Text-to-SQL의 전 생애주기(모델·데이터·평가·오류분석)를 LLM 관점에서 체계적으로 재정리한 서베이
0. 논문 개요
0.1 한눈에 보기
| 항목 | 내용 |
|---|---|
| 제목 | A Survey of Text-to-SQL in the Era of LLMs: Where are we, and where are we going? |
| 저자 | Xinyu Liu, Shuyu Shen, Boyan Li, Peixian Ma, Runzhi Jiang, Yuxin Zhang, Ju Fan, Guoliang Li, Nan Tang, Yuyu Luo |
| 소속 | HKUST(Guangzhou), Renmin University of China, Tsinghua University |
| 발표 | arXiv preprint (v6, 2025년 12월 갱신) |
| 분야 | Database, NLP, LLM 응용 |
| 핵심 키워드 | Text-to-SQL, NL2SQL, Database Interface, LLM, Schema Linking |
0.2 사전 지식
이 서베이를 효과적으로 읽기 위해 알아두면 좋은 개념들이다.
- Text-to-SQL (NL2SQL): 자연어 질의를 실행 가능한 SQL로 변환하는 과제. 데이터베이스 접근 장벽을 낮추는 핵심 기술이다.
- 스키마 링킹(schema linking): 자연어 질의에서 언급된 개체·속성을 데이터베이스의 어떤 테이블·컬럼에 매핑할지 판단하는 단계.
- PLM(Pre-trained Language Model): BERT, T5와 같이 대규모 코퍼스에서 사전학습된 인코더/디코더 모델. 일반적으로 추가 파인튜닝이 필요하다.
- LLM(Large Language Model): GPT-4, DeepSeek과 같이 emergent capabilities를 갖춘 대규모 모델. in-context learning만으로도 Text-to-SQL을 수행할 수 있다.
- In-Context Learning (ICL): 모델 파라미터를 갱신하지 않고 프롬프트 내 예시·지시문만으로 새로운 과제를 수행하게 하는 기법.
- Spider / BIRD: Text-to-SQL의 양대 벤치마크. Spider는 cross-domain 일반화에, BIRD는 대규모 더티 데이터·도메인 지식 활용에 초점을 둔다.
- Execution Accuracy(EX): 예측 SQL과 정답 SQL의 실행 결과가 같은지로 평가하는 지표. 현재 가장 널리 쓰이는 메인 지표다.
0.3 논문 구조
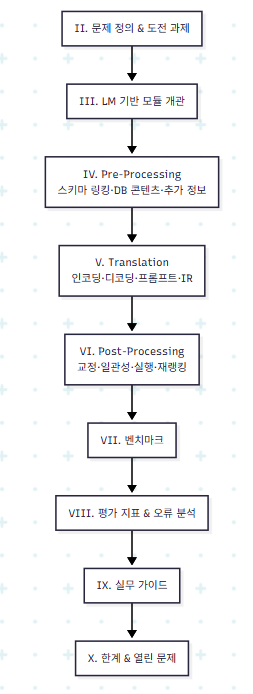
1. Abstract & Introduction
1.1 논문이 풀고자 하는 문제
LLM 시대에 들어서면서 Text-to-SQL은 단일 모델이 한 번에 SQL을 뽑아내는 end-to-end 과제가 아니라, 여러 모듈이 협업하는 모듈러 시스템으로 진화했다. 이 서베이는 그 변화를 다음 네 축으로 종합한다.
- Model: 자연어의 모호성과 underspecification, 그리고 스키마·인스턴스 매핑까지 다루는 번역 기법
- Data: 학습 데이터 수집·합성·벤치마크
- Evaluation: 다각도 지표와 시나리오 기반 평가
- Error Analysis: 오류 분류와 근본 원인 추적
저자들은 단순한 정리에 그치지 않고 "어떻게 LLM을 Text-to-SQL에 최적화할 것인가"에 대한 실무적 로드맵까지 제시한다.
1.2 기존 접근의 한계
이전 서베이들은 주로 PLM 시대까지의 기법을 다루거나, LLM 시대를 다루더라도 모듈 단위 분해가 부족했다. 저자들은 LLM 시대 Text-to-SQL 시스템이 갖는 모듈러 구조를 본격적으로 분해해 보여주는 첫 서베이임을 강조한다.
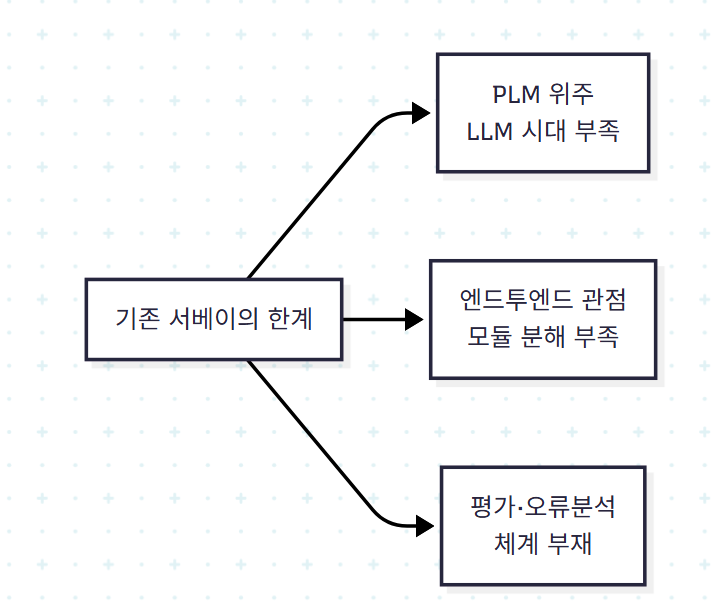
| 기존 서베이의 한계 | 이 서베이가 채우는 부분 |
|---|---|
| PLM 중심, LLM 시대 진단 부족 | LLM 시대 모듈러 구조의 첫 종합 정리 |
| End-to-end 시각 | Pre/Translation/Post 3단계 분해 |
| 평가 단일 지표 위주 | 다각도·시나리오 기반 평가 정리 |
| 오류 분석 비표준 | 2단계 오류 분류 체계 제안 |
1.3 이 논문의 기여
저자가 명시하는 기여를 정리하면 다음과 같다.
- 생애주기 관점의 종합 리뷰: 문제 정의부터 평가, 오류분석, 실무 가이드까지 한 번에 다룬다. Text-to-SQL을 단발성 모델이 아닌 시스템 엔지니어링 과제로 다루는 시각이다.
- 모듈 단위 분해: Schema Linking, DB Content Retrieval, Encoding/Decoding, IR, Self-correction 등을 독립 모듈로 분리해 비교한다. 이는 다음 절(Table I)에서 39개 시스템의 모듈 선택을 한 눈에 볼 수 있게 한다.
- 2단계 오류 분류 체계: "오류 위치(SELECT/WHERE/...)"와 "원인(스키마 링킹 실패, 값 매칭 실패 등)"의 두 축을 제안한다. 1.8%만 Others로 분류된다는 점에서 분류의 실용성을 검증한다.
- 실무 의사결정 흐름 제공: 데이터 프라이버시·볼륨·하드웨어 자원에 따른 LLM 최적화 로드맵, 시나리오별 모듈 선택 가이드를 제시한다.
1.4 논문의 위치
이 서베이는 Katsogiannis-Meimarakis & Koutrika의 VLDB Journal 서베이(2023), Deng et al.의 COLING 서베이(2022) 등을 잇는 흐름에 있다. 다만 LLM 시대 모듈러 시스템의 첫 종합 분해라는 점에서 차별화된다. 구체적으로는 DAIL-SQL(2023)·DIN-SQL(2023)·CHESS(2024)·CHASE-SQL(2025)·Alpha-SQL(2025) 등 최신 시스템을 동일한 모듈 격자에 정렬해 비교 가능하게 만든다는 점이 핵심 가치다.
2. Text-to-SQL 문제 정의와 도전 과제
2.1 문제 정의
Text-to-SQL is the task of converting natural language queries into corresponding SQL queries that can be executed on a relational database.
수식으로 표현하면 다음과 같다.
여기서 는 도메인 지식·추가 정보(예: BIRD 벤치마크의 evidence). 핵심은 단순한 일대일 매핑이 아니라는 점이다. 저자들은 다음 두 가지 다대일/일대다 관계를 강조한다.
- 동일한 NL이 모호성으로 인해 여러 SQL에 대응될 수 있다.
