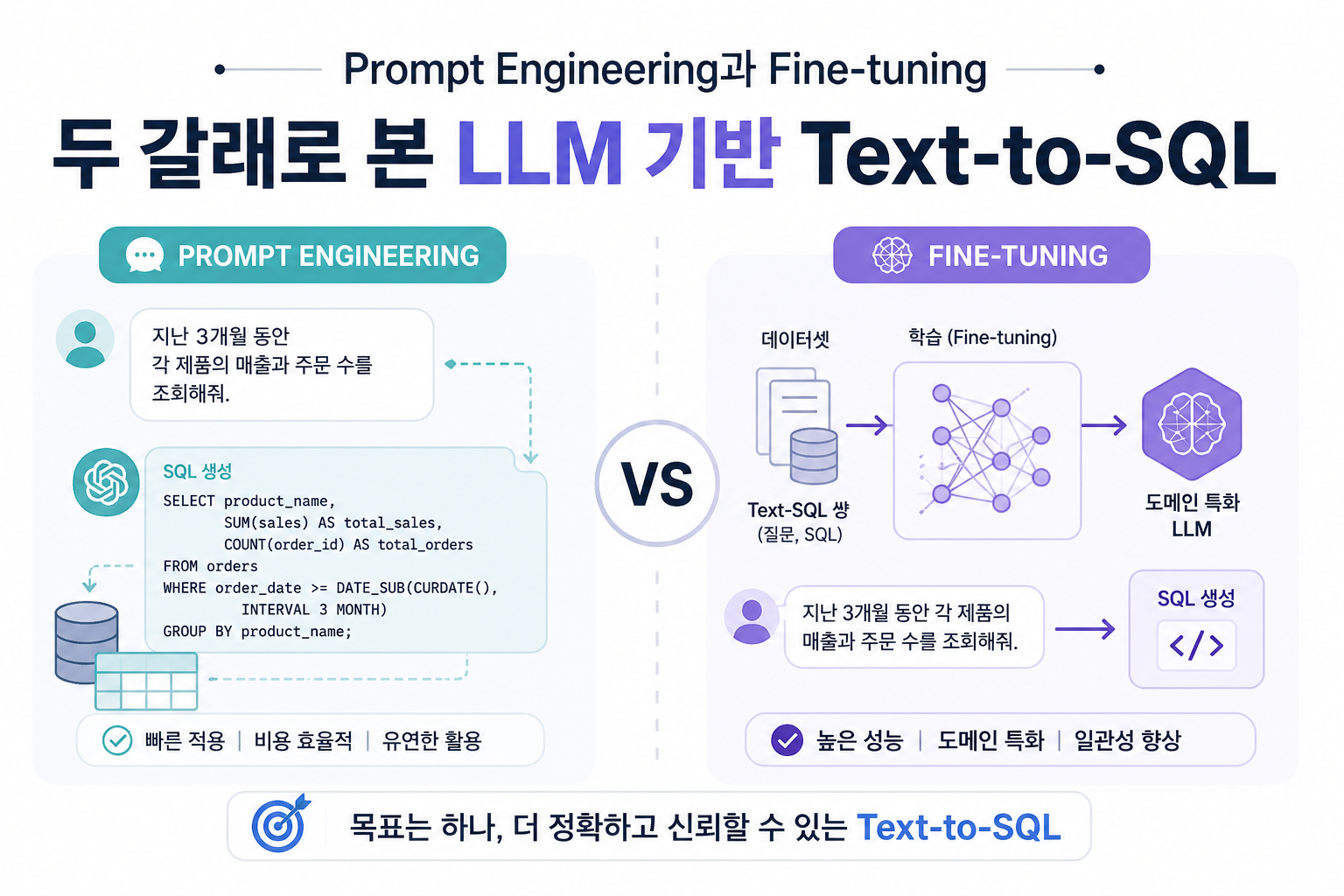
Prompt Engineering과 Fine-tuning을 두 축으로 LLM 기반 Text-to-SQL의 전체 파이프라인을 체계화한 ACM Computing Surveys 서베이
0. 논문 개요
0.1 한눈에 보기
| 항목 | 내용 |
|---|---|
| 제목 | A Survey on Employing Large Language Models for Text-to-SQL Tasks |
| 저자 | Liang Shi, Zhengju Tang, Nan Zhang, Xiaotong Zhang, Zhi Yang |
| 소속 | Peking University, SINGDATA CLOUD |
| 발표 | ACM Computing Surveys (2025년 5월 수락, v5는 6월 갱신) |
| 분야 | NLP, Database, LLM 응용 |
| 핵심 키워드 | Large Language Models, Text-to-SQL, Prompt Engineering, Fine-tuning |
0.2 사전 지식
이 서베이를 효과적으로 읽기 위해 필요한 개념을 정리한다.
- Prompt Engineering: 모델 파라미터를 갱신하지 않고 입력 프롬프트만 설계해 LLM 행동을 제어하는 기법.
- Fine-tuning: 사전학습된 LLM을 특정 도메인(여기선 Text-to-SQL)의 데이터로 추가 학습.
- In-Context Learning (ICL): 프롬프트 안에 제공된 예시만으로 새 과제를 학습하는 LLM의 emergent ability.
- Chain-of-Thought (CoT): 추론 과정을 명시적으로 단계별로 풀어내는 프롬프트 패턴.
- Least-to-Most: 복잡한 문제를 더 쉬운 서브문제로 환원해 푸는 프롬프트 전략.
- Self-Consistency / Cross-Consistency: 같은 모델이나 여러 모델이 만든 다수 답안을 투표로 종합.
- LoRA / QLoRA: 일부 파라미터만 학습해 fine-tuning 비용을 줄이는 PEFT 기법.
- Spider, BIRD, Spider 2.0: 각 시대를 대표하는 Text-to-SQL 벤치마크.
- Schema Linking: NL의 표현을 DB의 테이블·컬럼으로 매핑하는 핵심 단계.
0.3 논문 구조
1. Abstract & Introduction
1.1 논문이 풀고자 하는 문제
이 서베이가 답하려는 질문은 한 줄로 요약할 수 있다.
LLM 시대에 Text-to-SQL을 푸는 방법은 어떻게 분류·이해해야 하며, 각 방법은 언제 어떻게 써야 하는가?
저자들은 LLM 활용을 프롬프트 엔지니어링과 파인튜닝 두 갈래로 명확히 가르고, 각 갈래의 전체 파이프라인을 체계화한다. 이는 두 갈래가 단순한 alternative가 아니라 trade-off 관계임을 부각한다.
1.2 기존 접근의 한계
전통적 Text-to-SQL은 두 흐름이 있었다.
