이전 편까지의 GraphRAG 시리즈는 지식 그래프를 "구성"하고 "탐색"하는 문제를 다뤘다. 텍스트로부터 entity를 추출하고, 관계를 정제하고, Cypher로 traversal하는 흐름이다. 그러나 그래프 위에서 ML 모델을 직접 학습시키려면 또 하나의 단계가 필요하다. 노드·엣지·subgraph를 vector 공간에 사상(寫像)하는 단계, 즉 graph representation learning(GRL)이다. 이 글의 thesis는 다음 한 문장으로 압축된다.
그래프의 정보를 vector로 옮기는 작업은 lookup table(shallow)에서 출발해 message passing(GNN)으로 진화했고, 이제 LLM과 결합되는 지점에서 GraphRAG의 다음 세대를 형성한다.
1. GRL이 풀려는 문제: 왜 임베딩인가
전통적인 그래프 분석은 PageRank, community detection처럼 사람이 설계한 알고리즘에 의존했다. 노드 분류, 링크 예측, 그래프 분류 같은 downstream task에 ML을 적용하려면 그래프를 vector로 변환해야 하는데, 그래프는 일반적인 tensor와 달리 노드마다 이웃 수와 구조가 다르다. 이 불규칙성이 일반 ML 기법의 직접 적용을 막는다.
GRL은 graph structure와 node attribute로부터 dense vector representation(embedding)을 자동 학습한다. 학습된 embedding은 그래프의 structural·semantic 성질을 보존하면서, 표준 ML 알고리즘이 그대로 소비할 수 있는 형태다. 이 변환이 성립하면 노드 분류, 클러스터링, 추천, 링크 예측이 모두 단일 representation 위에서 풀린다.
GRL의 발전은 세 세대로 정리된다. 1세대는 전통 수학·CS에서 출발한 graph embedding, 2세대는 word2vec의 충격을 그래프로 옮긴 Node2Vec 계열, 3세대는 deep learning과 결합한 GNN이다. 각 세대는 이전 세대의 한계를 직접 겨냥하면서 등장했다.
2. 임베딩 공간의 기하학: Euclidean과 그 너머
대부분의 ML 모델은 Euclidean space에서 작동한다. 직선 거리, 피타고라스 정리, 내적이 그대로 통한다. 그러나 그래프, 특히 계층적(hierarchical) 그래프는 이 공간에서 잘 표현되지 않는다. 예컨대 ontology, 분류 체계, citation network처럼 트리 구조에 가까운 그래프는 깊이가 깊어질수록 노드 수가 지수적으로 늘어나는데, Euclidean space에서는 이 폭발적 공간을 담을 자리가 부족하다.
이 지점에서 등장하는 것이 hyperbolic space다. Hyperbolic space는 중심에서 바깥으로 갈수록 사용 가능한 공간이 지수적으로 늘어난다. 트리가 한 단계 내려갈 때마다 가지가 더 벌어지는 구조와 자연스럽게 들어맞는다. 이런 관점을 일반화한 분야가 geometric deep learning(GDL)이다.
| 공간 | 거리 성질 | 적합한 그래프 |
|---|---|---|
| Euclidean | 직선 거리, 다항식적 공간 성장 | 평탄한 social network, 일반 그래프 |
| Hyperbolic | 지수적 공간 성장 | 계층적 구조, ontology, 분류 트리 |
| Spherical | 곡률 양수, 유한한 표면 | 주기적/순환적 관계 |
3. 위치 vs 구조: 임베딩이 보존하는 것
두 노드가 "비슷하다"는 말은 한 가지 의미가 아니다. Positional embedding은 그래프 내 절대 위치를 보존한다. 두 노드가 가까운 위치에 있고 비슷한 이웃을 공유하면 embedding이 가깝다. Structural embedding은 상대적 패턴을 보존한다. 두 노드가 그래프상 멀리 떨어져 있어도 친구 관계의 패턴(예: 모두 hub처럼 행동)이 비슷하면 embedding이 가깝다.
