이 챕터의 thesis는 다음과 같다. 추천은 본질적으로 "관련 있는 후보를 찾는 단계"와 "부적절한 후보를 걸러내는 단계"로 분해되며, RAG는 vector similarity로 전자를, similarity score cutoff로 후자를 수행한다. KG와 LLM이 결합되면 단순 키워드 검색이 닿지 못하는 의미 기반 추천이 가능해진다.
1. 추천 엔진의 정의와 KG의 자리
추천 엔진은 사용자에게 가장 관심이 있을 만한 아이템을 예측하거나 제시하는 도구로 정의된다. 핵심 가치는 두 가지다. 사용자의 고유한 맥락을 반영한 personalization과, 의사결정 과정을 돕는 user engagement다. 단순히 인기 아이템을 노출하는 것과 추천 엔진을 가르는 지점이 바로 이 두 축이다.
전통적으로 추천 엔진은 세 갈래로 분류된다.
| 방식 | 동작 원리 | 강점 | 약점 |
|---|---|---|---|
| Content-Based Filtering | 사용자가 과거 선호한 아이템의 속성에 기반해 유사 아이템 추천 | cold-start user에 강건, 설명 가능성 | 다양성 부족, 콘텐츠 메타데이터 의존 |
| Collaborative Filtering | 유사한 사용자들의 선호 패턴을 활용 | 발견적(serendipity), 콘텐츠 무관 | cold-start, sparsity |
| Hybrid Systems | 위 둘을 결합 | 단점 상쇄, 포괄적 추천 | 구현·튜닝 복잡도 |
Knowledge graph는 이 분류 위에서 특수한 위치를 차지한다. 노드와 관계 자체가 일급 객체이기 때문에, 관계를 따라가는 traversal로 풍부한 맥락 분석이 가능하고, 새로운 엔티티·관계 타입을 손쉽게 추가할 수 있으며, 그래프 알고리즘(link prediction 등)을 그대로 추천 신호로 활용할 수 있다. Content-based의 속성 기반 매칭과 collaborative의 관계 기반 패턴이 한 데이터 모델 위에서 자연스럽게 결합된다는 점이 KG가 추천 도메인에서 갖는 구조적 이점이다.
2. 특허 도메인이 어려운 이유
이번 챕터의 예시 도메인은 특허(patent)다. 특허는 단순한 텍스트 코퍼스가 아니라, 변호사가 작성한 고도로 기술적인 문서다. 어휘는 의도적으로 모호하게 설계되고, 청구항(claim) 사이의 맥락이 중첩된다. 분석 측면에서는 두 가지 어려움이 누적된다.
첫째, 절대량이다. 한 분야의 특허만 수만 건 단위로 쌓이며, 인접 기술까지 포함하면 수십만 건이 된다. 둘째, 의미적 모호성이다. 같은 기술을 다른 표현으로 기술하거나, 다른 기술이 같은 용어로 표현되는 경우가 흔하다. 키워드 검색 기반 추천은 이 두 문제 모두에 취약하다. 키워드 매칭은 표현 차이에 약하고, 결과 수가 폭발할 때 ranking이 무력해진다.
RAG가 이 도메인에 적합한 이유가 여기서 나온다. Vector embedding은 표현 차이를 의미 공간에서 흡수하고, similarity score를 활용한 ranking과 cutoff는 결과 수 폭발을 통제한다. 이 챕터는 그 흐름을 Neo4j 위에서 구현하는 방식을 보여준다.
3. RAG 파이프라인의 골격
Neo4j 기반 RAG 추천 엔진의 흐름은 다음과 같이 정리된다.

