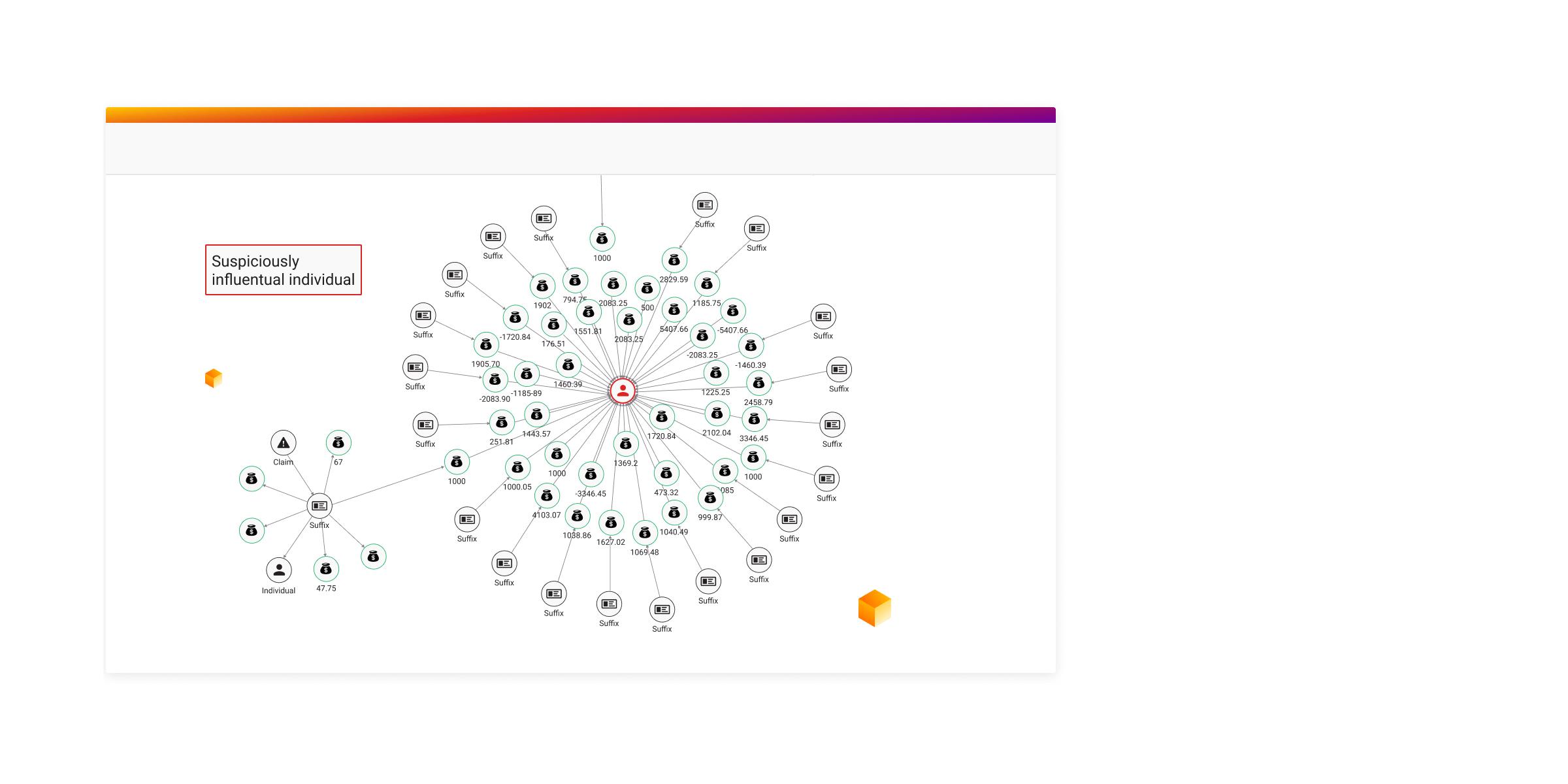
이 챕터의 thesis는 다음과 같다. 이상 탐지는 본질적으로 "흩어진 식별자들이 같은 인물·집단을 가리키는지"를 판별하는 entity linking 문제이며, 그래프는 이를 관계의 직접적인 표현으로 환원해 단순한 SQL 질의로는 도달할 수 없는 패턴을 드러낸다. Super Node로 의심 구간을 잡고, Weakly Connected Components로 커뮤니티를 분리하고, Eigenvector Centrality로 그 안의 핵심 인물을 지목하는 3단계 흐름이 챕터의 골격이다.