이 구분은 task 선택에 직결된다. Link prediction과 clustering처럼 그래프 전체의 topology가 중요한 unsupervised task에서는 positional embedding이 효과적이다. 반면 node classification과 graph classification에서는 local neighborhood pattern을 잡아내는 structural embedding(특히 GNN 기반)이 우세하다.
4. Transductive vs Inductive: 새 노드를 만났을 때
Transductive 방법은 고정된 노드 집합에 대해서만 embedding을 학습한다. 학습 그래프에 없던 노드가 들어오면 embedding을 만들 수 없다. 특정 퍼즐을 잘 푸는 법은 배웠지만, 다른 퍼즐로 옮겨가지 못하는 상태다. Static 그래프에서는 충분하지만, 실시간으로 노드가 추가되는 서비스 환경에서는 곤란하다.
Inductive 방법은 node feature를 입력으로 받는 parametric mapping을 학습한다. 학습 대상은 embedding 자체가 아니라 mapping function이다. 새 노드가 들어와도 feature만 있으면 embedding을 즉시 생성할 수 있다. 대부분의 현대 GNN이 inductive로 설계되는 이유다.
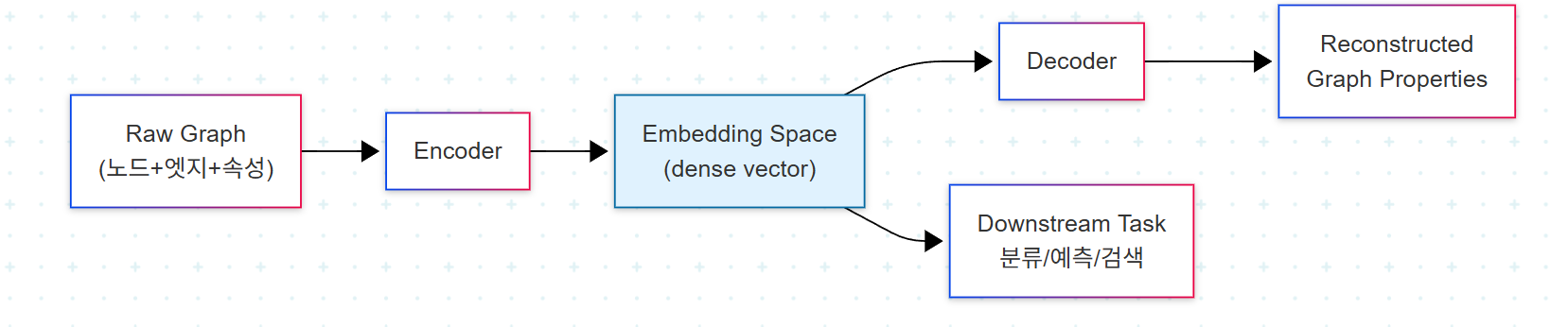
5. Encoder–Decoder 통합 관점
서로 다른 임베딩 기법을 한 그림으로 묶는 가장 깔끔한 framework가 encoder–decoder다. Encoder는 raw graph data를 embedding으로 변환한다. Decoder는 그 embedding으로부터 원본 그래프의 성질(예: 어떤 두 노드가 연결되어 있었는가)을 재구성한다. Decoder의 예측과 실제 그래프 성질의 차이를 최소화하면 encoder는 의미 있는 representation을 학습하게 된다.
