨리 도달 가능한가?" | 사기가 퍼지는 속도 |
| Betweenness | 최단 경로 위에 등장 빈도 | "얼마나 자주 bridge 역할을 하는가?" | 사기 자금이 통과하는 길목 |
4. PageRank의 고급 활용: Personalization
PageRank는 incoming connection의 구조에 기반하여 노드의 중요도를 측정하는 강력한 metric이다. 더 단순한 centrality 측정과 달리, PageRank는 연결의 양뿐 아니라 품질도 고려한다 — 다른 높은 순위 노드에 연결된 노드는 더 높은 PageRank 점수를 받는다.
이 챕터의 핵심 통찰은 PageRank를 두 가지 방식으로 적응시키는 것이다.
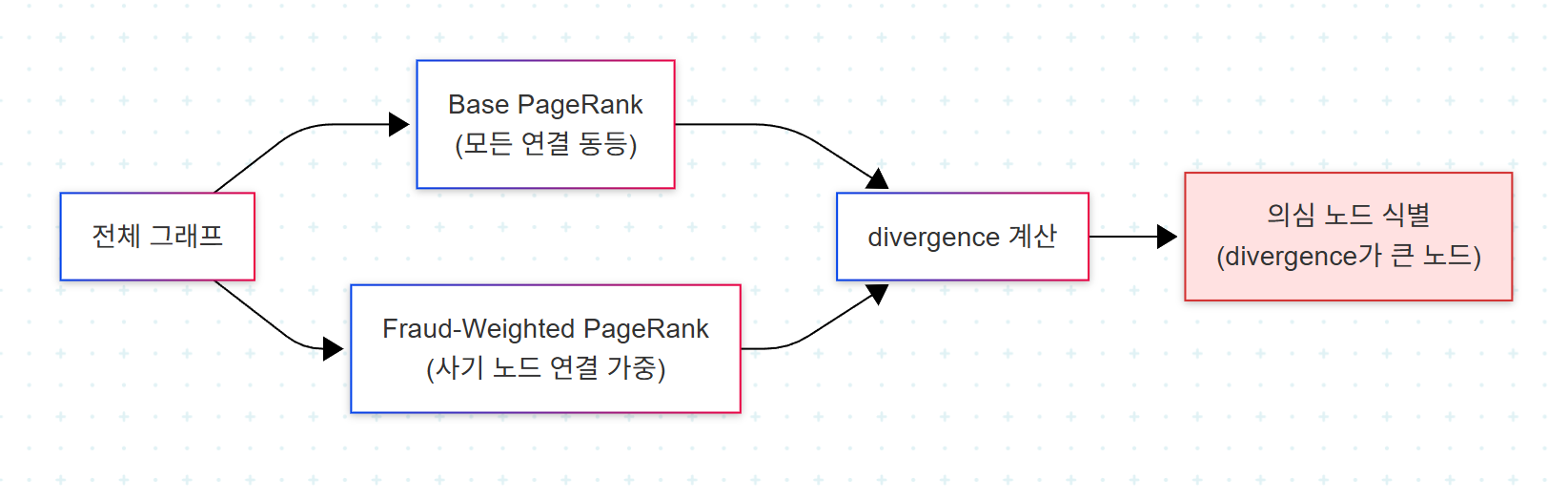
먼저 모든 연결을 동등하게 고려하는 base PageRank를 계산한다. 그 다음 알려진 사기 노드로부터의 연결이 더 큰 가중치를 갖는 fraud-weighted PageRank를 계산한다. base PageRank와 fraud-weighted PageRank 사이의 이 divergence는 가치 있는 통찰을 제공할 수 있다.
base PageRank와 비교하여 fraud-weighted PageRank에서 유의미한 증가를 보이는 노드는 더 면밀한 조사를 요할 수 있다. 직관은 명확하다 — 일반적 관점에서는 평범해 보이지만 사기 네트워크의 관점에서는 중요한 위치에 있는 노드, 그것이 잠재적 협력자다.
