
RAG의 한계를 인식하고, 자연어 질문을 KG에 직접 실행 가능한 formal query로 변환하는 4단계 파이프라인 — Intent Detection, Schema-to-LLM 변환, Reasoning-First Query Generation, Summarization — 을 설계했다. 이번 글은 그 개념적 설계를 실제 동작하는 시스템으로 구현하는 단계를 다룬다.
이번 글의 thesis는 다음과 같다. LangGraph의 state 기반 directed graph 아키텍처는 expert emulation 파이프라인에 자연스럽게 매핑되며, 구현의 가치는 시스템이 "무엇을 하는지"가 아니라 "어떻게 만들어졌는지"에 있다. 좋은 아키텍처는 turnkey solution이 아니라 진화 가능한 foundation을 제공한다. 그 foundation의 강점은 observability와 expert emulation 원칙에 있다.
1. LangGraph: State 기반 멀티 에이전트 오케스트레이션
LangGraph는 LLM 기반의 stateful, multi-actor 애플리케이션 구축을 위해 설계된 라이브러리로, 복잡한 추론과 의사결정 워크플로의 오케스트레이션에 특히 적합하다. 다른 에이전트 프레임워크와 구분되는 핵심은 컴포넌트 간 통신 방식이다.
전통적 파이프라인은 컴포넌트 A의 출력을 컴포넌트 B의 입력으로 직접 전달한다. LangGraph는 이 방식을 거부하고, 모든 에이전트가 공유 상태(shared state) 라는 화이트보드와 상호작용하는 모델을 채택한다. 각 에이전트는 이 화이트보드에서 이전 작업 결과를 읽고, 자신의 결과를 추가한다.
| 항목 | 직접 전달 방식 | LangGraph (Shared State) |
|---|---|---|
| 통신 단위 | 함수 인자/반환값 | 상태 객체 일부 |
| 결합도 | 높음 (인터페이스 일치 필수) | 낮음 (state 키만 합의) |
| 확장성 | 새 에이전트 추가 시 시그니처 변경 | 새 에이전트가 state 일부만 추가 |
| 라우팅 | 정적 | 동적 (dynamic edge resolution) |
| 디버깅 | 호출 스택 추적 | state 스냅샷 검사 |
아키텍처의 핵심 구성요소
LangGraph는 워크플로를 directed graph로 구현한다. 각 노드는 별도의 에이전트 함수이며, 자신의 책임을 수행하기 위해 global state와 상호작용한다 — 관련 데이터를 읽고, 실행 후 결과로 상태를 업데이트한다. 엣지는 실행 흐름을 결정하며, 어떤 노드가 다음에 실행될지를 지정한다.
특히 중요한 것이 dynamic edge resolution이다. 임의의 복잡한 로직에 기반하여 워크플로가 분기할 수 있게 해주며, 이를 통해 LLM이 그저 하나의 컴포넌트인 router 시스템부터 LLM이 자신의 실행 경로를 결정·형성하는 완전 자율 시스템까지 광범위한 스펙트럼의 애플리케이션을 구축할 수 있다.
2. State 객체: 에이전트 통신의 코너스톤
state 객체는 에이전트들이 읽고 쓸 수 있는 공유 메모리 공간으로 기능한다. 각 에이전트는 이 state의 특정 부분을 채울 책임을 가지며, 이를 통해 파이프라인 전체에 걸쳐 명확한 책임 사슬이 형성된다.
# State 정의 예시 (TypedDict 기반)
from typing import TypedDict, Optional, List
class PipelineState(TypedDict):
# 사용자 입력
question: str
selected_nodes: Optional[List[str]]
# Intent Detection 결과
intent: Optional[str]
# Schema Extraction 결과
relevant_schema: Optional[dict]
# Query Generation 결과
reasoning: Optional[str]
cypher_query: Optional[str]
# Query Execution 결과
query_result: Optional[list]
error: Optional[str]
retry_count: int
# Summarization 결과
summary: Optional[str]state는 단순히 에이전트 간 데이터를 운반하는 것이 아니라, 라우팅 결정을 내리고 에러를 우아하게 처리하는 데 필요한 컨텍스트를 함께 유지한다. 에이전트들은 진화하는 state 객체를 통해 통신하면서도 서로 decoupled 상태를 유지한다. 이것이 시스템의 modularity를 보장한다.
3. 시스템 아키텍처: Separation of Concerns
전체 시스템은 네 가지 컴포넌트로 명확히 분리된다.