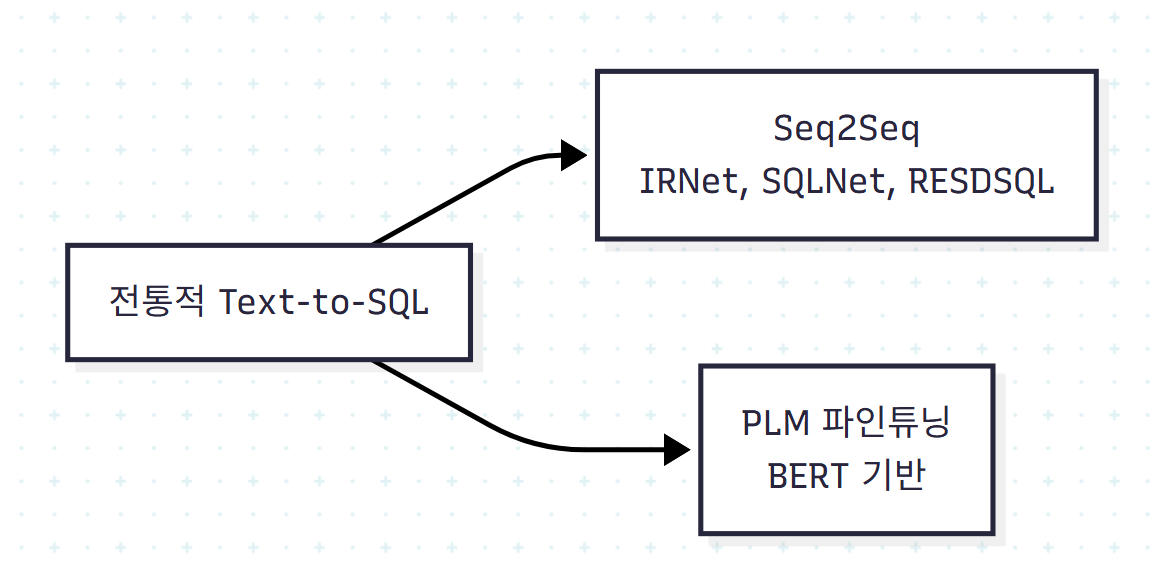
저자들은 전통적 방법과 LLM 기반 방법의 차이를 두 가지로 압축한다.
| 비교 축 | 전통 방법 | LLM 방법 |
|---|---|---|
| 패러다임 | 학습 필수 | 프롬프트만으로 가능 |
| 아키텍처 | LSTM·Transformer·GNN 혼재 | 통일된 transformer 디코더 |
특히 "학습 없이도 가능"은 LLM의 instruction-following 능력에서 나오는 본질적 변화다. 데이터 라벨링 비용·재학습 비용을 거의 0으로 만들 수 있다는 의미다.
1.3 이 논문의 기여
저자들이 명시한 기여는 다음과 같다.
- 체계적 분류 체계 제시: Prompt Engineering의 3단계(pre/inference/post)와 Fine-tuning의 4축(목표·방법·데이터·평가)을 격자로 정리.
- 각 절 끝의 Key Takeaways: 단순 정리가 아닌 실무 적용 가능한 요약을 명시. 각 섹션의 마지막에 "이것만은 챙겨라"를 박스로 제시한다.
- 모델 사용 트렌드 분석: 28개 LLM의 사용 빈도와 시간에 따른 변화를 정량 분석. 클로즈드와 오픈소스의 비중 변화가 두드러진다.
- 세 벤치마크 비교 분석: Spider 1.0, BIRD, Spider 2.0의 리더보드 데이터를 직접 비교하며 트렌드를 도출.
- 실용적 미래 방향: 프라이버시, 복잡 스키마, 도메인 지식, 자율 에이전트, 데이터 거버넌스의 5가지 축으로 미래 도전 정리.
1.4 논문의 위치
이 서베이는 같은 시기 발표된 다른 LLM Text-to-SQL 서베이들[43, 68, 139, 147]과 차별화된다. 특히 Liu et al.의 HKUST 서베이(2024)가 모듈러 시스템 관점이라면, 이 서베이는 Prompt Engineering vs Fine-tuning의 이항 대립을 강하게 밀고 나간다. 모듈을 잘게 쪼개기보다는, 실무자가 어느 갈래로 갈지 의사결정하는 데 도움을 주는 구조다.
2. Overview: LLM과 LLM 기반 Text-to-SQL
2.1 LLM의 두 emergent ability
LLM은 PLM의 단순 확장이 아니라 emergent abilities를 갖춘 새로운 패러다임이다. 본 논문은 두 가지를 강조한다.
- Few-shot learning: 프롬프트에 몇 개 예시만 주면 새 과제를 수행
- Instruction following: 자연어 지시만으로 unseen task에 적응
이 두 능력이 Text-to-SQL에서 특히 강력하다. 왜냐하면 Text-to-SQL은 (a) 도메인마다 스키마가 달라 학습 데이터가 부족하고 (b) 자연어 지시로 SQL 작성 규칙을 알려주기 쉬운 과제이기 때문이다.
2.2 자기회귀 디코딩 관점
논문은 LLM의 작동을 다음 수식으로 형식화한다.
여기서 는 프롬프트, 는 다음 토큰. 이 수식의 함의는 프롬프트 설계가 곧 출력 분포 설계라는 점이다. 즉 프롬프트 엔지니어링은 단순한 트릭이 아니라 분포를 형성하는 행위다.
2.3 왜 LLM 기반 Text-to-SQL인가
저자들은 세 가지 이유를 든다.
특히 일반화 능력이 결정적이다. 새 도메인마다 학습할 필요 없이 프롬프트만 바꾸면 된다는 점은 산업적으로 매우 큰 가치다.
2.4 전체 파이프라인
논문은 LLM 기반 Text-to-SQL을 두 갈래로 분리한다.
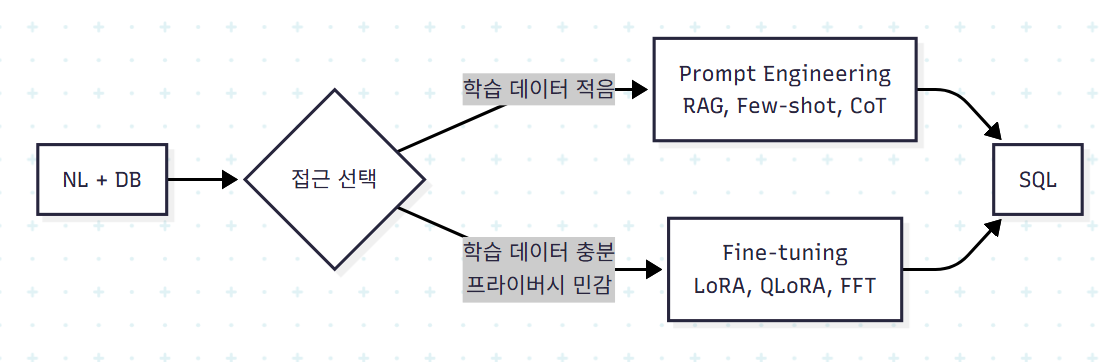
이 분기는 단순한 기술 선택이 아니라 데이터·자원·프라이버시 제약에 따른 의사결정이라는 시각이 깔려 있다.
3. 벤치마크와 평가 지표
3.1 벤치마크 분류
논문은 벤치마크를 LLM 등장 이전과 이후로 가른다.

LLM 시대 벤치마크는 다음 새 도전에 초점을 맞춘다.
- 도메인 특화 지식: ScienceBenchmark는 천체물리학, 암 연구, 정책 결정 같은 실제 도메인에서 SQL 전문가와 협업해 만들었다. 기존 데이터셋의 한계, 즉 일반 도메인에서 학습한 시스템이 특수 도메인에서 곧바로 무너진다는 문제를 정면으로 본다.