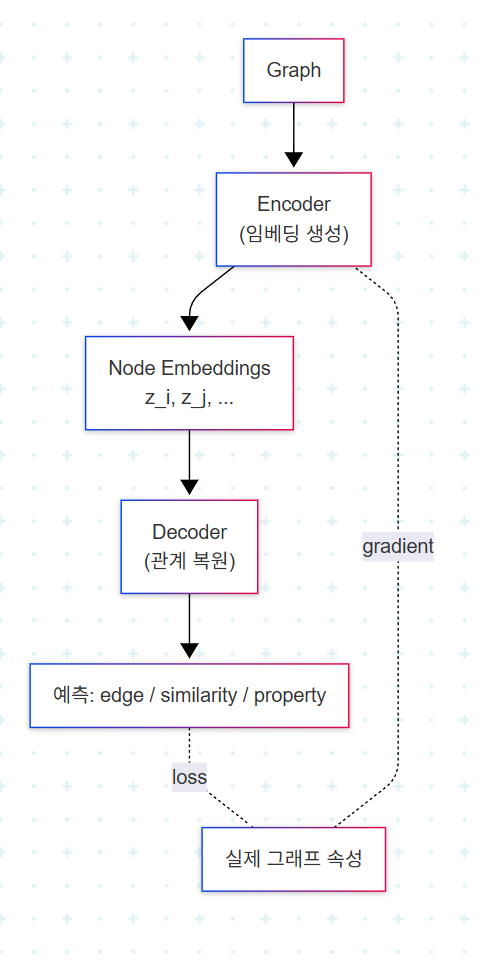
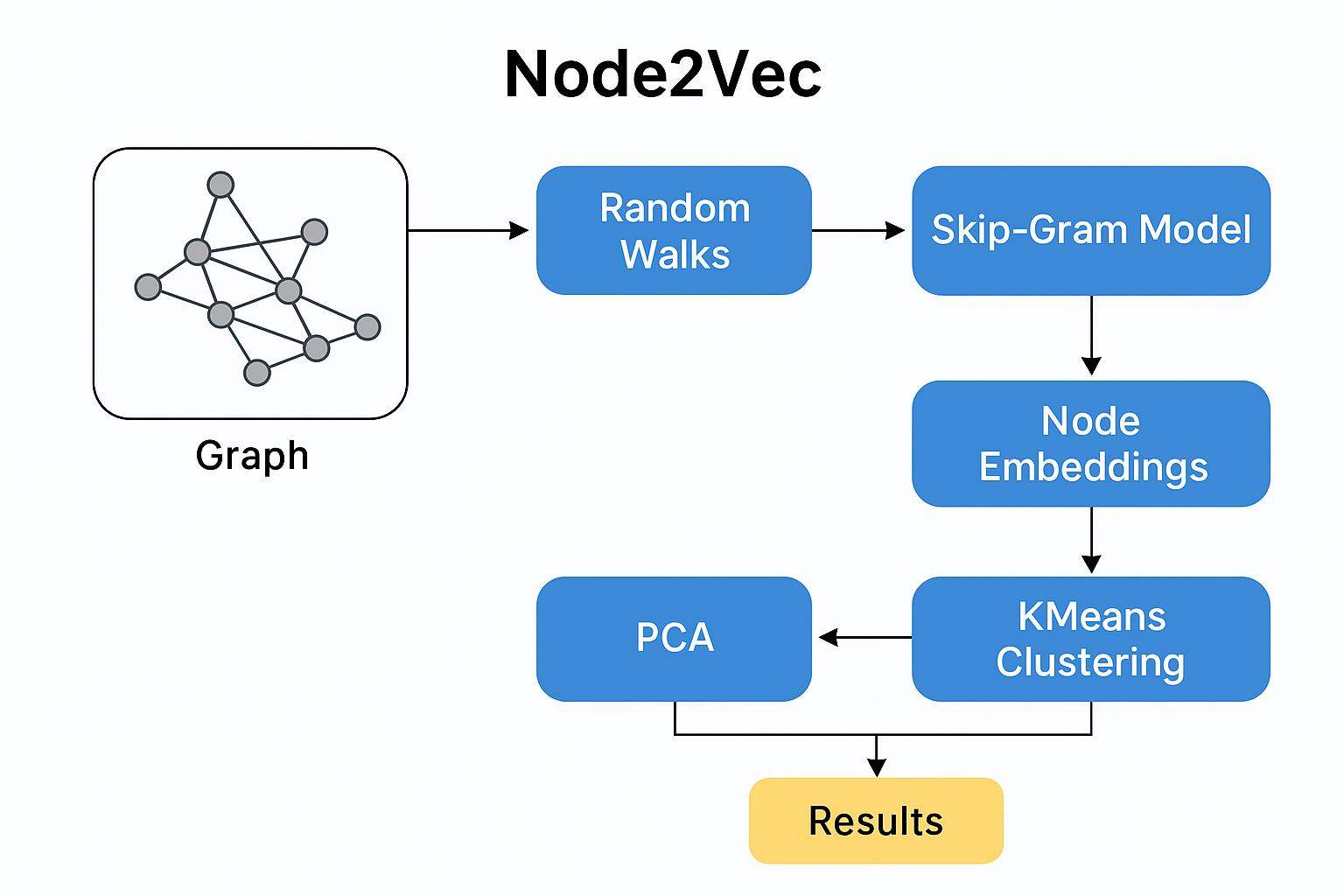
이 framework 안에서 Node2Vec은 random walk를 통해 noise가 섞인 "이웃 동시 출현" 신호를 만들고, encoder가 이를 softmax decoder로 복원하도록 학습한다. Node2Vec의 특징은 walk의 폭(BFS적 탐색)과 깊이(DFS적 탐색) 사이를 hyperparameter로 조절한다는 점이다. 폭을 키우면 structural role을, 깊이를 키우면 community 소속을 더 잘 잡아낸다.
6. Shallow Embedding의 네 가지 한계
Node2Vec, DeepWalk, LINE 같은 초기 기법은 모두 shallow embedding이다. Encoder가 단순한 lookup table로 동작한다. 즉 노드 ID를 키로 vector를 꺼내오는 구조다. 이 단순함은 명확한 한계를 동반한다.
| 한계 | 내용 | 실무 영향 |
|---|---|---|
| Parameter inefficiency | 노드 수에 비례해 파라미터가 선형 증가 | 대규모 그래프에서 메모리 한계 |
| No parameter sharing | 노드 간 패턴 공유 불가 | 일반화 능력 부족 |
| Feature blindness | 노드 속성(텍스트·범주 등)을 활용하지 않음 | 풍부한 정보 손실 |
| Transductive nature | 학습 시 본 노드에 대해서만 embedding 생성 | 신규 노드 처리 불가 |
이 네 한계가 GNN 등장의 직접적인 동기다. GNN은 (1) parametric function으로 파라미터를 공유하고, (2) node feature를 입력으로 받으며, (3) inductive하게 새 노드에도 대응한다.
7. Knowledge Graph Embedding: 관계까지 vector로
