임베딩은 의미를 고차원 공간에 새기고, 그래프는 그 사이를 잇는다. Neo4j Vector Index는 두 검색 방식을 한 데이터베이스 안에서 결합한다.
Neo4j Vector Index는 vector 기반 유사도 검색과 graph traversal을 하나의 storage 계층에서 통합 운용할 수 있게 만든 indexing 구조다.
1. Vector Index가 필요한 이유
전통적인 데이터베이스의 index는 key·attribute 기반으로 탐색을 가속한다. 그러나 데이터가 고차원 vector로 표현되는 순간, 이러한 색인 방식은 적합하지 않다. 임베딩 공간에서 의미가 가까운 항목을 찾으려면 "정확히 일치하는 key"가 아니라 "공간상 가까운 좌표"를 질의해야 한다.
Vector index는 고차원 공간에서의 공간적 근접성(spatial proximity) 을 효율적으로 탐색하도록 설계된 특수 index다. 일반 index가 정렬된 key를 따라 트리 구조로 좁혀가는 것과 달리, vector index는 임베딩 벡터 사이의 거리 또는 각도를 기준으로 유사 항목을 회수한다.
이 구조의 실질적 이점은 두 가지다. 첫째, 대규모 임베딩을 메모리에 모두 적재하지 않고 데이터베이스에 위임할 수 있다. 둘째, Neo4j의 경우 vector 질의를 graph 질의와 동일한 storage 계층에서 처리하므로, 유사 문서 회수 후 그 문서가 속한 entity의 관계망을 곧바로 traversal 할 수 있다.

2. Neo4j Vector Index 생성
Neo4j에서 vector index는 Cypher의 procedure 호출로 생성된다. 다음은 Tesla 관련 텍스트를 위한 index 정의 예시다.
CALL db.index.vector.createNodeIndex(
'TeslaEmbeddings', // index 이름
'Chunk', // node label
'tesla_embedding', // property 이름
1536, // vector 차원 수
'cosine' // similarity metric
)각 parameter의 역할은 다음과 같이 정리된다.
| Parameter | 역할 | 결정 기준 |
|---|---|---|
| index 이름 | 질의 시 참조할 식별자 | 도메인·용도별 명명 |
| node label | embedding을 저장할 node 종류 | 보통 Chunk 또는 Document |
| property 이름 | embedding이 들어갈 속성명 | 동일 node에 여러 embedding 공존 가능 |
| vector 차원 수 | 임베딩 벡터의 길이 | 사용한 embedding 모델에 종속 (OpenAI text-embedding-ada-002는 1536) |
| similarity metric | 유사도 계산 방식 | NLP에서는 주로 cosine |
vector 차원은 임의로 정할 수 없다. 임베딩 모델이 출력하는 차원과 정확히 일치해야 하며, 모델을 교체하면 index도 재생성해야 한다.
3. Cosine Similarity와 거리 척도
NLP 임베딩 분석에서 cosine similarity가 표준에 가까운 이유는 벡터의 크기(magnitude)가 아니라 방향(direction) 만으로 의미적 유사성을 판정하기 때문이다. 두 벡터를 고차원 공간에 투영했을 때 사잇각이 작을수록 유사하다고 본다.
cosine similarity 외에도 Euclidean distance, dot product 등이 사용 가능하지만, 텍스트 임베딩은 일반적으로 정규화되어 있어 cosine이 가장 안정적인 결과를 보인다. 문서의 길이가 임베딩 norm에 영향을 주는 경우, 크기 정보를 무시하는 cosine이 노이즈에 덜 민감하다.
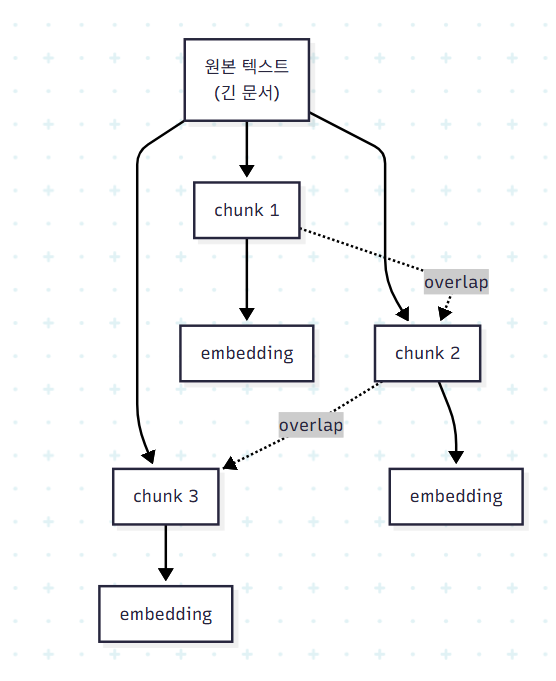
4. Chunking과 Overlap
LLM과 임베딩 모델은 입력 길이에 한계를 가진다. 따라서 긴 문서는 작은 단위로 분할해 각각 임베딩한다. 이때 두 가지 parameter가 결정적이다.