- NL·DB가 명확해도 의미적으로 동치인 SQL이 여럿 존재할 수 있다.
이 점은 평가 지표 설계(특히 Execution Accuracy 대 Exact Match)에 직접적인 영향을 준다.
2.2 인간 워크플로우
논문은 DBA가 "Find the names of all customers who checked out books on exactly 3 different genres on Labor Day in 2023"이라는 질의를 처리하는 과정을 3단계로 분해한다.
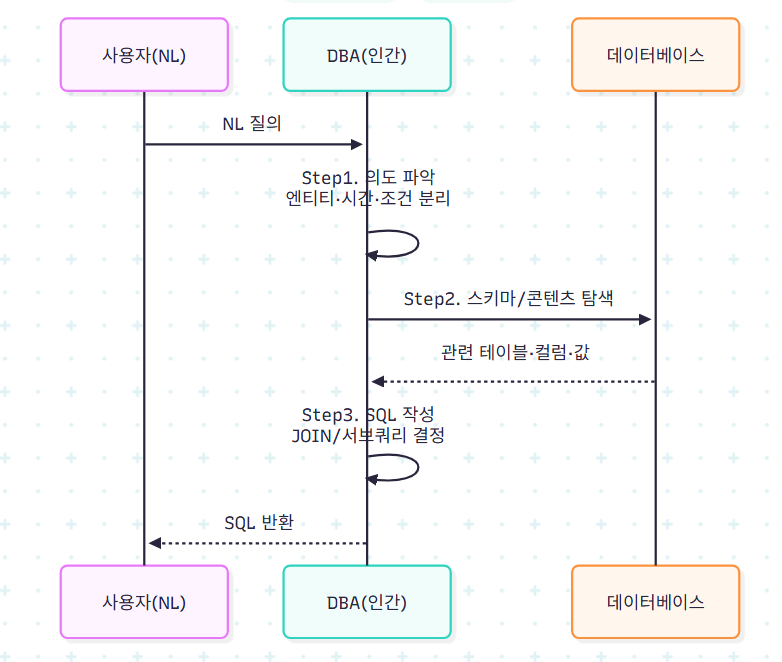
흥미로운 지점은 "Labor Day in 2023"이 미국에서는 9월 4일, 중국에서는 5월 1일을 가리킨다는 사례다. 이는 외부 도메인 지식 없이는 정확한 SQL을 만들 수 없음을 보여주며, 후술할 Additional Information Acquisition 모듈의 존재 이유가 된다.
2.3 세 가지 본질적 도전 과제
C1. 자연어의 불확실성(Uncertain NL)
- 어휘 중의성(lexical ambiguity): "bat"이 동물인지 야구방망이인지
- 통사 중의성(syntactic ambiguity): "Mary saw the man with the telescope"
- Underspecification: "Labor Day"가 어느 나라 기준인지
C2. 복잡한 DB와 더티 데이터
- 수백 개의 테이블, 복잡한 외래키 관계
- 컬럼명·값의 모호성(LiteraryGenre vs SubjectGenre)
- 도메인 특화 스키마 패턴
- 결측·중복·일관성 결여
C3. NL→SQL 번역 그 자체
- 자유 형식 vs 엄격한 문법
- 같은 NL에 대한 복수의 정답 SQL
- 스키마 의존성: 같은 NL이 스키마가 바뀌면 다른 SQL이 됨
이 세 도전 과제는 단순한 분류가 아니라, 후속 모듈(Pre-processing, Translation, Post-processing)이 각각 어느 도전 과제를 겨냥하는지 추적하는 격자 역할을 한다.
2.4 Text-to-SQL 솔루션의 진화
저자들은 Text-to-SQL의 발전을 4단계로 정리한다.
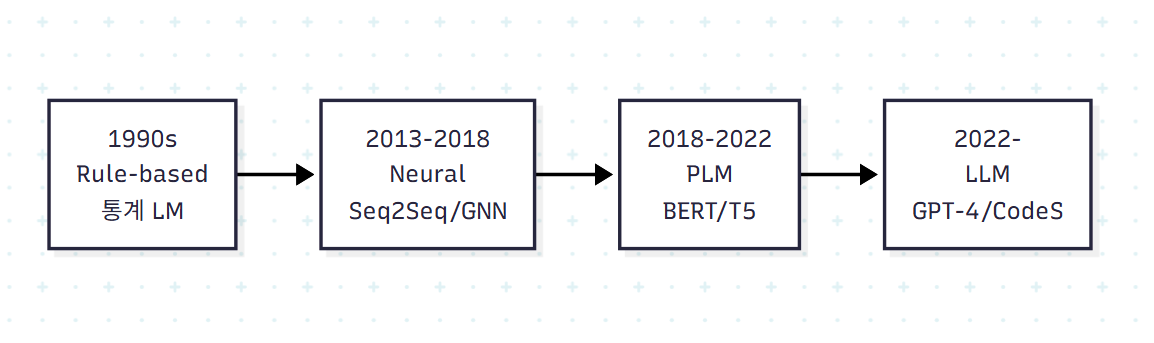
각 단계에서 풀린 도전 과제와 타깃 사용자가 달라진다.
| 단계 | 대표 모델 | 풀린 도전 과제 | 타깃 사용자 |
|---|---|---|---|
| Rule-based | n-gram 기반 파서 | 단일 테이블 토큰 매칭 | 전문가 |
| Neural | LSTM, Seq2Seq, GNN | 다중 테이블·동의어 처리 | 전문가 |
| PLM | BERT, T5, RAT-SQL | 복잡 스키마 일부, Spider 80% 해결 | 전문가→일반인 일부 |
| LLM | GPT-4, CodeS, DAIL-SQL | 대규모 테이블, 도메인 지식, BIRD 등 | 일반인 |
저자들은 다섯 번째 단계(향후 5년)로 "오픈 도메인 Text-to-SQL"을 제시한다. 즉 단일 DB가 아니라 여러 DB를 가로질러 질의·집계하는 시나리오다. 이는 마지막 X장에서 본격적으로 다뤄진다.
2.5 LLM 시대의 두 갈래
LLM을 Text-to-SQL에 활용하는 방법은 크게 둘로 나뉜다.
(1) In-Context Learning — LLM 파라미터를 건드리지 않고 프롬프트만 설계한다.
여기서 는 프롬프트 함수다. DAIL-SQL, DIN-SQL이 대표적이다.
(2) Pre-train & Fine-tune — LLM 자체를 Text-to-SQL에 특화시킨다.
는 일반 코퍼스, 는 Text-to-SQL 특화 데이터셋이다. CodeS가 StarCoder 기반으로 이 경로를 택한 대표 사례다.
이 두 갈래의 구분은 IX장 실무 가이드의 핵심 분기 조건이 된다.
3. LM 기반 Text-to-SQL 모듈 개관
3.1 3단계 모듈러 구조
LLM 시대 Text-to-SQL의 표준 아키텍처는 다음 3단계로 정리된다.
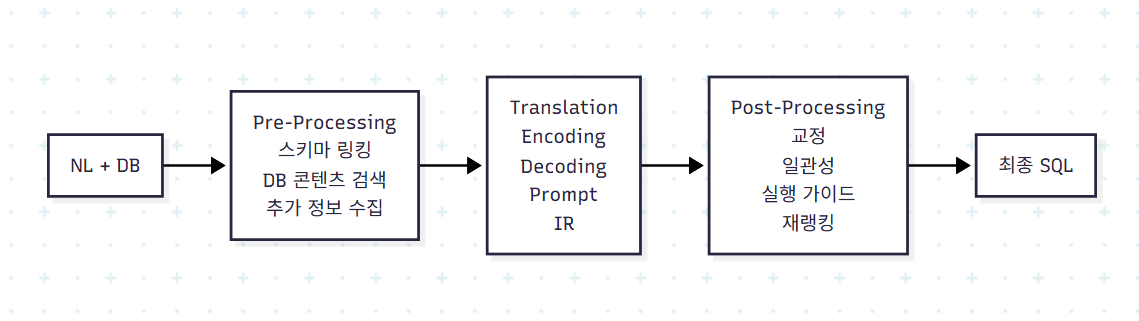
이 구조는 두 가지 의미를 갖는다. 첫째, 각 단계가 서로 다른 도전 과제를 겨냥한다(Pre-processing은 C2, Translation은 C3, Post-processing은 C1·C3 모두). 둘째, 각 모듈은 선택적이다. 단순한 시스템은 Translation만 쓰고, 강력한 시스템은 세 단계 모두에 모듈을 둔다.