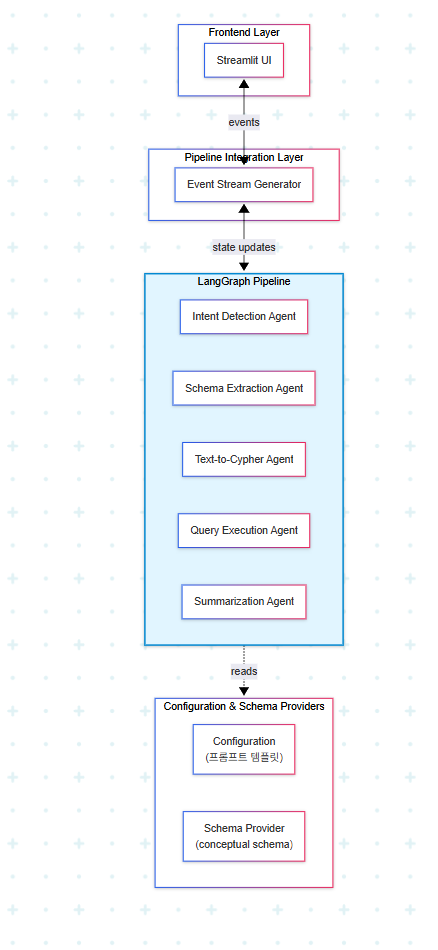
각 컴포넌트는 명확한 책임을 갖는다. LangGraph는 핵심 질문-답변 로직을 처리하고, provider는 configuration과 schema 접근을 관리하며, processing interface는 frontend 통신을 담당한다. 이러한 분리는 대화형 AI 시스템에 필요한 유연성을 유지하면서도 관심사를 깔끔하게 분리한다.
Configuration Component
Configuration 컴포넌트는 시스템이 의존하는 텍스트 요소들 — 주로 프롬프트 템플릿과 KG annotation — 의 중앙 저장소로 기능한다. 이 분리의 가치는 다음과 같다.
| 분리 이전 | 분리 이후 |
|---|---|
| 긴 프롬프트가 코드 로직에 섞임 | 템플릿 작성과 렌더링의 경계 명확 |
| 프롬프트 튜닝 시 코어 로직 위험 | 단일 위치에서 KG 설명·프롬프트 조정 가능 |
| 버전 관리 어려움 | 프롬프트·annotation 버전 관리 용이 |
특히 시스템 개발과 정제 단계에서 다양한 버전의 프롬프트를 비교 실험할 때 이 분리는 결정적 가치를 갖는다.
Schema Provider: 가장 중요한 변환
Schema Provider의 역할은 14편에서 다룬 conceptual schema 개념을 운영 가능한 형태로 구현하는 것이다. 핵심 통찰은 다음과 같다.
우리에게 필요한 것은 conceptual schema이지만, 프로그램적으로 접근 가능한 것은 technical schema뿐이다.
Schema Provider는 이 간극을 메우기 위해 3단계 프로세스를 따른다.

이 접근은 기술적 정확성을 유지하면서도 LLM에게 접근 가능한 비즈니스 지향 view를 제공하는 효과적 균형을 만들어낸다. skip list와 business description은 모두 Configuration 컴포넌트에서 관리되므로, 도메인 전문가가 코드를 건드리지 않고 schema의 LLM 표현을 조정할 수 있다.
4. 파이프라인 에이전트: Expert Emulation의 구현
14편의 expert-emulating 접근은 LangGraph 파이프라인에 자연스럽게 매핑된다. 질문-답변 프로세스의 각 단계가 특화된 에이전트로 구현된다.

각 에이전트의 책임
| 에이전트 | 입력 (state read) | 출력 (state write) | 역할 |
|---|---|---|---|
| Intent Detection | question | intent | 질문 유형 분류, 시각화 방식 결정 |
| Schema Extraction | question, selected_nodes | relevant_schema | KG와 LLM 간 다리, 컨텍스트 인식 |
| Text-to-Cypher | question, relevant_schema, error | reasoning, cypher_query | reasoning-first 쿼리 생성 |
| Query Execution | cypher_query | query_result, error, retry_count | DB 실행, 에러 처리 |
| Summarization | query_result, intent | summary | 시각화 보완 텍스트 생성 |
Intent Detection 에이전트는 파이프라인의 entry point로, 사용자 질문이 어떻게 시각화되어야 하는지를 결정한다. Schema Extraction 에이전트는 KG와 LLM 컴포넌트 사이의 다리 역할을 한다. 이 에이전트는 사용자가 선택한 노드나 관계를 명시적으로 기술하지 않고도 참조할 수 있게 해주며, 이러한 contextual awareness가 쿼리를 더 자연스럽고 간결하게 만든다.
5. Error Handling과 Retry Logic
Query Execution 에이전트에서 에러 처리는 시스템의 회복력을 결정하는 핵심 요소다. 쿼리 실행이 실패하면 (일반적으로 syntax 에러나 schema 불일치로 인해) 에이전트는 다음 작업을 수행한다.