- 더티 데이터·도메인 지식·SQL 효율: BIRD는 33.4GB 규모, 95개 DB, 37개 도메인. GPT-4가 54.89%인 반면 인간은 92.96%로, 격차가 여전히 크다.
- 17종 견고성 perturbation: Dr.Spider는 가장 강한 모델조차 평균 14% 성능 하락, 가장 어려운 perturbation에선 50.7% 하락을 보인다.
- 엔터프라이즈 워크플로우: Spider 2.0은 BigQuery, Snowflake, PostgreSQL 같은 실제 클라우드 DB. 1,000개 이상 컬럼을 가진 DB도 포함.
- 오류 진단: BIRD-Critic 1.0은 SQL 생성을 넘어 SQL 디버깅 능력을 평가. 가장 강한 o1-preview조차 38.5% pass rate로, 이 새 axis는 모델들에게 어렵다.
3.2 평가 지표
논문은 다섯 지표를 다룬다.
Exact Set Match Accuracy (EM): SQL 절 단위 문자열 일치. 같은 의미를 다른 표현으로 쓴 SQL을 모두 틀렸다고 처리해 과소평가 위험이 있다.
Execution Accuracy (EX): 실행 결과 비교. 의미가 다른데 우연히 같은 결과를 내는 경우 과대평가 위험이 있다.
Test-suite Accuracy (TS): 무작위 생성된 다수 DB 중 코드 커버리지 높은 작은 테스트 스위트로 평가. 의미적 정확도의 strict upper bound를 측정한다.
Valid Efficiency Score (VES): BIRD에서 도입한 효율 지표.
여기서 은 정답일 때만 1을 반환하고, 은 실행 시간 비율의 제곱근이다. 정확하면서도 빠른 SQL을 보상한다.
ESM+: EM의 개선판. LEFT/RIGHT JOIN, OUTER/INNER JOIN, DISTINCT, LIMIT, IN, foreign key, schema check, alias 등에 대한 새 규칙을 추가해 false positive와 false negative를 줄인다.
지표들의 trade-off를 정리하면 다음과 같다.
| 지표 | 강점 | 약점 |
|---|---|---|
| EM | 엄밀함 | 표현 다양성 처벌 |
| EX | 실행 검증 | 의미 다른데 같은 결과 |
| TS | 의미 정확도 상한 | 테스트 스위트 구축 비용 |
| VES | 효율 반영 | 환경 의존성 |
| ESM+ | EM 보완 | 새 규칙 익혀야 함 |
3.3 벤치마킹 연구
저자들은 서베이 외 벤치마킹 연구들도 정리한다.
- Rajkumar et al.(2022): Codex와 GPT-3로 프롬프트 구성 비교
- DAIL-SQL의 모태가 된 비교 연구: question representation, example selection, organization
- Zhang et al.(2024): Text-to-SQL, SQL Debugging, SQL Optimization, Schema Linking, SQL-to-Text 5종 과제
- DB-GPT-Hub: 오픈소스 모델 fine-tuning에 특화된 모듈러 코드베이스
저자들은 빠른 모델·기법 변화 때문에 수치 비교는 빠르게 낡는다고 경고한다. 이 경고는 모든 LLM 서베이의 본질적 한계이기도 하다.
4. Prompt Engineering: 3단계 파이프라인
4.1 전체 구조
논문의 핵심 분류다. 전체 파이프라인을 다음과 같이 형식화한다.
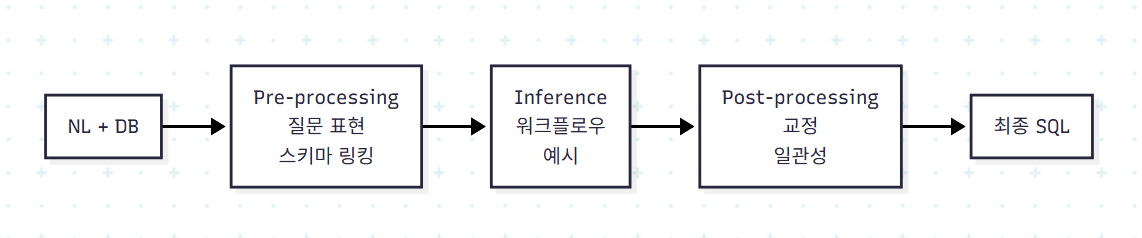
세 단계를 차례로 풀어본다.
4.2 Pre-processing
4.2.1 Question Representation
질문 자체와 DB 정보를 어떻게 프롬프트로 표현할지 결정하는 단계다. 세 요소로 분해된다.
(a) Layouts: 두 가지가 표준이다.
- OpenAI Template: SQLite 주석 형태로
Table(Column1, Column2, ...)줄을 나열하고 마지막에SELECT로 시작 - CREATE TABLE Layout: 실제 DDL인
CREATE TABLE문으로 데이터 타입과 PK/FK까지 명시
(b) Sample Data: 실제 DB 콘텐츠 몇 행을 함께 제공. SELECT * FROM Table LIMIT 3 같은 형식. 데이터의 형식과 분포를 모델이 이해하게 만든다.
(c) Knowledge: 두 종류다.
- SQL Knowledge: SQL 키워드·문법·작성 관습. 예: C3는 "COUNT(*)는 특정 경우만, LEFT JOIN/IN/OR 피하고 JOIN/INTERSECT 사용, DISTINCT/LIMIT 권장" 같은 명시적 가이드를 프롬프트에 포함
- External Knowledge: 도메인 용어·약어·은어. BIRD의 evidence가 대표적이고, CHESS는 컨텍스트 검색으로 DB 카탈로그·테이블·컬럼의 설명·약어를 가져온다
4.2.2 분석: Layout 선택의 의미
논문이 정리한 실험 결과를 종합하면 다음과 같다.
| 변경 | 영향 |
|---|---|
| 구조화 → 비구조화 layout | 큰 성능 하락 (C3) |
| OpenAI Template ↔ CREATE TABLE | 거의 동등 (DAIL-SQL은 OpenAI 우세, QDecomp는 동등) |
| Sample Data 추가 | 일반적으로 도움 (단 너무 많으면 역효과) |
| Foreign Key 추가 | 일반적으로 도움 (PK/FK는 멀티테이블 추론의 핵심) |
| External Knowledge 추가 | SQLfuse, DEA-SQL 모두 큰 개선 |
핵심 통찰은 layout 자체보다 그 안에 든 정보(PK/FK, sample data, knowledge)가 결정적이라는 점이다.
4.2.3 Schema Linking
Pre-processing의 또 다른 핵심 모듈이다. 큰 DB에서 모든 테이블을 프롬프트에 넣을 수 없기 때문에 관련 부분만 추려야 한다.
