Abstract
video object segmentation(VOS)
- Prior work : 한 가지 유형의 특징 메모리 사용 → 1분 이상의 긴 비디오에서는 단일 특징 메모리 모델이 메모리 소비와 정확도 사이의 연관성이 강함
- XMem : Atkinson-Shiffrin memory model 사용(앳킨슨-시프린 메모리 모델 - 위키백과, 우리 모두의 백과사전 (wikipedia.org)) ⇒ 여러 개의 독립적, 깊이 연결된 특징 메모리 저장소를 통합하는 아키텍처 개발(빠르게 업데이트되는 sensory memory, 고해상도의 working-memory, 압축되어 지속 가능한 long-term memory)
- 메모리 강화 알고리즘(memory potentiation algorithm) 개발 → 자주 사용되는 작업 메모리 요소를 장기 메모리로 정기적으로 통합 ⇒ 메모리 폭발 방지, 장기 예측에서 성능 저하 최소화
- 메모리 강화 알고리즘(memory potentiation algorithm) 개발 → 자주 사용되는 작업 메모리 요소를 장기 메모리로 정기적으로 통합 ⇒ 메모리 폭발 방지, 장기 예측에서 성능 저하 최소화
- 긴 비디오에서 성능 좋음
- 짧은 비디오에서도 좋음
1 Introduction
- Video object segmentation (VOS) : 주어진 비디오에서 특정 목표 객체를 강조하여 분할하는 작업
- 사용자가 첫 번째 프레임에서 annotation하면 그 정보를 바탕으로 다른 프레임에서 객체를 분할하는 semi-supervised 반지도 학습
- 주어진 주석 정보를 다른 프레임에 전달 → 대부분의 VOS는 특징 메모리 사용하여 관련 deep-net 표현을 저장 → 느려짐
- SOTA VOS : attention 메커니즘 사용 : 특징 메모리에 저장된 과거 프레임의 표현을, 새롭게 관찰된 쿼리 프레임에서 추출된 특징과 연결 → 과거 프레임 표현 저장 위해 많은 GPU 메모리 필요
- XMem : Atkinson-Shiffrin 메모리 모델에서 영감 받아, 다양한 시간적 규모의 메모리 저장소 도입
-
빠르게 업데이트되는 sensory memory
- 매 프레임마다 업데이트되는 GRU(게이트 순환 유닛)의 숨겨진 표현 → 시간적 부드러움 제공, 장기 예측 실패(표현 drift 때문)
-
고해상도의 working-memory
- historical frame의 하위 집합에서 집계, 시간에 따라 drift하지 않다.
-
압축되어 지속 가능한 long-term memory
- 작업 메모리의 크기를 제어하기 위해, XMem은 표현을 장기 메모리에 통합함.
- 장기 메모리를 압축된 프로토타입 세트로 저장한다. → 메모리 강화 알고리즘 개발(프로토타입에 풍부한 정보를 집약하여 하위 샘플링으로 인한 aliasing(노이즈)을 방지)
- working and long-term memory에서 읽기 작업을 위해 → space-time memory reading operation 고안⇒ 세 가지 특징 메모리 저장소 결합 ⇒ 긴 비디오 높은 정확도, GPU 사용량 낮게 유지
-
2 Related Works
- General VOS Methods
- Online learning approach
- 테스트에서 네트워크 훈련하거나 fine-tuning → 예측에서 느림
- 온라인 적응 필요
- Tracking-based approach
- 프레임 간 정보를 전달 → 테스트에서 효율
- 장기적인 context 부족, occlusion 이후 추적 자주 잃음(re-id) ⇒ 문맥 제한 문제 해결 위해 최근에는 더 많은 과거 프레임을 특징 메모리로 사용
- Space-Time Memory(STM) 인기 많음. 변형 많음. STCN도 변형.
- STM의 계속 확장되는 특징 메모리 뱅크로 인해 대부분의 변형은 긴 비디오 처리가 안 됨.
- AOT : GPU 메모리 폭발 문제 해결 못함.
- 우리는 STCN을 working memory backbone으로 사용
- XMem : 다양한 시간적 문맥 포착 위해 여러 메모리 저장소 사용하면서 GPU 메모리 사용량을 엄격하게 제한
- Online learning approach
- Methods that Specialize in Handling Long Videos
- AFB-URR (Liang dt al.)
- 주어진 메모리 요소가 기존 요소와 가까우면 지수 이동 평균 사용하여 병합, 아니면 새로운 요소로 추가
- 특징 메모리가 정의된 한도에 도달 → least-frequently-used-based 메커니즘으로 사용되지 않은 특징 제거
- global context module (Li et al.)
