이번 글의 thesis는 다음과 같다. 그래프 알고리즘은 연결된 데이터에서 숨겨진 패턴을 드러내는 도구이며, 5개의 카테고리 — Centrality, Community Detection, Similarity, Link Prediction, Network Embeddings — 가 거의 모든 그래프 분석 시나리오를 커버한다. Neo4j는 이 알고리즘들을 데이터베이스 내부에서 직접 실행할 수 있는 unique opportunity를 제공하며, 이는 데이터 파이프라인을 단순화하고 인사이트 도달 시간을 단축한다.
1. 왜 Graph Algorithm인가
데이터가 점점 더 연결될수록 그래프 알고리즘은 그 데이터에서 의미를 추출하는 데 큰 역할을 한다. knowledge graph는 상호연결된 데이터의 복잡한 web을 탐색하고 이해할 수 있는 unique opportunity를 제공한다.
그래프 알고리즘이 다루는 문제는 다음과 같이 정리된다.
| 문제 유형 | 질문 | 대표 알고리즘 |
|---|---|---|
| 중심성 | 누가/무엇이 가장 중요한가 | PageRank |
| 커뮤니티 | 어떻게 무리 지어 있는가 | Louvain |
| 유사성 | 어느 노드가 닮았는가 | Jaccard, Cosine |
| 연결 예측 | 어떤 연결이 생길 것인가 | Adamic-Adar |
| 표현 학습 | 그래프를 어떻게 벡터로 변환할까 | GraphSAGE |
Neo4j의 결정적 가치는 이 알고리즘들을 데이터베이스 내부에서 직접 실행할 수 있다는 점이다. in-database 분석은 데이터 엔지니어와 데이터 사이언티스트의 데이터 파이프라인을 단순화하고, 결과적으로 end stakeholder를 위한 인사이트와 액션이 더 빠르고 효과적으로 이어진다.
2. 전체 워크플로: GDS Pipeline
5가지 알고리즘 카테고리는 모두 동일한 GDS 워크플로를 공유한다.
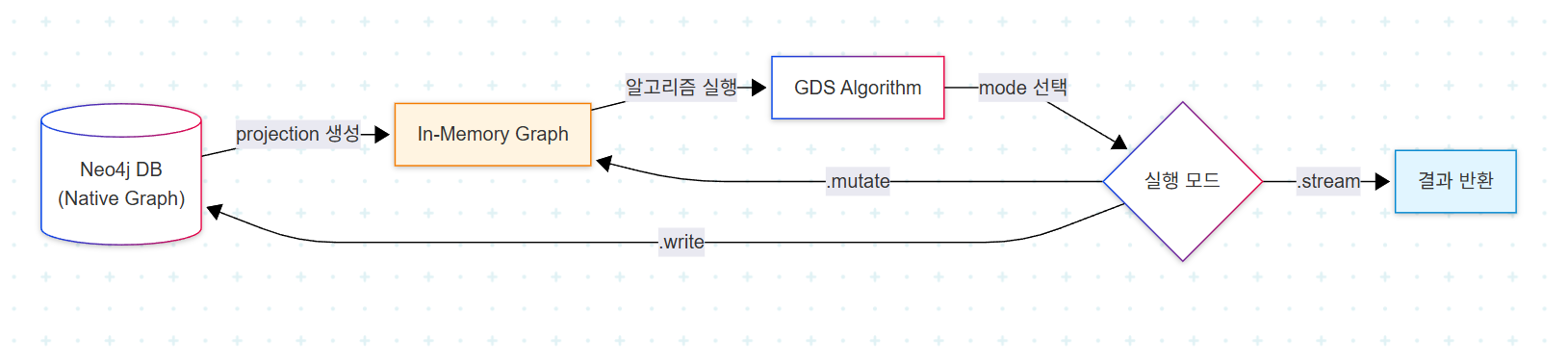
GDS의 모든 알고리즘 호출은 세 가지 실행 모드 중 하나를 선택한다.
| 모드 | 동작 | 적합 상황 |
|---|---|---|
.stream | 결과를 행 단위로 반환, DB 미변경 | 탐색적 분석, 즉시 시각화 |
.write | 결과를 노드/관계 속성에 영구 저장 | 운영 환경, 후속 쿼리 활용 |
.mutate | in-memory projection만 갱신 | 알고리즘 체이닝 |
이 워크플로 위에서 5개 카테고리를 차례로 살펴본다.