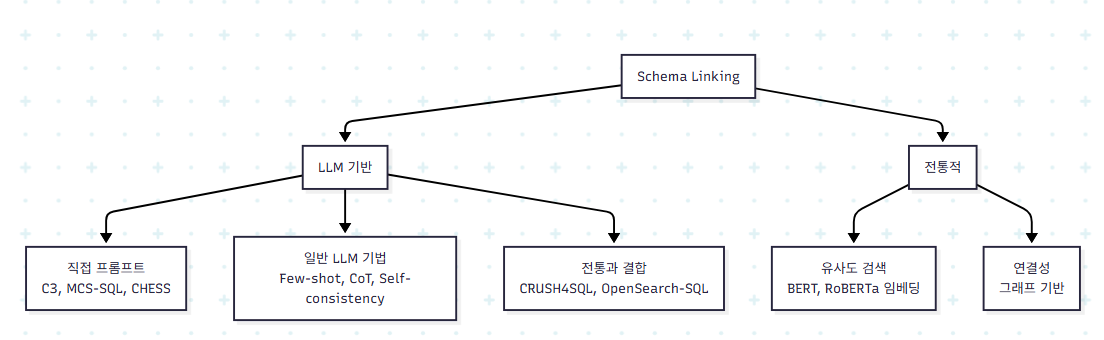
LLM 기반 접근의 세 갈래:
(1) 단계별 프롬프트: 직접 시키되 효율을 위해 분할
- C3, MCS-SQL: 테이블 → 컬럼 두 단계
- DEA-SQL: 질문 요소 식별 → 스키마 필터링
- CHESS: 컬럼 필터링 → 테이블 선택 → 최종 컬럼 필터링의 3단계
- PET-SQL: 흥미로운 역접근 - 먼저 SQL을 그려보고 그 SQL에서 테이블·컬럼 추출. LLM이 SQL 작성을 schema linking보다 잘한다는 통찰이다
- RSL-SQL: bidirectional, 전체 스키마와 LLM이 만든 SQL 모두 고려
- E-SQL: pre-generated SQL을 NL에 직접 통합
(2) 일반 LLM 기법 활용: few-shot, CoT, self-consistency, fine-tuning
- DIN-SQL: random examples + "Let's think step by step"
- C3, MCS-SQL: self-consistency 투표
- ACT-SQL: 임베딩 모델로 phrase-schema 관계를 식별, CoT 형식의 예시 구성
- SQLfuse: schema linking을 직접 fine-tuning
(3) 전통적 방법과 결합:
- CRUSH4SQL: LLM이 hallucinate한 schema를 기준 삼아 유사도 기반 검색
- OpenSearch-SQL: LLM이 선택한 schema에 vector retrieval로 보완
전통적 접근의 두 갈래:
(a) 유사도 기반: BERT, RoBERTa 같은 PLM으로 query와 schema를 임베딩해 유사도 비교. De-semanticization은 직접 매칭 + DB 값 매칭을 결합
(b) 연결성 기반:
- DBCopilot: DB·테이블 그래프 + Seq2Seq 라우터
- PURPLE: PK-FK 그래프
- SGU-SQL: query-schema 통합 그래프
4.2.4 Distillery의 통찰
흥미로운 반론이 있다. Distillery는 모델의 SQL 생성 능력이 향상될수록 무관한 컬럼이 컨텍스트에 있어도 영향이 줄어든다고 보여준다. 즉 컨텍스트 윈도우가 커지고 모델이 강해질수록 schema linking의 비용 대비 가치가 떨어진다는 것이다. 그럼에도 실서비스 DB는 컨텍스트 한계를 초과하기 때문에 여전히 필요하다.
Key Takeaways
- 대부분의 시스템은 CoT 또는 decomposition을 기본 워크플로우로 채택
- LLM 기반 schema linking의 주류는 단계별 프롬프트와 일반 LLM 기법 활용
- 유사도와 연결성 모두 고려할 가치가 있음
4.3 Inference
4.3.1 Workflow
복잡한 Text-to-SQL을 단발 LLM 호출로 푸는 것은 무리다. 따라서 워크플로우 설계가 중요하다. 네 종류로 분류된다.
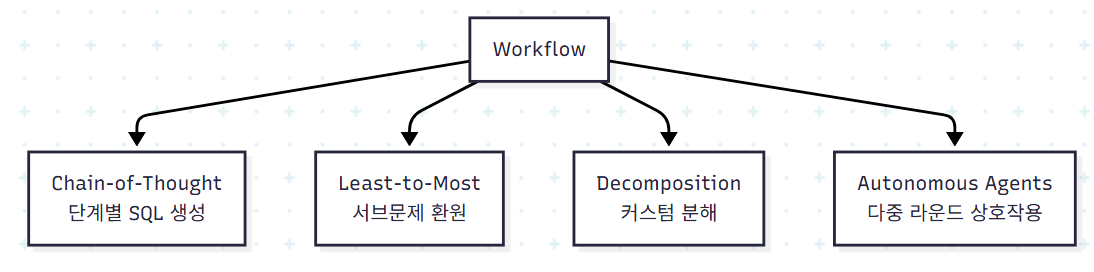
(1) Chain-of-Thought (CoT)
전통적 CoT는 "Let's think step by step"으로 추론을 유도한다. Text-to-SQL에 응용된 변형들은 다음과 같다.
- DIN-SQL: 복잡 질의에 대해 인간이 설계한 CoT 단계
- Divide-and-Prompt: 절(clause) 단위 SQL 생성
- CoE-SQL: Chain-of-Edition. 14개 SQL 편집 규칙(SELECT 항목 편집, WHERE 논리 연산자 편집 등)
- ACT-SQL: Auto-CoT - CoT 예시를 자동 생성해 라벨링 비용 감소
- Open-SQL: skeleton 기반 query framework를 중간 표현으로 사용
(2) Least-to-Most
서브문제로의 환원이 핵심이다. CoT가 SQL 자체를 단계화한다면, Least-to-Most는 NL 질문을 더 단순한 질문으로 환원한다. LTMP-DA-GP가 대표 사례로, NL을 분해하고 NatSQL에 매핑한 뒤 SQL로 변환한다.
(3) Decomposition
작업 자체를 여러 LLM 상호작용으로 분해한다. 병렬과 순차 두 형태가 있다.
- DIN-SQL (병렬 분해): SQL을 Easy/Nested Complex/Non-Nested Complex로 분류해 각각 다른 처리
- MAC-SQL (순차 분해): Selector → Decomposer → Refiner 3-agent. Decomposer가 sub-question과 sub-SQL을 만들고 최종 SQL로 통합
- DEA-SQL: Information determination → Classification & Hint → SQL generation → Self-correction → Active learning
- OpenSearch-SQL: Preprocessing → Extraction → Generation → Refinement → Alignment 5모듈
- R³: SQL Writer + 여러 Reviewer의 negotiation 기반 합의
(4) Autonomous Agents
ReAct 프레임워크에 기반한 자율 에이전트. 다른 워크플로우와 차별화되는 핵심은 다음과 같다.
- 다중 턴 상호작용
- 긴 추론 시간
- 장기 기억
- 조건부 종료
대표 사례:
- Spider-Agent (Spider 2.0): 커맨드라인 인터페이스로 DB와 다중 턴 상호작용. 같은 결과를 3번 출력하거나 timeout이면 자동 종료
- REFORCE: self-refinement + 도메인 특화 기법(table compression, format restriction). self-consistency, max iterations, empty result로 종료
4.3.2 워크플로우 비교
| 워크플로우 | 적합한 시나리오 |
|---|---|
| CoT | SQL을 단계별로 생성, 인간 사고 과정 모방 |
| Least-to-Most | 서브문제 환원이 자연스러운 질문 |
| Decomposition | 사전 준비(스키마 링킹)나 후처리(refinement)가 필요할 때 |
| Autonomous Agents | 실세계 복잡 과제, DB 동적 탐색 필요 |
4.3.3 Demonstrations
워크플로우와 함께 시연(예시)도 핵심이다. Zero-shot vs Few-shot 분류 위에서 demonstration의 역할은 두 가지다.