1. 이상 탐지 문제의 본질
사기는 개인적 이익을 위한 사실의 허위 표시로 정의된다. 디지털 거래는 매일 수십억 건의 데이터 포인트로 구성되며, 사기 양상을 분석하려면 최첨단 기술이 필요하다. 신원 도용 같은 사기 수법은 금융 서비스 회사에 막대한 경제적 손실과 평판 리스크를 동시에 안긴다. AI의 등장과 함께 사기 수법은 점점 더 복잡해지고 있으며, 분석 측면에서도 단순한 통계 규칙이나 임계값 기반 탐지로는 한계가 명확해졌다. 상호 연결된 관계를 분석하기 위한 knowledge graph 같은 고급 분석 기법으로의 전환이 요구되는 배경이다.
사기는 가해자 구성에 따라 세 유형으로 나뉜다.
| 유형 | 정의 | 탐지 난이도 |
|---|---|---|
| First-Party Fraud | 본인이 자신의 정체나 정보를 허위로 표시 | 단일 계정 분석으로 탐지 가능 |
| Second-Party Fraud | 본인이 동의 하에 정보를 타인에게 제공하고 공모 | 관계 분석 필수 |
| Third-Party Fraud | 외부인이 본인 몰래 신원·정보를 도용 (가장 흔함) | 광범위한 네트워크 분석 필요 |
Second·Third-Party Fraud는 단일 계정 단위로는 보이지 않는다. 공모자 또는 도용자가 다른 계정·다른 식별자를 거쳐 활동하기 때문이다. 관계의 그물망을 펼쳐야만 패턴이 드러난다는 사실이 그래프 기반 탐지의 출발점이다.
2. 고객을 잇는 식별자들
KG는 방대한 데이터셋의 복잡한 관계를 매핑해, 위험을 알고리즘적·시각적으로 정확히 지목할 수 있게 한다. 매핑의 출발점은 "어떤 속성으로 사람과 사람을 잇는가"다. 챕터가 제시하는 대표 식별자는 다음과 같다.
| 식별자 | 공유 시 의미 |
|---|---|
| SSN | 신원 도용 의심 — 같은 SSN을 여러 client가 사용 |
| IP 주소 | 잠재적 사기범 간 연결 — 동일 IP에서 다수 client 접속 |
| 은행 계좌 | 의심 거래의 red flag — 다른 client 간 계좌 공유 |
| 물리적 주소·PO Box | 잠재적 의심 — 다수 client가 같은 주소 사용 |
| 이메일 | 식별자로 활용, 단 fake 이메일 주의 |
각 식별자는 단독으로는 결정적 증거가 아니지만, 여러 식별자가 동시에 일치하면 정보량이 누적된다. 이 누적을 자연스럽게 표현하는 것이 그래프 모델이다. Client 노드와 식별자 노드를 별도로 두고, 각 client가 어떤 식별자에 연결되었는지를 엣지로 기록하면, 동일 식별자를 공유하는 client들은 그 식별자 노드를 경유해 자동으로 연결된다.
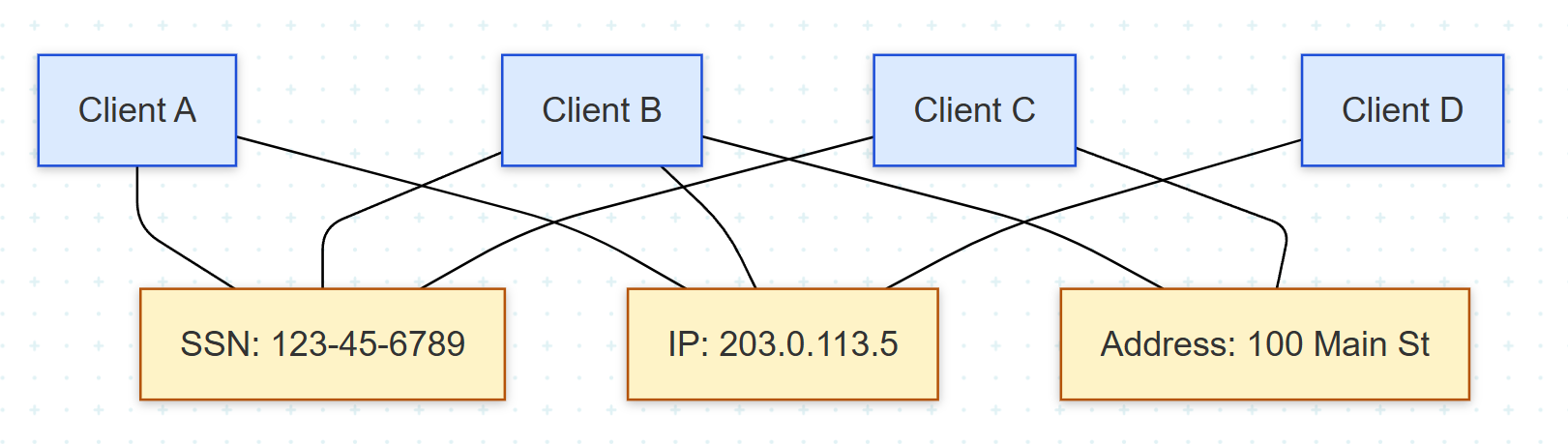
이렇게 표현하면 "두 client가 식별자를 매개로 간접적으로 연결되어 있는가"가 그래프 traversal 한 단계의 문제로 환원된다. 관계형 DB에서 동일한 분석을 하려면 여러 테이블에 걸친 self-join이 누적되고, client 수가 늘어남에 따라 비용이 기하급수적으로 증가한다.
