1. KG 구축이 복잡한 이유: 의미적 heterogeneous 문제
Knowledge Graph 구축의 본질적 난점은 단순한 포맷 변환이 아니라 의미(semantics)의 통합에 있다. 책에서는 이 난점을 네 층위로 분해한다.
- 포맷 차이: XML, CSV, JSON 등 직렬화 형식이 제각각이다.
- 저장 기술 차이: 관계형 DB와 문서지향 DB의 모델이 다르다.
- 구문(syntax) 차이: 같은 날짜를
2022-08-09로 쓰기도,9 August 2022로 쓰기도 한다. - 의미(semantics) 차이: 가장 까다로운 층위다. 헬스케어 도메인의 예가 분명하다.
type 2 diabetes와ketosis resistant diabetes는 다른 표현이지만 동일 개념이며, 반대로PE라는 동일 약어는physical examination일 수도pulmonary embolism일 수도 있다. 거기에necrosis와lobular necrosis처럼 정보의 granularity 차이까지 더해진다.
이 네 층위 중 앞의 셋은 ETL 도구로 흡수 가능하지만, 의미 차이는 별도의 reference schema 없이는 풀리지 않는다. 그 reference 역할을 하는 것이 ontology다.
2. Ontology: heterogeneous 정보의 중재자
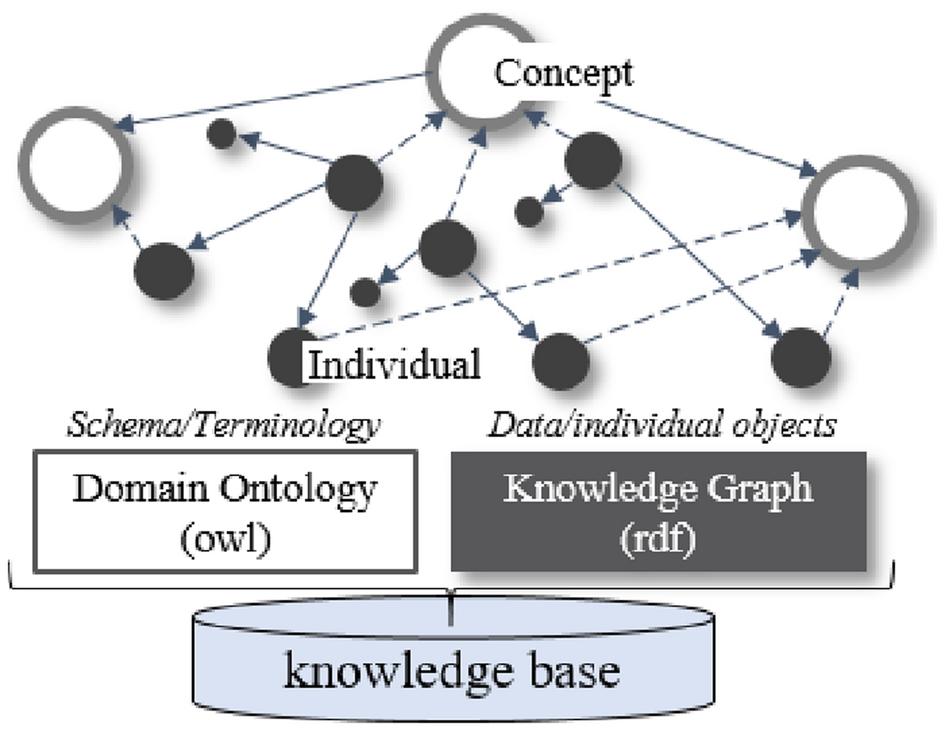
Ontology는 데이터에 등장하는 entity의 formal name, property, category, relationship을 표준 vocabulary로 모델링한 것이다. 책에서 ontology는 "semantically heterogeneous information의 intermediary"로 정의된다. 즉 각 데이터 소스의 local schema를 ontology의 reference schema로 mapping하는 구조다.
이 mapping 구조를 도식화하면 다음과 같다.
