SAM
SAM
- 0. Abstract
- SA 프로젝트의 데이터셋(SA-1B)은 10억개 이상의 mask, 1,100만 장 이상의 저작권을 준수한 이미지로 구성됨
- zero-shot setting에서도 준수한 성능 보임
- 1. Introduction
-
목표
- NLP에는 GPT같은 패러다임을 바꾸는 혁신적인 모델이 있는데 CV에는 그런 모델이 없다
- ⇒ image segmentation 분야에서의 foundation model을 제안하는 것목표 달성하기 생각할 것 3가지
1) task: 어떤 task가 zero-shot 일반화를 가능하게 할까?
2) model: 어떤 모델 아키텍쳐를 사용해야 할까?
→ flexible prompting과 실시간 segmentation mask 생성을 해줄 수 있는 model이 필요하다
3) data: 어떤 data가 해당 task와 model에 적합할까?
→ segmentation을 위한 web-scale data source가 없기 때문에 data engine을 만들어 데이터를 수집하고, 이를 활용하여 모델을 개선하는 과정 반복하자
-
Task
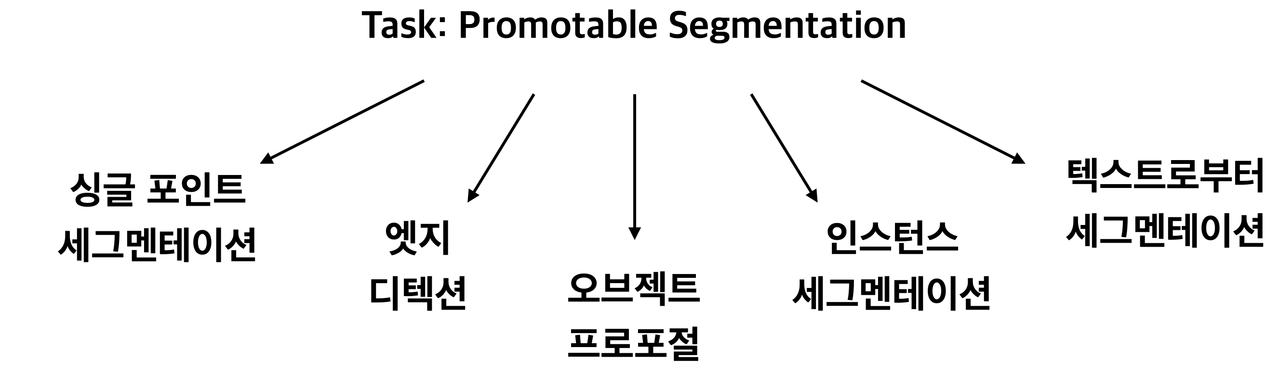
- LLM에서 사용하는 방식과 비슷하게 promptable segmentation task 제안
- 어떠한 segmentation prompt가 주어져도 유효한 segmentation 결과 출력하는 것이 목표
-
Model
- 3가지 만족하는 model 만들어야 함
- 1) flexible prompts 지원
- 2) 실시간으로 interactive하게 segmentation mask를 계산
- 3) prompt에 대해서 ambiguity aware
- SMA은 3가지 만족함
- 3가지 만족하는 model 만들어야 함
-
Data engine
그냥 assisted- manual,semi- automatic, fully-automatic 3가지 방식 있다는 것만 알아두자.
