Abstract
- 이전에 좋았던 모델(object Detection의 가장 좋은 성능 낸 모델): high-level context의 복잡한 앙상블 모델
- 30%이상 향상된 더 간단하고 확장 가능한 detection 알고리즘
-
객체를 localize 및 segment하기 위해 상향식 방식의 지역 제안(region proposal)에 CNN 적용
-
domain-specific fine-tuning을 통한 supervised pre-training을 적용
- Pre-training
임의의 값으로 초기화하던 모델의 가중치들을 다른 문제(task)에 학습시킨 가중치들로 초기화하는 방법
- fine-tuning
사전 학습한 모든 가중치와 더불어 downstream task를 위한 최소한의 가중치를 추가해서 모델을 추가로 학습(미세 조정) 하는 방법
1. Introduction
- CNN으로 image classification의 정확도는 많이 올라감
- Alex Net을 기반으로 큰 성능 향상을 달성
- CNN이 PASCAL VOC와 같은 Object detection에서는 좋은 성능을 가질 것인가→ 있을 듯… 저자 曰
- deep network을 통한 localization, 적은 양의 data로 모델 학습시키기
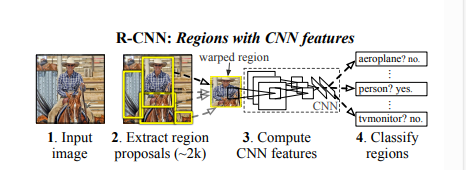
- (R-CNN 어떻게 진행되는지 설명)
- region proposals 추출 → 추출한거 전처리 → CNN 돌려서 분류
- Selective search 알고리즘을 통해 객체가 있을 법할 위치인 후보 영역(region proposal)을 2000개 추출하여, 각각을 227x227 크기로 warp시켜준다.
- Warp된 모든 region proposal을 Fine tune된 AlexNet에 입력하여 2000x4096 크기의 feature vector를 추출한다.
- 추출된 feature vector를 linear SVM 모델과 Bounding box regressor 모델에 입력하여 각각 confidence score와 조정된 bounding box 좌표를 얻는다.
- 마지막으로 Non maximum suppression 알고리즘을 적용하여 최소한의, 최적의 bounding box를 출력한다
2. Object detection with R-CNN
R-CNN 3가지 모듈로 구성
- Category-independent region proposals- Selective Search
- Large CNN that extracts a feature vector from each region
- Set of class-specific linear SVMs
Region proposals
- Region Proposal: 주어진 이미지에서 물체가 있을법한 위치를 찾는 것
- 최적의 region proposal를 제안: Selective Search → 임의의 (크기, 비율)로 모든 영역을 탐색하는 것은 너무 느림 > 비효율성 극복
- 이미지의 초기 세그먼트를 정하여, 수많은 region 영역을 생성
- greedy 알고리즘을 이용하여 각 region을 기준으로 주변의 유사한 영역을 결합
- 각 단계에서 최적이라고 생각되는 것을 선택해 나가는 방식으로 진행하여 최종적인 해답에 도달하는 알고리즘 (최적의 값의 근사한 값을 목표)
- 결합되어 커진 region을 최종 region proposal로 제안
- 최종적으로 2000개의 region proposal을 생성 → 같은 사이즈로 warp: CNN output 사이즈를 동일하게 만들기 위해
Feature extraction
- Selective Search를 통해서 찾아낸 2천개의 박스 영역은 227 x 227 크기로 리사이즈 (warp)
- Image Classification으로 미리 학습되어 있는 CNN 모델을 통과하여 4096 크기의 특징 벡터를 추출
Test-time detection
- 피처를 활용해 SVM으로 각 클래스별 점수를 계산
- Non-Maximum Suppression(가장 확실한 bounding box만 남기고 나머지 bounding box는 제거) 를 수행: 점수가 높은 후보 영역 (bounding box)를 기준으로 IoU가 특정 임계값을 넘는 다른 경계 박스는 모두 제거
Training
Supervised pre-training
- ILSVRC2012 분류 데이터셋으로 R-CNN을 사전 훈련
- ILSVRC2012 분류 데이터셋에는 경계 박스 정보가 없음 → 이미지 레이블만 사용해서 훈련
Domain-specific fine-tunning
-
사전 훈련한 CNN 모델을 새로운 객체 탐지 영역에 적용하기 위해
-
SGD(Stochastic Gradient Descent)알고리즘 이용
-
객체 탐지에 맞게 구조를 바꾸려면 최종 출력층이 (N + 1)개 값을 내놓도록 바꿔야 함.