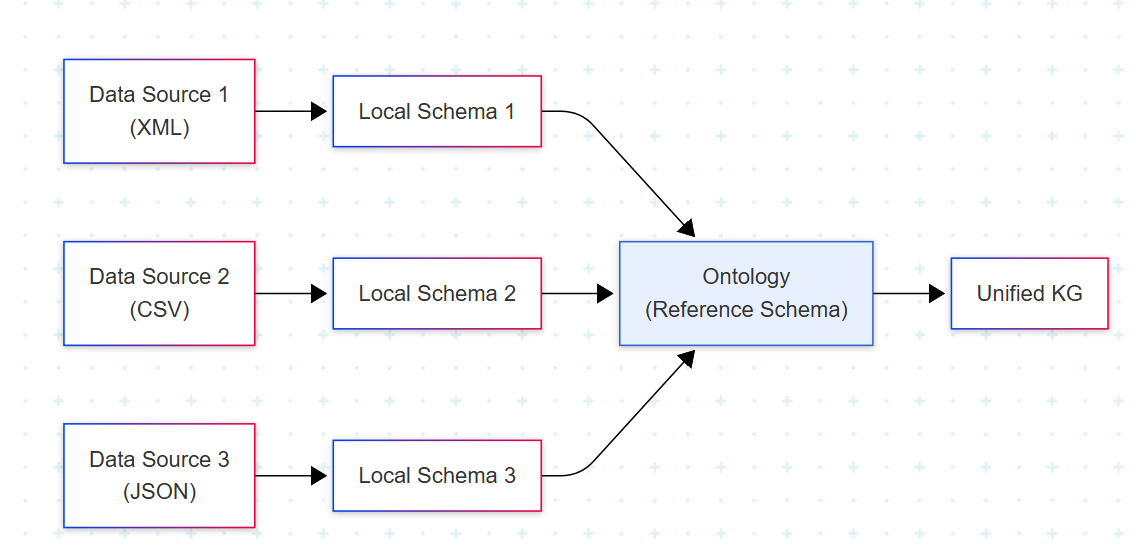
KG의 목표는 이렇게 단일 view로 융합된, unified·well-grounded·meaningful한 표현을 얻는 것이다. 개별 데이터 조각이 일관된 view 안에서 의미를 갖게 되어야 한다.
3. KG 구축 프로세스: CRISP-DM의 변형
책은 데이터 마이닝 표준 방법론인 CRISP-DM을 KG 구축용으로 각색해 제시한다. 단계별 책임이 명확히 분리된다.
| Phase | 역할 |
|---|---|
| Data Understanding | 정의된 목표에 부합하는 데이터를 식별 |
| Data Preparation | 현재 scope에서 관련 데이터를 추려 다음 단계 입력으로 만든다 |
| Modeling | ML task 알고리즘을 정의 |
| KG Model Creation/Update | 정의된 데이터·모델 기반으로 KG를 생성·갱신 |
| Evaluation | 구축된 KG가 목표를 충족하는지 검증 |
| Deployment | 운영 환경에 적용 |
이 절차는 일회성 빌드가 아니라 순환 구조라는 점이 중요하다. 도메인 이해가 깊어지거나 데이터 소스가 추가될 때마다 ontology 자체가 진화하고, 그에 따라 후속 phase가 다시 돌아간다.
4. 사례: HPO 기반 희귀질환 진단 지원
책의 실제 use case는 임상 현장이다. 임상의가 진단을 내리는 과정에는 명확한 검사 결과뿐 아니라 gray area가 포함된다. 이 불확실성을 다루기 위해 두 속성을 가진 structured knowledge base가 필요하다.
- phenotype 도메인의 contextual description: 같은 장기·계통과 관련된 phenotypic anomaly가 명시적으로 연결되어 있어야 한다.
- phenotypic anomaly와 disease 간 관계 추적성: 임상의가 연결의 근거 출처에 도달할 수 있어야 한다.
이 요구를 만족시키는 것이 HPO (Human Phenotype Ontology) 와 그 annotation 데이터다. HPO는 phenotype 계층을 제공하고, annotation 파일은 phenotypic abnormality와 disease를 연결한다.
5. RDF vs LPG: 두 갈래 기술 선택
KG를 구축하는 가장 대표적 두 모델이 RDF (Resource Description Framework) 와 LPG (Labeled Property Graph) 다. 둘은 같은 그래프를 표현하지만 설계 철학이 갈린다.
RDF의 구조
RDF는 W3C가 정의·관리하는 web 기반 데이터 교환 표준이다. 모든 statement가 subject–predicate–object의 triple로 구성된다. Subject는 노드, predicate은 edge, object는 또 다른 노드다. KG 전체가 이런 statement의 집합으로 모델링된다. 도메인 ontology 작성에 특히 적합하다.
LPG의 구조
LPG는 노드와 relationship에 key–value pair를 직접 붙일 수 있는 모델이다. 그래프 traversal과 path 분석에 최적화되어 있고, 저장·접근 효율이 강점이다.
핵심 차이: 메타데이터의 부착 위치
RDF에서 relationship(triple)은 전역적으로 정의된다. 즉 어떤 predicate에 메타데이터를 붙이면 그래프 전체에서 해당 relationship의 모든 instance에 영향이 간다. LPG는 반대로 edge별 unique 속성을 허용하므로 개별 relationship에 따로 메타데이터를 부여할 수 있다.