- 강한 일반화 위해서는 방대한 dataset 필요함
- data engine 구축: Model-in-loop dataset annotation을 사용하는 방법
- assisted- manual: 기존의 annotation task와 비슷하게 SAM이 annotator를 assist하는 방식
- semi- automatic: 프롬포트해서 선택된 objects들 중에서 일부만 SAM이 mask를 자동으로 생성하고 나머지는 annotator가 한다
- fully-automatic: annotation을 완전 자동으로~
-
Data set:
- fully automatic strategy로 생성된 최종 dataset: SA-1B
-
- 2. Segment Anything Task Task
-
promptable segmentation task는 주어진 어떠한 prompt라도 유효한 segmenation mask를 출력하는 것
-
프롬포트가 모호하거나 여러 물체 나타내도 결과는 여러 물체 중 하나를 출력하는 segmentation mask여야 한다
Pre-training
-
Promptable segmentation task는 각 학습 샘플에서 연속된 프롬프트(점, 박스, 마스크 등)를 simulation하고, 이를 ground truth와 비교하는 사전학습을 제안
-
prompt가 모호해도 valid한 mask를 예측하도록 하는것이 목적
Zero-shot transfer
-
사전학습 덕분에 추론 시 어떤 프롬프트에도 적절하게 응답 -<> zero-transfer에 용이
-
예: 고양이에 대한 bounding box detector가 있다면 그 output을 SAM의 프롬프트로 사용해서 양이에 대한 instance segmentation을 수행
-
- 3. Segment Anything Model
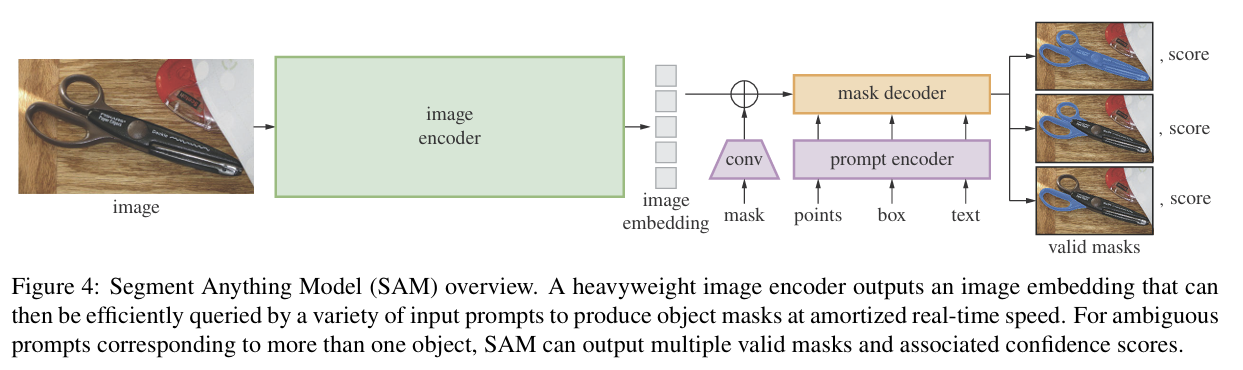
세 가지 구성 요소( Image encoder/ Flexible prompt encoder/Fast mask decoder )
**Image encoder**
- 사전학습된 vision transformer기반 MAE(Masked autoencoders) 사용
- MAE의 encoder는 **recognition을 위한 image representation을 추출**
- image encoder는 각 이미지 당 한 번만 실행
- 모델에 프롬프트를 제공하기 전에 적용
**Prompt encoder**
- Prompt를 2개로 나눔
- sparse(point,box,text)
- point,box: positional encoding사용
- text: free-form 표현하기 위해 CLIP의 text encoder 사용
- dense (mask)
- convolution 사용해서 임베딩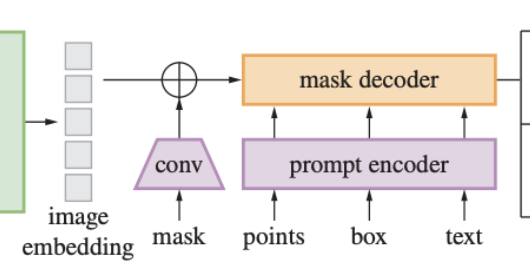
**Mask decoder**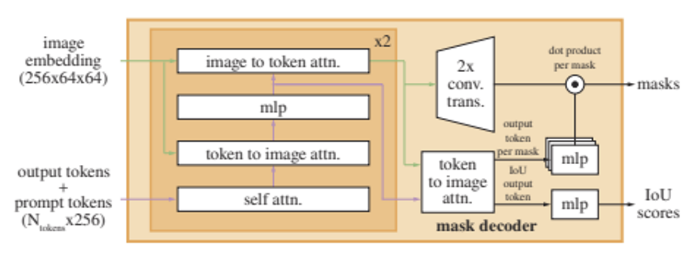
- Mask decoder는 Image embedding, prompt embedding, output token을 받아서 mask 형태로 반환
- 구조는 Transformer Decoder를 변형한 형태
- modified decoder block은 모든 embeddings을 업데이트하기 위해 prompt self-attention과 cross-attention을 양방향으로 사용한다
- 이후에 이미지 임베딩을 upsample하고, MLP가 output token을 dynamic linear classifier에 매핑한다
- . 이후 각 이미지 위치에서 mask foreground probability를 계산한다