이 패턴은 PageRank의 personalization vector 기능을 활용한 것이며, 의료(특정 질병과 가까운 약물 식별), 추천(특정 사용자 그룹의 관점에서 본 영향력) 등 다양한 도메인으로 일반화된다.
5. Manual Engineering의 운영 특성
manual feature engineering의 프로세스는 반복적이어야 한다. features는 분류기가 충분하다고 느낄 만한 예측 품질에 도달할 때까지 변경되고 증가될 수 있다.
이 접근의 운영적 장점은 다음과 같다.
- 프로세스가 복잡하고 광범위한 feature 설계와 신중한 고려를 요구했음에도 불구하고, 완전히 자신의 통제 하에 있다
- 각 추출된 feature는 그래프를 보는 것만으로 쉽게 설명될 수 있다
- 이는 프로세스의 투명성을 증가시킨다 — 데이터베이스 크기가 제한적이거나 설명가능성이 중요한 경우 이 방법이 유효한 이유다
GraphRAG #9의 실험이 보여준 것처럼, 단순한 degree-based feature가 실패할 때 그 실패의 양상 자체가 다음 단계의 feature 설계 방향을 알려준다. manual engineering의 가치는 단지 모델 성능이 아니라, 이 진단 가능성과 통제력에 있다.
6. Relationship Representation: Link Prediction의 본질
지금까지 다룬 features는 모두 노드에 대한 것이다. 그러나 link prediction은 본질적으로 다른 종류의 representation을 요구한다.
두 단백질이 상호작용할지, 고객이 특정 상품에 관심을 가질지, 약물이 질병을 치료할 수 있을지를 예측하든, 본질적으로 우리는 동일한 질문을 던지고 있다 — 두 노드가 주어졌을 때, 그들 사이에 관계가 존재할 가능성은 얼마나 되는가? 개별 노드를 표현하는 대신, 노드 간 잠재적 연결의 특성을 포착해야 한다.
이는 두 가지 분류 작업으로 접근할 수 있다.
| 작업 유형 | 출력 |
|---|---|
| Binary classification | 관계 존재 여부 |
| Multiclass classification | 관계의 유형 |
두 가지 접근법
관계를 표현하는 방법은 크게 두 가지로 나뉜다.
Node-based combination. source와 target 노드의 feature 벡터를 결합하여 관계 표현을 도출한다.
Path-based features. 노드 feature에 의존하는 대신, 그래프 내 노드들이 연결된 방식을 분석하여 관계를 특성화한다. 각 feature는 두 노드 간의 특정 path 패턴을 나타낸다 — 예를 들어 two-hop path의 수, 또는 특정 metapath의 존재.
| 접근 | 장점 | 적합 상황 |
|---|---|---|
| Node-based combination | node embedding과 잘 작동 | 단순한 관계 예측 |
| Path-based features | 복잡한 네트워크 패턴 포착에 탁월 | 복잡한 메타 구조 (예: 약물-질병) |
7. Vector Combination Operators
Node-based combination을 사용할 때, 두 노드 벡터를 결합하는 연산자의 선택이 결과에 영향을 미친다.
| Operator | 공식 | 출력 차원 | 특성 |
|---|---|---|---|
| Catenate | 두 벡터를 끝에서 끝으로 연결. 원본 정보 모두 보존하지만 차원이 두 배가 됨 | ||
| Average | 원래 차원 유지, 두 벡터 간 central tendency 포착 | ||
| L1 | 각 차원에서 벡터들이 얼마나 다른지 포착, 비유사성 측정에 유용 | ||
| L2 | 벡터 간 차이 포착하지만 제곱 연산으로 큰 차이를 강조 | ||
| Hadamard | 원소별 곱. 두 벡터의 값이 곱셈적으로 결합되어야 할 관련 양을 나타낼 때 특히 유용 |
link prediction의 품질은 노드 표현의 품질에 직접적으로 의존한다. 또한 선택을 도울 generic rule이 없다 — 따라서 벤치마크가 자신의 시나리오에 어떤 접근이 적절한지에 대한 표시를 제공할 수 있다.