- chunk_size: 한 chunk에 포함되는 token 길이. 너무 작으면 의미 단위가 끊기고, 너무 크면 임베딩이 평균화되어 검색 정밀도가 떨어진다.
- chunk_overlap: 인접한 chunk 사이에서 겹치는 token 수. 문장 경계에서 끊긴 context를 보존하기 위한 장치다.
chunking은 단순한 전처리 단계로 보이지만, RAG 품질의 상한을 결정짓는 변수다. chunk가 의미 단위와 어긋나면, 아무리 좋은 retrieval 알고리즘도 잘못된 단위로 검색하게 된다.
5. Embedding 생성과 저장
Cypher로 index를 만든 뒤, 실제 embedding 적재는 LangChain의 Neo4jVector와 같은 wrapper로 처리할 수 있다.
hybrid_db = Neo4jVector.from_documents(
docs,
OpenAIEmbeddings(),
url=url,
username=username,
password=password,
index_name="TeslaEmbeddings",
search_type="hybrid"
)여기서 search_type="hybrid"는 vector 유사도와 keyword 검색(전문 검색)을 결합하는 옵션이다. 임베딩 검색은 의미적으로 가까운 항목을 잘 찾지만, 고유명사나 정확한 ID 매칭에는 약하다. hybrid 모드는 두 약점을 상호 보완한다.
6. Vector 검색과 Graph Traversal의 결합
Neo4j Vector Index의 진짜 가치는 vector 검색 결과를 곧바로 graph 질의와 이어 붙일 수 있다는 점이다. 일반적인 vector store는 유사 chunk를 반환하면 거기서 끝나지만, Neo4j는 회수된 Chunk node가 어떤 Document, Entity, Topic 등과 연결되어 있는지 같은 질의 안에서 추적할 수 있다.
| 구분 | Pure Vector Store | Neo4j Vector Index |
|---|---|---|
| 저장 단위 | 임베딩 + 메타데이터 | node + 임베딩 + 관계 |
| 검색 결과 | 유사 chunk 목록 | 유사 chunk + 연결된 subgraph |
| 후속 질의 | 별도 시스템 필요 | Cypher로 즉시 traversal |
| 적합 use case | 단순 의미 검색 | 의미 검색 + 관계 추론 |
비슷한 문서를 찾는 작업은 vector가 강점을, 그 문서를 둘러싼 관계를 따라가는 작업은 graph가 강점을 가진다. Neo4j Vector Index는 이 둘을 단일 backend에서 묶어 결과를 풍부하게 만든다.
7. 한계와 트레이드오프
vector index를 graph 데이터베이스 안에 통합하는 설계는 여러 장점을 제공하지만, 다음과 같은 비용을 동반한다.
첫째, 임베딩 모델 종속성. index 차원은 모델에 묶여 있다. embedding 모델을 1536차원에서 3072차원으로 교체하려면 index를 재생성하고 전체 chunk를 다시 임베딩해야 한다. 모델 ABI가 깨지는 셈이다.
둘째, chunking 전략의 비가역성. 한 번 chunk_size·overlap을 정해 임베딩을 만들고 나면, 이를 변경하려면 전체 데이터를 재처리해야 한다. 운영 중인 시스템에서 chunking 정책을 바꾸는 것은 단순한 hyperparameter 튜닝이 아니라 데이터 마이그레이션 작업이 된다.
셋째, vector 검색과 graph 검색의 인지 부담. 두 검색 방식을 결합하면 시스템은 강력해지지만, 질의를 설계하는 쪽의 책임도 커진다. 어느 단계까지를 vector로 회수하고, 어디서부터 graph traversal로 정밀도를 높일 것인가는 도메인별로 답이 다르다. 이 결정이 잘못되면 두 방식 모두의 장점을 잃는다.
8. 실무 적용 시 고려사항
운영 환경에서 Neo4j Vector Index를 도입할 때 우선 점검할 항목은 데이터 volume과 갱신 주기다. 임베딩 생성 비용은 token 수에 비례하므로, 정적 corpus에서는 한 번 적재하고 끝나지만 매일 수만 건의 문서가 추가되는 환경에서는 embedding API 호출 비용이 빠르게 누적된다. 이 경우 변경분만 재임베딩하는 incremental indexing 전략이 필수다.
또한 hybrid search를 활성화할 때는 keyword index와 vector index 중 어느 쪽 결과를 우선할지 가중치 조정이 필요하다. 두 결과의 점수 척도가 다르기 때문에, 단순 합산은 한쪽 신호를 압도하기 쉽다. 정규화 또는 reciprocal rank fusion 같은 결합 방식을 검토해야 한다.
참고 자료
- Graph Data Science with Python and Neo4j. Chapter 7: Neo4j Vector Index and Retrieval-Augmented Generation (RAG).
