Abstract
- regression problem으로 정의
- 이미지 전체에 대해서 하나의 신경망(a single neural network)이 한 번의 계산만으로 bounding box와 클래스 확률(class probability)을 예측
- 객체 검출 파이프라인이 하나의 신경망으로 구성
- 빠르다! → 1초에 45프레임 처리 (?)
- 이미지 전체를 본다는점에서→ 해당 클래스의 맥락정보, 모습을 encode해서 background error를 절반 가량 줄일 수 있다.
- background error: 배경 이미지에 객체가 있다고 탐지한 것
- 자연 이미지(natural image)로 학습한 후 그림(artwork)에서 test를 진행해도 다른 모델들 보다 좋은 성능을 보임
1. Introduction
<비교> 기존모델의 문제?
- DPM: sliding window 기법을 이용

-
R-CNN:
- 2 Stage:
- 1) 객체가 검출될만한 곳 찾기(region proposal-selective search 이용해서)
- 2) 1단계에서 선택된 곳에서 무슨 물체인지 구분하기
-
느림🐢🐢🐢 최적화 어렵다 ⇒ 각 요소 개별적으로 학습하니까
-
Yolo이름 유래(You Only Look Once)
you only look once (YOLO) at an image to predict what objects are present and where they are.
- 이미지 한 번만 보면 객체 검출 쌉가능!!
Yolo의 장점
- 굉장히 빠르다
- 기존의 복잡한 프로세스→ 하나의 회귀문제
- 다른 실시간 객체 검출 모델보 2배 이상의 mAP를 보여준다.
- 예측 시 이미지 전체를 본다
- 훈련과 테스트 단계에서 이미지 전체를 본다
- 클래스 정보 + 주변 정보까지 학습
→ background error가 Fast R-CNN에 비해 훨씬 적다!
- 물체의 일반적인 부분을 학습한다
- 검출 정확도가 높다:
- 훈련 단계에서 보지 못한 새로운 이미지에 대해 더 robust하다
단점
-
최신 객체 검출 모델에 비해 정확도가 다소 떨어진다
- 특히 작은 물체
-
trafe off 관계 : 속도, 정확성
2. Unified Detection
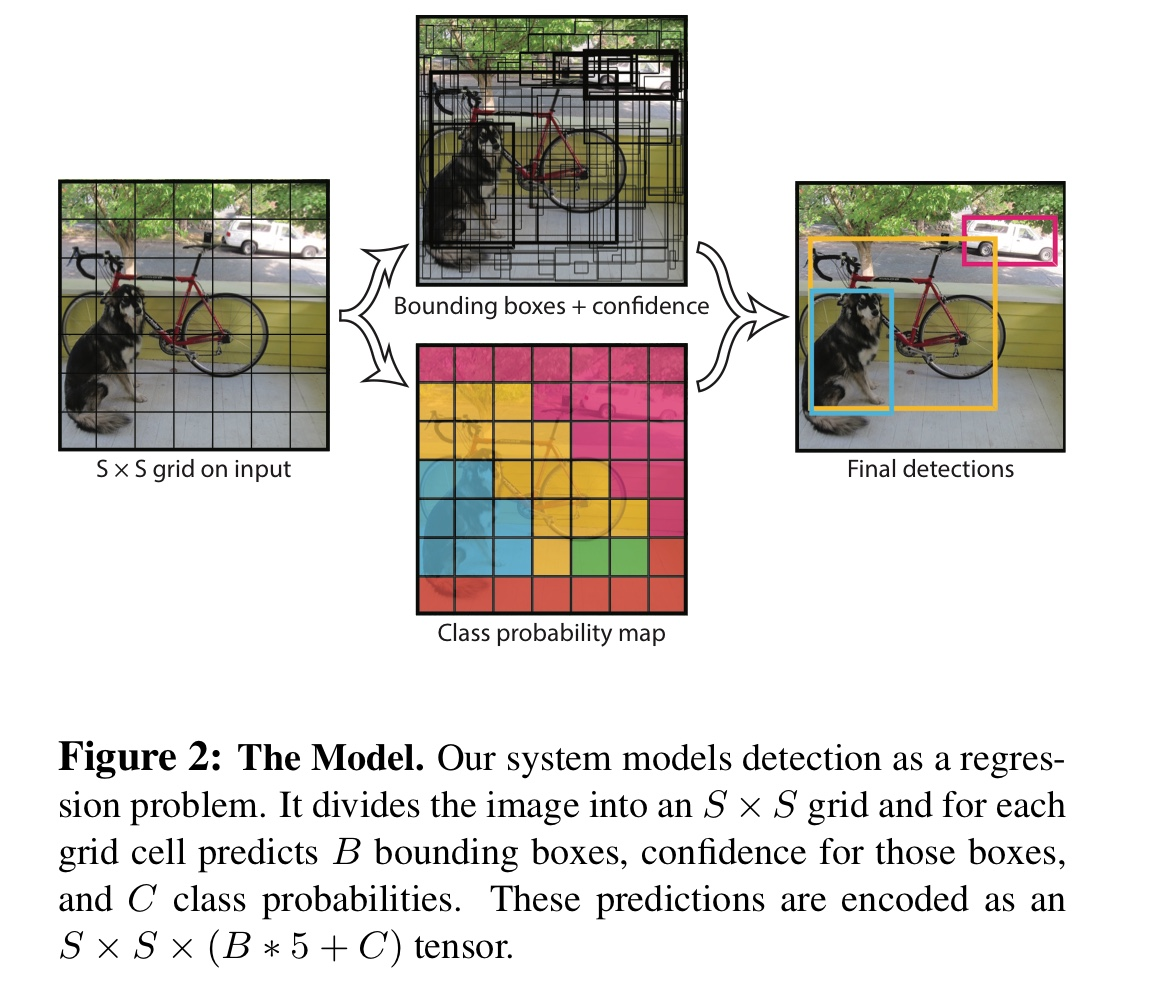