3.2 멀티 에이전트 협업으로의 진화
최근 트렌드는 단일 모놀리식 시스템이 아닌 멀티 에이전트 협업으로 가고 있다. 저자들이 강조하는 사례는 다음과 같다.
- MAC-SQL (3-agent): Selector(스키마 링킹), Decomposer(질의 분해·생성), Refiner(실행 기반 정정)
- CHASE-SQL (divide-and-conquer): 다중 CoT 경로로 후보 SQL을 만들고 self-correction과 ranking으로 정제
- Alpha-SQL: Monte Carlo Tree Search 기반 자율 에이전트가 모듈을 동적으로 선택·활성화
특히 Alpha-SQL의 MCTS 접근은 파이프라인의 경직성을 깨고 컨텍스트 추론과 실행 피드백에 따라 다음 모듈을 선택한다는 점에서 의미가 크다. 즉 "어떤 순서로, 어떤 모듈을 쓸 것인가"마저 학습/탐색의 대상이 된다.
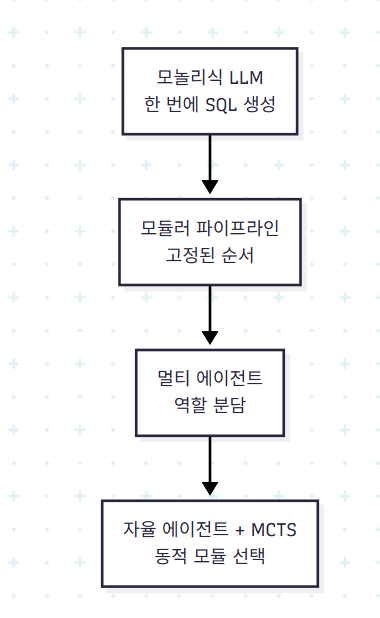
3.3 Table I이 보여주는 트렌드
논문의 Table I은 39개 대표 시스템을 모듈 선택의 격자로 정렬한 표다. 이를 읽고 나면 몇 가지 트렌드가 드러난다.
- Schema Linking은 거의 표준: 39개 중 30개 이상이 사용. PLM 시대(Encoder-Decoder)부터 LLM 시대(Decoder-Only)까지 일관된다.
- Encoding은 Sequential로 수렴: 2022년 이전엔 Graph-based가 강했지만, LLM 시대에 와선 거의 모두 Sequential. LLM이 self-attention으로 관계를 암묵적으로 처리하기 때문이다.
- Decoding은 Greedy가 우세: GPT 계열이 기본 greedy인 영향. PLM 시대의 Beam Search나 Constraint-aware Incremental은 점차 줄어드는 추세다.
- CoT/Decomposition은 LLM에서만 등장: PLM 시대에는 거의 없던 모듈로, LLM의 추론 능력에 의존한다.
- Post-processing은 다양화: Correction, Consistency, Execution-Guided가 결합되어 사용된다.
이는 LLM 시대로 오면서 인코더의 부담은 줄고, 디코더 후처리의 다양성이 늘어난다는 큰 흐름을 말해준다.
4. Pre-Processing 전략
4.1 스키마 링킹
스키마 링킹은 NL과 관련된 테이블·컬럼을 식별하는 단계다. LLM의 컨텍스트 길이 한계 때문에 LLM 시대에는 더욱 중요해졌다.
4.1.1 세 갈래 접근
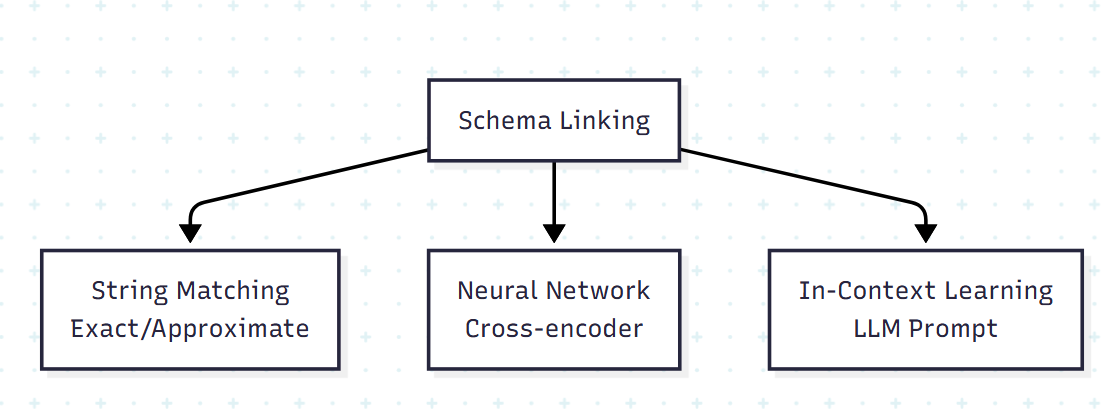
(1) String Matching 기반: IRNet은 정확 매칭, ValueNet은 Damerau-Levenshtein 거리 기반 근사 매칭을 쓴다. 단순하고 빠르지만 동의어와 어휘 변이에 약하다.
(2) Neural Network 기반: RESDSQL은 cross-encoder로 테이블·컬럼을 분류 확률에 따라 정렬한다. FinSQL은 parallel cross-encoder로 시간 비용을 줄인다. SLSQL은 Spider에 스키마 링킹 어노테이션을 추가해 데이터 기반 연구를 가능하게 했다. 의미 관계는 잘 잡지만 도메인 일반화가 어렵다.
(3) In-Context Learning 기반: GPT-4 시대의 표준이 되어가는 방식이다.
- C3-SQL: zero-shot 프롬프트 + self-consistency. 테이블 정렬 후 컬럼을 사전 형태로 출력
- MAC-SQL: 멀티에이전트의 Selector 에이전트가 담당하며, 스키마가 길 때만 활성화
- CHESS: GPT-4로 NL과 evidence에서 키워드 추출 후 3단계 스키마 프루닝
4.1.2 분석
스키마 링킹 모듈은 본질적으로 "검색 정확도"와 "컨텍스트 절약" 사이의 trade-off다. 너무 적게 가져오면 정답에 필요한 컬럼을 놓치고, 너무 많이 가져오면 LLM이 노이즈에 흔들린다. 최근 연구가 ICL 기반으로 수렴하는 이유는 단순 문자열 매칭이 가진 동의어·표현 변이 약점을 LLM의 의미 이해로 보완하면서, 신경망 학습보다 도메인 적응이 쉽기 때문이다.
4.2 데이터베이스 콘텐츠 검색
WHERE 절 등에 들어갈 셀 값을 어떻게 찾을 것인가의 문제다.
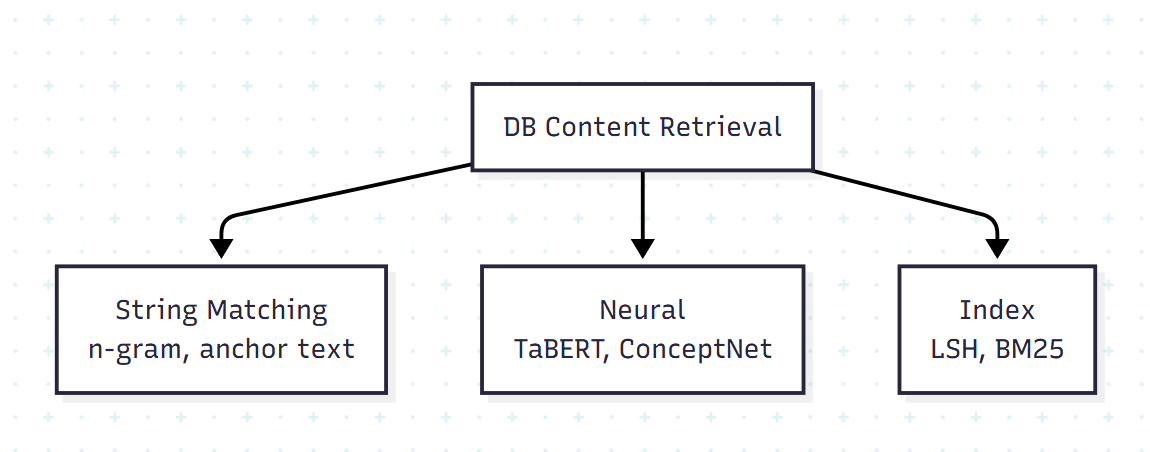
(1) String Matching: BRIDGE는 anchor text matching으로 NL에서 셀 값을 자동 추출한다. 휴리스틱으로 최대 시퀀스 매치를 계산해 매칭 경계를 정한다. 동의어 처리가 약점.