- 모든 과거 메모리를 단일 표현으로 평균화 → 시간이 지나도 GPU 메모리 증가 없음
- AFB-URR (Liang dt al.)
⇒ AFB-URR, global context module : 새로운 고해상도 특징 메모리를 압축 표현하는 것 → segmentation accuracy 희생함
- XMem : multi-store 특징 메모리는 적극적인 압축 피하고, 단기-장기 예측에서 높은 정확도 달성함
3 XMem
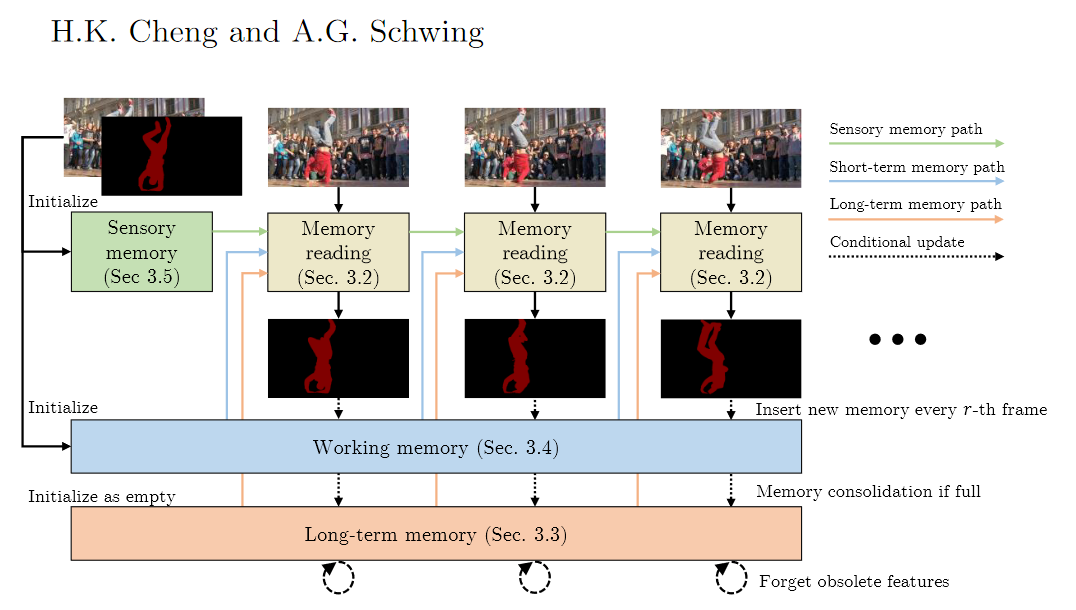
- Memory reading operation
- 3개의 메모리 저장소에서 관련된 특징 추출하고 특징 사용해서 mask 생성
- Sensory memory
- 새로운 메모리 통합을 위해, 감각 메모리는 매 프레임마다 업데이트
- Working memory
- 새로운 메모리 통합을 위해, 작업 메모리는 매 r번째 프레임미다 업데이트
- 작업 메모리는 가득 차면 압축된 형태로 장기 메모리에 통합
- Long-term memory
- 장기 메모리는 시간이 지나면 obsolete(더 이상 쓸모가 없는) 특징을 잊음
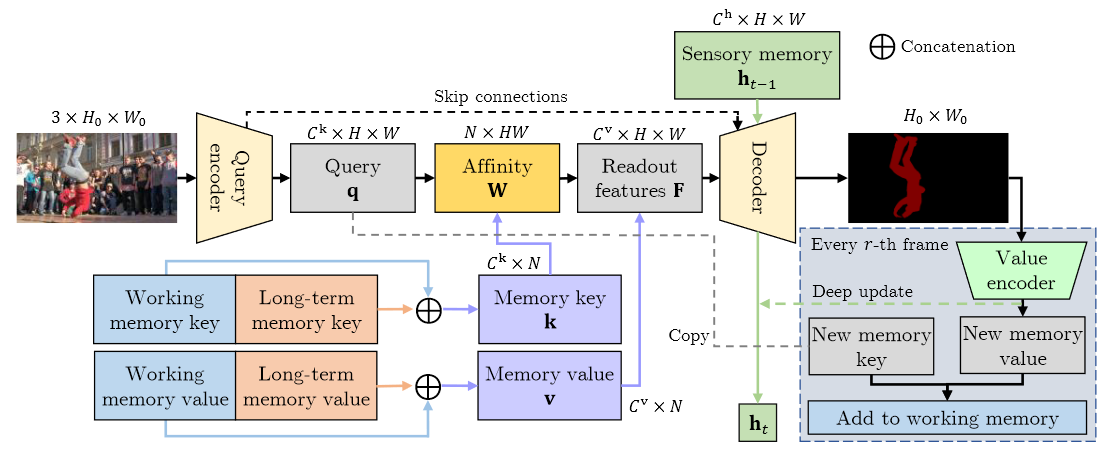
-
single query frame의 메모리 읽기와 마스크 디코딩 프로세스
-
이미지에서 쿼리 q를 추출, 작업/장기 메모리에서 어텐션 기반 메모리 읽기를 수행하여 특징 F 얻음
-
감각 메모리와 함께 디코더에 공급되어 마스크 생성
-
매 r번째 프레임에서 새로운 특징을 작업 메모리에 저장하고, 감각 메모리에 대한 deep 업데이트 수행
-
3.1 Overview
- 첫 번째 프레임 (이미지와 타겟 객체 마스크 주어짐) : XMem은 객체 추적하고 후속 쿼리 프레임에 대해 해당하는 마스크를 생성
- 입력을 사용하여 다양한 특징 메모리 저장소를 초기화
- 각 후속 쿼리 프레임에 대해, 메모리 읽기 수행(각각 장기 메모리, 작업 메모리, 감각 메모리) → 읽어온 특징은 분할 마스크를 생성하는데 사용
- 각 프레임에서 감각 메모리 업데이트, 매 r번째 프레임마다 작업 메모리에 특징 삽입
- 작업 메모리가 사전에 정의된 프레임의 최대치()에 도달하면, 작업 메모리에서 장기 메모리로 특징을 압축된 형태로 통합