- 먼저 전체 이미지를 SxS 크기의 grid로 나눈다
→ 어떤 객체의 중심이 특정 grid안에 위치하면 그 셀이 해당 객체를 검출해야 함
-
grid는 B개의 bounding box와 그 bounding box에 대한 confidence score를 예측
- confidence score: 얼마나 자신있게(? )박스가 객체를 포함하고 있는지, 얼마나 정확하게 예측했는지를 반영
- Pr(Object) * IoU
- pr(object) = 해당 Grid cell에 물체가 존재할 확률
- cell에 객체 존재x: confidence score= 0
- 셀에 어떤 객체가 확실히 있다고 예측한 거 , 즉 Pr(Object)=1일 때가 가장 이상적
-
bounding box는 5개의 예측치로 구성: x, y, w, h, confidence
-
(x,y): bouding box 중심의 grid cell 내 상대 위치(0~1)
→그리드 셀 중앙에 위치했다면: (x,y) =(0.5,0.5) -
(w,h): bounding box의 상대 너비와 상대 높이
→ 이미지 전체의 비와 높이를 1이라고 했을 때 bounding box의 너비와 높이
- 각 그리드셀은 conditional class probabilities 예측( 하나의 class만!)
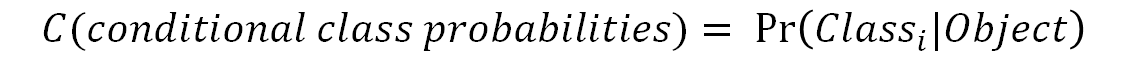
- conditional class probabilities:
- 셀 안에 객체가 있다는 조건 하에 그 객체가 어떤 class인지에 대한 확률
- bounding box가 있는지와는 무관하게 하나의 그리드 셀에는 오직 하나의 클래스에 대한 확률 구한다!

class-specific confidence score 구하기
- class-specific confidence score: conditional class probability(C)와 개별 boudning box의 confidence score를 곱한 거
- bounding box에 특정 클래 객체가 나타날 확률(Pr(Class_i))과 예측된 bounding box가 그 클래스 객체에 얼마나 잘 들어맞는지
2.1. Network Design
-
네트워크 구조: GooglENet model 이용