일반 그래프 embedding이 "두 노드가 연결되는가"를 다룬다면, knowledge graph(KG) embedding은 "어떻게 연결되는가"까지 다룬다. (h, r, t) triple에서 head·relation·tail이 각각 vector 공간에서 어떻게 배치되어야 하는지가 핵심이다.
대부분 KG는 sparse하다. 가능한 (h, r, t) 조합의 대부분은 실제로 존재하지 않는다. 이 불균형을 다루기 위해 negative sampling + cross-entropy loss가 표준이 되었다. Negative sampling 전략은 두 갈래다. Type-constrained sampling은 관계의 의미에 맞는 후보만 negative로 뽑는다(예: "수도이다" 관계의 tail은 도시여야 함). Adversarial sampling은 진짜와 헷갈리기 쉬운 hard negative를 의도적으로 생성한다.
Multirelational decoder는 세 계열이 대표적이다.
| 디코더 계열 | 대표 모델 | 핵심 아이디어 | 강점 | 약점 |
|---|---|---|---|---|
| Translation 기반 | TransE | h + r ≈ t | compositional pattern | many-to-one 관계 |
| Matrix 기반 | RESCAL | 관계 = 변환 행렬 | 표현력 | 파라미터 폭증 |
| Semantic matching | DistMult, ComplEx | 관계별 유사도 측정 | asymmetric 관계(ComplEx) | composition |
TransE는 compositional 패턴(국가→수도, 수도→국가)에 강하지만 many-to-one에서 흔들린다. ComplEx는 complex number를 도입해 비대칭 관계(예: parent_of vs child_of)를 우아하게 다루지만 composition이 약하다. 모델 선택은 KG의 관계 분포에 따라 달라진다.