**Resolving ambiguity**
- 애매한 프롬프트가 주어진다면 다양한 valid mask들이 생성될 수 있음
- SAM은 하나의 prompt에 대해 여러 output mask를 예측하도록 변형함
- 3개의 mask output이면 충분함
- 학습 중에는 예측된 마스크와 ground truth 사이의 loss를 계산하는데, backpropagation은 **가장 loss가 적었던 마스크**에 대해서만 진행
- 3개의 mask에 대해 rank 매기기 위해 confidence score 예측하도록함- 4. Segment Anything Data Engine
- 인터넷에 segmentation masks가 충분하지 않기 때문에, 저자들은 data engine을 만들어 11억개의 마스크 데이터 셋인 SA-1B를 구축
- 인터넷에 segmentation masks가 충분하지 않기 때문에, 저자들은 data engine을 만들어 11억개의 마스크 데이터 셋인 SA-1B를 구축

**Assisted-manual stage**
- 전문 Annotator들이 SAM으로 지원되는 웹 기반의 interactive segmentation tool에서 전경/배경 객체 지점을 클릭해서 마스크를 레이블링 함
- SAM은 공개된 segmentation datasets를 통해 학습했고, data 충분히 수집되면 이를 이용해서 재학습 ( 재학습은 총 6번함)
**Semi-automatic stage**
- 모델이 segmet anything할 수 있도록 mask를 다양하게 만들어 내는 것에 초점 둠
- annotator들이 덜 중요한 물체에도 집중할 수 있도록, 먼저 confident masks들을 감지
- annotator들에게 주석이 달리지 않은 물체들 추가적으로 주석을 달도록 함
**Fully automatic stage**
- annotation이 모두 자동적으로 이루어진다.
- 충분한 데이터를 만들어 모델을 학습시키고 모호성 인식 모델을 개발
- 모델에 32x32 regular grid 점을 프롬프팅했고, 각 점 별로 valid objects에 일치하는 마스크를 예측
- IoU prediction module을 사용하여 confident mask를 선택
- NMS를 이용해 중복된 마스크를 제거- 5. Segment Anything Dataset
-
데이터 셋 SA-1B는 1,100만 개의 다양한 고해상도와 11억 개의 고품질 segmentation mask로 구성됨
Images
-
이미지는 평균 3300x4950 픽셀로 고해상도
-
1500 픽셀로 downsampling함
-
그래도 이미 존재하는 다양한 vision datasets보다 고해상도
Masks
-
11억개 MASK 만들었는데 그중에서 99.1%가 자동 생성된 것
Mask quality
-
무작위로 샘플을 뽑아 이를 전문 annotator가 작업한 것과 비교했는데, 94% 이상이 90%보다 큰 IoU 값을 가졌다.
-
기존은 기존 모델들은 85-91% 정도
Mask properties
-
SA-1B에서는 다른 대규모 데이터 셋에 비해 center bias가 훨씬 적다.
-
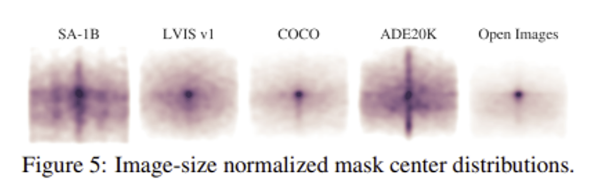
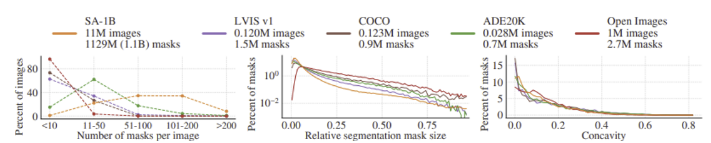
- SA-1B는 이미지 당 마스크의 개수가 많으며, 비교적 작은 크기의 마스크를 더 많이 포함하고 있다
- 마스크의 오목함 분포는 다른 데이터셋과 유사- 6. Segment Anything RAI Analysis Geographic and income representation
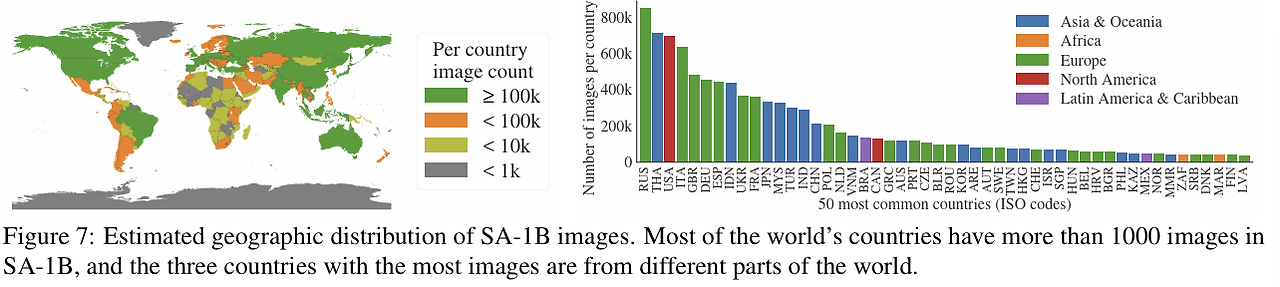

- 지리적, 경제적으로 평등한 데이터셋 사용했다.