-
24 Conv layers→ 이미지로부터 특징을 추출
-
2개의 Fc layer → 클래스 확률과 bounding box의 좌표(coordinates)를 예측
-
GooglENet은 inception module
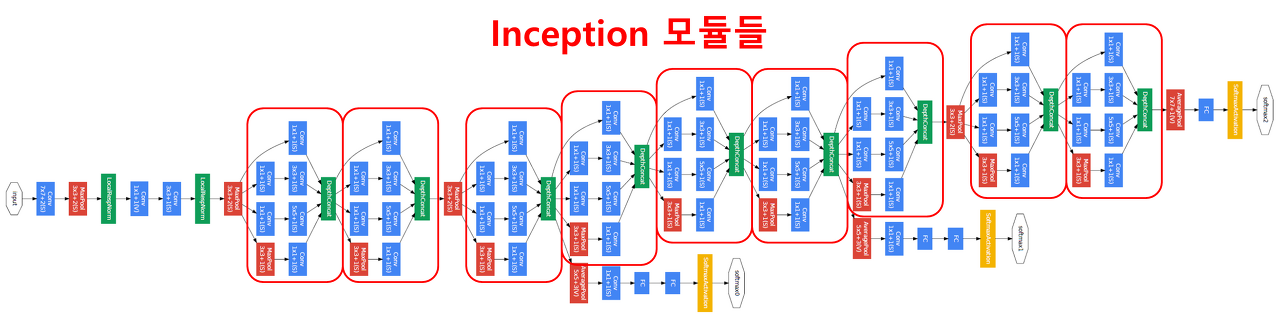
- inception module: 모든 결과를 채널을 기준으로 결합→ 결합 함으로써 여러가지 필터를 한꺼번에 합쳐 다양한 Feature Map을 가져올 수 있다- YOLO는 단순한 컨볼루션으로 네트워크를 구성
- 1 x 1 reduction layer과 3 x 3 컨볼루션 계층의 결합 (일자로 이어둔 모델 사용)
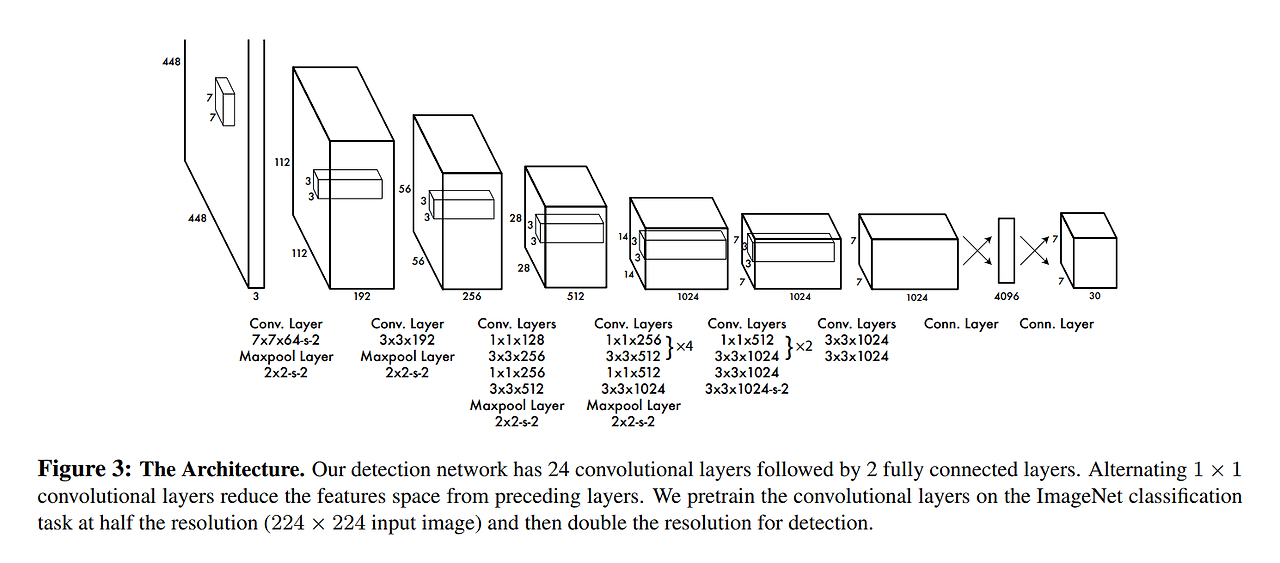
- Fast YOLO
- 좀 더 빠른 객체 인식 속도를 위해 YOLO보다 더 적은 컨볼루션 계층(24개 대신 9개)과 필터를 사용
- 크기만 다를 뿐이고 훈련 및 테스트 시 사용하는 나머지 파라미터는 YOLO와 모두 동일
2.2. Training
-
ImageNet data(1,000개의 클래스)에 대해 pretrain
- 24개의 컨볼루션 계층 중 첫 20개의 컨볼루션 계층만 사용, fc layer를 연결
- 약 1주간 훈련, ImageNet validation set에서 정확도 88% 나옴.
- training과 inference를 위해 Darknet framework를 사용
- 24개의 컨볼루션 계층 중 첫 20개의 컨볼루션 계층만 사용, fc layer를 연결
-
사전 훈련된 분류 모델을 객체 검출(object detection) 모델로 바꾸기
- 20개 컨볼루션 계층 뒤에 4개의 컨볼루션 계층 및 2개의 전결합 계층을 추가
- 가중치는 random initialized로 초기화
- 20개 컨볼루션 계층 뒤에 4개의 컨볼루션 계층 및 2개의 전결합 계층을 추가
-
객체 검출을 위해서는 이미지 정보의 해상도가 높아야 해서
- 해상도를 224 x 224 → 448 x 448로 증가
-
신경망의 최종 아웃풋: 클래스 확률과 bounding box 위치정보
- 너비, 높이, 중심 좌표값(w, h, x, y)을 모두 0~1 사이의 값으로 정규화
-
activation function