(a) 작업 설명 대체: DIN-SQL의 fine-designed 단계처럼 인간 언어로 설명하기 어려운 워크플로우를 예시로 보여준다. BINDER도 SQL+API 호출이라는 확장 언어를 예시로 가르친다.
(b) SQL 코딩 능력 증대: 적절한 예시 선택이 핵심이다. 단순 질문 유사도만으론 부족하다. 같은 의도라도 스키마가 다르면 SQL이 크게 다르기 때문이다.
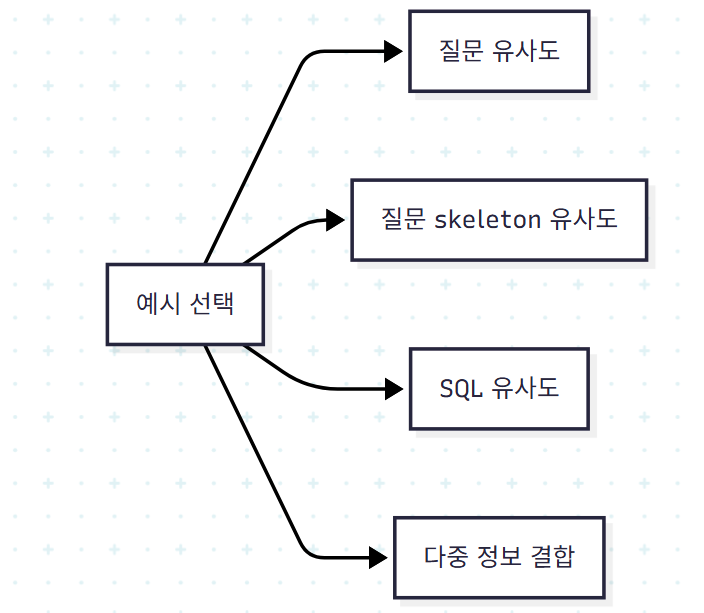
대표 전략들:
- De-semanticization, Retrieval & Revision, DAIL-SQL, DEA-SQL, PURPLE: 도메인 특화 단어를 마스킹한 skeleton으로 검색. PURPLE은 4단계 SQL skeleton 추상화
- Retrieval & Revision: 원래 질문 + LLM이 단순화한 질문 모두 사용
- DAIL-SQL: 질문 + SQL 모두로 검색. 토큰 비용을 위해 (질문, SQL)만 포함하는 압축 형식 채택
- Open-SQL: 질문 + 스키마 + SQL 모두 사용
- OpenSearch-SQL: mask question similarity
- MCS-SQL: 질문 유사도 + masked 질문 유사도 두 전략 결합
- ACT-SQL: 무작위 + 유사 예시 혼합으로 다양성 확보
Key Takeaways
- 복잡한 워크플로우를 가진 시스템은 demonstration을 task description의 일부로 활용
- Question skeleton이 원본 질문보다 의도를 더 잘 잡음
- 정확도와 토큰 비용 사이의 trade-off는 항상 고려
4.4 Post-processing
4.4.1 Self-Correction
생성된 SQL을 다시 검토해 수정하는 단계다.
- 공백 처리: Generic은 테이블 값의 잉여 공백을 다시 확인
- 재시도: RSL-SQL, OpenSearch-SQL은 빈 결과나 max round까지 재생성
- 스키마 확장 후 재시도: Retrieval 계열은 부분 schema가 실패하면 전체 schema로 재생성
- 에러 로그 활용: DIN-SQL, CHESS, MAC-SQL은 incorrect SQL과 실행 에러 정보를 프롬프트로 주고 재생성
- DEA-SQL: 필드 매칭과 SQL 문법의 오류 포인트별 특화 프롬프트
- SQLfuse SQL Critic: 외부 SQL 지식 베이스 + few-shot ICL로 hindsight feedback
4.4.2 Consistency Methods
Self-Consistency: 같은 LLM이 다양한 SQL을 생성하고 다수결.
- 직접 다수결: Open-SQL, BINDER, C3, DAIL-SQL, CHESS, OpenSearch-SQL 등 다수
- 실행 결과 기반 다수결: PURPLE
- Confidence + 실행 시간으로 선택: MCS-SQL
Cross-Consistency: 서로 다른 LLM/agent가 답을 만들고 비교.
- PET-SQL: 여러 LLM이 낮은 temperature로 SQL 생성 후 실행 결과로 투표
- R³: 다중 agent의 negotiation. Cross-Consistency + Self-Correction의 결합
- CHESS: Self-Correction과 Self-Consistency를 순차 적용
4.4.3 분석
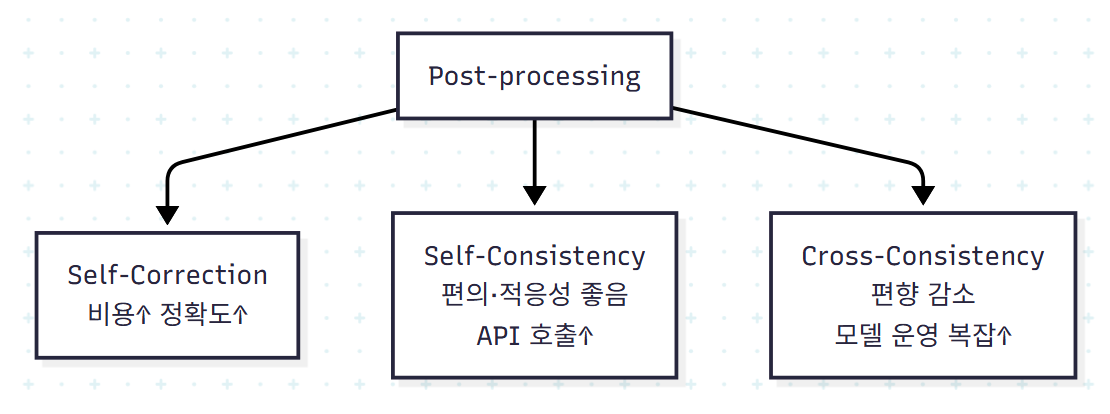
각 방법의 trade-off는 다음과 같다.
| 방법 | 장점 | 단점 |
|---|---|---|
| Self-Correction | 구체적 오류 수정 | 'critic' 능력의 한계 |
| Self-Consistency | 적응성·간단함 | 호출 N배 비용 |
| Cross-Consistency | 단일 모델 편향 감소 | 모델 운영 복잡도 |
Key Takeaways
- Self-Correction은 'refine'(수정)에 강하지만 'critic'(판단)은 탐색 여지
- Self-Consistency는 비용↑이지만 안정적 성능 향상
- Cross-Consistency는 단일 LLM 편향 완화
- 두 가지를 결합하는 것이 promising
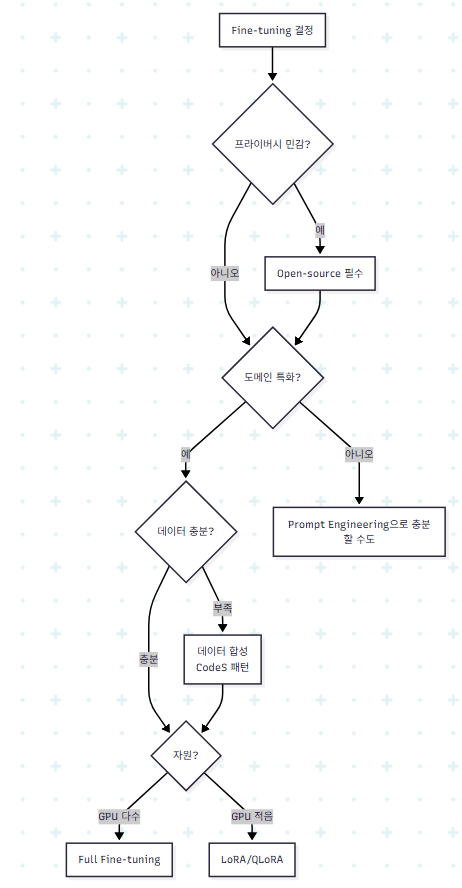
5. Fine-tuning
5.1 왜 Fine-tuning인가
저자들은 Fine-tuning이 필요한 이유를 두 가지로 본다.