(2) Neural Network: TaBERT는 "database content snapshots"를 어텐션으로 인코딩한다. IRNet은 ConceptNet 같은 지식 그래프를 활용한다. 학습 비용이 크다.
(3) Index 전략: 대규모 DB에서 결정적으로 중요한 접근.
- CHESS: Locality-Sensitive Hashing(LSH)으로 유니크 셀 값을 인덱싱하고 근사 최근접 검색을 수행. 편집 거리·시맨틱 임베딩 비교를 가속.
- CodeS: Coarse-to-fine 매칭. BM25로 후보를 좁힌 뒤 Longest Common Substring으로 재순위.
인덱스는 검색을 빠르게 하지만 빌드 비용과 콘텐츠 변경 시 재구축 부담이 있다. 그래서 대규모 분석 DB에서 매력적이고, 빈번히 변경되는 OLTP DB에서는 부담스럽다.
4.3 추가 정보 수집
도메인 지식, 시연 예제, 공식 증거 등을 프롬프트에 주입하는 모듈이다.
Sample-based: DIN-SQL이 few-shot 예시를 단계별로 삽입. BIRD의 도메인 지식(evidence)을 프롬프트에 포함하는 방식이 대표적.
Retrieval-based: 효율을 위해 유사도 기반 검색을 한다.
- PET-SQL: question frame 풀에서 가장 유사한 k개 예시를 선택
- REGROUP: 도메인별 공식 지식 베이스를 만들고 Dense Passage Retriever로 검색
- ReBoost: Explain-Squeeze 2단계 스키마 링킹
핵심 통찰은 BIRD 같은 현실적 벤치마크에서는 도메인 지식 없이는 성능이 안 나온다는 점이다. 즉 추가 정보 수집은 선택 모듈이 아니라 사실상 필수 모듈로 자리잡고 있다.
5. Translation 모듈
5.1 인코딩 전략
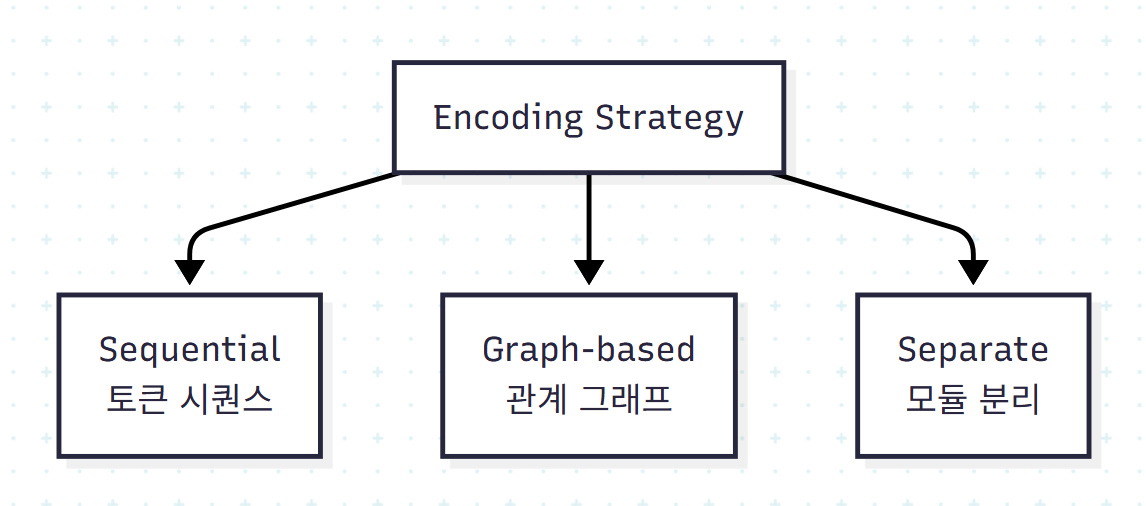
5.1.1 Sequential Encoding
NL과 스키마를 하나의 토큰 시퀀스로 처리한다. T5 기반 모델, 그리고 모든 LLM 기반 시스템이 이 방식을 쓴다(LLM은 명시적으로 인코딩 전략을 정의하지 않지만, NL+스키마를 concatenate하는 순간 암묵적으로 sequential).
- BRIDGE: 매칭된 셀 값(anchor text)을 해당 필드 옆에 삽입해 정렬을 강화
- RESDSQL: rank-enhanced encoder로 스키마 항목을 정렬·필터링
장점은 유연성, 단점은 깊게 중첩된 SQL의 관계 구조를 잡기 어렵다는 점.
5.1.2 Graph-based Encoding
NL과 스키마를 그래프로 표현해 관계 구조를 보존한다.
- RAT-SQL: relation-aware self-attention으로 질문과 스키마를 함께 인코딩
- S²SQL: ELECTRA 기반에 syntactic structure를 주입
- G³R: LGESQL + GAT(Graph Attention Network)
- Graphix-T5: 그래프 인식 레이어를 직접 인코딩 과정에 추가
복잡한 그래프 구성·처리 알고리즘이 필요하고 대규모 학습 데이터를 요구한다. LLM 시대에 이 흐름이 사라진 이유는 LLM의 self-attention이 충분히 강력해서 명시적 그래프 인코딩의 이득이 크지 않기 때문으로 해석할 수 있다.
5.1.3 Separate Encoding
NL과 스키마를 분리 인코딩하거나, 작업을 서브태스크로 나눠 각각 인코딩.
- TKK: 작업 분해 + 멀티태스크 학습
- SC-Prompt: 텍스트 인코딩을 structure(구조)와 content(내용) 두 단계로 분리
연산 오버헤드는 늘지만 모듈성·해석성을 얻는다.
5.2 디코딩 전략
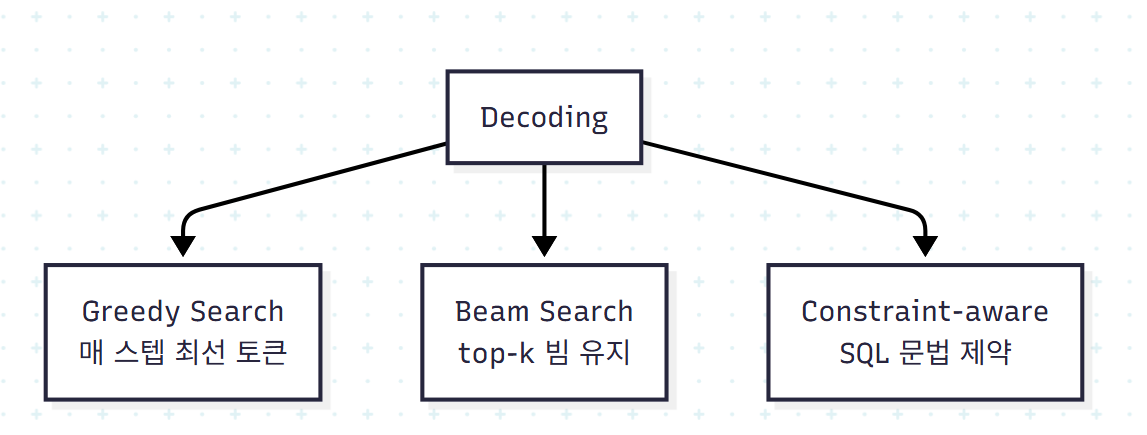
Greedy Search: GPT 계열의 기본. 단순·빠르지만 long-term 의존성을 놓치고 초기 오류가 전파된다.
Beam Search: top-k 빔을 유지해 더 넓은 탐색.
- RAT-SQL은 그래프 구조 + beam search로 후보 SQL을 만들고 재랭킹
- SmBoP은 semi-autoregressive bottom-up 디코딩으로 sub-tree를 병렬 구축(로그 시간 복잡도)
- ZeroNL2SQL은 sketch 단계에서 top-k 가설을 유지
Constraint-aware Incremental: SQL 문법을 디코딩 루프에 삽입해 매 토큰의 문법 적합성을 검증.