실무적으로는 Hadamard가 가장 흔한 기본 선택이다. 두 노드 임베딩이 같은 차원에서 함께 활성화될 때 그 차원을 강조하기 때문에, "공통된 잠재 속성"이 관계를 정의한다는 직관과 잘 맞는다.
8. Drug Repurposing과 Metapath: 도메인 특화 표현의 사례
manual representation 프로세스는 일반적으로 도메인 특화적이며, 우리가 달성하려는 목표와 도메인에 대한 이해를 요구한다. Hetionet 데이터셋을 사용한 drug repurposing이 이 원칙의 대표적 사례다.
연구자들은 우울증과 알코올 중독에 사용되는 기존 약물 중 흡연 중독과 간질 치료에 잠재력을 보이는 것들을 식별했다. 목표는 화합물과 질병의 네트워크 연결성을 치료 확률로 변환하는 ML 모델을 학습시키는 것이었다.
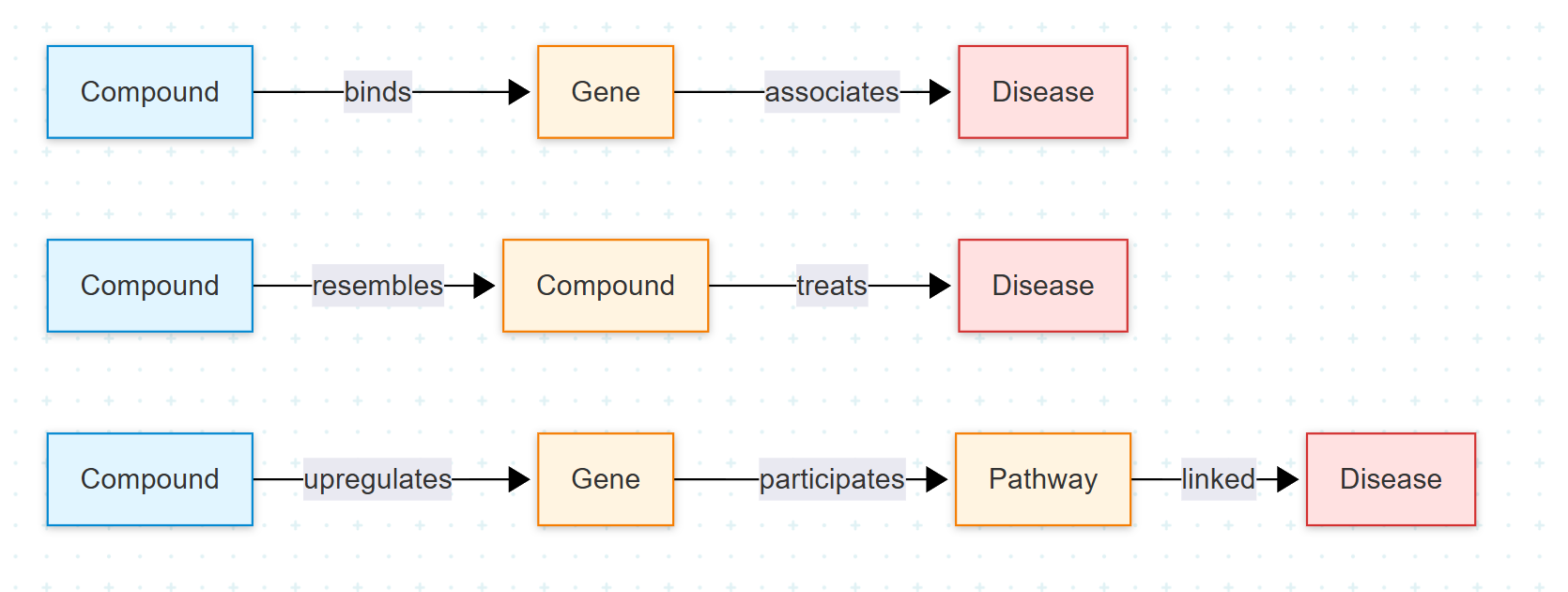
각 metapath는 화합물과 질병 사이의 가능한 경로의 부분집합을 나타낸다. 이들은 직접적 연결이 존재하든 아니든 각 화합물-질병 쌍에 대한 feature를 형성한다. 즉, "Compound→Gene→Disease" 같은 패턴 자체가 의미 있는 신호다.