- 프라이버시: GPT-4 API는 데이터 유출 위험. 오픈소스를 로컬에서 fine-tuning하면 해결.
- 성능 보강: 오픈소스 LLM은 SQL 관련 corpus가 적어 그대로는 약하다. Fine-tuning으로 보완.
수식으로 정리하면 다음과 같다.
여기서 는 (질문, DB 정보, 정답 SQL) 데이터셋이다.
5.2 Fine-tuning Objectives
대부분 SQL generation을 직접 fine-tuning한다. 그러나 흥미로운 변형들이 있다.
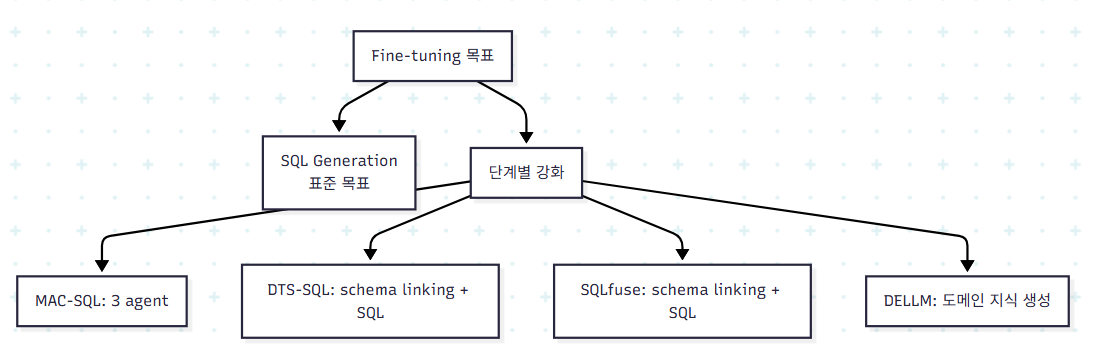
특히 DELLM은 흥미롭다. SQL을 직접 만드는 게 아니라 질문과 DB 정보로부터 도메인 지식을 생성하는 LLM을 fine-tuning한다. 그리고 그 지식을 다른 SQL 생성 LLM의 프롬프트에 주입한다. 즉 fine-tuning 대상이 SQL이 아닌 외부 지식 생산자가 되는 사례다.
5.3 Training Methods
두 흐름이 있다.
(a) Full Fine-Tuning (FFT): 모든 파라미터를 학습. 자원 많이 필요. MAC-SQL, CodeS, SQL-Palm.
(b) Parameter-Efficient Fine-Tuning (PEFT): 일부 파라미터만 학습.
- LoRA: Transformer 각 층에 trainable rank decomposition matrix 주입. 사전학습 가중치는 frozen
- QLoRA: LoRA + 4-bit NormalFloat + double quantization + Paged Optimizers. 메모리 사용량 감소
PEFT의 장점은 학습 효율, 비용, 그리고 catastrophic forgetting 저항성이다. 후자는 특히 중요하다. FFT는 LLM의 일반 능력을 잊을 위험이 있는데 PEFT는 덜하다.
| 방법 | 사용 사례 |
|---|---|
| FFT | MAC-SQL, CodeS, SQL-Palm |
| LoRA/QLoRA | OpenSQL, DELLM, FinSQL, SQLfuse |
5.4 Training Data
대부분 Spider/BIRD 학습셋을 그대로 쓴다. 그러나 두 가지 흥미로운 사례가 있다.
(a) FinSQL: 금융 도메인 특화 BULL 벤치마크 구축. Hundsun Technologies의 실제 펀드·주식·거시경제 분석 업무에서 수집. 공개 벤치마크가 산업 특성을 반영하지 못한다는 문제 제기.
(b) CodeS의 두 흐름:
- 일반 능력 강화: 21.5GB(SQL 11GB + NL-to-code 6GB + NL 4.5GB) 수집
- 도메인 적응: 소수의 실제 사용자 질의 + GPT-3.5로 few-shot 합성, SQL 템플릿에 새 도메인 데이터 plug-in
후자는 prompt engineering으로 fine-tuning 데이터를 만든다는 점에서 흥미롭다. 두 갈래가 서로 보완하는 사례다.
5.5 Model Evaluation
평가는 단순한 EX/EM 측정을 넘어서 다음을 다룬다.
- 난이도별 분류 (Spider의 4단계)
- 도메인별 분류 (BIRD의 37개 도메인)
- Perturbation 유형별 (Dr.Spider의 17종)
- 오류 유형별 분석 (schema-linking, JOIN, nested, group by)
- LLM Comparator 같은 모델 간 차이 시각화 도구
5.6 현황과 한계
저자들은 fine-tuning 연구가 prompt engineering보다 적은 이유를 두 가지 든다.
- API 비용이 낮은 closed-source 모델의 강력한 성능 때문에 prompt engineering이 우세
- Fine-tuning은 알고리즘적 혁신 포인트가 적음. 학습 기법, base 모델, 데이터 품질이 결정적인데 이는 점진적 발전이다
이 진단은 본 서베이의 prompt engineering 섹션이 fine-tuning보다 훨씬 긴 이유를 설명해준다.
Key Takeaways
- Fine-tuning은 SQL 생성뿐 아니라 워크플로우 각 단계의 성능 강화에 사용 가능
- PEFT(LoRA/QLoRA)가 FFT보다 선호됨
- 공개 벤치마크는 산업 DB 특성 부족
- LLM으로 데이터셋 자체를 만드는 것이 promising
6. Model
6.1 Closed-source Models
GPT-4는 가장 인기 있는 base 모델이다. ~13T 토큰으로 사전학습되었고 약 1.8T 파라미터 / 120 레이어 규모. CodeX는 14K 이상의 Python 코드를 메모리에 갖고 있어 코드 생성에 특화된다.
저자들의 흥미로운 관찰: "As of the time of writing, there is no closed-source LLM specifically for SQL code generation." 두 가지 추측 이유는 다음과 같다.
1. SQL은 비즈니스 데이터의 프라이버시와 얽혀 있어 학습 데이터 확보가 어렵다
2. SQL 전용 모델은 일반화 능력이 떨어질 수 있다
6.2 Open-source Models
오픈소스 모델은 다양한 크기로 제공된다.