8. GNN의 핵심: Message Passing
GNN은 shallow embedding의 한계를 neural message passing이라는 메커니즘으로 돌파한다. 직관적으로는 그래프 위에서 동시에 진행되는 정교한 대화에 가깝다. 각 노드는 매 iteration마다 (1) 이웃으로부터 메시지를 수집하고, (2) 그 메시지를 가공해 의미 있는 정보를 추출하고, (3) 그 결과로 자신의 representation을 갱신한다.
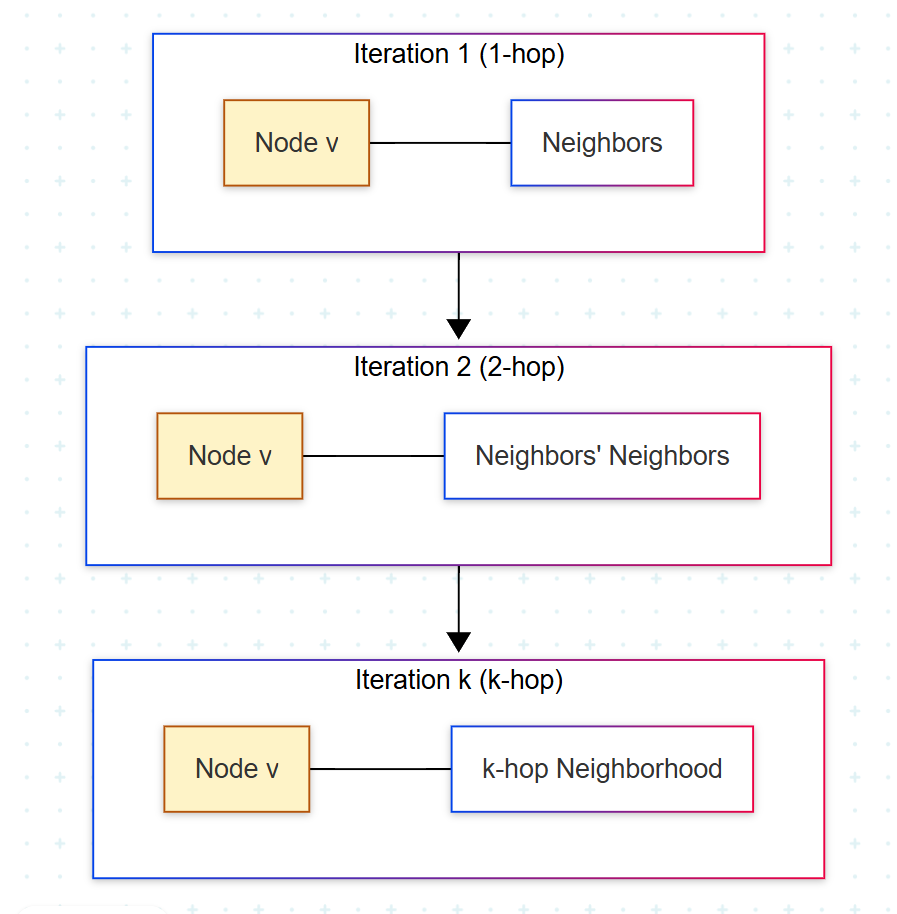
수식 수준에서는 두 함수가 반복된다.
m_v^(k) = AGGREGATE^(k)( { h_u^(k-1) : u ∈ N(v) } )
h_v^(k) = UPDATE^(k)( h_v^(k-1), m_v^(k) )AGGREGATE는 이웃의 representation을 모아 하나의 메시지로 합치고(mean, sum, max, attention 등), UPDATE는 그 메시지로 자기 표현을 갱신한다. k iteration 후 노드 v의 representation은 k-hop 이웃까지의 정보를 담는다.