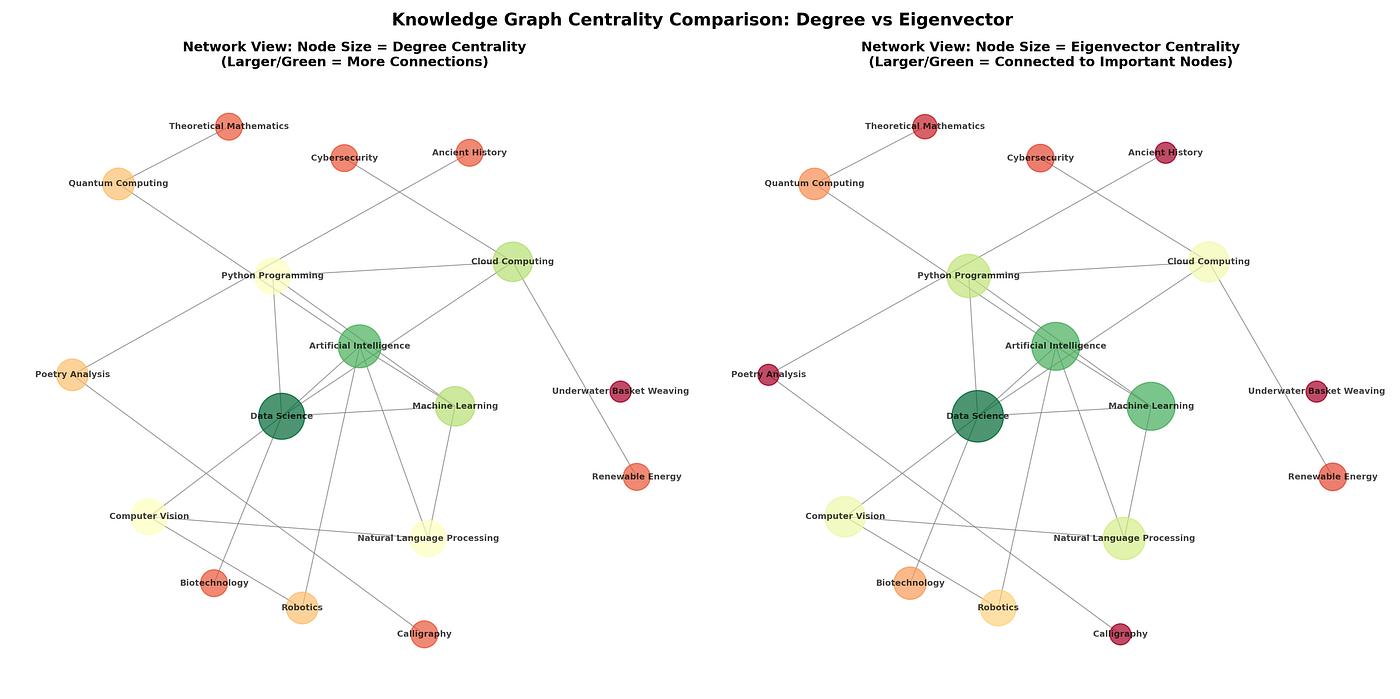
3. Centrality: 가장 중요한 노드 찾기
Centrality 알고리즘은 graph data science에서 중추적 역할을 한다. 네트워크 내에서 가장 pivotal하고 influential하며 중요한 노드를 풀어내는 것이 목적이다. 가장 친숙한 사례는 소셜 미디어 플랫폼의 뉴스 피드에서 가장 많이 팔로우되는 인플루언서가 상단으로 밀려 올라오는 것이다.
PageRank: 알고리즘이 검색을 바꾼 순간
PageRank는 Google의 공동 창립자 Larry Page와 Sergey Brin이 개발한 centrality 측정 방식으로, 웹 검색 알고리즘에 혁명을 일으켰다. 그 전제는 elegant yet powerful하다 — 노드 간 연결을 기반으로 네트워크 내 노드의 중요도를 측정한다.