- 에러 상세 정보 캡처
- 디버깅을 위한 실패 로깅
- 시도된 쿼리와 에러 설명을 포함한 에러 메시지 구성
- retry counter 증가
def query_execution_agent(state: PipelineState) -> dict:
try:
result = neo4j_driver.execute_query(state["cypher_query"])
return {"query_result": result, "error": None}
except Neo4jError as e:
return {
"error": f"Query: {state['cypher_query']}\nError: {str(e)}",
"retry_count": state.get("retry_count", 0) + 1
}
def should_retry(state: PipelineState) -> str:
"""Conditional edge resolver"""
if state.get("error") and state.get("retry_count", 0) < 3:
return "text_to_cypher" # 재시도
elif state.get("error"):
return END # 최대 시도 초과
else:
return "summarization" # 성공retry 메커니즘은 최대 3회까지 쿼리 실행을 시도한다. 이는 일시적 실패나 LLM이 정확한 쿼리를 생성하는 데 여러 시도가 필요한 경우에 대한 시스템의 회복력을 제공한다. 14편에서 다룬 <previous_error> 필드가 이 단계에서 실효성을 발휘한다. 이전 시도의 에러 메시지가 다음 쿼리 생성 prompt에 주입되어, 모델이 이전 결정을 검토하고 수정된 쿼리를 생성할 수 있다.
이 dynamic routing 능력은 LangGraph의 핵심 기능이며, 실행 결과와 사용자 의도 모두에 기반한 복잡한 흐름 제어를 가능하게 한다. 단순해 보이는 conditional edge는 실제로는 전체 파이프라인 동작을 오케스트레이션하는 결정적 컴포넌트다.
6. Pipeline Integration Layer: UX와 아키텍처의 균형
LangGraph 파이프라인을 사용하는 가장 단순한 방법은 invoke 모드 — 초기 state를 제공하고 파이프라인 완료 후 최종 결과를 받는 방식 — 이다. 그러나 이 방식은 이상적이지 못한 사용자 경험을 야기한다. 사용자가 백엔드에서 무슨 일이 일어나는지에 대한 피드백 없이 오랜 시간 기다려야 할 수 있다.
LangGraph는 중간 단계를 가시화하는 stream 실행 모드를 제공하지만, 이 업데이트를 직접 관리하는 것은 애플리케이션 로직을 복잡하게 만든다. 이 트레이드오프를 해결하기 위해 별도의 interface layer가 도입된다.
Generator 기반 Event Stream 설계
Interface layer는 파이프라인 실행을 frontend가 쉽게 소비할 수 있는 well-defined event의 시리즈로 변환한다. Generator 함수는 이 작업에 매우 적합하다. 단순하고 선형적인 코드 흐름을 유지하면서 중간 결과를 산출할 수 있기 때문이다.
def process_question(question: str):
"""Generator yielding (response_type, payload, state) triplets"""
initial_state = {"question": question, "retry_count": 0}
for event in graph.stream(initial_state):
node_name, node_output = next(iter(event.items()))
current_state = node_output
# 1. Update event - 진행 상황 알림
yield ("update", f"실행 중: {node_name}", current_state)
# 2. Result event - 텍스트 출력
if "reasoning" in node_output:
yield ("result", node_output["reasoning"], current_state)
if "error" in node_output:
yield ("result", node_output["error"], current_state)
if "summary" in node_output:
yield ("result", node_output["summary"], current_state)
# 3. Visualization event - 구조화된 출력
if "query_result" in node_output:
yield ("visualization", node_output["query_result"], current_state)각 event는 일관된 구조를 따른다 — response type, response payload, 그리고 파이프라인의 현재 state를 담은 triplet이다.
| Event 종류 | 용도 | 예시 |
|---|---|---|
| Update | 파이프라인 진행 상황 | "Intent Detection 실행 중", "쿼리 생성 중" |
| Result | 텍스트 출력 | reasoning 단계, 에러 메시지, 생성된 summary |
| Visualization | 구조화된 출력 | 그래프, 지도, 차트, 테이블 |
각 event에 현재 파이프라인 state를 포함시킴으로써, frontend가 이 정보를 어떻게 사용할지에 대한 가정 없이 완전한 컨텍스트를 제공한다. 이 접근은 관심사의 깔끔한 분리를 유지한다. Interface layer는 파이프라인 실행을 well-defined event 스트림으로 변환하는 데 집중하고, 표현 결정은 frontend에 맡긴다.