9. DWPC: Path Counting의 핵심 문제 해결
화합물-질병 쌍을 metapath로 표현할 때 가장 단순한 접근은 화합물과 질병 사이의 distinct path instance를 카운팅하는 것이다. 그러나 단순히 경로를 카운팅하면, 매우 높은 연결성을 가진 노드들이 카운트를 지배할 때 오해를 불러일으킬 수 있다.
예를 들어, 한 유전자가 많은 생물학적 프로세스에 관여한다면, 그 유전자는 자연스럽게 더 많은 경로에 나타날 것이다. 그러나 이것이 반드시 화합물과 질병 사이의 더 강하거나 의미 있는 관계를 나타내는 것은 아니다. hub node가 결과를 지배하면 분석은 무의미해진다.
DWPC의 작동 원리
이 편향을 해결하기 위해 DWPC(degree-weighted path count) 가 사용된다. DWPC는 노드 degree에 기반한 damping factor를 적용한다.
| 방법 | 동작 | 문제점/장점 |
|---|---|---|
| Simple Path Count | 경로 수만 카운팅 | hub node가 결과 지배 |
| DWPC | 중간 노드 degree에 반비례 가중 | hub의 영향 완화, 특정적·집중적 경로 강조 |
각 path는 중간 노드의 degree에 반비례하여 가중된다. 많은 연결을 가진 노드는 최종 점수에 적게 기여한다. damping 효과는 더 특정적이고 집중된 생물학적 경로를 강조하는 데 도움이 된다.
여기서 는 damping exponent (일반적으로 0.4~0.5)다. 이 접근은 생물학적 네트워크에서 hub 노드로부터의 노이즈를 줄이면서 의미 있는 치료적 관계를 식별하는 데 도움이 되기 때문에, drug repurposing에서 특히 효과적임이 입증되었다.
Feature Reduction의 필요성
모든 잠재적 metapath에 걸쳐 모든 가능한 화합물-질병 쌍에 대한 DWPC 값을 계산하는 것은 computationally expensive하며 noisy하거나 misleading한 결과로 이어질 수 있다. 이를 위해 두 단계의 reduction이 적용된다.
| 단계 | 방법 |
|---|---|
| Metapath reduction | 알려진 treatment vs non-treatment 관계에서의 빈도 분석으로 가장 유의미한 metapath 식별 |
| Pair selection | 도메인 지식과 degree 기반 확률 분석으로 가장 유망한 화합물-질병 쌍 식별 |
10. ReFeX: Semiautomated 접근의 정수
Manual feature engineering의 장점 — 해석가능성, 신뢰성, 예측가능성 — 을 유지하면서 feature 선택 프로세스의 대부분을 자동화할 수 있다면 어떨까? 이 질문에 대한 답이 ReFeX(Recursive Feature eXtraction) 이다.
ReFeX는 fully manual feature engineering과 복잡한 신경망 접근 사이의 중간 지대를 제공한다. ReFeX는 그래프에서 관련 구조적 features를 자동으로 식별하고 추출한다. black-box 신경망 접근과 달리, ReFeX의 프로세스는 투명하며 도메인 전문가가 이해하고 검증할 수 있는 해석 가능한 features를 생산한다. 이 투명성은 특정 예측이 왜 이루어졌는지 설명해야 할 때 특히 가치 있다.
ReFeX의 차별화된 특성
ReFeX가 생성하는 features는 서로 다른 네트워크 간, 심지어 동일 네트워크의 서로 다른 시간 스냅샷 간에 의미 있게 비교될 수 있다 — 더 복잡한 신경망 접근으로는 거의 불가능한 것이다. 이 속성은 그래프 구조가 어떻게 진화하는지 추적하거나 서로 다른 네트워크 간 패턴을 비교해야 하는 응용에서 ReFeX를 특히 가치 있게 만든다.