- PICARD: 가장 유명한 구현. 매 스텝마다 부분 SQL의 문법 유효성을 검사
- BRIDGE: schema-consistency guided decoding으로 스키마 정렬도 강제
문법 위반은 거의 0%로 만들 수 있지만 토큰별 검증이 추가 비용을 만든다.
5.3 Task-specific Prompt 전략
LLM 시대의 핵심 모듈이다. 두 갈래가 있다.
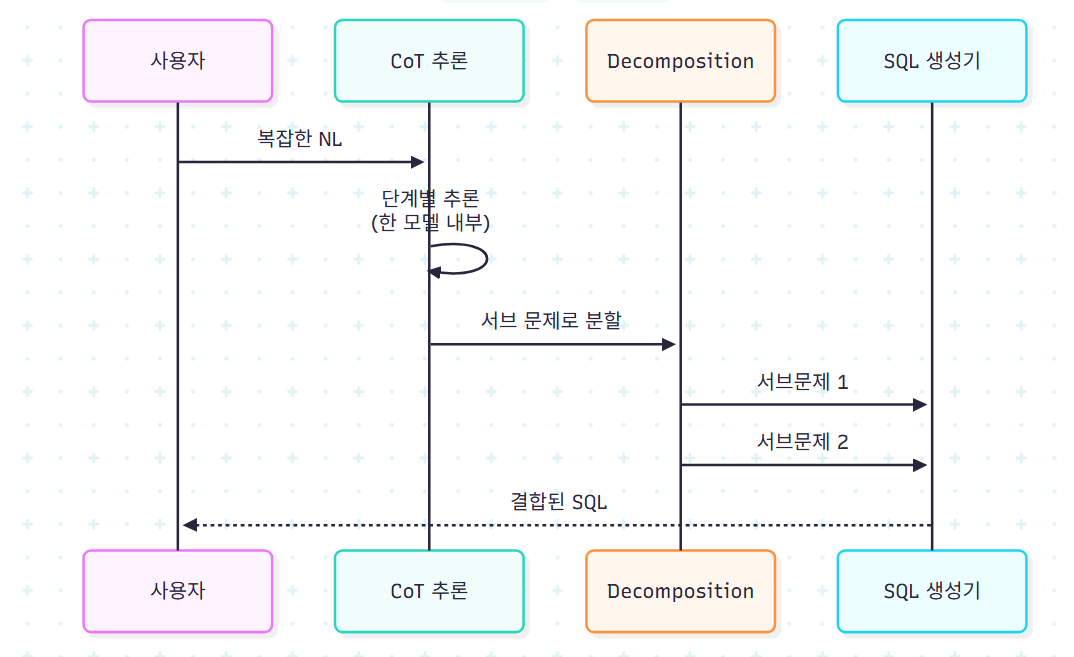
Chain-of-Thought (CoT): 추론 과정을 노출시켜 정확도와 해석성을 동시에 잡는다.
- CHESS는 entity/context retrieval → schema selection → SQL generation → revision의 파이프라인 전체에 CoT 적용
- ACT-SQL, COE-SQL은 CoT + ICL 결합
- C3-SQL, G³R은 CoT + 힌트 calibration
Decomposition: 작업을 서브태스크로 분해.
- TKK: SELECT/FROM/WHERE 절 단위로 분해
- MAC-SQL: Decomposer 에이전트가 사용자 질의를 서브 문제로 쪼갬
- DEA-SQL, G³R도 비슷한 전략
CoT와 Decomposition은 종종 결합된다. 차이는 CoT가 "한 모델 안의 reasoning trace"라면 Decomposition은 "여러 모듈/호출 간의 작업 분할"이라는 점이다.
5.4 Intermediate Representation (IR)
NL과 SQL의 간극을 메우기 위한 중간 표현이다.
5.4.1 SQL-like Syntax Language
SQL을 단순화한 언어다. 발전 흐름은 단순화의 단계를 보여준다.
| 표현 | 단순화 정도 |
|---|---|
| Schema-free SQL | FROM 절 단순화 |
| SyntaxSQLNet | FROM/JOIN 일부 제거 |
| SemQL | FROM/JOIN/ON/GROUP BY 제거, WHERE/HAVING 통합 |
| NatSQL | 드문 연산자·키워드 제거, 스키마 항목 최소화 |
NatSQL은 RESDSQL과 결합해 강한 성능을 보인다. 한계는 큰 스키마와 도메인 특화 SQL을 모두 커버하기 어렵다는 점, 수동 설계 비용이 있다는 점이다.
5.4.2 SQL-like Sketch Structure
SQL의 구조를 슬롯이 있는 템플릿으로 표현한다.
SELECT [column]
FROM [table]
JOIN [table] ON [table].[column] = [table].[column]
GROUP BY [column]
HAVING count([column]) > [n]LLM의 cloze(빈칸 채우기) 능력을 활용해 슬롯을 채우는 전략이다.
- CatSQL: 일반 템플릿 sketch + 슬롯 채우기
- RESDSQL: skeleton-aware decoding으로 SQL skeleton 먼저 생성, 그다음 실제 SQL로 변환
- ZeroNL2SQL, SC-Prompt, TA-SQL도 sketch 활용
장점은 LLM 의존이 줄고 다른 전략(decomposition, syntax language)과 결합이 쉽다는 점.
5.4.3 IR의 의미
IR은 본질적으로 SQL의 표현력을 일부 포기하는 대신 NL→SQL 매핑을 단순화하는 trade-off다. 모든 SQL을 표현하지 못해도, 자주 등장하는 패턴을 깔끔히 잡을 수 있으면 정확도가 올라간다. LLM 시대에 IR의 비중이 줄어든 것은 LLM이 이미 SQL을 직접 잘 생성하기 때문이지만, 복잡한 nested query에서 IR은 여전히 유효한 도구다.
6. Post-Processing 전략
6.1 SQL 교정
DIN-SQL의 self-correction 모듈이 대표적이다. 두 종류 프롬프트를 쓴다.
- General prompt (CodeX용): 직접 오류 식별·수정 요청
- Mild prompt (GPT-4용): 오류가 있다고 가정하지 않고 잠재 이슈만 탐색
ZeroNL2SQL은 predicate 오류(컬럼·값 오인식)에 대한 multi-level matching을 제안. 컬럼→테이블→DB로 매칭 범위를 점진 확장한다.
한계는 대부분 syntax 오류 교정에 집중되어 있고, semantic 오류(잘못된 join, 조건 불일치, 집계 오류)는 잘 다루지 못한다는 점. NL2SQL-BUGs(2025)가 이 빈틈을 본격적으로 다루는 후속 연구다.
6.2 출력 일관성
self-consistency 아이디어를 차용한다. 여러 추론 경로를 샘플링한 뒤 다수결로 답을 고른다.
- DAIL-SQL: self-consistency로 0.4%p 개선
- FinSQL: n개 후보를 병렬 생성, 키워드 일관성 클러스터링 후 최대 클러스터에서 선택
- PET-SQL: cross-consistency. 여러 LLM이 낮은 temperature로 SQL을 만들고 실행 결과로 투표
단점은 추론 비용이 N배가 된다는 것. 그리고 단일 모델 샘플링은 다양성이 한정적이라는 최근 연구도 있다.
6.3 실행 가이드 전략
생성된 SQL을 실제 실행해 결과를 보고 다시 수정하는 전략.
- CHESS: 초안 SQL → 실행 결과 → syntax 오류 수정 → 반복
- CodeS: beam search로 4개 후보를 만들고 첫 번째 실행 가능한 것을 선택
장점은 실행 결과로 검증이 되니 신뢰도가 높다는 것. 단점은 대형 DB에서는 실행 자체가 느려 latency가 폭증한다는 점.
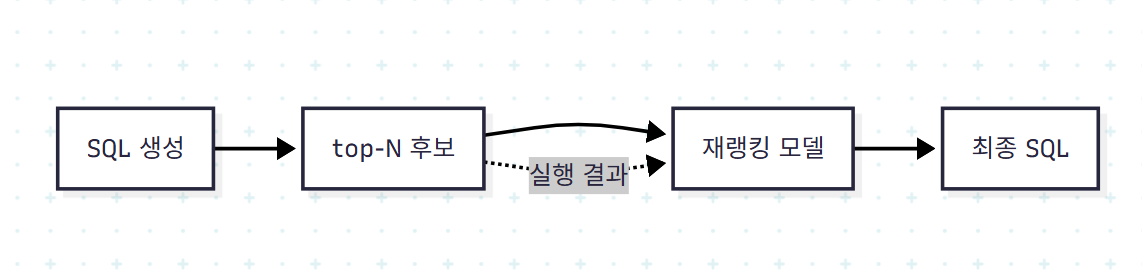
6.4 N-best 재랭킹
PLM 기반 시스템에서 활발하게 쓰인 전략이다. 모델이 생성한 top-N 후보를 다른 (더 큰) 모델로 재정렬한다.