- 마지막 계층에는 linear activation function를 적용
- 나머지 모든 계층에는 leaky ReLU를 적용
- Reaky ReLU는 기존 ReLU가 0보다 작을 때 gradient가 사라지는 현상을 막아준다
-
Loss: SSE(sum-squared error)를 기반 // SSE가 최적화하기 쉬워서
- 문제점1
- localization error와 classification error를 동일하게 가중치를 둔다
- 객체를 포함하고 있지 않은 grid cell은 confidence 값이 0을 갖는다 ⇒ grid cell의 gradient를 폭발 ⇒ 불안정
- 해결한 방법
- 객체가 존재하는 bounding box 좌표(coordinate)에 대한 loss의 가중치를 증가
- 객체가 존재하지 않는 bounding box의 confidence loss에 대한 가중치는 감소 → 두 개의 파라미터를 사용) λcoord=5 , λnoobj=0.5
- λcoord: 바운딩 박스 좌표 손실에 대한 파라미터 ⇒ 높은 패널티를 부여
- λnoobj : 객체를 포함하고 있지 않은 박스에 대한 confidence 손실의 파라미터 : 패널티를 낮추는 것
- 문제점2
- 큰 bounding box와 작은 boudning box에 대해 모두 동일한 가중치로 loss를 계산
- 해결한 방법
- bounding box의 너비(widht)와 높이(hegith)을 제곱근 이용해서 계산
- 문제점1
-
YOLO는 하나의 그리드 셀 당 여러 개의 bounding box를 예측
- 훈련 단계에서 객체 하나당 하나의 bounding box와 매칭을 시켜야
- 여러 bounding box 中 실제 객체를 감싸는 ground-truth boudning box와의 IOU가 가장 큰 것을 선택 ( 객체 잘 감싸는 거 선택)
-
loss function 살펴보자 ^0^
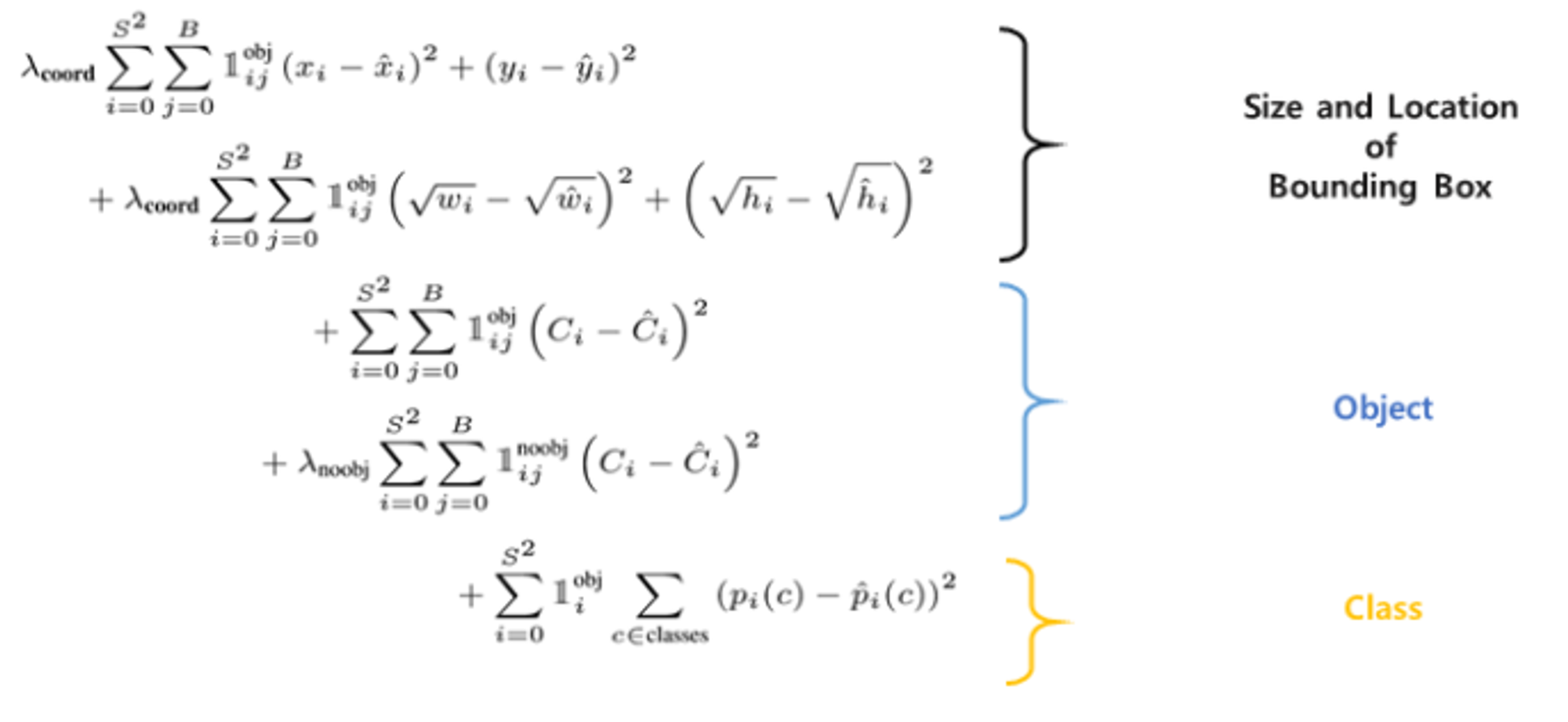
1) object가 존재하는 bounding box 의 x,y(상대 위치)의 loss계산
- x,y는 바운딩 박스 좌표
- 정답 좌표랑 예측 좌표 차이를 제곱하여 error를 계산
- obj는 객체가 탐지된 bounding box (i번째 grid에서 j번째 객체를 포함한 바운딩박스?)