3. Super Node: 분석의 첫 신호
Client 간 연결 그래프를 만들고 나면, 가장 먼저 마주치는 현상은 일부 노드가 비정상적으로 많은 연결을 갖는다는 점이다. 이것이 super node다. 연결 수가 많은 노드를 super node라고 부르며, 사기 분석의 출발점은 이런 노드를 flag하는 일이다.
Super node는 두 가지를 의미할 수 있다. 첫째, 실제로 다수의 client와 식별자를 공유하는 사기 허브일 수 있다. 둘째, 데이터 품질 문제로 발생한 가짜 연결의 산물일 수 있다. 예컨대 이메일이 가짜이거나 자동 생성된 경우("NONE@NA.com" 같은 placeholder), 이 이메일은 수많은 client와 연결된다. 이런 가짜 이메일은 분석에서 제외하거나, 원본 데이터의 품질 이슈를 해결하는 데 활용된다.
따라서 super node 처리는 두 갈래로 나뉜다.
| 처리 방향 | 목적 | 결과 |
|---|---|---|
| Filter Criteria | 데이터 품질 오류로 인한 false connection 제거 | 분석에서 제외 |
| Stand-Alone Analytics | super node가 존재하는 근본 원인을 별도 프로젝트로 조사 | 새로운 사기 패턴 발견 가능성 |
Client 간 연결이 community detection에 유효하지 않다 하더라도, 많은 수의 연결 자체가 사기 증거가 될 수 있다는 관점이 챕터의 핵심이다. 즉 super node는 community에서 분리해 분석하더라도, 그 자체로 별도의 사기 신호로 다뤄야 한다.
4. SHARED_IDENTIFIERS 관계와 가중치
Client–식별자–client의 2-hop 구조를 1-hop으로 압축한 것이 SHARED_IDENTIFIERS 관계다. "Client A와 Client B가 SSN 1개, IP 1개를 공유한다"는 사실을 두 client 사이의 가중치 엣지로 표현한다.