- Bertrand-dr: BERT 기반 reranker. 효과가 임계값에 민감해 부정적 효과도 발생
- G³R: feature-enhanced reranker, hybrid prompt tuning + contrastive learning
- ReFSQL: retriever와 generator의 결과를 결합
LLM 기반 시스템에서는 LLM 자체의 추론력이 강해서 재랭킹이 덜 쓰인다. 다만 다중 후보 + voting/ranking은 CHASE-SQL에서 다시 부상하는 패턴이다.
7. 벤치마크
7.1 데이터셋 분류
논문은 벤치마크를 8가지 시나리오로 분류한다.

대표 흐름은 다음과 같다.
- 단일 도메인 → 크로스 도메인: ATIS, GeoQuery에서 시작해 WikiSQL, Spider로 일반화 능력을 측정.
- Spider → BIRD: BIRD는 더 큰 DB(평균 4.5M 레코드/DB), 도메인 지식, scalar function/수학 연산을 포함.
- Robustness 강조: Spider-Syn(동의어), Dr.Spider(17가지 perturbation), AmbiQT(모호성).
- 현실 시나리오: BookSQL(회계), FinSQL/BULL(금융), Archer(추론), Spider2-Lite(엔터프라이즈).
7.2 통계 분석으로 본 트렌드
논문 Table II의 통계에서 의미 있는 수치를 골라 해석한다.
| 데이터셋 | #-DBs | #-Tables/DB | #-Records/DB | Avg #-Selects | 의미 |
|---|---|---|---|---|---|
| Spider | 206 | 5.13 | 8,980 | 1.17 | Cross-domain 표준 |
| BIRD | 80 | 7.64 | 4,585,335 | 1.09 | 대규모 데이터·도메인 지식 |
| Spider2-Lite | 264 | 23.71 | - | 5.10 | 엔터프라이즈 복잡도 |
| Archer | 10 | 6.8 | 31,365 | 3.07 | 추론·산술 강조 |
| BULL | 3 | 26 | 85,631 | 1.0 | 금융 도메인 단일 |
관찰점: Spider→BIRD→Spider2-Lite로 갈수록 DB 크기와 SQL 복잡도가 모두 증가. 특히 Spider2-Lite는 평균 23개 테이블/DB, 평균 5개 SELECT로 현실 엔터프라이즈에 가깝다.
저자들이 강조하는 "현재 데이터셋의 한계"는 다음과 같다.
- 중첩 쿼리(nested SELECT)와 복잡 set operation 부족
- Scalar function·수학 연산이 적게 포함됨
- Open-domain(다수 DB 가로지르는) 시나리오 거의 없음
이는 X장의 open problem과 직접 연결된다.
7.3 데이터 합성
학습 데이터 부족은 본질적 문제다. 합성 방법은 시간순으로 다음과 같이 진화했다.
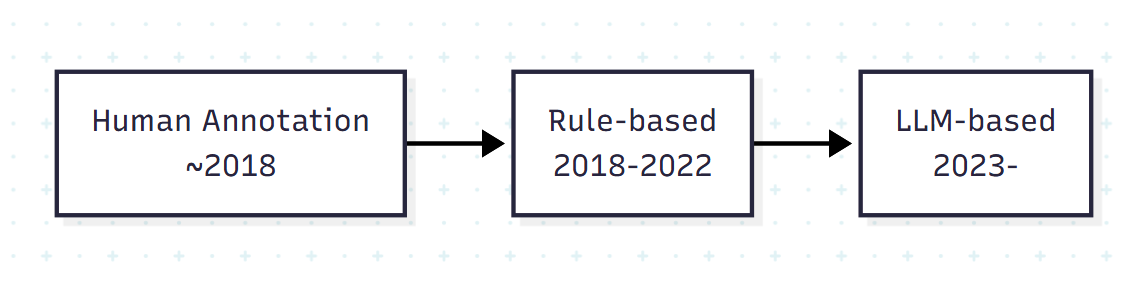
- Human annotation: Spider, ATIS. 품질은 높지만 비싸다.
- Rule-based synthesis: MIMICSQL은 템플릿 기반 SQL 생성 후 NL 작성.
- LLM-based synthesis: ScienceBenchmark는 SQL을 템플릿으로 만들고 GPT-3로 NL을 역생성.
LLM 기반 합성의 가능성은 크지만, 합성 데이터의 다양성·정확성·도메인 적합성을 어떻게 보장할 것인가가 X장의 "Adaptive Training Data Synthesis" 문제로 이어진다.
8. 평가와 오류 분석
8.1 평가 지표
논문은 6가지 지표를 정의한다.
Execution Accuracy (EX): 가장 널리 쓰이는 메인 지표.
는 정답 SQL의 실행 결과 집합, 는 예측 SQL의 결과 집합. 의미적으로 다른 SQL이 우연히 같은 결과를 낼 수 있다는 false positive 가능성이 한계다.
String-Match Accuracy (SM): 문자열 정확 일치. 의미적으로 같은 SQL을 다르게 작성한 경우(예: WHERE 절 순서 변경)를 모두 틀렸다고 처리하는 약점.
Component-Match Accuracy (CM): SELECT, WHERE 등 컴포넌트 단위 정확도.
WHERE 절 같은 일부 컴포넌트는 순서를 무시하고 매칭한다.
Exact-Match Accuracy (EM): CM의 모든 컴포넌트가 일치할 때만 정답.
Valid Efficiency Score (VES): BIRD가 도입한 실행 효율 평가.
는 SQL의 효율(실행 시간 등). 정확하지만 느린 SQL이 패널티를 받는다.
Query Variance Testing (QVT): 같은 SQL에 대응되는 여러 NL 변형에 대한 모델의 일관성을 측정.
이 지표들의 의미를 정리하면 다음과 같다.
| 지표 | 측정 대상 | 약점 |
|---|---|---|
| EX | 결과 동치성 | 의미 다른데 우연히 같은 결과 |
| SM/EM | 문자열·구성요소 일치 | 표현 다양성 미반영 |
| VES | 효율성 | 정확도와 효율 분리 어려움 |
| QVT | NL 표현 변동에 대한 견고성 | 변형 NL 데이터 필요 |
8.2 평가 툴킷
MT-TEQL: 메타모픽 테스팅. NL 변형(prefix insertion 등) 4종, 스키마 변형(table shuffle 등) 8종을 자동 생성해 견고성을 평가.
NL2SQL360: 다각도 평가 프레임워크. 6개 컴포넌트(Dataset, Model Zoo, Metrics, Filter, Evaluator, Analysis)로 구성. SQL 특성(집계 함수, 중첩 쿼리, top-k)별로 데이터셋을 필터링해 시나리오별 성능을 측정.
이 툴킷들의 의미는 "단일 벤치마크의 단일 점수"로는 실서비스 성능을 알 수 없다는 인식이다. BI 시나리오는 집계·top-k 쿼리가 많고, 정형 보고는 join이 깊다. 각각의 부분집합에서 성능을 따로 봐야 한다.
8.3 오류 분류 체계
8.3.1 기존 분류 체계 정리
- Ning et al.: Syntactic 차원(SQL 키워드별)과 Semantic 차원(NL 해석 오류) 두 축.
- SQL-PaLM: Schema Linking, Database Content, Knowledge Evidence, Reasoning, Syntax 5종.
- NL2SQL-BUGs: semantic 오류에 집중. 9개 메인 카테고리, 31개 서브카테고리.
이들은 데이터셋·모델 의존적이라는 한계가 있다.
8.3.2 저자의 2단계 분류 원칙
저자들은 분류 체계가 갖춰야 할 4원칙을 제시한다.
1. Comprehensiveness: 모든 오류 타입 포괄
2. Mutual Exclusivity: 분류 모호성 제거
3. Extensibility: 새 오류 유형 수용
4. Practicality: 실제 디버깅에 활용 가능
이 원칙으로 만든 2단계 분류는 다음과 같다.