핵심 설계 원칙 2가지
| 원칙 | 의미 |
|---|---|
| Structural | feature matrix F의 구성은 노드나 link에 대한 추가 속성 정보를 요구하지 않아야 함 |
| Effective | 좋은 노드 feature는 (1) 가용 시 노드 속성 예측을 돕고 (2) 그래프 간 전이 가능해야 함 |
이 원칙들은 ReFeX의 핵심 철학과 연결된다.
"서로 다른 그래프 간 마이닝에서 중요한 것은 누구를 아는가, 또는 누구와 관련되는가이다."
즉, 노드의 identity가 아니라 어떤 종류의 노드와 연결되어 있는가가 핵심이라는 관점이다.
작동 원리
ReFeX는 그래프 구조의 순수한 구조적 측면 — 노드와 관계 — 위에서 작동하며, 노드 라벨이나 타입을 고려하지 않는다. topology에 대한 이 초점은 알고리즘이 구조적 패턴을 식별할 수 있게 해준다.
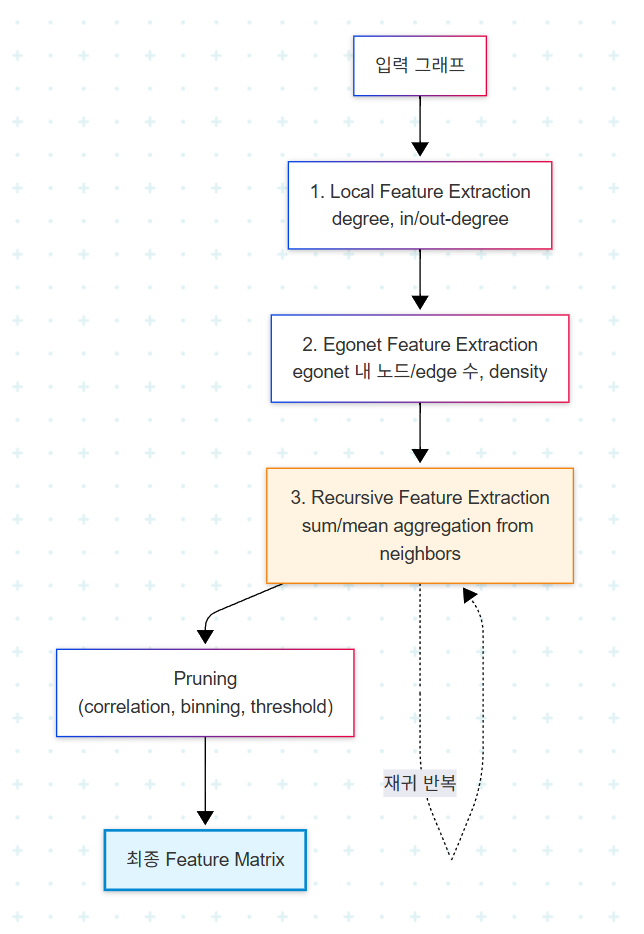
Recursive feature extraction은 summary statistics의 재귀적 적용을 통해 기존 features를 집계한다. 이 프로세스는 점점 더 복잡한 구조적 패턴을 포착하기 위해 aggregation function(sum/mean)의 조합을 사용한다. 알고리즘의 재귀적 특성은 지수적으로 증가하는 수의 features를 생성할 수 있다.
Pruning 기법
지수적 증가를 통제하기 위해 세 가지 pruning 기법이 적용된다.
| 기법 | 동작 |
|---|---|
| Correlation analysis | 높게 상관된 feature 쌍 식별 및 제거 |
| Logarithmic binning | feature 값을 효율적 비교를 위해 이산 구간으로 매핑 |
| Threshold-based pruning | 지정된 임계값보다 적게 차이나는 features 제거 |
ReFeX의 4대 장점
| 장점 | 의미 |
|---|---|
| Efficiency | 재귀적 구조 features의 자동 추출 |
| Consistency | feature 생성의 systematic한 접근 |
| Interpretability | 명확한 구조적 의미를 유지하는 생성된 features |
| Scalability | feature 품질을 유지하면서 더 큰 그래프를 처리할 수 있는 능력 |
ReFeX의 위치와 한계
ReFeX는 manual feature engineering과 fully autonomous representation learning 기법 사이의 중요한 중간 지대를 차지하는, 자동화된 feature 추출을 향한 유의미한 진전을 나타낸다. 순수한 그래프 구조에 대한 그것의 초점은 더 복잡한 접근을 이해하기 위한 훌륭한 기초를 제공한다.