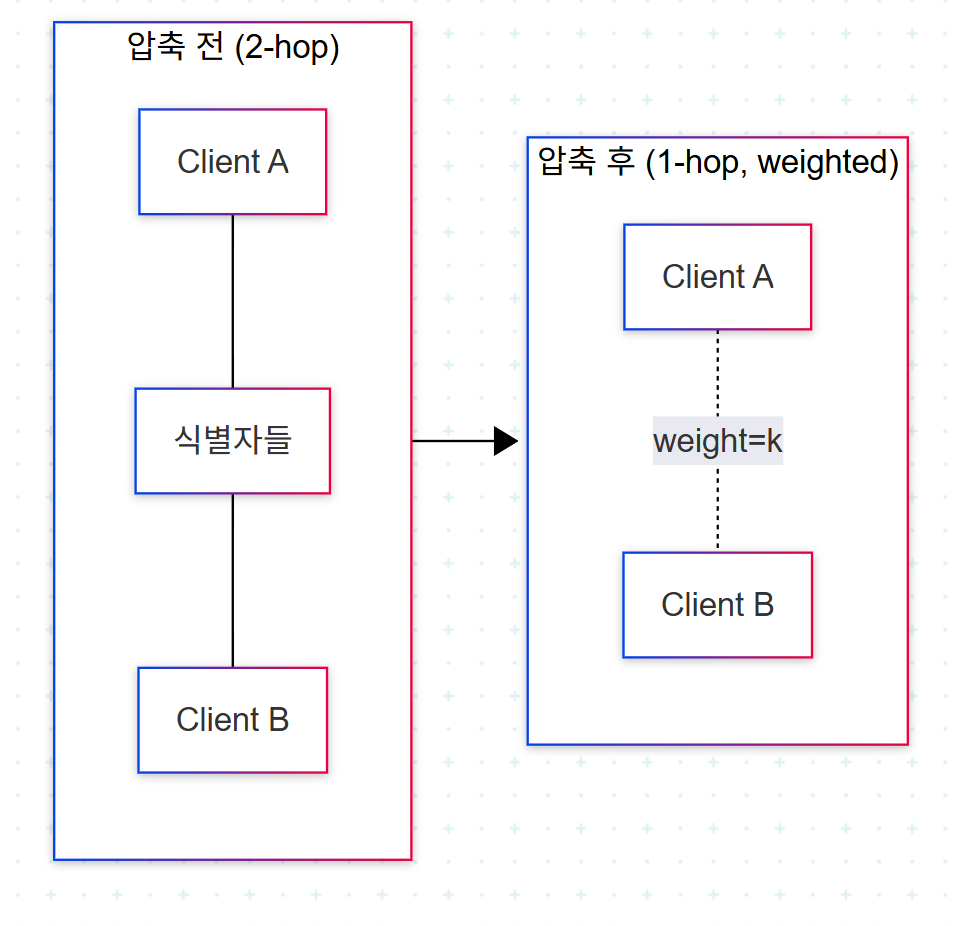
가중치 결정에는 비즈니스 규칙이 들어간다. 단순 공유 식별자 개수를 합산할 수도 있고, 식별자 종류에 따라 가중치를 차등 부여할 수도 있다(SSN 공유가 IP 공유보다 무거움). 두 client 간 연결의 강도를 결정하는 가중치는 그래프 알고리즘이 가중치를 활용한 계산을 수행할 때 유용해진다.
5. Graph Projection: 인메모리 분석을 위한 재구성
Neo4j Graph Data Science(GDS) 라이브러리는 알고리즘 실행 전에 graph projection을 만든다. 코드 스니펫이 생성하는 graph projection은 KG 데이터를 인메모리 저장에 최적화된 형태로 효과적으로 재구성한다. 이 최적화된 포맷은 그래프 데이터 사이언스 알고리즘의 효율적인 실행을 가능하게 하며, 더 빠르고 효과적인 데이터 처리·분석을 가능하게 한다.
Projection의 핵심은 두 가지다. 첫째, 분석 대상 노드·관계만 골라낸다. 둘째, 디스크 기반 표현에서 인메모리 그래프 자료구조로 변환한다. 이 두 단계가 합쳐져 알고리즘이 메모리 접근 비용 없이 인접 리스트를 순회할 수 있게 된다.
6. Weakly Connected Components: 커뮤니티 분리
가중치 그래프 위에서 가장 먼저 적용되는 알고리즘은 Weakly Connected Components(WCC)다. 이 community detection 알고리즘은 두 노드 사이에 어떤 방향이든 link가 있는 노드들에 고유 ID를 부여한다. 매우 큰 데이터셋에서도 이 효율적인 알고리즘은 공유된 연결에 기반해 수만 명 단위의 client 그룹을 식별할 수 있다.
WCC가 사기 탐지에서 갖는 의미는 다음과 같다. 이런 커뮤니티들은 그렇지 않으면 계산적으로 비효율적이거나 전통적인 SQL 및 관계형 DB 접근으로는 발견이 불가능한 엔티티들을 연결한다. 데이터 규모가 커질수록 이질적인 연결들을 엮어주는 KG의 필요성은 더욱 커진다.
WCC 결과로 얻은 community ID는 후속 분석의 기본 단위가 된다. 분석가는 더 이상 수백만 client 전체를 보지 않고, 의심스러운 community 수십~수백 개만 본다. 분석 공간이 압축된다.
7. Shortest Path: Community 내부 연결 추적
Community 단위로 좁히고 나서도, 그 안에 수천 명의 client가 들어있는 경우가 흔하다. 사기 네트워크는 때때로 수천 명의 client가 서로 연결될 만큼 매우 커질 수 있다. 이 안에서 특정 두 client가 어떻게 연결되는지 추적하는 데 shortest path 알고리즘이 쓰인다. 같은 weakly connected component 커뮤니티 안에서 잠재적 사기범 사이의 연결 경로를 매핑하는 데 도움이 된다.