2) object가 존재하는 bounding box 의 너비와 높이에 대한 loss계산
3) 객체를 포함한 바운딩 박스에 대한 confidence loss 계산
4) 객체를 포함하지 않은 바운딩박스에 대해 confidence loss 계산
5) p(c) 클래스 확률에 대한 계산: classification error
- gird cell i안에 객체가 존재하는지 여부 ( 있으면1, 없으면 0) ⇒ 객체를 포함한 바운딩박스에 대해서만 계산
- batch size = 64
- momentum = 0.9
- decay = 0.0005
- lr을 0.001 → 0.01로 천천히 상승
- 이후 점점 증가시켰다가 다시 감소시킴
- 과적합 막기 위해 dropout(0.5)과 data augmentation을 적용
2.3. Inference
- 테스트 이미지로부터 객체를 검출하는 데에는 하나의 신경망 계산
-
파스칼 VOC 데이터 셋에 대해서 YOLO는 한 이미지 당 98개의 bounding box를 예측한다
-
그 bounding box마다 클래스 확률을 구한다
⇒ R-CNN 이랑 다르게 하나의 신경망 계산만 필요해서 테스트 단계에서 굉장히 빠름
-
2.4. Limitations of YOLO
- 공간적 제약 :
- YOLO는 하나의 그리드 셀마다 두 개의 bounding box를 예측 ,하나의 그리드 셀마다 오직 하나의 객체만 검출
- ⇒ 하나의 그리드 셀에 두 개 이상의 객체가 붙어있다면 이를 잘 검출하지 못한다
예) 새 떼와 같이 작은 물체가 몰려 있는 경우 공간적 제약 때문에 객체 검출이 제한적이다
-
Train dataset에 존재하는 bounding box의 형태(가로,세로 비)와 다를 경우 일반화하는데 어려움이 있다
- YOLO 모델은 데이터로부터 bounding box를 예측하는 것을 학습하기 때문
-
부정확한 localization 문제
- 큰 bounding box와 작은 bounding box의 loss에 대해 동일한 가중치를 둔다