- 장기 메모리가 가득 차면(수천 프레임 처리 후에 발생), 오래된 특징을 삭제하여 GPU 메모리 사용량 제한
- XMem : 쿼리 인코더, 디코더, 값 인코더 같이 end-to-end 훈련 가능한 컨볼루션 네트워크로 구성된다.
- 쿼리 인코더 : query-specific 이미지 특징 추출
- 디코더 : 메모리 읽기 단계의 출력을 사용하여 객체 마스크 생성
- 값 인코더 : 이미지와 객체 마스크 결합하여 새로운 메모리 특징을 추출
-
3.2 Memory Reading
- single frame에 대한 메모리 읽기와 마스크 생성 과정
- 마스크는 디코더를 통해 계산
- 단기 감각 메모리 h와 작업/장기 메모리에 저장된 정보를 나타내는 특징 F를 입력으로 사용
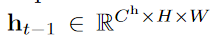
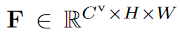
- 특징 F는 읽기 작업을 통해 계산됨
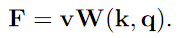
- k, v : 장기/작업 메모리에 저장된 총 N 개의 메모리 요소에 대한 $C^{\text{k}}$, $C^{\text{v}}$차원의 키와 값
- $\text{W(k, q)}$ : N*HW 크기의 affinity matrix. 키 k와 쿼리 q에 의해 제어되는 읽기 작업을 나타냄.
- 읽기 작업은 각 쿼리 요소를 모든 N개의 메모리 요소에 대한 분포로 매핑하고 해당 값을 집계.
- Affinity matrix는 유사도 행렬 S(k, q)의 행에 소프트맥스를 적용해서 얻음
- STCN에서 제안된 L2 유사도는 dot product보다 안정적이지만 표현력이 낮아 메모리 요소의 신뢰 수준을 인코딩할 수 없다.(memory element의 중요도 설정할 수 없다)
⇒ 해결 : 두 가지 새로운 스케일링 항을 도입; 키와 쿼리 간의 대칭을 깨는 새로운 유사도 함수(anisotropic L2, 이방성, 비등방성) 제안 : 안정적, 표현력 좋음
- 키는 shrinkage term s와 연결, 쿼리는 selection term e와 연결 ⇒ i 번째 키 요소와 j 번째 쿼리 요소 간의 유사도
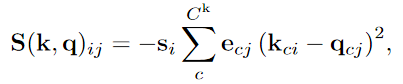
$s_i = e_{cj} = 1, \forall i, j, c$에서 L2유사도와 같다.