핵심 원리:
- 높은 순위 노드에서 다른 노드로 향하는 관계는 그 새 노드의 순위를 끌어올린다
- 알고리즘은 노드 연결 간 점수를 반복적으로(iteratively) 계산한다
- damping factor를 도입하여 연결의 randomness를 줄이고, 모든 페이지가 non-zero rank를 가지도록 보장한다
// 1. Projection 생성
CALL gds.graph.project(
'webGraph',
'Page',
'LINKS_TO'
);
// 2. PageRank 실행 (stream 모드)
CALL gds.pageRank.stream('webGraph', {
maxIterations: 20,
dampingFactor: 0.85
})
YIELD nodeId, score
RETURN gds.util.asNode(nodeId).url AS page, score
ORDER BY score DESC
LIMIT 10;damping factor 0.85는 PageRank의 표준 기본값으로, 임의 사용자가 현재 페이지의 링크를 따라갈 확률을 의미한다. 이 값이 낮을수록 무작위 점프 비중이 커지고, 결과 분포가 평탄해진다.
PageRank가 검색 엔진에 혁명을 일으킨 이유는 단순한 in-degree 카운트(들어오는 링크 수)와 다르게, 연결의 출처가 가진 권위를 재귀적으로 반영하기 때문이다. 권위 있는 사이트에서 받은 링크 1개가 무작위 사이트의 링크 100개보다 가치 있을 수 있다.
4. Community Detection: 모듈 구조 해독
Community detection은 그래프의 modular structure를 해독하도록 돕는다. community는 네트워크 내의 cluster이며, 강한 내부 연결을 가진 하위 그룹을 의미한다.
사회적 상호작용을 매핑하든, 복잡한 생물학적 시스템을 풀어내든, 복잡한 사기 네트워크를 파싱하든, community detection은 강한 내부 연결을 가진 subgroup을 식별하도록 돕는다. 사기 탐지 영역에서 특히 가치 있는 이유는 다음과 같다. 단순 거래 패턴 분석은 사기 거래 하나하나를 잡지만, community detection은 협업하는 사기 네트워크 전체를 한 단위로 식별한다.
Louvain Algorithm
Louvain은 대규모 네트워크에서 community detection을 위해 널리 사용되는 매우 효율적인 방법이다. modularity라는 지표를 최적화한다. modularity는 네트워크를 모듈 또는 community로 분할한 강도를 측정하는 스케일 값이다.
Louvain은 2단계로 작동한다.
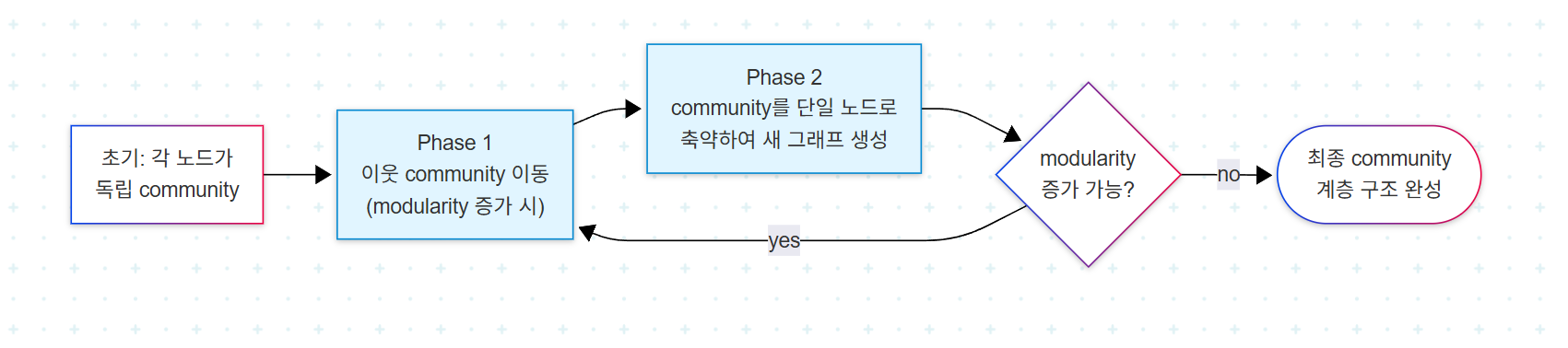
Phase 1에서는 각 노드를 이웃 community에 할당하고, Phase 2에서는 같은 community의 노드를 집계하여 community의 새 네트워크를 구축한다. 이 과정이 modularity가 더 이상 증가할 수 없을 때까지 반복된다.