- 크기가 큰 bounding box는 위치가 약간 달라져도 비교적 성능에 별 영향을 주지 않음
- but 크기가 작은 bounding box는 위치가 조금만 달라져도 성능에 큰 영향을 줄 수 있다
- 작은 bounding box가 위치 변화에 따른 IOU 변화가 더 심하기 때문
3. Comparison to Other Detection Systems (넘어가자👩🦱 ^ㅡ^ Intro랑 겹침..)
- DPM
- sliding window 방식을 사용
- 서로 분리된 파이프라인으로 구성(특징 추출/ 위치 파악)
- but YOLO는 파이프라인을 하나의 컨볼루션 신경망으로~
- R-CNN
- 복잡한 파이프라인( region proposal/ selective search / SVM /box regression/ non-max suppression)
- 정확도 높아도 짱 느려서 실시간 비추
- but YOLO는 파이프라인을 하나의 컨볼루션 신경망으로~
4. Experiments
- 다른 실시간(real-time) 객체 검출 모델과 비교
- Fast R-CNN이 젤 좋았따 (이 논문이 나온 시점을 기준으로)
4.1. Comparison to Other Real-Time Systems
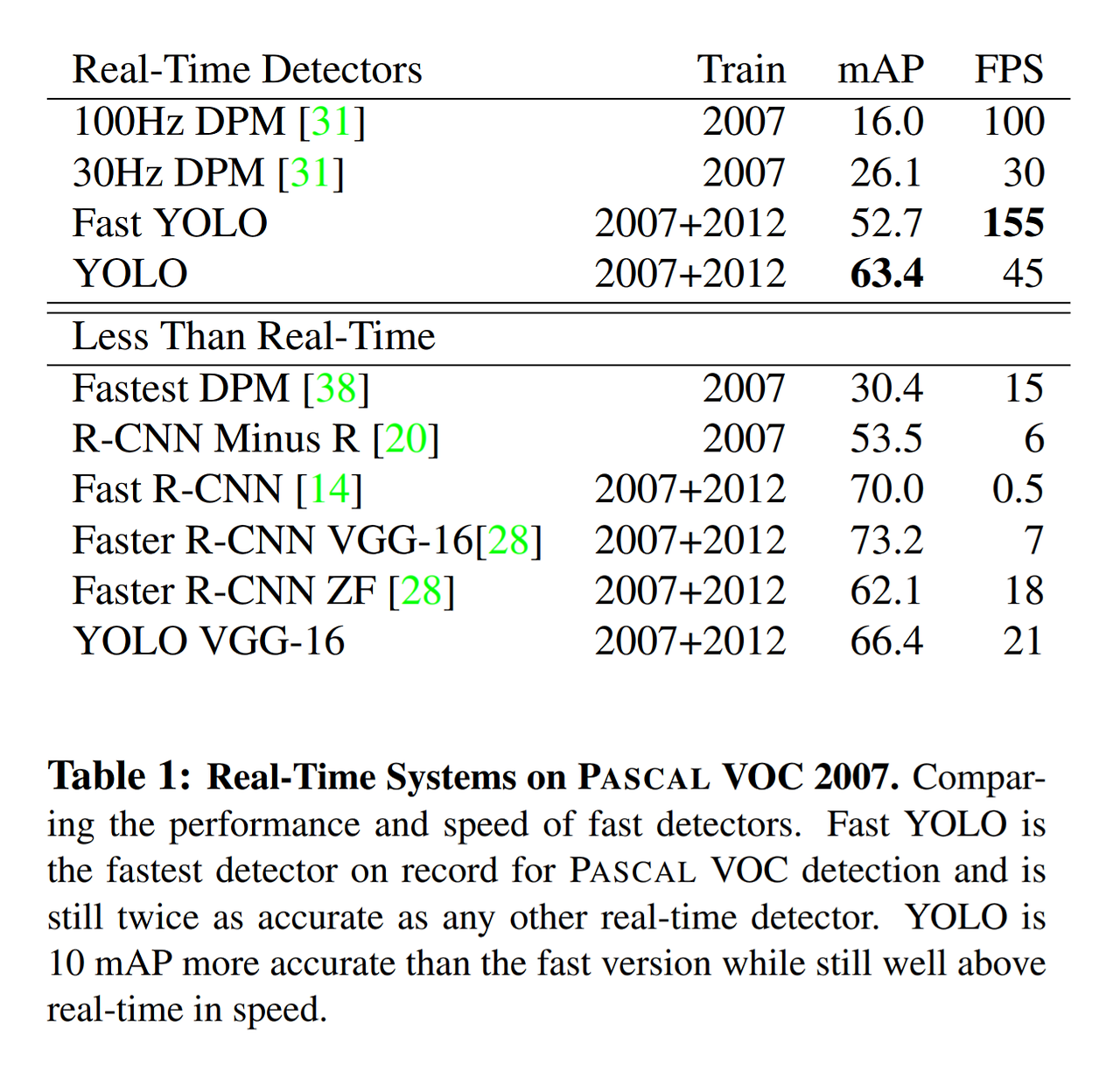
- 정확도는 Fast R-CNN과 Faster R-CNN VGG-16이 가장 높지만 FPS는 너무 낮아서 실시간 객체 검출 모델로 사용할 수는 없다
- YOLO 계열은 정확도도 적당히 높고 속도도 빠르다
4.2. VOC 2007 Error Analysis
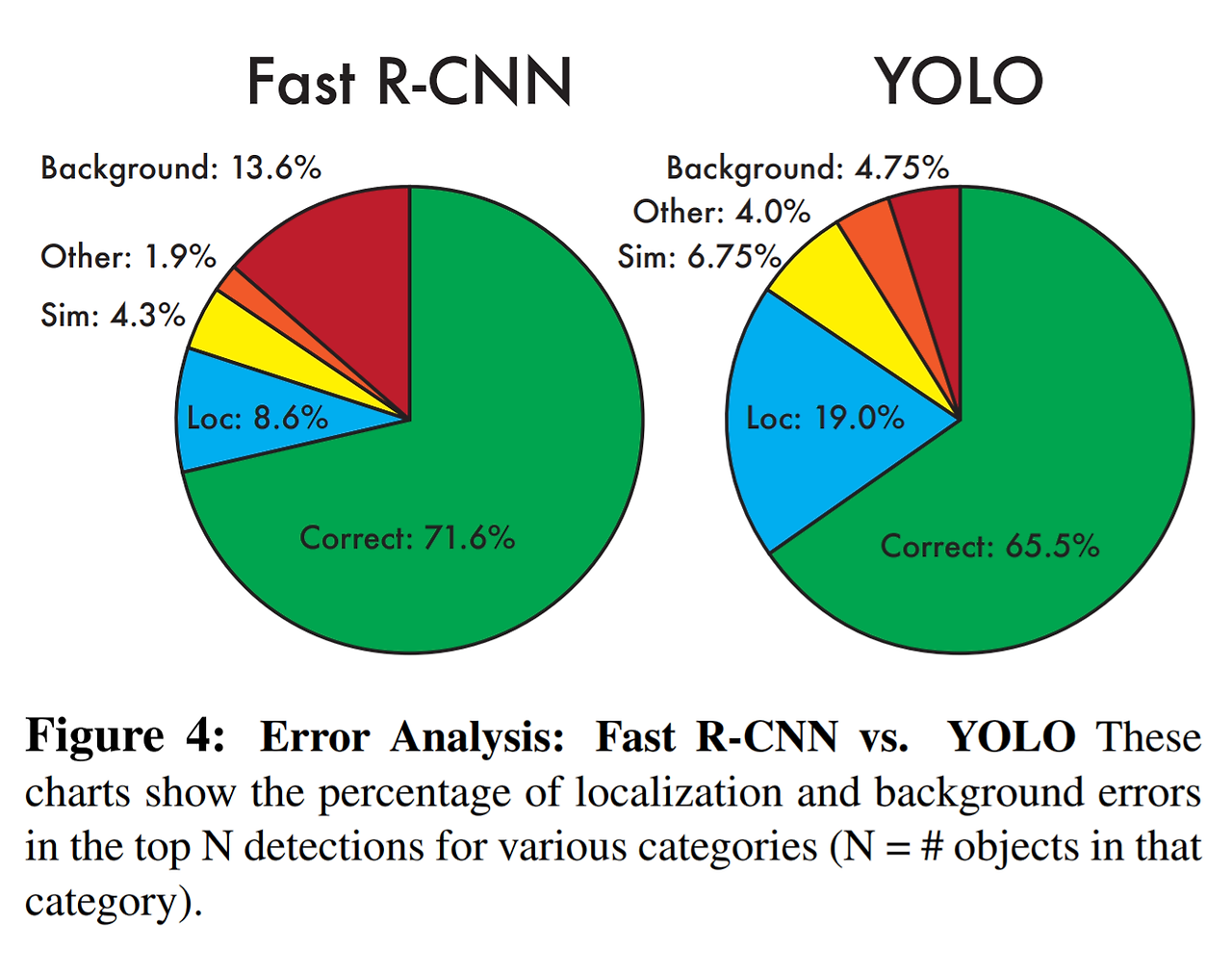
- YOLO는 background error가 다른 모델에 비해 적으나 Localization error가 많이 발생한다
- Fast R-CNN에서는 Background error가 많이 발생하나 Localization error가 상대적으로 적다.