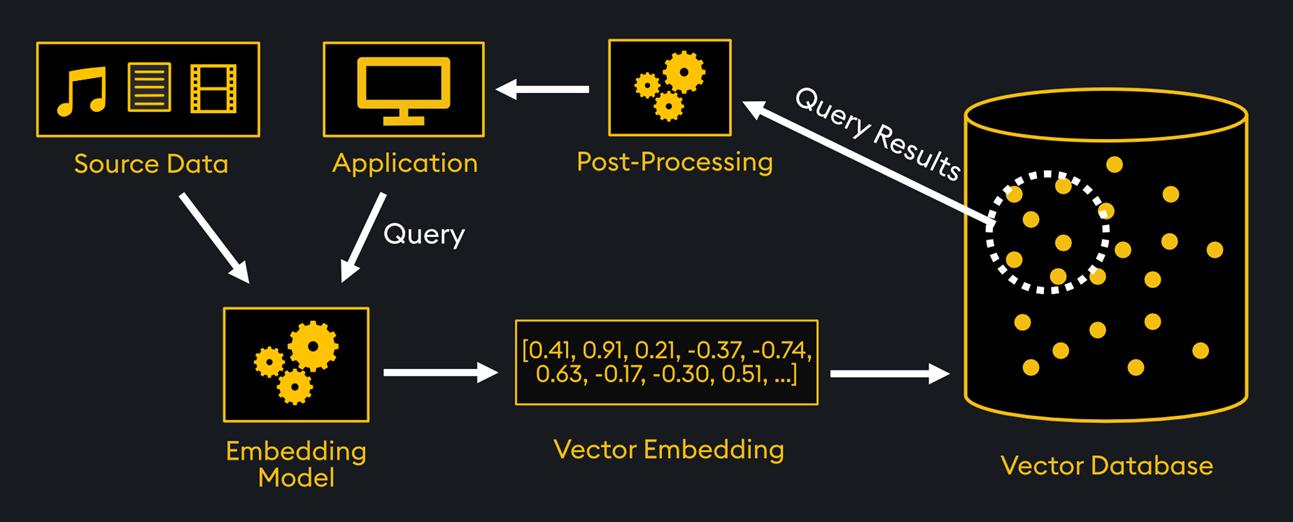
이 파이프라인의 첫 단계는 Neo4j vector index 연결이다. 임베딩 모델로 특허 텍스트를 벡터로 변환해 저장하고, 쿼리 시점에 페르소나 설명이나 사용자 질의를 같은 모델로 임베딩한 뒤 cosine similarity로 인접 벡터를 검색한다. Neo4j는 이 vector index와 기존 graph traversal을 하나의 storage 안에서 결합할 수 있어, "유사한 특허를 찾고, 그 특허의 발명자·인용 관계를 따라가는" 식의 복합 질의가 자연스럽게 작동한다.
4. False Positive 필터링: 추천의 진짜 어려움
Vector similarity 검색은 항상 결과를 반환한다. 코사인 유사도가 정의된 이상 0에 가까운 점수라도 "가장 가까운 K개"는 존재한다. 문제는 이 K개 중 상당수가 잘못된 매치라는 점이다. 특허처럼 의미가 미세하게 갈리는 도메인에서는 더욱 그렇다.
이 챕터가 강조하는 핵심 기법은 RAG의 ranking 결과에 score cutoff를 적용해 false positive를 일괄 제거하는 것이다. 페르소나 설명과 가장 유사한 후보들을 ranking한 뒤, 일정 임계값 미만의 결과는 잘라낸다. 단순해 보이지만 추천 품질에 결정적이다. Cutoff 없이 top-K만 노출하면 의미적으로 어긋난 결과까지 추천 리스트에 포함되어 사용자 신뢰가 훼손된다.
복잡한 도메인일수록 이 단계가 중요해진다. 특허의 경우 RAG 구현은 텍스트의 semantic essence를 유지하면서 false positive 매치를 걸러내는 데 결정적인 역할을 한다.
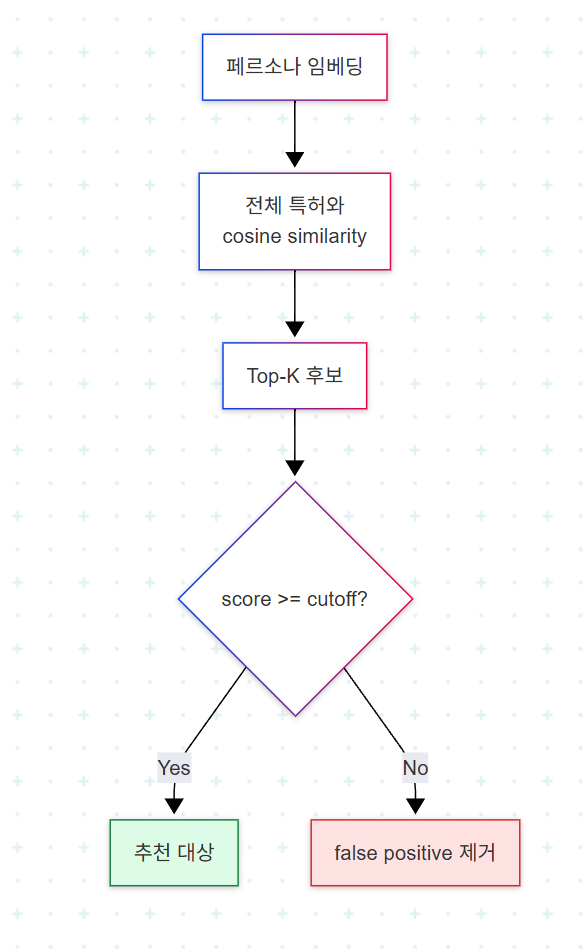
Cutoff 값의 결정은 도메인에 따라 다르다. 일반 텍스트 코퍼스에서는 0.7 전후가 흔히 쓰이지만, 특허처럼 어휘가 좁고 표현이 정형화된 도메인에서는 0.8 이상에서 비로소 의미 있는 매치가 시작되는 경우도 있다. 챕터는 구체적 수치보다 cutoff 적용 자체를 강조한다.