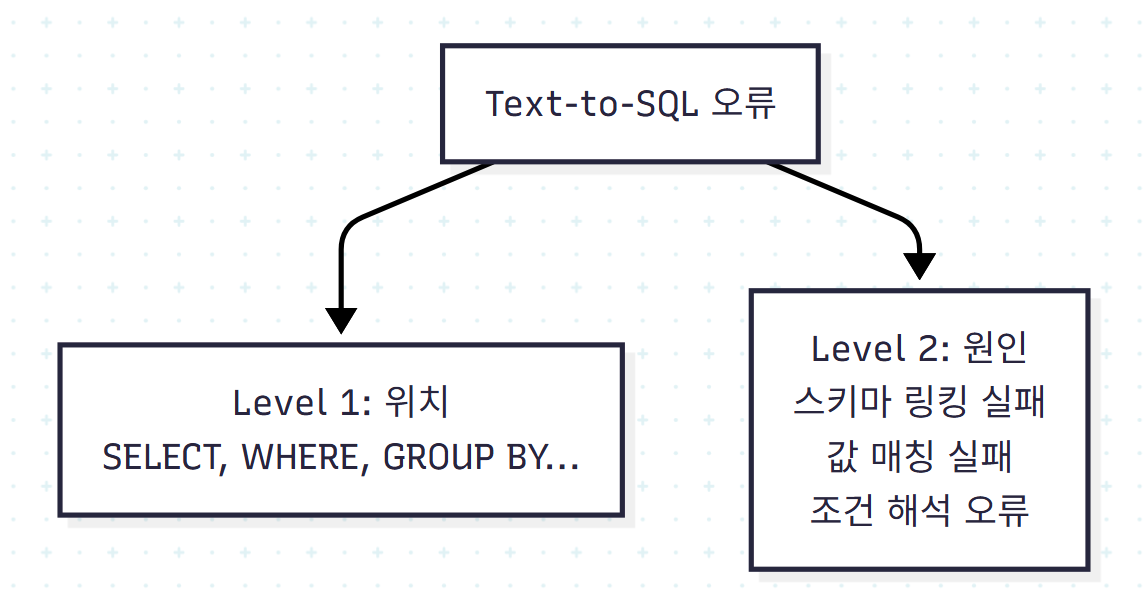
Level 1 (위치): 어느 SQL 절에서 오류가 발생했는가
Level 2 (원인): 왜 그 오류가 발생했는가
8.3.3 적용 결과 분석
DIN-SQL을 Spider에 적용한 오류 분포(Figure 1d)를 정리하면 다음과 같다.
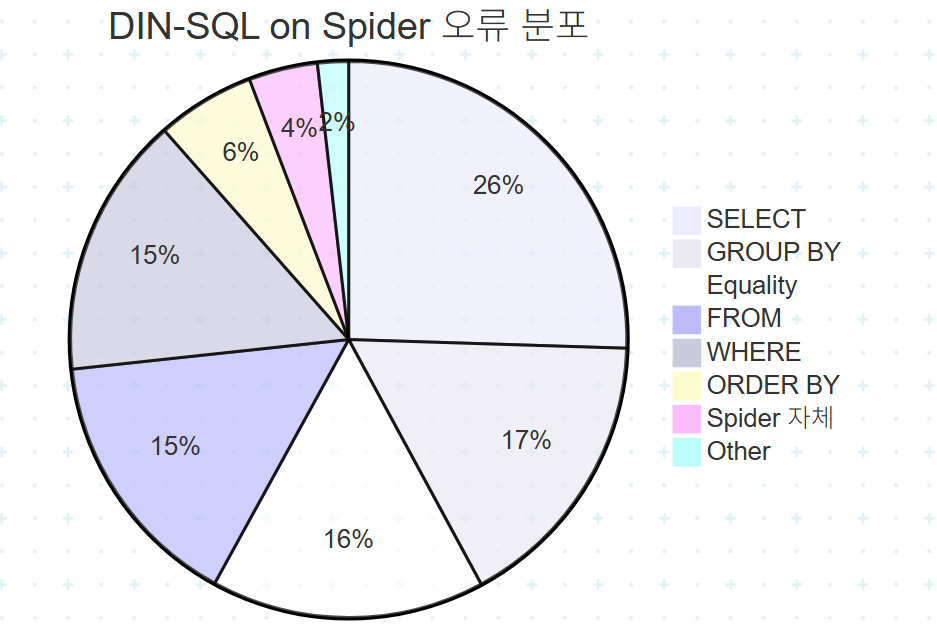
흥미로운 관찰점은 다음과 같다.
- SELECT 오류가 25.5%로 가장 큼: 어떤 컬럼을 출력할지 결정하는 단계가 의외로 약하다. 스키마 링킹의 한계.
- GROUP BY 16.6%: 집계의 핵심 절. 누락·중복·서브쿼리화 오류가 섞여 있음.
- Equality 15.9%, WHERE 15.2%: 조건절의 값 매칭이 여전히 큰 골칫거리. DB content retrieval 모듈의 중요성을 뒷받침.
- FROM 15.3%: JOIN 결정과 테이블 선택. 복잡 스키마의 본질적 어려움.
- Other가 1.8%: 분류 체계의 실용성 검증.
각 위치 안에서 원인은 더 세분된다. WHERE 절 오류(15.2%) 내부를 들여다보면 Value 매칭이 11.6%로 압도적이다. 즉 WHERE의 어려움 대부분은 "어떤 값으로 필터링할지"를 못 맞추는 것이라는 진단이다. 이는 indexed retrieval(LSH, BM25)이 왜 중요한지를 정량적으로 뒷받침한다.
9. 실무 가이드
9.1 데이터 기반 LLM 최적화 로드맵
저자들은 두 조건(데이터 프라이버시, 데이터 볼륨)에 따른 의사결정 흐름을 제안한다.
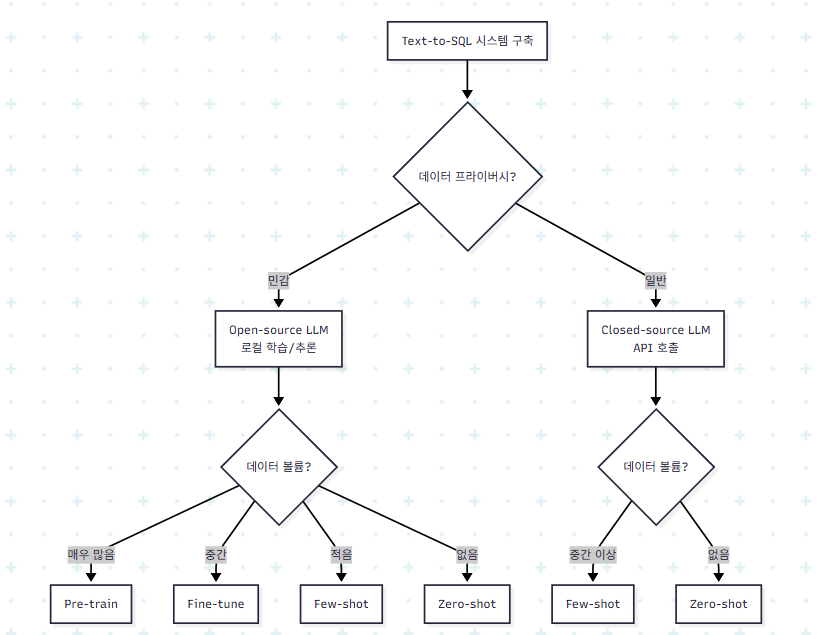
핵심 원칙은 다음과 같다.
- 프라이버시가 민감하면 무조건 오픈소스 LLM: 외부 API는 데이터 유출 위험.
- 오픈소스는 학습+추론 모두 최적화 가능, 클로즈드는 추론만 가능.
- 하드웨어 vs API 비용: 오픈소스는 GPU 자원을, 클로즈드는 API 예산을 요구.
- 저데이터 환경에선 few-shot, zero-shot 우선: 작은 라벨링 데이터로 fine-tuning을 시도하는 건 종종 손해.