7. Frontend: Streamlit 선택
운영 배포에서는 더 특화된 인터페이스가 정당화될 수 있지만, 시스템 개발과 데모 단계에서는 Streamlit이 적합한 선택이다.
| Streamlit 특성 | 시스템 요구사항과의 정합성 |
|---|---|
| Python-first | LangGraph 파이프라인과 동일 환경, 직렬화 불필요 |
| 빠른 반복 주기 | 다양한 질문 처리 방식의 신속한 검증 |
| 낮은 구현 오버헤드 | frontend 복잡성보다 expert-emulating 코어 정제에 집중 |
| Reactive UI | event stream과 자연스럽게 통합 |
Reactive UI Pattern: Temporary vs Permanent State
사용자 입력과 LangGraph 파이프라인 간 통합은 reactive 패턴을 사용한다. 이 패턴은 temporary state와 permanent state 모두를 관리한다는 점이 특징이다.
질문을 처리할 때 시스템은 즉각적인 피드백을 보여줘야 하면서, 동시에 영구적인 대화 이력도 유지해야 한다. 두 요구사항은 서로 다른 메커니즘으로 충족된다.
import streamlit as st
# Permanent state
if "message_history" not in st.session_state:
st.session_state.message_history = []
# 대화 이력 렌더링
for msg in st.session_state.message_history:
render_message(msg)
# 사용자 입력 처리
if user_question := st.chat_input("질문을 입력하세요"):
# Temporary placeholder - 실시간 업데이트
progress_area = st.empty()
final_state = None
for response_type, payload, state in process_question(user_question):
# Temporary 업데이트
progress_area.write(f"[{response_type}] {payload}")
final_state = state
# 처리 완료 후 permanent history에 추가
st.session_state.message_history.append({
"question": user_question,
"state": final_state
})
progress_area.empty() # placeholder 정리| 영역 | 메커니즘 | 역할 |
|---|---|---|
| Temporary placeholder | st.empty() | 파이프라인 처리 중 실시간 피드백 |
| Permanent history | st.session_state.message_history | 대화의 영구 기록 누적 |
이 접근은 사용자가 즉각적 피드백과 상호작용의 영구적 기록 양쪽 모두를 보장한다.
8. Transparency: 디버깅을 넘어선 가치
이 시스템의 history 영역의 실시간 업데이트는 이중 목적을 수행한다. 사용자에게 진행 상황을 알리는 동시에, expert-emulating 파이프라인의 추론 과정 자체를 가시화한다.
이 transparency는 사용자가 자연어 질문이 어떻게 해석되고 실행되는지를 이해하도록 돕는다. 그러나 그 가치는 단순히 디버깅에 국한되지 않는다. 각 컴포넌트의 의사결정 과정이 가시화되므로, 시스템이 무엇을 하는지뿐 아니라 왜 그렇게 하는지도 이해할 수 있다. 이것이 시스템 진화의 출발점이 된다.
9. Context-Aware Querying: 실전 적용
Schema Extraction 에이전트의 contextual awareness는 실제 사용에서 다음과 같은 자연스러운 인터랙션을 가능하게 한다.
- "the selected crime"처럼 시스템이 현재 선택에서 컨텍스트를 이해하는 직접 참조
- 선택된 요소에 대한 참조와 명시적 제약 조건(예: 차량 외관, 번호판)의 조합
- 사용자의 역할과 조사 의도를 제공하여 더 분석적인 인사이트로 시스템을 유도
이 단계에서 시스템은 단순한 기준 매칭을 넘어, 의심스러운 행동을 시사할 수 있는 시간적 패턴을 능동적으로 분석하는 단계로 진화한다.
10. 정리
이 챕터의 핵심은 14편에서 다룬 expert emulation 개념을 production-ready foundation으로 구현하는 것이다. 시스템의 가치는 무엇을 하는지에만 있는 것이 아니라, 어떻게 만들어졌는지에도 있다. foundation의 강점은 그 아래에 깔린 아키텍처, 특히 observability와 expert emulation에 대한 접근 방식에서 나온다.
LangGraph 기반 시스템의 설계 원칙은 세 가지로 압축된다.
- State-based communication: 직접 전달이 아닌 공유 상태를 통한 통신으로 modular하고 observable한 AI 파이프라인 구축
- Separation of concerns: configuration, schema, pipeline, frontend의 명확한 책임 분리
- Observability + Expert emulation: 투명성을 통한 자연스러운 시스템 진화
LangGraph의 state 기반 설계는 각 컴포넌트가 독립적 추론을 유지하는 modular, observable AI 파이프라인 생성을 가능하게 한다. Pipeline integration 아키텍처는 처리 업데이트의 실시간 스트리밍을 가능하게 하며, context-aware query generation은 schema 지식, 사용자 선택, 대화 이력을 결합한 자연스러운 인터랙션을 제공한다.
결론: 좋은 AI 시스템의 가치는 무엇을 하는지가 아니라 어떻게 진화할 수 있는지에 있다.
참고 자료
- Knowledge Graphs and LLMs in Action. Manning, 2024 — Chapter 15: Building a QA agent with LangGraph.