이 차이를 보완하기 위해 양쪽 모두 진화 중이다. RDF 측은 named graph로 triple 묶음에 컨텍스트를 부여하고, RDF-star로 edge에 property를 붙이는 길을 열고 있다. LPG 측은 Neo4j의 Neosemantics 플러그인으로 OWL·RDFS·SKOS 같은 RDF vocabulary를 LPG 위에서 활용 가능하게 하며, Amazon Neptune은 RDF 데이터에 Cypher를 실행하는 우회 경로를 제공한다.
| 비교 축 | RDF | LPG |
|---|---|---|
| 표준화 | W3C 표준 | 벤더별 구현 |
| 기본 단위 | Triple (subject–predicate–object) | Node·Relationship + key-value |
| 메타데이터 부착 | Predicate 단위 (전역) | Edge별 (지역) |
| 강점 | Knowledge representation, ontology 작성 | Traversal·path 분석 성능, 저장 효율 |
| Edge property | RDF-star로 부분 지원 | Native 지원 |
| 추론 | OWL 기반 inference 자연스러움 | 추가 도구 필요 (예: Neosemantics) |
| 컨텍스트 표현 | Named graph | Relationship property |
RDF 내부의 세 가지 모델링 전략
RDF가 edge에 속성을 붙이지 못한다는 한계를 우회하기 위해 세 가지 패턴이 통용된다.
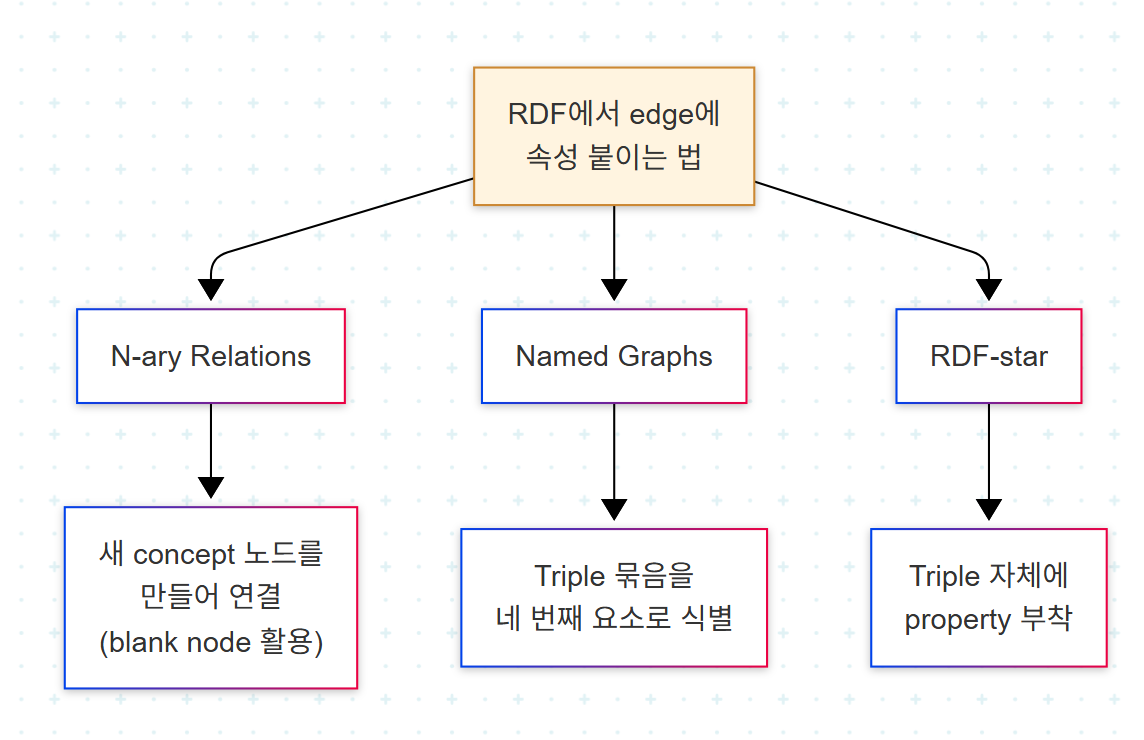
- N-ary relations: 데이터를 연결하는 새로운 concept을 만든다. 보통
_:Annotation같은 blank node로 표현되는데, 이는 전역 식별자 없이 관련 정보를 묶기 위한 unnamed resource다. ontology 진화에 따른 backward compatibility가 약점이 될 수 있다. - Named graphs: triple에 네 번째 요소를 추가해 statement가 어느 sub-graph에 속하는지 명시한다. provenance·context 표현에 강력하지만, named graph 수가 많아지면 저장·교환 효율이 떨어지고 fine-grained update가 어려워진다.