**Fairness in segmeting people**
- 성별, 나이, 인종 차별이 없다- 7. Zero-Shot Transfer Experiments
**1. Zero-Shot Single Point Valid Mask Evaluation**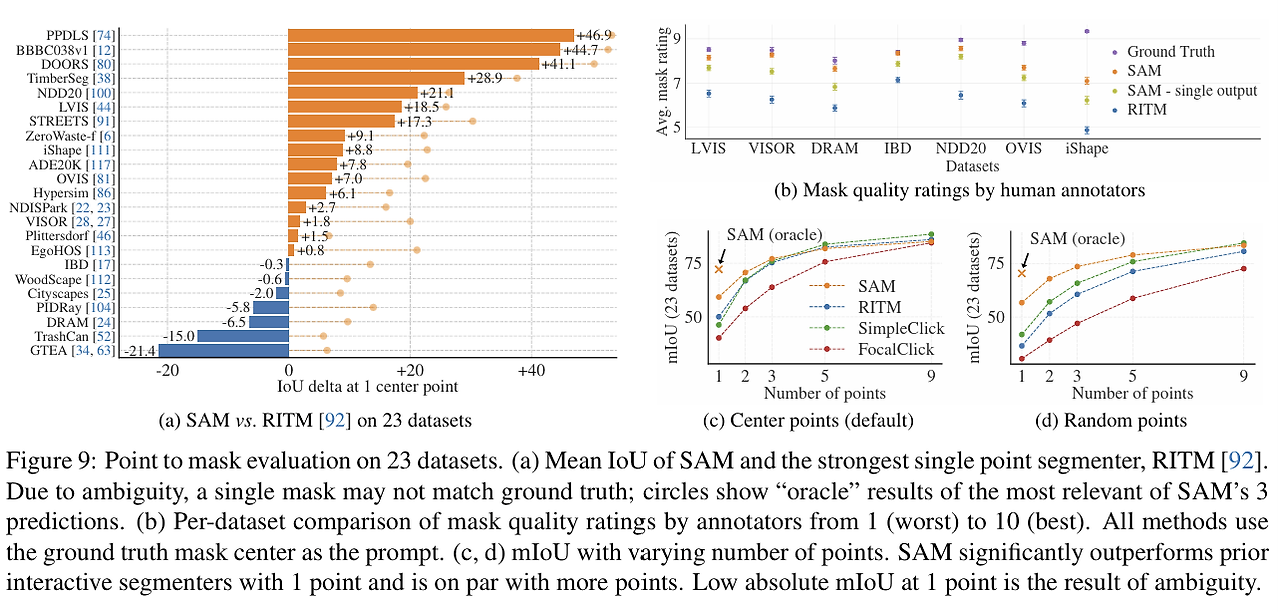
- SAM 모델이 학습한 적 없는 기존 23개의 segmentation 데이터 셋들에 대해서
점 찍었을 때 마스크를 얼마나 잘 생성하는지를 기존 SOTA 모델인 RITM과 비교했따
- 주황색과 파란색 막대로 표시된 부분은 각각 SAM과 RITM이 더 뛰어난 성능을 보여준 지표
- SAM이 23개 중에서 16개에서 우수한 결과 냈따
**2 . Zero-Shot Edge Detection**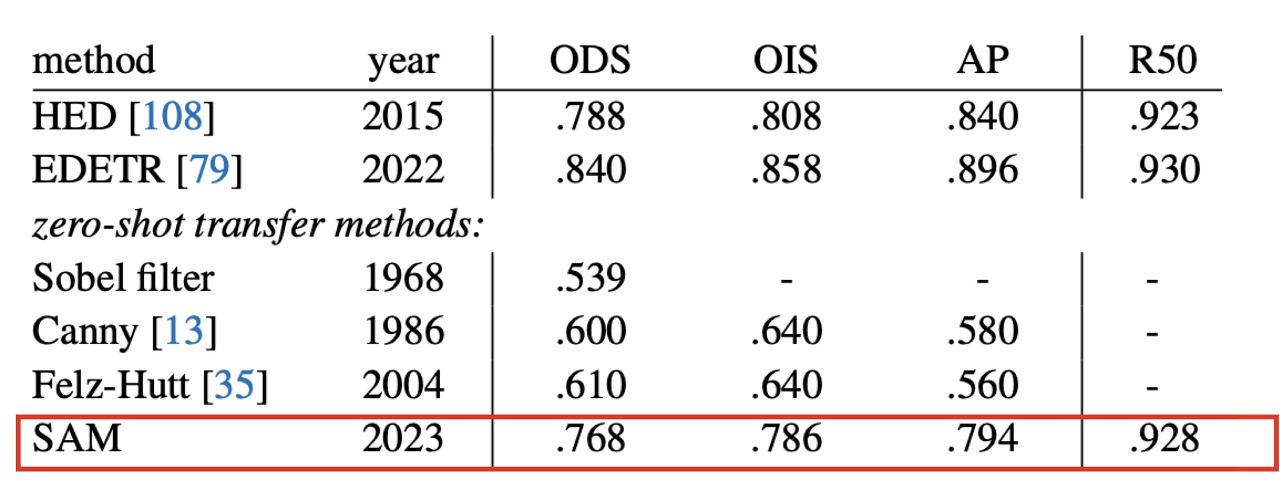
- 이미지가 주어졌을 때, 테두리를 추출하는 테스크로 기존 edge detection 데이터 셋에 대해서 SOTA 모델들과 비교
- SOTA 모델을 뛰어넘지는 못했지만, 비빌만한 성능올 보여줬다

- SAM이 edge detection에 대한 학습이 이뤄지지 않았음에도, Ground truth와 비교하여 훨씬 정교한 결과를 보여줬다.
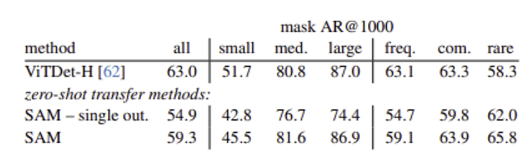