9.2 모듈 선택 의사결정 흐름
저자들은 시나리오별 모듈 추천을 표로 정리했는데, 핵심을 다음과 같이 재구성할 수 있다.
| 시나리오 | 추천 모듈 | 장점 | 단점 |
|---|---|---|---|
| 복잡한 스키마(테이블·컬럼 多) | Schema Linking | 토큰·노이즈 ↓ | 시간 ↑ |
| DB 콘텐츠와 NL 표현 불일치 | DB Content Retrieval | 값 매칭 정확도 ↑ | 토큰·시간 ↑ |
| 도메인 특화 NL/DB | Additional Information | 의미 이해·도메인 적응 ↑ | 토큰·시간 ↑ |
| 모델 가이드 필요 | Task-specific Prompt | 이해도 ↑ | 토큰 ↑ |
| NL-SQL 격차 큼 | IR | 격차 ↓ | 시간·복잡도 ↑ |
| 동일 NL에 결과 불일치 | Output Consistency | 일관성 ↑ | 시간 ↑ (토큰 ↑) |
| Syntax 오류 발생 | SQL Correction | 실행 성공률 ↑ | 시간 ↑ (토큰 ↑) |
| 실행 결과 접근 가능 | Execution-Guided | 비실행 SQL 필터링 | 시간 ↑ |
이 표의 핵심은 모든 모듈이 시간/토큰 비용 증가를 동반한다는 점이다. 모듈 선택은 항상 trade-off이고, 시나리오에 맞춰 선택해야 한다.
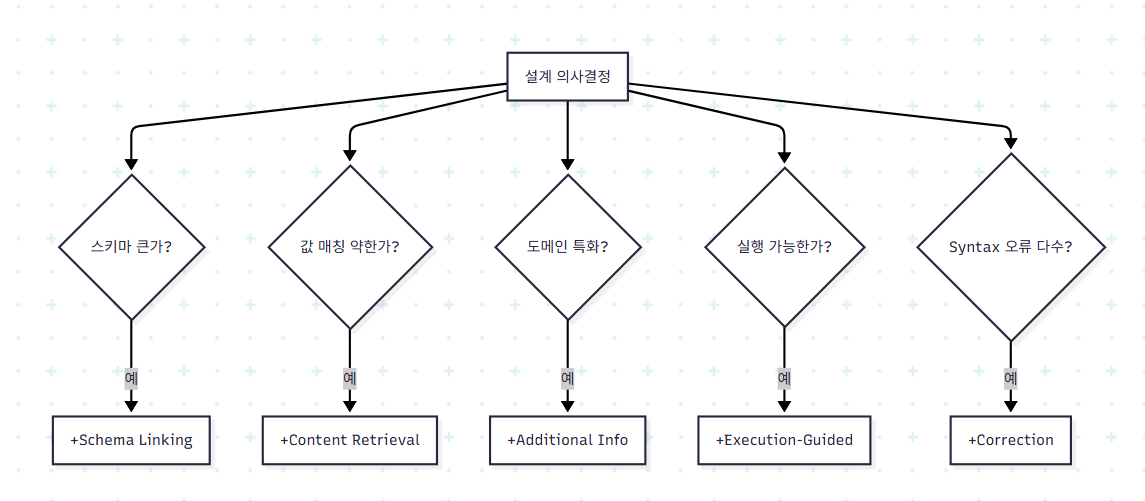
9.3 자원 비용 비교
논문 Table III는 Spider에서의 자원 사용을 비교한다.
| Method | Base | Tokens/SQL | Latency/SQL (s) |
|---|---|---|---|
| RESDSQL | PLM | - | 1.91 |
| RESDSQL+NatSQL | PLM | - | 1.97 |
| ZeroNet | PLM+LLM | 377 | 3.72 |
| DIN-SQL | LLM | 3,579 | 10.34 |
관찰: DIN-SQL은 RESDSQL보다 5배 이상 느리고 토큰 소비도 거의 10배다. 정확도는 더 높지만 운영 비용 차이가 크다. 실무에서는 PLM과 LLM을 혼합하거나 복잡도에 따라 라우팅(EllieSQL의 접근)이 합리적인 선택이 될 수 있다.
10. 한계와 열린 문제
10.1 현재 LLM 기반 방법의 한계
저자들이 정리한 한계는 다음과 같다.
- 단일 DB 가정: 학습·추론 모두 단일 DB 위에서 이뤄짐. cross-DB 시나리오 미지원.
- 추론 비용: 강력한 NLU에도 불구하고 토큰 소비가 크다.
- 해석성·디버그 부재: 사용자가 SQL 생성 과정을 이해·검증할 수단이 부족.
- 도메인 적응 약함: 새 도메인마다 고품질 데이터가 필요하지만 자동 합성 메커니즘이 미숙.
10.2 Open-Domain Text-to-SQL
가장 큰 미해결 과제다. 정부 오픈데이터 같은 환경에서는 한 NL이 여러 DB(세금기록, 처리로그, 통계보고서 등)에 걸쳐 있다.
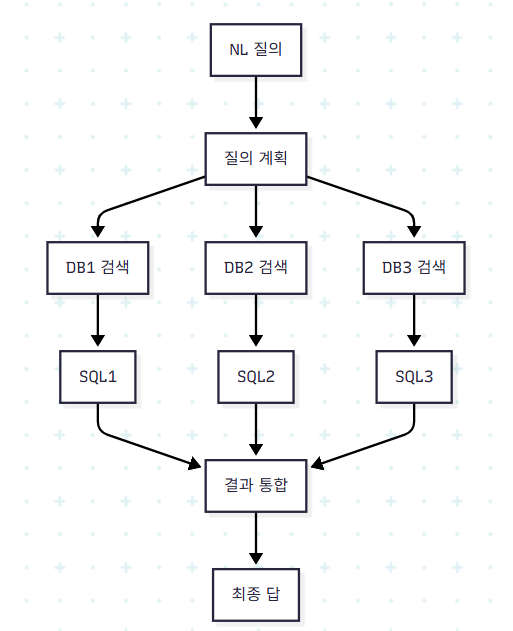
이 시나리오의 도전 과제는 다음과 같다.
- DB 검색: 거대한 데이터 소스 풀에서 관련 DB를 찾는 검색 단계
- 이질적 스키마: 서로 다른 명명·구조 통합
- 답 집계: 여러 SQL 결과를 종합해 최종 답 도출
- 도메인 적응: 도메인별 용어·구조 차이
- 확장성·효율: 대규모 데이터 처리
- 평가: 현실 복잡도를 반영하는 메트릭·데이터셋 필요
10.3 Cost-Effective Text-to-SQL
LLM 단독 사용은 비용이 너무 크다. 저자들이 제시하는 방향은 다음과 같다.
- PLM + LLM 하이브리드: 단순 쿼리는 PLM, 복잡 쿼리는 LLM
- EllieSQL 같은 complexity-aware routing: 쿼리 복잡도에 따라 적합한 생성기로 분배
이는 실서비스 관점에서 매우 현실적인 방향이다. 모든 쿼리에 GPT-4를 쓰는 것은 비용·latency 모두 부담스럽고, 실제로 대부분의 쿼리는 단순하기 때문이다.
10.4 Trustworthy Text-to-SQL
신뢰성을 위한 4가지 방향이 제시된다.
(a) 해석 가능성: surrogate model, saliency map 등 XAI 기법의 Text-to-SQL 적용. 멀티 에이전트 LLM이 자연스럽게 각 단계의 출력을 보여주므로 일부 해석성을 제공.
(b) 디버깅 도구: 컴파일러처럼 SQL 오류를 잡되, syntax뿐 아니라 semantic 오류까지 검증. NL2SQL-BUGs가 이 방향의 시작.
(c) 인터랙티브 도구: DBA가 50줄 이상의 복잡 쿼리를 작성할 때, 모델이 분해하고 사용자가 부분별로 정정·확인하는 워크플로우. bottom-up과 top-down 모두 지원.
(d) 적응형 데이터 합성: 모델 약점을 평가 결과에서 식별하고, LLM으로 해당 약점을 보완하는 (NL, SQL) 쌍을 자동 생성하는 피드백 루프.
11. 정리
11.1 핵심 한 줄
LLM 시대의 Text-to-SQL은 단일 모델이 SQL을 한 번에 뱉는 게 아니라, Pre/Translation/Post의 모듈러 시스템이며, 각 모듈은 시나리오별 비용·정확도 trade-off의 산물이다.
11.2 의의
이 서베이의 의의는 두 가지다. 학술적으로는 LLM 시대 Text-to-SQL을 "에이전트·모듈러 시스템"으로 정식화한 첫 종합 정리다. 실무적으로는 어떤 모듈을 언제 쓸지에 대한 의사결정 프레임을 제공해, 시스템 설계자가 길을 잃지 않게 돕는다.