같은 알고리즘이 물류 분야에서 공급망 분석과 두 지점 사이의 최단 경로 분석에도 유용하다는 점은, 그래프 알고리즘이 도메인 무관한 일반적 도구라는 사실을 보여준다. 사기 탐지에서 의미 있는 동일 연산이 공급망에서도 의미 있다는 사실은 우연이 아니다. 둘 다 "관계의 비용을 따라 두 점을 잇는다"는 동일한 추상에 속한다.
8. Eigenvector Centrality: 사기 링의 핵심 인물 지목
WCC가 community를 만들고 shortest path가 그 안의 경로를 추적했다면, 마지막 단계는 community의 "주범"을 찾는 일이다. 큰 community에서는 node centrality 측정값을 활용해 어떤 노드가 네트워크 안에서 가장 중요하거나 영향력 있는지를 식별하는 것이 유용하다. 사기 탐지에서 흔히 쓰이는 centrality 측정값 중 하나가 Eigenvector Centrality다.
Eigenvector Centrality는 단순 degree centrality와 다르다. Degree centrality는 "연결이 많은 노드가 중요하다"고 보지만, Eigenvector Centrality는 "중요한 노드와 연결된 노드가 중요하다"는 재귀적 정의를 사용한다. 노드 A의 중심성은 A에 연결된 모든 노드의 중심성 합에 비례한다. 이 정의는 고유벡터 방정식 형태로 풀린다.
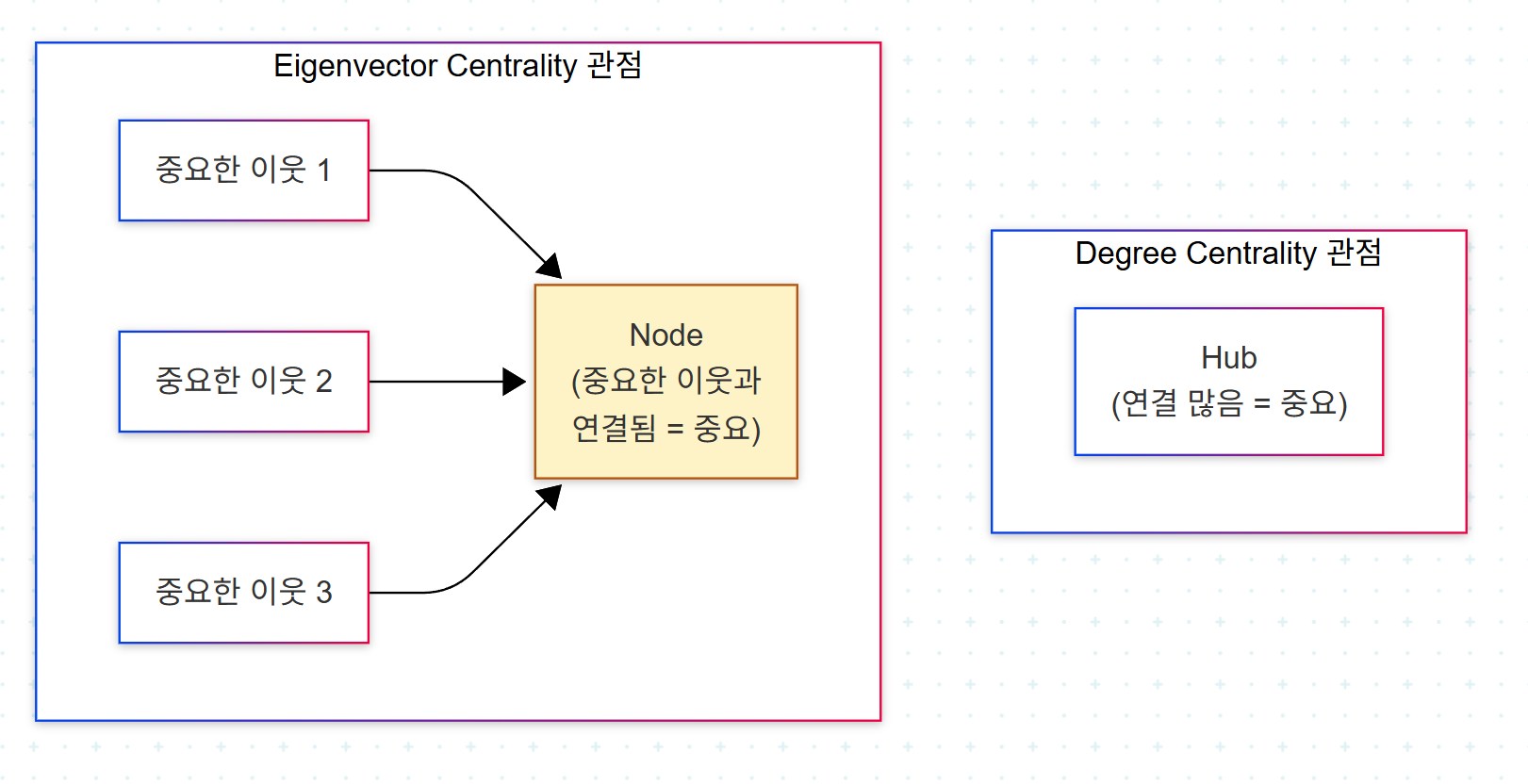
이 차이가 사기 탐지에서 결정적이다. 사기 링의 주범은 종종 직접 연결 수를 의도적으로 제한한다. 노출을 피하기 위해 중간 매개자(mule)를 거치기 때문이다. 그러나 그 중간 매개자들이 다시 다수의 client와 연결되어 있다면, 주범의 중심성은 degree로는 낮아 보여도 eigenvector로는 높게 측정된다.
| 측정값 | 정의 | 사기 탐지 의미 |
|---|---|---|
| Degree Centrality | 직접 연결 수 | 표면적 hub 탐지 — 데이터 품질 이슈 노드 포함 |
| Betweenness Centrality | 다른 노드들 사이의 최단 경로에 얼마나 자주 포함되는가 | 거래 흐름의 길목 — 자금 세탁 경로 |
| Eigenvector Centrality | 중요한 노드와의 연결 가중 합 | 사기 링의 진짜 주범 — 중간 매개자 뒤에 숨은 인물 |