5. RetrievalQA Chain: LLM과 KG의 결합
Vector similarity 기반 검색만으로는 "유사한 특허"의 리스트는 만들 수 있어도, 그 특허들이 왜 추천되는지를 자연어로 설명하기 어렵다. 이 지점에서 RetrievalQA chain이 등장한다.
RetrievalQA는 두 단계로 구성된다. Retrieval 단계는 외부 데이터 소스(여기서는 Neo4j)에 질의해 관련 정보를 가져온다. 이 정보는 LLM에 컨텍스트로 전달되어, 더 정보에 입각한 정확하고 관련성 있는 응답을 생성하는 데 사용된다. 결과적으로 LLM의 일반 지식과 데이터베이스의 도메인 특화 데이터가 단일 응답으로 결합된다.
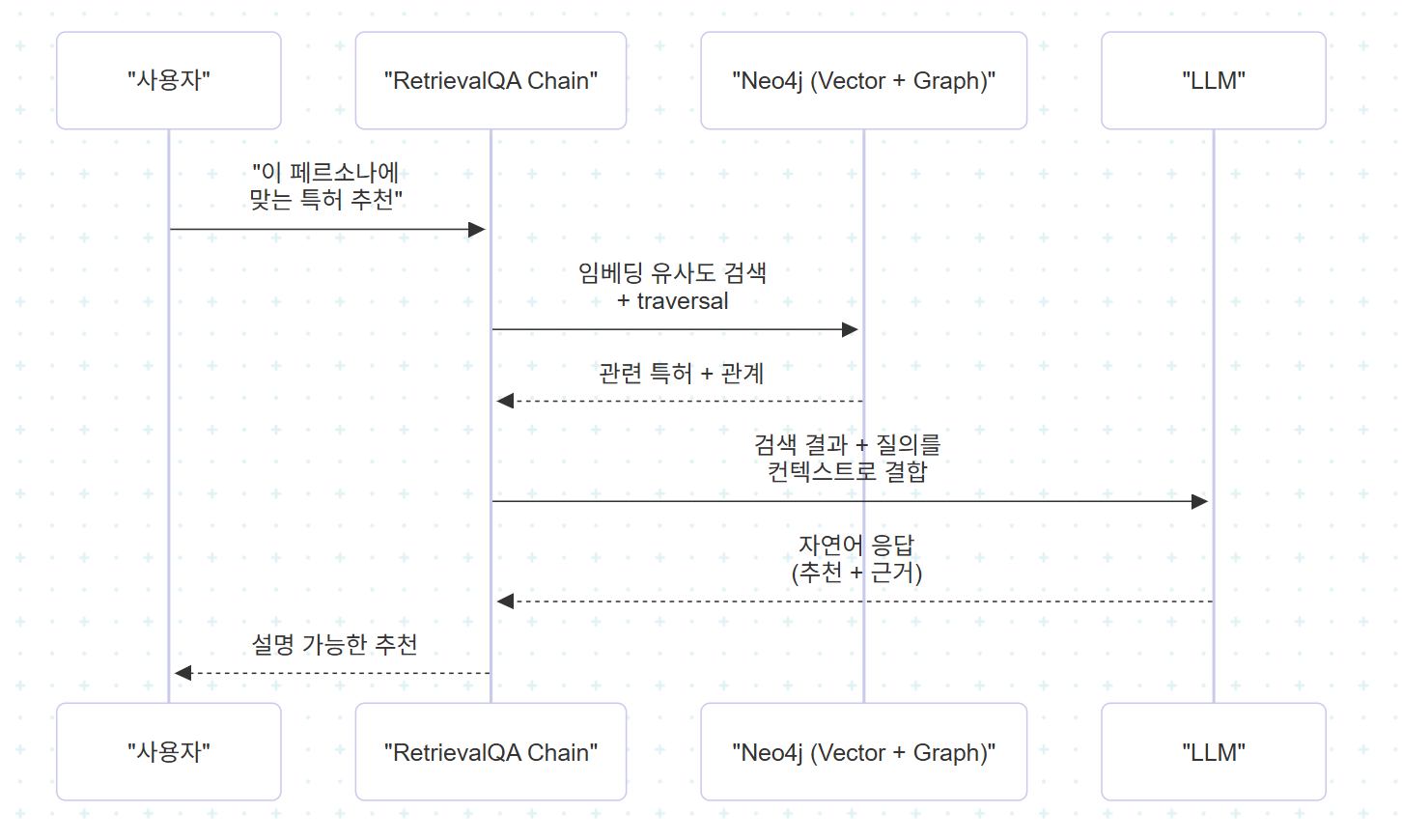
RetrievalQA의 강점은 두 가지가 동시에 충족된다는 데 있다. 데이터베이스의 proprietary data가 응답의 사실성을 보장하고, LLM의 생성 능력이 응답의 가독성과 맥락성을 보장한다. 챗봇 형태의 추천 인터페이스에서 특히 유용한 이유다. 사용자에게 반환되는 정보가 최신이며 관련성이 있어야 하는 시나리오에 잘 맞는다.