운영 관점에서 ReFeX의 결정적 장점은 다음과 같다.
- 단계별로 추적되고 검증될 수 있다 — feature engineering 프로세스를 이해하고 검증해야 하는 실무자에게 매우 가치 있는 도구
- deterministic 특성이 일관성을 보장한다 — 동일한 입력은 항상 동일한 출력을 생성
- 이 예측가능성은 재현성이 필수적인 운영 환경에서 특히 가치 있음
- 그래프 구조가 변경되면, ReFeX는 전체 feature matrix의 재생성을 요구하는 대신 영향받은 features의 선택적 재계산을 허용한다
다만 ReFeX의 본질적 한계도 명확하다. 구조적 features에 대한 의존은 노드 속성이나 edge 유형을 직접적으로 통합할 수 없음을 의미한다. 노드의 의미적 속성이 결정적 신호인 도메인(예: 사용자의 demographic 정보가 중요한 추천 시스템)에서는 ReFeX만으로는 충분하지 않다.
11. LLM을 활용한 Feature Engineering
새로운 가능성으로 LLM을 활용한 feature engineering 자동화가 부상하고 있다. LLM은 복잡한 패턴을 이해하고 그것을 실행 가능한 코드로 번역하는 작업에 탁월하다. 이는 그래프 데이터베이스와 작업할 때 특히 가치 있는데, 쿼리 작성이 종종 도메인과 쿼리 언어 양쪽 모두에 대한 깊은 이해를 요구하기 때문이다.
LLM은 도메인 전문가가 "사기 노드 주변의 비정상적 거래 패턴을 포착하는 feature를 만들어줘" 같은 자연어 요구사항을 받아서, Cypher 쿼리와 후처리 코드의 조합으로 변환할 수 있다. 이는 manual feature engineering의 해석가능성을 유지하면서 그 노동 집약성을 완화하는 방향이다.
12. 정리
이 챕터의 핵심은 다음과 같이 압축된다.
- 그래프 ML의 manual과 semimanual feature engineering은 ML 작업을 위한 기초를 제공하며, 해석가능성과 자동화 사이의 균형을 이룬다.
- Manual feature engineering은 local metrics와 global measures를 결합하여 즉각적 연결과 더 넓은 네트워크 패턴 양쪽을 포착하는 의미 있는 노드 표현을 생성한다.
- DWPC는 노드 degree를 고려하면서 연결 관련성을 측정하는 sophisticated한 접근을 제공한다.
- Manual과 semiautomated 접근 사이의 선택은 해석가능성 요구, 컴퓨팅 자원, 가용한 도메인 전문성에 의존한다.
Feature engineering의 스펙트럼 — Manual → Semiautomated(ReFeX) → Fully Automated(GNN) — 위에서 각 지점은 고유한 가치를 갖는다. 7대 manual node feature(degree, triangles, density, geodesic, closeness, betweenness, PageRank), 5대 vector combination operator(catenate, average, L1, L2, Hadamard), path-based feature와 DWPC, 그리고 ReFeX의 recursive aggregation은 그래프 ML 실무자의 도구 상자를 구성하는 핵심 도구들이다.
결론: 그래프 feature engineering의 본질은 알고리즘 선택이 아니라 해석가능성과 자동화 사이의 트레이드오프를 의식적으로 설계하는 것이다.
참고 자료
- Knowledge Graphs and LLMs in Action. Manning, 2024 — Chapter 10: Graph feature engineering: Manual and semiautomated approaches.