-
1을 더한 이유: 배경 때문
-
실제 bounding box와의 IoU가 0.5 이상인 후보 영역 bounding box만 positive로 여기고, 나머지는 negative로 여긴다
-
positive bounding box는 해당 객체를 표시하는 bounding box로 간주
-
negative bounding box는 배경을 뜻하는 bounding box로 간주
Object category classifiers
- 애매하게 걸친 bounding box → positive인지 negative인지 구분하기 애매…
- sol: 임계값 이용→ IoU 임계값이 0.3일 때 성능이 가장 좋았음
+) 파인튜닝할 땐 IoU 임계값을 0.5로 설정했는데, SVM을 훈련할 땐 IoU 임계값을 0.3으로 설정
3. Visualization, ablation, and modes of error
3.1. Visualizing learned feature
- 목적: CNN이 어떤 것을 학습했는지 시각화하는 것
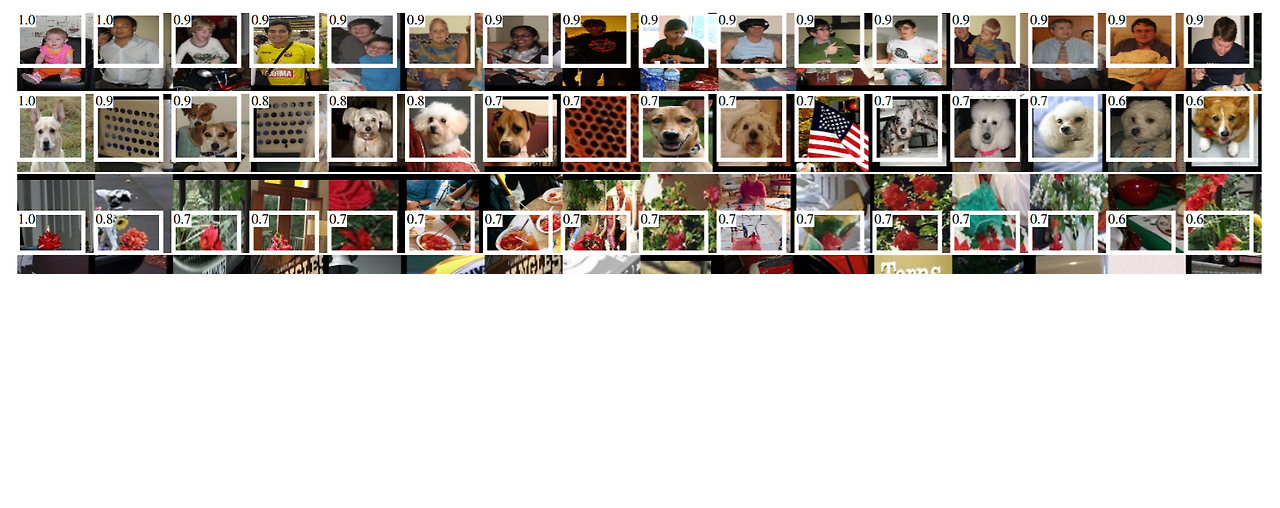
- 첫번째 계층 필터 역할: 경계와 보색 찾는다
- 유닛의 활성화 계산: 활성화가 높은 순서대로 제안들을 정렬
- non-maximum suppression를 수행하여 상위 점수의 지역을 표시
→ 객체를 잘 식별해줄 후보 영역(경계 박스)만 남는다
⇒ 모양, 질감, 색깔 등의 특성을 종합해 객체를 학습
3.2. Ablation studies
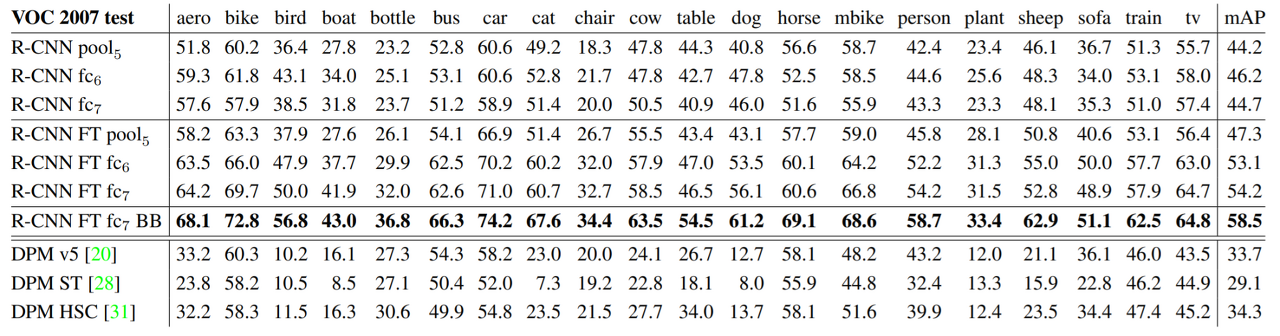
- 파인튜닝을 한 CNN이 파인튜닝을 하지 않은 CNN보다 성능이 더 좋다. (4~6)
- bounding box regression 학습→ 더 좋은 성능 (7)
3.3 NETWORK Architectures

- O Net: VGG NET // T Net: Alex Net
- VGG Net(O Net)에 적용한 것이 더 우월 but 연산 시간이 T-Net에 비해 길다
3.4. Detection error analysis
- 객체 탐지 기법의 오류를 분석하는 방법
3.5. Bounding-box regression
- 오류를 줄이기 위한 간단한 방법
- bounding box 위치 선정을 교정 + 성능 높이는 과정
- 추출한 후보 영역 bounding box를 실제 경계 박스와 일치하도록 회귀 모델을 만들어 훈련
4. The ILSVRC2013 detection dataset
4.1. Dataset overview
- 검증 데이터와 테스트 데이터는 이미지 분포가 서로 비슷하고, 완전히 annotation되어 있음
- annotation: 모든 객체에 경계 박스가 표시돼 있고, 클래스명도 기재된 거
- 훈련 데이터는 완벽히 annotation되어 있지 않음 → hard negative mining 적용 어렵당
- hard negative mining: 모델이 예측에 실패하는 ****어려운 sample들을 모으는 기법
- sol) 검증 데이터 일부를 훈련 데이터로 활용
…
⇒ 훈련 데이터 많을수록 좋다,
한계
- 모델이 너무 복잡→ 과도한 연산량
- Selective Search는 CPU를 사용하는 알고리즘( GPU는 13초 걸리는게 CPU는 53초나 걸림ㄷㄷㄷ) → real-time 분석이 어렵다