복잡한 관계 네트워크에서 잠재적으로 사기성인 노드를 드러내는 데 이 접근법이 도움이 된다. Eigenvector Centrality는 네트워크 구조에 대한 더 깊은 통찰을 제공하며, 커뮤니티 내 연결성과 흐름의 중심에 있는 노드를 부각한다. 대규모 사기 탐지에서 node centrality 알고리즘은 네트워크 안의 주요 가해자를 정확히 지목하는 데 결정적인 역할을 한다.
9. 3단계 분석 흐름 통합
지금까지의 단계들을 하나의 파이프라인으로 정리하면 다음과 같다.

각 단계의 역할은 다음과 같이 분리된다.
| 단계 | 역할 | 출력 |
|---|---|---|
| Super Node 필터링 | 데이터 품질·hub 노드 분리 | 정제된 분석 대상 |
| Graph Projection | 인메모리 최적화 | GDS 알고리즘 입력 |
| WCC | community 분리 | community ID |
| Shortest Path | community 내 경로 추적 | 연결 경로 |
| Eigenvector Centrality | community 주범 식별 | 중심성 score |
10. 수사 실무 관점
이 챕터가 단순 기술 정리에 그치지 않는 이유는 수사 실무의 관점을 명시적으로 도입하기 때문이다. 사기 탐지에서는 수사팀을 돕기 위해 initial lead subject를 식별하는 것이 중요하다. 대규모 범죄 네트워크는 다루기 번거롭고 비대하다. 분석이 정확하지 않으면 잘못된 인물을 추적하게 되고, 결과적으로 수사의 정당성과 무고한 개인의 프라이버시가 모두 위협받는다.
이런 신중한 분석은 결과의 정확성을 보장할 뿐 아니라 수사의 무결성을 유지하고 개인의 프라이버시를 보호하는 데도 결정적이다. 정밀하고 효율적인 데이터 분석 방법을 구현하는 것은 핵심 인물을 분리하고 더 광범위한 사기 활동 네트워크를 풀어내는 데 매우 가치 있게 작용한다.
기술적으로는 동일한 알고리즘이라도, 출력 결과를 어떻게 운영 워크플로에 연결하는지가 시스템의 가치를 결정한다. Centrality score 상위 노드를 자동으로 차단·신고하는 것과, 수사관의 초기 lead로 제시하는 것은 완전히 다른 시스템이다. 자동화의 정도와 사람의 개입 지점을 명확히 설계해야 한다.
참고 자료
- Graph Data Science with Python and Neo4j — Chapter 10: Fraud Detection.