- Llama 3: 8B, 70B
- Code Llama: 7B, 13B, 34B, 70B
- DeepSeek: 다양한 버전
- Qwen: 다양한 버전
- SQLCoder: Text-to-SQL 전용. 70B는 GPT-4를, 15B는 GPT-3.5-turbo를 능가하는 새 데이터셋 결과
특히 SQLCoder는 closed-source가 채우지 못한 "Text-to-SQL 전용 모델" 빈 칸을 채우려는 시도다.
6.3 사용 트렌드
논문 Figure 7이 보여주는 흐름을 정리하면 다음과 같다.

저자들은 이를 오픈소스 모델의 파라미터 규모 증가와 fine-tuning을 통한 도메인 적응 가능성이 결합된 결과로 본다. 미래 전망은 가장 강한 closed-source와 가장 강한 open-source가 양강 구도를 형성하리라는 것이다.
Key Takeaways
- Closed-source: 사용 편의성 + 강력한 코드 생성. 하드웨어 부족 사용자에게 적합
- Open-source: 독립 배포 + 프라이버시 + 도메인 fine-tuning 가능
- 선호 시리즈: Closed는 GPT, Open은 DeepSeek/Llama/Code Llama/Qwen
- 오픈소스 사용 빈도가 점차 closed-source와 비등해짐
7. 분석: 세 벤치마크 비교
7.1 평가 방법론
저자들은 Spider 1.0, BIRD, Spider 2.0의 공식 리더보드를 비교 기준으로 삼는다. 다음 5가지 선택 기준을 적용한다.
- LLM 활용 방법만
- 방법당 최대 2개 LLM
- 2022년 이전 모델 제외 (pre-ChatGPT)
- 비공개 모델 제외
- 비재현 가능 방법 제외
7.2 Spider 1.0 결과
대부분의 LLM 방법이 EX 80% 이상을 달성. 결론은 명확하다. Spider 1.0의 기본 Text-to-SQL은 이미 LLM에 의해 풀린 문제다. 더 어려운 벤치마크가 필요한 이유다.
7.3 BIRD 결과 분석
여기가 가장 흥미로운 부분이다. 저자들은 두 차원으로 분석한다.
(a) 모델 차원: closed-source와 open-source의 격차가 좁혀짐. Compact + fine-tuning 모델이 거대 LLM에 견줄 만함.
(b) 방법 차원: 같은 LLM 위에서 비교했을 때 상위 시스템들의 공통점은 다음 두 가지다.
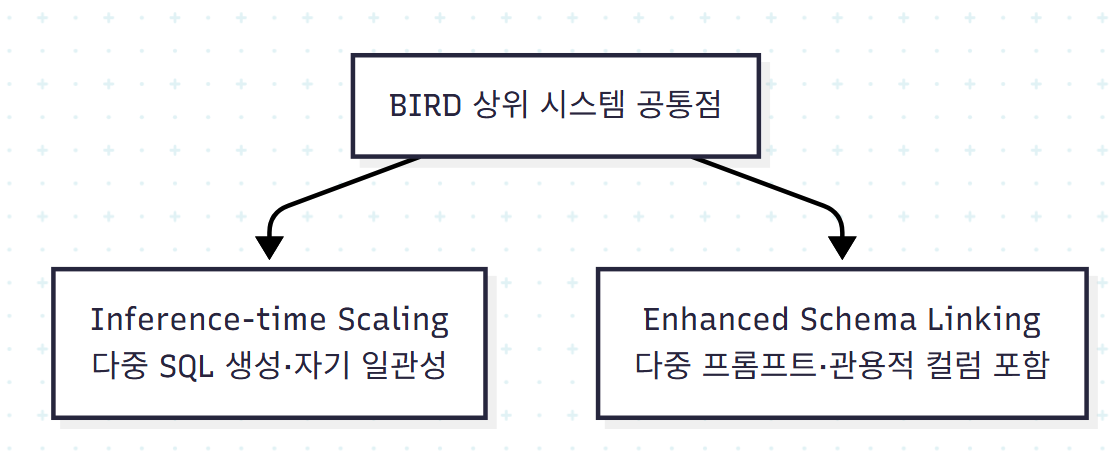
Characteristic 1: Inference-time Scaling
- OpenSearch-SQL: 다중 SQL 생성 + correction + self-consistency
- Distillery: iterative correction + self-consistency
- MCS-SQL: schema linking과 SQL 생성 모두에 다중 프롬프트
vs 베이스라인 (DIN-SQL은 단일 step correction, DAIL-SQL은 correction과 consistency 자체가 없음)
Characteristic 2: Enhanced Schema Linking
- Distillery: 모던 LLM이 무관한 컬럼에 관용적이라는 발견 → 컨텍스트가 허용되면 가능한 많은 컬럼 포함 권장
- MCS-SQL: inference-time scaling 자체가 schema linking 탐색 공간 확장
이 두 특성은 "답을 한 번에 잘 맞추려 하기보다, 여러 후보를 만들고 잘 고른다"는 공통 철학을 드러낸다.
7.4 Spider 2.0 결과 분석
Spider 2.0은 현실 엔터프라이즈 워크플로우를 측정한다. 주요 관찰점은 다음과 같다.
- 오픈소스가 여전히 closed-source에 못 미침: 다양한 SQL 방언, 복잡 문법, nested 컬럼 등 실제 엔터프라이즈 복잡성이 작용
- Reasoning-enhanced 모델 우세: o1-preview 같은 추론 강화 모델이 좋은 성과
- Non-agent vs Agent 격차: agent 기반이 큰 차이로 우세
대표 사례는 REFORCE다. 표준 Spider Agent를 다음으로 개선한다.
- table compression (컨텍스트 최적화)
- structured output formatting
- iterative column exploration (스키마 이해 향상)
- parallelized voting + CTE-based resolution의 self-refinement
그러나 SOTA가 31.26%에 그친다. 학술 진보와 실서비스 배포 사이의 큰 격차를 보여준다.
Key Takeaways
- Spider 1.0: 기본 Text-to-SQL은 LLM에 의해 거의 해결
- BIRD: inference-time scaling과 enhanced schema linking이 결정적
- Spider 2.0: agent 기반이 우세, 그러나 절대 성능은 아직 낮음
8. 미래 방향
8.1 오류 분석 정리
기존 연구들의 오류 분류는 다음 5범주로 수렴한다.