- e : 쿼리 인코더에 의해 쿼리 q와 함께 생성
- s : 키 k와 값 v와 함께 작업/장기 메모리에서 수집- 3.3 Long-Term Memory
- Motivation
- 장기 메모리는 긴 비디오 처리에 필수적
- 작업 메모리에서 프로토타입을 선택하고 이것을 메모리 강화 알고리즘으로 강화하는 메모리 통합 절차를 설계
- 작업 메모리가 사전 정의된 크기()에 도달하면 메모리 통합을 수행
- 첫 번째 프레임(사용자의 제공 실제 값)과 가장 최근 은 프레임은 고해상도 버퍼로 작업 메모리에 유지
- 나머지 메모리 프레임은 장기 메모리 표현으로 변환될 후보
- 후보 기와 값 : ,
- Prototype Selection
- 후보에서 소수의 대표적인 하위 집합 를 프로토타입으로 선택
- 프로토타입 수는 장기 메모리의 크기와 직접적으로 비례 → 소수의 프로토타입 선택하는 것이 중요
- 사용 빈도가 높은 후보를 P개를 프로토타입으로 선택 (인간의 기억을 본떠서, 자주 접근하거나 학습된 패턴을 장기 저장소로 이동시킴)
- 메모리의 “사용량Usage”은 affinity matrix W의 누적 총 affinity친화도(확률 질량)에 의해 정의, 각 후보가 작업 메모리에 있는 기간으로 정규화됨.
- 각 후보의 기간은 최소 r(T_min - 1)
- Memory Potentiation
- 후보 키()에서 프로토타입 키() 선택하는 방식은 현재는 희소하고 이산적 → 동일한 방식은 aliasing 발생
- Aliasing 방지 : 필터링을 수행, 각 샘플링된 프로토타입에 더 많은 정보를 집계 → 2D 이미지 평면이나 3D 공간에서의 표준 필터링은 객체 경계에서 블러링을 유발할 수 있다. → 고차원 키 공간 ()에서 필터링 수행 : 키 와 가 제공하는 인접 정보 활용 (이 키들은 어차피 메모리 읽기에서 계산되고 저장되므로 런타임과 메모리 소비 측면에서 경제적)
- 각 프로토타입에 대해, 모든 후보 값 ()에서 가중 평균으로 값 집계 (가중치는 키 유사성에 대한 소프트맥스 사용하여 계산)
- Motivation
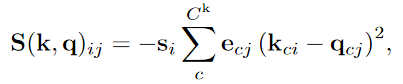
위 식을 재사용한다. k → $k^c$, q → $k^p$
소프트맥스 사용하여 친화도 행렬 W 얻고, 프로토타입 값 $v^P$로 계산, 마지막으로 $k^p, v^p$를 장기 메모리에 추가
- Removing Obsolete Features
- 메모리 압축, 오래된 기능 제거, 작업 메모리- 3.4 Working Memory
- 작업 메모리는 고해상도 특징을 임시로 저장하는 버퍼
- 몇 초 동안의 시간적 맥락에서 정확한 매칭을 가능하게 함
- 장기 메모리로 들어가는 게이트 역할을 함. 각 메모리 요소의 중요도는 작업 메모리에서의 사용 빈도로 추정
- STCN 스타일의 특징 메모리 뱅크를 작업 메모리로 사용
- 작업 메모리는 로 구성
- 키는 이미지에서 인코딩, 쿼리와 같은 임베딩 공간
- 값은 이미지와 마스크에서 인코딩
- 매 r번째 프레임마다, 쿼리를 새로운 키로 복사하고, 이미지를 예측된 마스크와 함께 값 인코더에 넣어 새로운 값을 생성 → 새로운 키와 값은 작업 메모리에 추가되어 이후 프레임의 메모리 읽기에 사용
- 메모리 폭발 방지를 위해 작업 메모리의 프레임 수를 제한하고 초과된 프레임은 장기 메모리로 통합한다.
- 3.5 Sensory Memory
- 단기 정보를 저장. 객체 위치와 같은 저수준 정보를 유지
- 작업/장기 메모리에서 시간적 지역성이 부족한 부분(the lack of temporal locality)을 보완
- 은닉 표현 저장 : 영벡터로 초기화, GRU를 통해 프레임마다 갱신
- 매 r번째 프레임마다, 새로운 작업 메모리 프레임이 생성될 때 deep update 수행
- 값 인코더의 특징으로 또다른 GRU로 감각 메모리 갱신
- 3.6 Implementation Details
- ResNet을 특징 추출기로 사용
4 Experiments
T_min=5, T_max=10, P=128 (top-P : prototype selection)
- 4.4 Limitations 대상 물체가 너무 빨리 움직이거나, 모션 블러가 심할 때 실패할 때가 있다. 가장 빨리 업데이트되는 감각 기억도 따라잡지 못한다.
5 Conclusion
- 비디오 객체 분할에 사용하는 다중 저장소 특징 메모리 모델

ML Engineer 🧠 | AI 모델 개발과 최적화 경험을 기록하며 성장하는 개발자 🚀 The light that burns twice as bright burns half as long ✨