// Louvain 실행
CALL gds.louvain.stream('socialGraph')
YIELD nodeId, communityId
RETURN
communityId,
collect(gds.util.asNode(nodeId).name) AS members,
count(*) AS size
ORDER BY size DESC;k-means 같은 평면 클러스터링과 달리, Louvain의 계층적 구조는 dendrogram 형태의 community 트리를 만든다. 분석가는 필요한 추상화 수준에서 community를 잘라낼 수 있으며, 이는 사기 네트워크의 큰 그림과 세부 셀 구조를 동시에 다룰 때 결정적 유연성을 제공한다.
community detection을 실행하고 나면, 새로운 패턴이 드러나기 시작한다. 이전에는 개별 노드로만 보이던 데이터가 그룹화된 단위로 재구성되며, 이는 후속 분석의 출발점이 된다.
5. Similarity: 노드 간 닮음의 정량화
Similarity 알고리즘은 그래프 내 노드 간의 likeness 또는 resemblance를 정량화하도록 설계되었다. 사용자 노드 간의 나이나 위치 같은 그래프 특징을 비교한다.
| 알고리즘 | 핵심 메커니즘 | 적합 데이터 |
|---|---|---|
| Cosine Similarity | 다차원 공간의 벡터 각도 | 텍스트 임베딩, NLP |
| Jaccard Similarity | 집합의 교집합/합집합 | 관계 기반 멤버십 |
| Pearson Correlation | 선형 상관 | 평점·수치 데이터 |
| Overlap Coefficient | 교집합/최소 집합 크기 | 비대칭 포함 관계 |
서로 다른 similarity 알고리즘은 서로 다른 데이터 유형과 응용에서 장점을 제공한다. Cosine similarity는 텍스트 분석과 NLP 분야에서 강력하고 일반적으로 사용되는 알고리즘이다 — 다차원 공간에서 두 벡터 간의 유사성을 측정하기 때문이다.
Jaccard Similarity Index: 집합 기반 유사도
Jaccard Similarity Index는 두 집합 간의 유사성을 정량화하는 일반적 방법이다. 알고리즘은 두 노드 간의 교집합을 측정한 다음, 집합 합집합의 크기로 나눈다.
이 접근은 노드 간의 관계가 그 노드의 membership을 정의하는 시나리오에서 특히 유용하다. 예를 들어 두 사용자가 follow하는 계정 집합, 두 영화가 출연시킨 배우 집합처럼 "어떤 것에 연결되어 있는가"가 정체성을 정의하는 경우다.
// Node similarity (Jaccard 기반) 실행
CALL gds.nodeSimilarity.stream('userInterestGraph', {
similarityCutoff: 0.5,
topK: 10
})
YIELD node1, node2, similarity
RETURN
gds.util.asNode(node1).name AS user1,
gds.util.asNode(node2).name AS user2,
similarity
ORDER BY similarity DESC;Jaccard의 가장 실용적 활용 중 하나는 entity resolution이다. 데이터에 여러 중복 노드가 존재할 때, 유사한 community composition으로 정의된 중복 노드들이 있다면 Jaccard Similarity Index가 그 유사성을 정량화하여 데이터 중복 제거를 가능하게 한다. 동일 인물의 다른 표기, 동일 회사의 자회사 별칭 같은 사례가 모두 이 패턴으로 처리된다.