4.3. Combining Fast R-CNN and YOLO
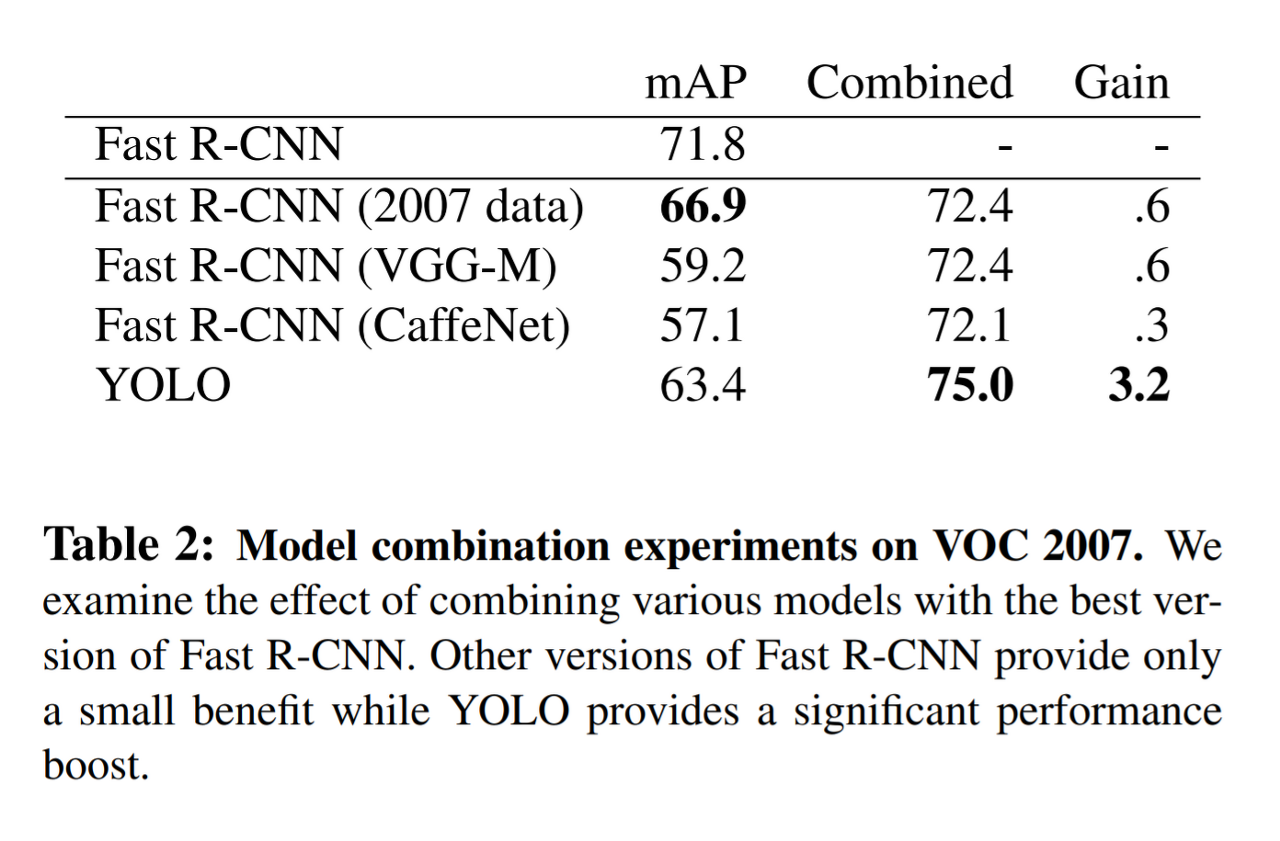
- 만약 두 모델을 결합한다면 굉장히 높은 성능을 낼 수 있을 듯
- Fast R-CNN과 YOLO를 독립적으로 돌려 결과를 앙상블 하는 방식으로! → YOLO에 비해 느림 🥕🥕🥕🥕 그래도 YOLO가 워낙 빨라서 Fast R-CNN을 단독 사용보다 앙상블 모델 사용하는 것이 낫다!