**3. Zero-Shot Object Proposals**
- 물체가 있을만한 후보 영역을 찾는 테스크
- 다양한 category 수를 가지는 LVIS 데이터셋에 대한 Object proposal task 결과를 실험하였다. (비교 모델은 ViTDet detector )
- 중간이거나 큰 objects에 대해서는 SAM이 좋은 결과를 보였고, 작거나 빈번한 objects에 대해서는 나쁜 결과를 보였다
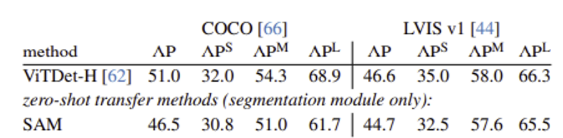
**4. Zero-Shot Instance Segmentation**
- Object Detection 결과로 출력된 물체에 대해서 Segmentation을 하는 테스크
- ViTDet보다는 성능이 낮았지만, 크게 뒤지지 않는다
**5. Zero-Shot Text-to-Mask**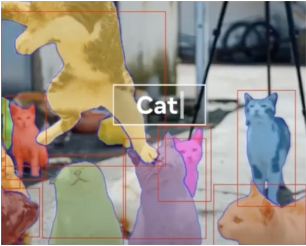

- free-form text로부터 object를 segmenting하는 실험을 진행
- Prompt 정확하게 쓰면 mask 더 잘 만든다- 8. Discussion Limitation
- 일반적으로는 잘 작동하지만 완벽하지 않다.
- 미세한 구조를 놓치기도 한다
- 연결되지 않은 작은 요소를 상상해서 만 든다
- 더 많은 연산을 요구하는 방법들 보다는 경계선을 명확하게 생성하지 못한다