다만 이 알고리즘은 size variation에 민감하다. 한 노드는 10개 이웃을 가지고 다른 노드는 1000개 이웃을 가질 때, Jaccard 점수는 교집합 비율로만 평가되어 규모 차이에서 오는 정보를 놓친다. 이 단순성과 해석 가능성이 탐색적 데이터 분석과 유사성 비교에서 인기 있는 선택이 되게 만든다.
6. Link Prediction: 미래의 연결 예측
Link prediction은 복잡한 네트워크 내에서 잠재적 연결을 이해하는 강력한 접근이다. 이 기법은 이웃 간 공유 연결의 수를 단순히 카운팅하는 것을 넘어선다.
활용 영역은 광범위하다.
- 소셜 네트워크: 현재 연결과 그 연결들의 다른 개인과의 관계를 검토하여 새 친구 추천
- 추천 시스템: 사용자-아이템 잠재 선호 예측
- e-commerce: 상호 구매 가능성 추정
- 신약 개발: 약물과 질병 간 잠재적 연결 식별 → 더 효과적인 치료법으로 가는 길 개척
Adamic-Adar Index: 희귀 연결의 가중
Adamic-Adar Index는 less common한 link의 중요성을 강조함으로써 네트워크 내 잠재적 연결을 식별하는 능력으로 알려져 있다. 개념적으로 이 알고리즘은 네트워크 내 노드 간의 모든 공유 연결이 동등하게 중요하지 않다는 아이디어에 뿌리를 두고 있다.
| 공통 이웃의 특성 | Adamic-Adar의 가중치 | 직관 |
|---|---|---|
| 이웃이 많은 popular 노드 (예: 인기 해시태그) | 낮음 | 누구나 연결됨, 정보 가치 낮음 |
| 이웃이 적은 niche 노드 (예: 전문 학회) | 높음 | 두 사람이 같은 niche 노드와 연결됨은 강한 신호 |
희귀하거나 흔치 않은 연결이 있다면, 그 연결은 더 무겁게 가중된다. 두 연구자가 동일한 거대 학회에 모두 참여했다는 사실보다, 동일한 5명짜리 워크숍에 모두 참여했다는 사실이 협업 가능성에 대해 훨씬 강한 신호를 준다. 이 직관이 Adamic-Adar의 정량적 핵심이다.
// 두 노드 간 Adamic-Adar 점수 계산
MATCH (u1:User {id: 'A'}), (u2:User {id: 'B'})
RETURN gds.alpha.linkprediction.adamicAdar(u1, u2) AS score;복잡한 네트워크를 탐색하여 anchor 노드로의 연결을 파싱할 수 있을 뿐 아니라, 상대 빈도에 기반하여 연결에 자동으로 가중치를 부여할 수 있어 분석 효과를 극적으로 향상시킨다.
7. Network Embeddings & GNN: 그래프를 벡터로
Network embedding과 graph neural network(GNN)는 인공지능과 네트워크 과학이 교차하는 최첨단을 대표한다.
그래프 구조를 임베딩하는 목적은 그래프의 구조를 보존하면서 그래프를 컴퓨터가 읽을 수 있는 벡터 표현으로 변환하는 것이다. 이 변환은 노드 분류, 연결 예측, 클러스터링, 시각화를 포함한 다양한 형태의 분석을 가능하게 한다.