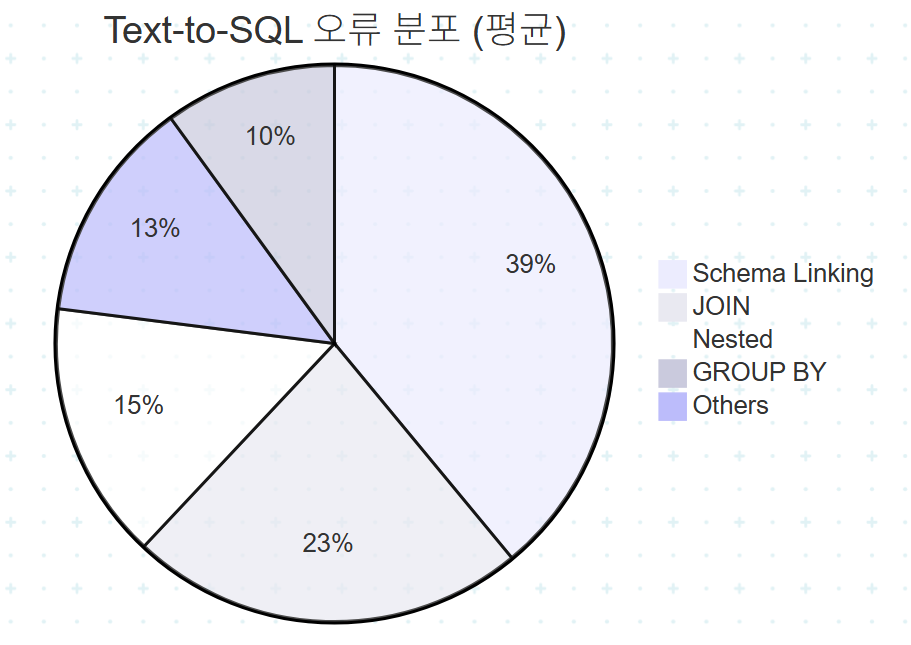
평균 비율을 정리하면:
- Schema Linking 29-49%: 가장 큰 오류 원인. 여전히 핵심 개선 대상
- JOIN 21-26%: 멀티테이블 처리의 어려움
- GROUP BY, Nested 각 20% 이하: 상대적으로 작은 비중
각 카테고리 안에서도 wrong column, wrong table, wrong condition 등 세부 분류가 가능하다. DIN-SQL의 경우 SELECT/FROM/WHERE/ORDER BY/GROUP BY 키워드별로 error/redundancy/insufficiency 같은 더 세밀한 분류를 한다.
충격적인 관찰: MAC-SQL이 SPIDER와 BIRD의 정답 자체에 20-30% 오류가 있다고 발견한 점이다. 이는 데이터 클리닝의 필요성을 직접 보여준다.
8.2 다섯 가지 도전과 방향
8.2.1 프라이버시
API 호출 시 프롬프트가 외부 서버로 전송되는 위험. 해결책은 오픈소스 LLM의 사설 배포 + fine-tuning이지만, 다음 문제가 있다.
- 더티 데이터
- LLM의 일반 능력 손상 가능
- catastrophic forgetting
핵심은 고품질 학습 데이터 추출 기법이다.
8.2.2 복잡 스키마와 부족한 벤치마크
저자들이 인용한 Microsoft 사례가 인상적이다. 내부 금융 데이터 웨어하우스는 632개 테이블 + 4,000개 이상 컬럼 + 200개 뷰 + 7,400개 이상 컬럼을 포함한다. 이런 규모에서는 다음 문제가 발생한다.
- Schema linking의 어려움
- LLM 주의력 분산 (토큰 폭증)
- 긴 추론 시간
해결 방향:
- Agent 기반 동적 탐색 (REFORCE, Spider 2.0)
- Self-consistency로 schema linking 오류 감소 (MCS-SQL)
- Dynamic graph attention 같은 새 메커니즘으로 적응형 그래프 표현
기존 벤치마크의 한계도 명확하다. Spider는 너무 단순하고, BIRD조차 실제 규모엔 못 미친다. Spider 2.0이 BigQuery·Snowflake 같은 실제 시스템을 도입해 좋은 방향을 제시한다.
8.2.3 도메인 지식
LLM의 일반 지식만으론 산업 용어·약어·은어를 처리하기 어렵다. 두 갈래가 있고 각각 한계가 있다.
| 접근 | 한계 |
|---|---|
| RAG 기반 prompt engineering | 노이즈 많은 비구조화 문서가 KB 구축 방해, 유사도 검색이 무관 정보 가져옴 |
| Fine-tuning | catastrophic forgetting, 지식 갱신 시 비싼 재학습 |
8.2.4 자율 에이전트
ReAct 프레임워크에 기반한 autonomous agent의 부상. 인간이 SQL을 작성하는 방식 자체가 trial-and-error의 반복인데, 이는 agent 모델링에 잘 맞는다.
REFORCE와 Spider 2.0의 Spider-Agent가 첫 사례다. Spider 2.0 리더보드에서 non-agent가 agent 기반보다 현저히 떨어진다는 결과는 이 방향의 잠재력을 보여준다.
8.2.5 데이터 거버넌스
현 데이터셋의 두 한계가 강조된다.
- Ambiguity: 의미적으로 다른 여러 SQL이 같은 NL의 답이 될 수 있음
- Semantic Mismatch: NL이 표현하는 의도를 DB가 (부분적으로) 답할 수 없음
데이터 거버넌스의 세 효익:
1. 도메인 지식 구조화 → RAG 효율 ↑, 모호성 ↓
2. 학습 데이터 품질 향상 → fine-tuning 강화
3. 벤치마크 정제 → 평가 신뢰성 ↑
9. 정리
9.1 핵심 한 줄
LLM 시대 Text-to-SQL은 Prompt Engineering(저데이터·빠름)과 Fine-tuning(프라이버시·도메인) 두 갈래로 나뉘며, 각 갈래는 pre/inference/post 또는 목표/방법/데이터/평가의 서브모듈로 더 분해된다.
9.2 의의
이 서베이의 의의는 실무 의사결정을 지원하는 분류 체계를 제공한 점이다. "어느 갈래를 택할까", "그 안에서 어느 워크플로우를 쓸까", "어떤 LLM을 base로 삼을까" 같은 질문에 명확한 가이드를 준다. 각 섹션 끝의 Key Takeaways는 그 자체로 압축된 의사결정 트리다.
Prompt Engineering 의사결정 트리
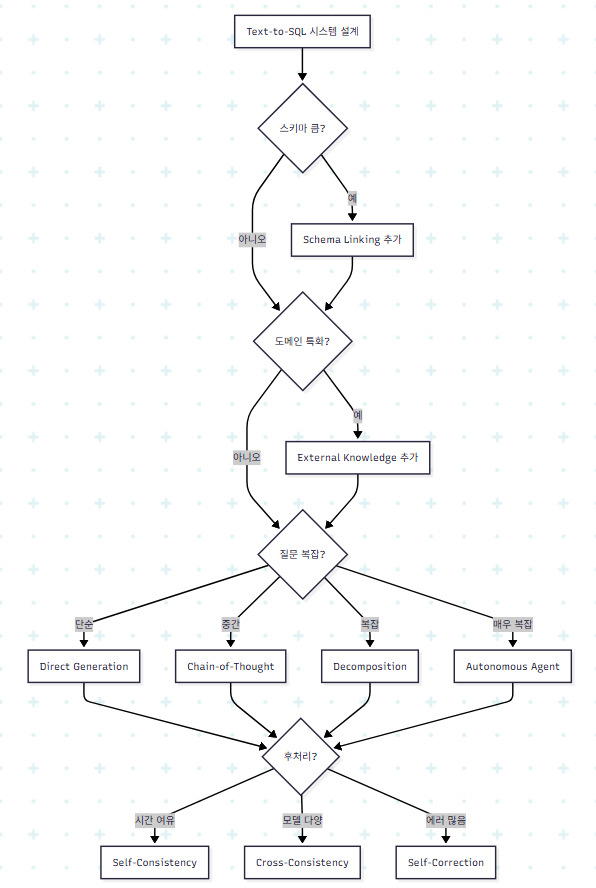
Fine-tuning 의사결정 트리