6. Content-Based Filtering의 텍스트 분석으로의 재해석
이 챕터의 또 다른 메시지는 content-based filtering이 사실상 텍스트 분석 문제로 환원된다는 관찰이다. 사용자가 과거 좋아한 아이템의 속성을 추출해 유사 아이템을 추천하는 작업은, 임베딩 시대에 들어 다음과 같이 재구성된다.
- 사용자 선호(또는 페르소나)를 자연어로 기술한다.
- 그 텍스트를 임베딩한다.
- 아이템 임베딩과의 유사도로 후보를 ranking한다.
- Cutoff와 RetrievalQA로 결과를 정제한다.
이 흐름은 별도의 feature engineering 없이도 의미적 추천을 가능하게 한다. RAG는 content-based filtering을 텍스트로부터 의미 있는 정보를 추출해 수행한다고 정리할 수 있다. 즉, 임베딩 기반 RAG는 content-based filtering의 현대적 구현체로 볼 수 있다.
7. 두 가지 결합 방식의 비교
이 챕터에 등장하는 두 메커니즘—단순 vector similarity 검색과 RetrievalQA chain—은 추천 엔진에서 서로 다른 역할을 맡는다.
| 항목 | Vector Similarity Only | RetrievalQA Chain |
|---|---|---|
| 출력 형태 | 아이템 리스트 + score | 자연어 응답 + 근거 |
| LLM 개입 | 없음 (임베딩 단계만) | Retrieval 후 generation |
| 외부 데이터 활용 | 임베딩 매칭에 한정 | 컨텍스트로 직접 주입 |
| 적합 시나리오 | 검색·필터·랭킹 UI | 챗봇·대화형 추천 |
| 비용 | 낮음 (DB 조회만) | 높음 (LLM 호출 추가) |
| 응답 일관성 | 결정적 | 확률적(LLM 응답에 의존) |
실무 설계에서는 두 단계를 직렬로 결합하는 패턴이 흔하다. Vector similarity로 후보군을 빠르게 좁히고, cutoff로 false positive를 제거한 뒤, 사용자가 더 깊은 설명을 요청할 때만 RetrievalQA chain을 호출하는 식이다. 이는 LLM 호출 비용을 통제하면서 설명 가능성을 확보하는 절충안이다.
8. 정리
이 챕터의 결론부는 단순한 기술 정리에 그치지 않고, IP·R&D 같은 첨단 분야에서의 전략적 가치를 강조한다. 추천 엔진은 대규모 데이터를 훑으면서, 그렇지 않았다면 결코 발견되지 않았을 연결과 통찰을 식별하는 능력을 제공한다. 지식재산권, 연구개발, 그 외 최첨단 분야의 전문가에게 이런 도구는 경쟁에서 앞서가고, 혁신하며, 전략적 우위를 확보하는 수단이 된다.
KG와 LLM의 결합은 단순한 검색 자동화가 아니라, 사람의 인지 한계를 보완하는 도구로 자리잡는다. 수만 건의 특허 중에서 어떤 두 건이 연결되는지를 사람이 모두 검토하는 것은 불가능하지만, 임베딩 유사도와 그래프 관계를 결합한 시스템은 이를 일상적인 질의로 수행한다.
결론: 추천은 "찾기"와 "거르기"의 직렬 결합이며, RAG는 vector similarity로 찾고 cutoff로 거른다. KG와 LLM이 그 위에 더해질 때, 추천은 비로소 설명 가능해진다.
참고 자료
- Graph Data Science with Python and Neo4j — Chapter 9: Recommendation Engines Using Embeddings.