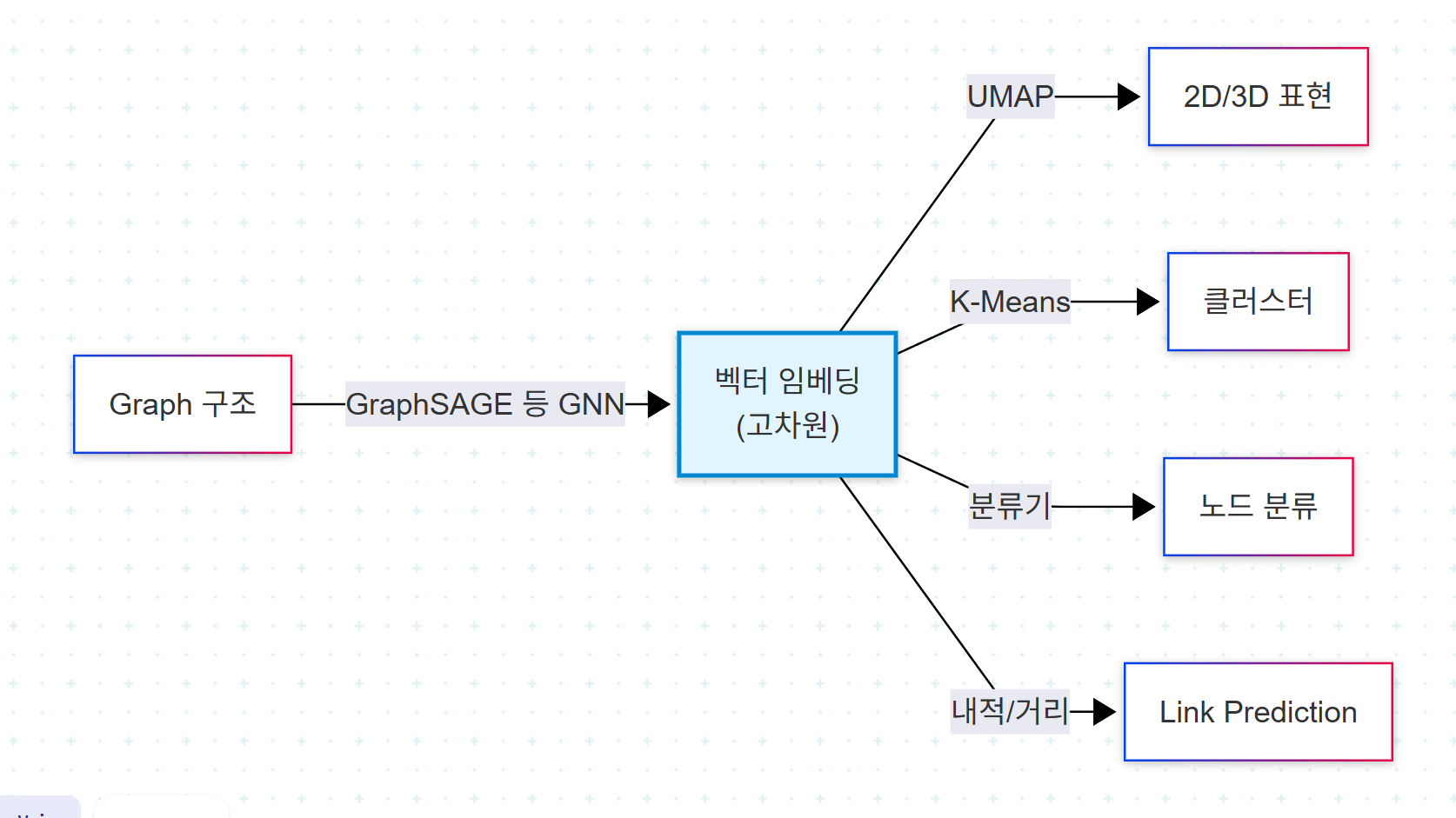
GraphSAGE: 샘플링 기반 GNN
GraphSAGE(Graph Sample and AggregatE)는 노드의 local neighborhood로부터 features를 sampling하고 aggregating하여 임베딩을 생성하는 novel approach를 GNN에 도입한다. 기존의 transductive GNN(예: 초기 GCN)이 학습 시점에 존재했던 노드에만 임베딩을 줄 수 있던 것과 달리, GraphSAGE는 unseen data에 대한 예측을 지원하며 각 노드에 대해 고정된 수의 이웃을 샘플링하기 때문에 매우 확장 가능하다.
| GNN 비교 축 | 전통 GCN | GraphSAGE |
|---|---|---|
| 학습 방식 | transductive | inductive |
| 새 노드 처리 | 전체 재학습 필요 | 학습된 함수로 즉시 임베딩 |
| 이웃 처리 | 전체 이웃 집계 | 고정 수 샘플링 |
| 확장성 | 제한적 | 대규모 그래프 적합 |
GraphSAGE는 추천 시스템, 노드 분류, 연결 예측, 사기 탐지, 신약 발견 등에서 유용하다.