이 구조의 결정적인 함의는 다음과 같다. Shallow embedding은 노드 ID마다 별개 vector를 학습했지만, GNN은 AGGREGATE와 UPDATE의 파라미터를 모든 노드가 공유한다. 따라서 graph structure의 일반 법칙을 학습할 수 있고, 학습 시 보지 못한 노드에도 동일한 함수를 적용해 inductive하게 embedding을 만든다.
9. 깊은 GNN의 적: Over-smoothing과 그 처방
Iteration을 늘리면 더 먼 이웃 정보를 가져올 수 있지만, layer가 깊어질수록 모든 노드 representation이 비슷해지는 over-smoothing이 발생한다. 그래프 전체가 한 점으로 수렴하는 효과다. 현대 GNN 설계는 이 문제에 대한 일련의 처방으로 구성된다.
Skip connection은 이전 layer의 표현을 우회 경로로 보존한다. ResNet에서 가져온 발상이다. 노드 v의 원래 feature가 깊은 layer에서도 살아남아, 과도한 평활화를 막는다.
Attention 메커니즘은 이웃 기여도에 학습 가능한 가중치를 부여한다. 모든 이웃이 같은 비중이라는 가정을 버리는 것이다. Graph attention network(GAT)는 transformer가 sequence의 각 토큰에 대해 다른 토큰들을 attend하는 방식과 평행하게, 노드가 이웃을 선택적으로 attend하게 한다. Multihead attention은 여러 attention 메커니즘을 병렬로 운영해 이웃 관계의 서로 다른 측면을 동시에 학습한다.
Normalization은 노드마다 이웃 수가 천차만별인 상황에서 출력 분포를 안정화한다. Kipf와 Welling의 GCN이 도입한 symmetric normalization은 source·target 노드의 degree를 모두 반영해 메시지 강도를 조정한다. Citation network에서는 매우 많이 인용된 논문(degree가 큰 노드)의 영향력을 적절히 낮추는 효과가 있다. 단, normalization은 lossy operation이다. 정규화 후에는 degree가 다른 노드를 embedding으로 구분하기 어려워진다는 대가가 있다.
Jumping knowledge network는 각 layer의 representation을 모두 보관했다가 마지막에 결합한다. 노드마다 적절한 hop 수가 다를 수 있다는 관찰에서 출발한다. 어떤 노드는 1-hop 정보가 결정적이고, 어떤 노드는 3-hop까지 봐야 한다. 학습이 노드별로 적절한 layer를 선택하게 한다.
10. GNN과 LLM의 결합: GraphRAG가 가는 방향
이 챕터의 결론부는 그래프와 언어 모델의 상보성이다. GNN은 message passing으로 구조적 정보를 잘 다루지만, 노드·엣지에 붙은 풍부한 텍스트는 잘 다루지 못한다. LLM은 자연어 이해와 생성에 탁월하지만, 그래프의 복잡한 구조적 관계는 본질적으로 sequential 처리 모델로는 자연스럽지 않다. 통합 방식은 세 갈래다.

| 통합 방식 | 역할 분담 | 적합 시나리오 |
|---|---|---|
| LLM as Predictor | 그래프를 sequence로 변환 → LLM이 최종 출력 | KG QA, 생성형 추천 |
| LLM as Encoder | LLM이 텍스트 feature 추출 → GNN이 구조 처리 | text-rich 노드를 가진 분류/예측 |
| LLM as Aligner | LLM과 GNN을 contrastive 학습으로 정렬 | 멀티모달 representation |
세 방식 중 실무에서 가장 자주 마주치는 것은 LLM as Encoder다. 그래프의 노드가 논문 초록, 제품 설명, 환자 기록 같은 텍스트를 가질 때, LLM 임베딩을 node feature로 GNN에 주입하는 구조는 비교적 단순하면서도 효과가 분명하다. GraphRAG의 retrieval 단계에서 텍스트 chunk 임베딩과 그래프 구조를 함께 활용하는 시도들이 대체로 이 카테고리에 속한다.
참고 자료
- Knowledge Graphs and LLMs in Action. Manning, 2024 — Chapter 11: Graph Representation Learning and Graph Neural Networks.