- RDF-star: triple 자체에 property를 붙일 수 있게 한 RDF 확장이다. 더 읽기 쉬운 SPARQL 쿼리가 가능하지만, query 성능이 아직 부족하고 새 syntax 확장이라는 특성상 RDF 엔진별 구현이 필요해 채택이 제한적이다.
이 외에 reification이나 singleton property 같은 방법도 존재하지만, 실무에서는 named graph와 n-ary relation이 더 자주 선택된다.
6. Neo4j로 HPO KG 만들기: 구축 단계
책은 LPG 진영의 Neo4j와 Neosemantics 플러그인을 사용해 HPO KG를 실제로 구축한다. 절차는 두 단계다.
- Ontology 로딩: HPO vocabulary 자체를 그래프에 적재
- Annotation 데이터 ingest: ontology를 reference로 삼아 disease–phenotype 연결을 채워 넣기
전체 파이프라인을 정리하면 다음과 같다.
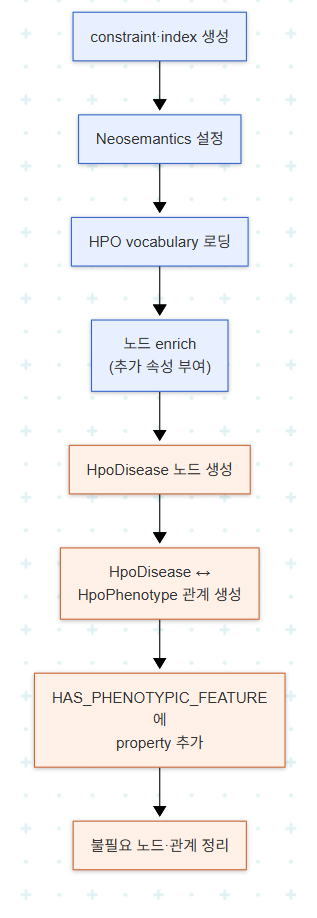
특히 HAS_PHENOTYPIC_FEATURE relationship에 속성을 붙이는 단계는 LPG의 강점을 잘 보여준다. 다음 의사코드는 TSV의 각 row에서 값이 존재하는 경우에만 property를 부여하는 패턴이다.
LOAD CSV WITH HEADERS FROM 'file:///annotations.tsv' AS row
FIELDTERMINATOR '\t'
MATCH (d:HpoDisease {id: row.disease_id})
MATCH (p:HpoPhenotype {id: row.phenotype_id})
MATCH (d)-[r:HAS_PHENOTYPIC_FEATURE]->(p)
FOREACH (_ IN CASE WHEN row.frequency IS NOT NULL THEN [1] ELSE [] END |
SET r.frequency = row.frequency
)
FOREACH (_ IN CASE WHEN row.onset IS NOT NULL THEN [1] ELSE [] END |
SET r.onset = row.onset
)FOREACH 블록은 해당 column 값이 null이 아닐 때만 property를 set하는 가드다. 결과적으로 missing data에 resilient하면서 기존 값을 null로 덮어쓰지 않는다. RDF의 전역 predicate 모델에서는 이런 per-edge 부분 갱신이 부자연스럽다.
7. Inference: KG의 진짜 가치
KG의 가장 강력한 활용은 저장된 정보를 그대로 조회하는 것이 아니라, logical rule 기반의 deductive reasoning으로 implicit 정보를 끌어내는 것이다.
예를 들어 "내분비계 이상(HP:0000818)을 동반하는 disease는 무엇인가"라는 질의를 생각해보자. 이 phenotype에 직접 annotation된 disease만 반환하면 답이 충분치 않다. 임상의는 갑상선 등 더 구체적인 hierarchy 하위의 phenotype까지 묶어 보고 싶어한다. HPO의 계층 구조가 ontology 안에 박혀 있기 때문에, subclass를 따라 traversal하는 단일 query로 implicit한 연결까지 회수할 수 있다.
이 지점이 단순 검색·문서 retrieval과 KG가 갈리는 지점이다. 계층·관계가 schema에 명시적으로 표현되어 있기 때문에, 질의 시점에 추론이 가능해진다.
참고 자료
- Knowledge Graphs and LLMs in Action. Manning, 2024 — Chapter 3: Create your first knowledge graph from ontologies