4.4. VOC 2012 Results
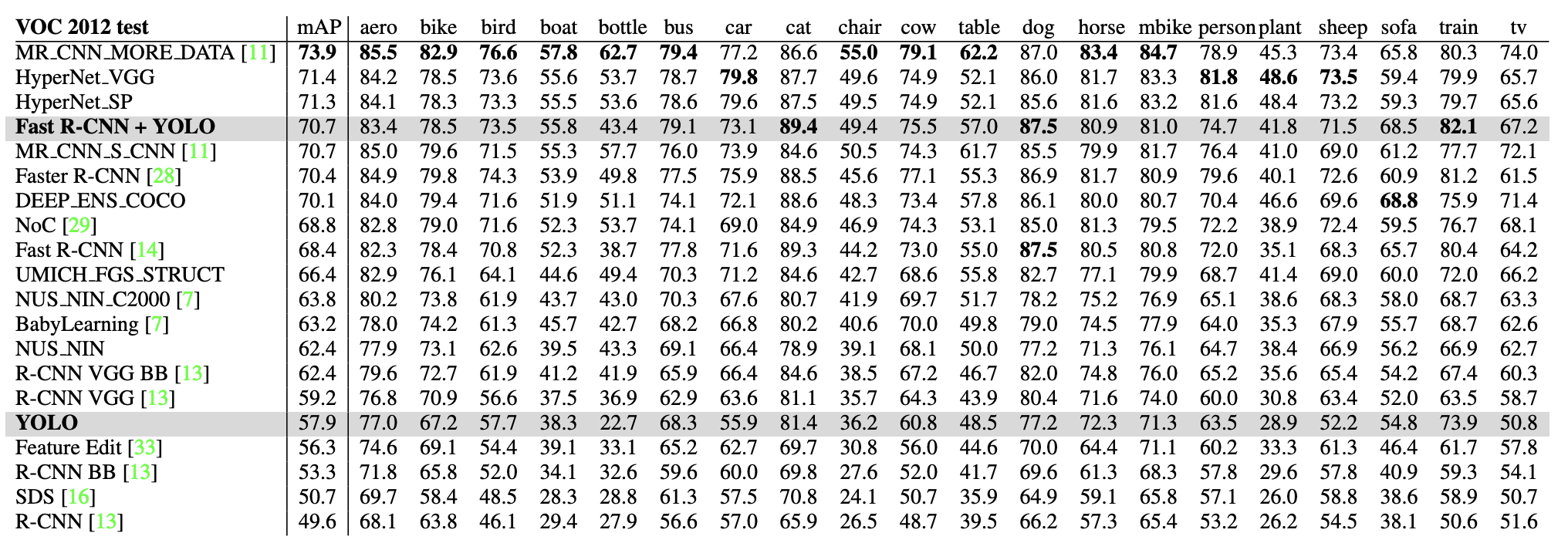
- YOLO는 57.9%의 mAP를 달성, 속도도 제일 빠
- 정확도는 Fast R-CNN과 YOLO를 결합한 모델이 가장 높
4.5. Generalizability: Person Detection in Artwork
- 연구를 위해 사용하는 데이터셋은 train과 test의 데이터 분포가 동일하다
- 실제 데이터셋은 이미지 분포가 다를 수 있다
⇒ 연구진들은 train과 다른 분포를 가진 test 데이터로 모델을 테스트해봄
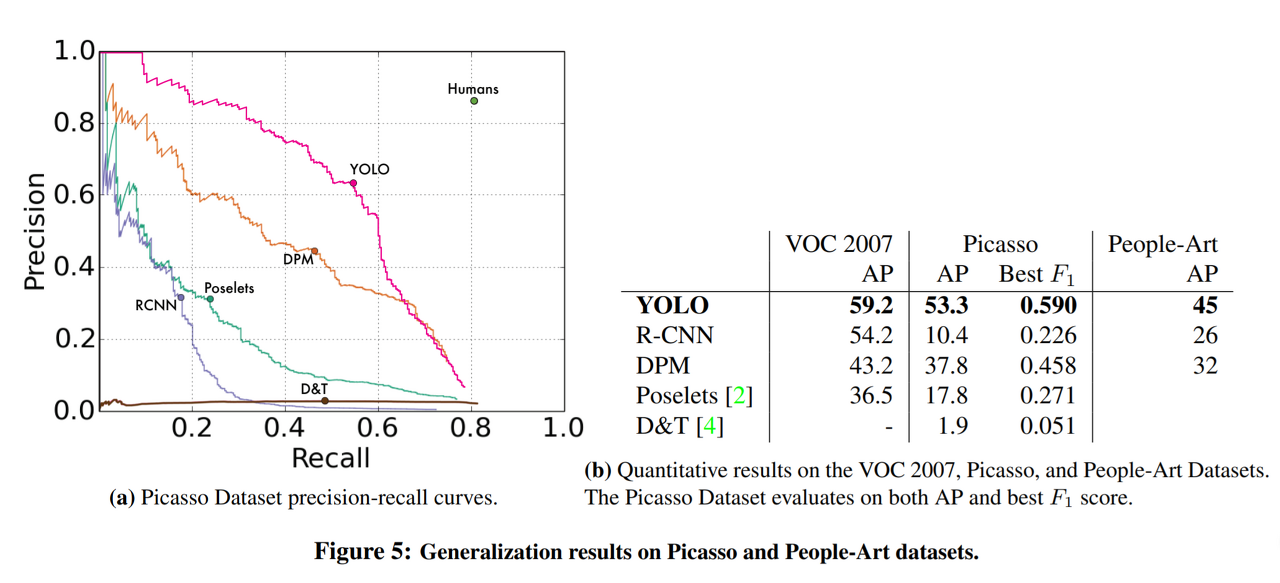
- YOLO는 훈련 단계에서 접하지 못한 새로운 이미지도 잘 검출한다.
5. Real-Time Detection In The Wild
- YOLO를 webcam과 연결해 실시간 Object detection을 가능하게 했다(자랑vV)
6. Conclusion
- YOLO는 단순하면서 빠르고 정확
- 훈련 단계에서 보지 못한 새로운 이미지에 대해서도 객체를 잘 검출