UMAP과 K-Means: 임베딩의 시각화·클러스터링
GraphSAGE가 생성한 임베딩은 일반적으로 64차원, 128차원처럼 고차원이다. 이를 인간이 해석하려면 차원 축소가 필요하다.
UMAP은 GraphSAGE가 생성한 임베딩 같은 복잡한 고차원 데이터를 시각화하도록 돕는다.
| UMAP 파라미터 | 역할 | 효과 |
|---|---|---|
n_neighbors | local vs global 구조의 균형 | 낮으면 local 디테일, 높으면 broader context |
min_dist | 축소 공간에서 점들의 밀집도 | 낮으면 타이트한 클러스터, 높으면 분산 |
이 파라미터들은 데이터 클러스터의 granularity와 separation을 결정한다. 축소된 임베딩 위에 K-Means 클러스터링을 적용하면, 고차원 공간에서 서로 유사한 노드들의 모음을 식별할 수 있다.
# 일반적 파이프라인 (의사코드)
embeddings = gds.graphsage.stream(graph, model_name='recipe_model')
reduced = umap.UMAP(n_neighbors=15, min_dist=0.1).fit_transform(embeddings)
clusters = KMeans(n_clusters=8).fit_predict(reduced)
plot(reduced, color=clusters)이 워크플로는 노드 간 의미적 유사성을 시각적으로 확인할 수 있게 해주며, 도메인 전문가의 검증과 해석을 가능하게 한다.
8. 5개 카테고리 통합 비교
각 카테고리는 답하는 질문과 활용 도메인이 명확히 다르다.
| 카테고리 | 답하는 질문 | 대표 알고리즘 | 대표 도메인 |
|---|---|---|---|
| Centrality | 누가 가장 영향력 있는가 | PageRank | SNS, 웹 검색 |
| Community Detection | 어떻게 무리 지어 있는가 | Louvain | 사기 탐지, 생물 시스템 |
| Similarity | 누가 닮았는가 | Jaccard, Cosine | Entity Resolution, NLP |
| Link Prediction | 다음 연결은 무엇인가 | Adamic-Adar | 친구 추천, 신약 개발 |
| Network Embeddings | 그래프를 어떻게 벡터화할까 | GraphSAGE | 분류, 사기 탐지, 추천 |
실무에서는 이 카테고리들을 연쇄적으로 사용하는 경우가 많다. 예를 들어 사기 탐지 시나리오는 다음과 같이 구성될 수 있다.
PageRank (의심 거래 허브 식별)
→ Louvain (협업 사기 네트워크 식별)
→ Jaccard (유사 행동 패턴 매칭)
→ GraphSAGE (학습된 임베딩으로 신규 사기 예측)이 연쇄가 가능한 이유는 GDS의 .mutate 모드가 알고리즘 출력을 in-memory projection에 즉시 추가하여 다음 알고리즘의 입력으로 사용할 수 있게 해주기 때문이다.
11. 정리
Neo4j 데이터베이스는 이 알고리즘들을 데이터베이스 내에서 제공하여 graph data science를 위한 강력한 도구가 된다. graph data science의 힘은 연결된 데이터에서 숨겨진 패턴을 드러내어 혁신과 발견을 가능하게 하는 능력에 있다.
5대 graph algorithm 카테고리는 다음과 같이 압축된다.
- Centrality는 네트워크 내에서 가장 영향력 있는 노드를 식별한다
- Community Detection은 노드의 그룹이나 클러스터를 발견하여 네트워크의 modular structure를 부각시킨다
- Similarity는 노드 간의 likeness 또는 structural equivalence를 측정한다
- Link Prediction은 두 노드 간 연결 형성의 가능성을 예측한다
- Network Embeddings와 GNN은 그래프 구조를 더 깊은 분석을 위해 표현하는 데 advanced ML 기법을 활용한다
결론: 그래프 알고리즘의 진정한 가치는 답을 주는 것이 아니라, 연결된 데이터에서 어떤 질문을 던질 수 있는지를 드러내는 데 있다.
참고 자료
- Graph Data Science with Python and Neo4j — Chapter 8: Graph Algorithms in Neo4j.
