1. NER만으로는 부족한 이유
이전 편에서 비정형 텍스트로부터 NER·RE 파이프라인을 통해 entity와 relation을 추출하는 과정을 다뤘다. 그러나 NER의 출력은 "어떤 문자열이 entity인가"까지만 답할 뿐, "그 문자열이 정확히 어느 entity를 가리키는가"는 답하지 못한다. 이 챕터의 thesis는 다음과 같다. NER은 mention을 식별하고, NED는 그 mention을 knowledge base의 정확한 entity에 연결하며, ontology integration은 그 연결을 KG의 분석 가능한 구조로 확장한다.
헬스케어 도메인의 IAS(intelligent advisory system) 시나리오를 예로 든다. "Zika"라는 mention이 텍스트에 등장했을 때, 이것이 바이러스를 가리키는지·질병을 가리키는지·지명을 가리키는지는 문맥에 의존한다. 도메인 전문가에게는 자명하나 문서 양이 늘어나면 수작업으로는 처리 불가능하다. NED는 이 모호성을 자동으로 제거하기 위해, 각 mention의 주변 문맥을 분석하고 reference knowledge base의 entity와 매핑하는 작업이다.
NER → NED → KG의 흐름은 단순한 후처리가 아니라, 비정형 텍스트를 ontology에 grounding하기 위한 필수 절차다. NER이 끝나는 지점에서 KG가 시작되는 것이 아니라, NED가 끼어들어야 비로소 KG가 의미 있는 구조를 갖는다.
2. NED 시스템의 3단계 아키텍처
NED 시스템은 일반적으로 세 phase로 구성된다.
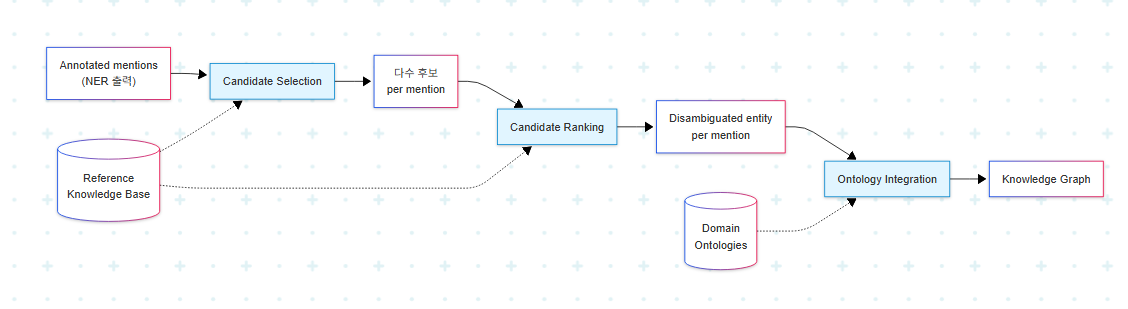
각 phase의 역할은 다음과 같다.
| Phase | 입력 | 출력 | 역할 |
|---|---|---|---|
| Candidate Selection | mention + reference KB | mention당 plausible entity 집합 | 가능한 후보를 추리는 단계. KB의 구조 정보를 활용해 정확한 식별을 가능하게 한다 |
| Candidate Ranking | 후보 집합 + 주변 문맥 | mention당 단일 target entity | 문맥(주변 단어) 기반으로 후보에 score를 부여하고 최고점 entity를 선택 |
| Ontology Integration | disambiguated entity + 도메인 ontology | KG | 다중 ontology의 구조·문맥 정보를 단일 KG로 집계 |
이 3단계 분리가 중요한 이유는, 각 단계가 다른 종류의 신호에 의존하기 때문이다. Candidate selection은 KB의 표면형(surface form) 매칭에 가깝고, candidate ranking은 분산 표현·문맥 임베딩에 의존하며, ontology integration은 schema·hierarchy 같은 구조적 지식을 다룬다. 단일 모델에 압축하면 어느 신호도 충분히 활용되지 않는다.
3. UMLS·SNOMED와 ontology integration
헬스케어 도메인의 reference knowledge base로 UMLS(Unified Medical Language System)가 표준이다. UMLS는 다중 출처에서 수집된 terminology, classification, coding 표준을 제공하며, 서로 다른 source에서 출발해도 동일 entity로 수렴할 수 있게 하는 interoperable 시스템을 가능하게 한다.
UMLS 산하의 SNOMED는 가장 포괄적이고 다국어를 지원하는 clinical terminology 중 하나로, 450,000개 이상의 concept을 포함한다. 책의 schema에서 SNOMED는 두 가지 방식으로 KG에 통합된다.
SNOMED_IS_Arelationship을 통한 semantic type 전파: SNOMED의 계층 구조를 따라 상위 entity의 semantic type이 하위 entity로 propagate된다. 트리 traversal을 통해 명시적으로 type이 부여되지 않은 entity에도 의미 분류가 부여된다.SNOMED_RELATION의 단일화: SNOMED 내부의 다양한 relation 종류를 모두 하나의 relationship type으로 통일하고, 구체적 관계명은 type 속성에 저장한다. graph schema를 단순하게 유지하기 위한 설계 결정이다.
LLM과의 관계도 분명히 짚어야 한다. UMLS knowledge base는 ChatGPT 같은 generic LLM에 incorporate되어 있지 않다. 따라서 도메인 NED를 LLM 단독으로 해결하려는 시도는 한계가 명확하다. LLM은 scispaCy 같은 전통 도구의 modern alternative이지만, KG 기술과 결합되어야 비로소 도메인 가치를 더한다.
4. KG schema 설계: mention과 entity의 분리 보존
NED를 거친 결과를 KG에 어떻게 저장할지는 단순한 문제가 아니다. 책의 설계는 다음 원칙을 따른다.
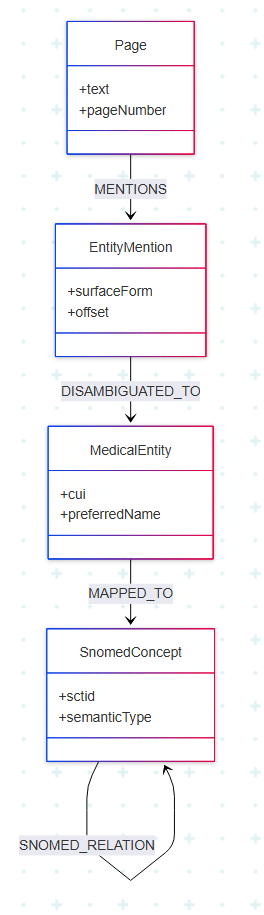
핵심은 EntityMention과 MedicalEntity를 모두 그래프에 보존한다는 점이다. DISAMBIGUATED_TO relationship을 통해 두 layer를 연결하면 다음과 같은 표현이 가능해진다.
- 동일 문자열의 mention이 문맥에 따라 다른 entity로 매핑되는 경우 (예: "PE" → physical examination / pulmonary embolism)
- 서로 다른 문자열의 mention이 동일 entity로 수렴하는 경우 (예: "pancreatic islets" / "islets of Langerhans" → 동일 MedicalEntity)
이 양방향 다대다 관계는 mention layer를 버리고 entity layer만 남기면 표현할 수 없다. flexibility를 위한 의도적 redundancy다.
5. Co-occurrence: 텍스트 기반 KG의 확장
Co-occurrence의 정의는 책에서 명료하다. "the projection of Page nodes onto Entity nodes." 같은 문장(또는 페이지) 내에 함께 등장한 medical entity 쌍을 직접 연결하는 relation이다.
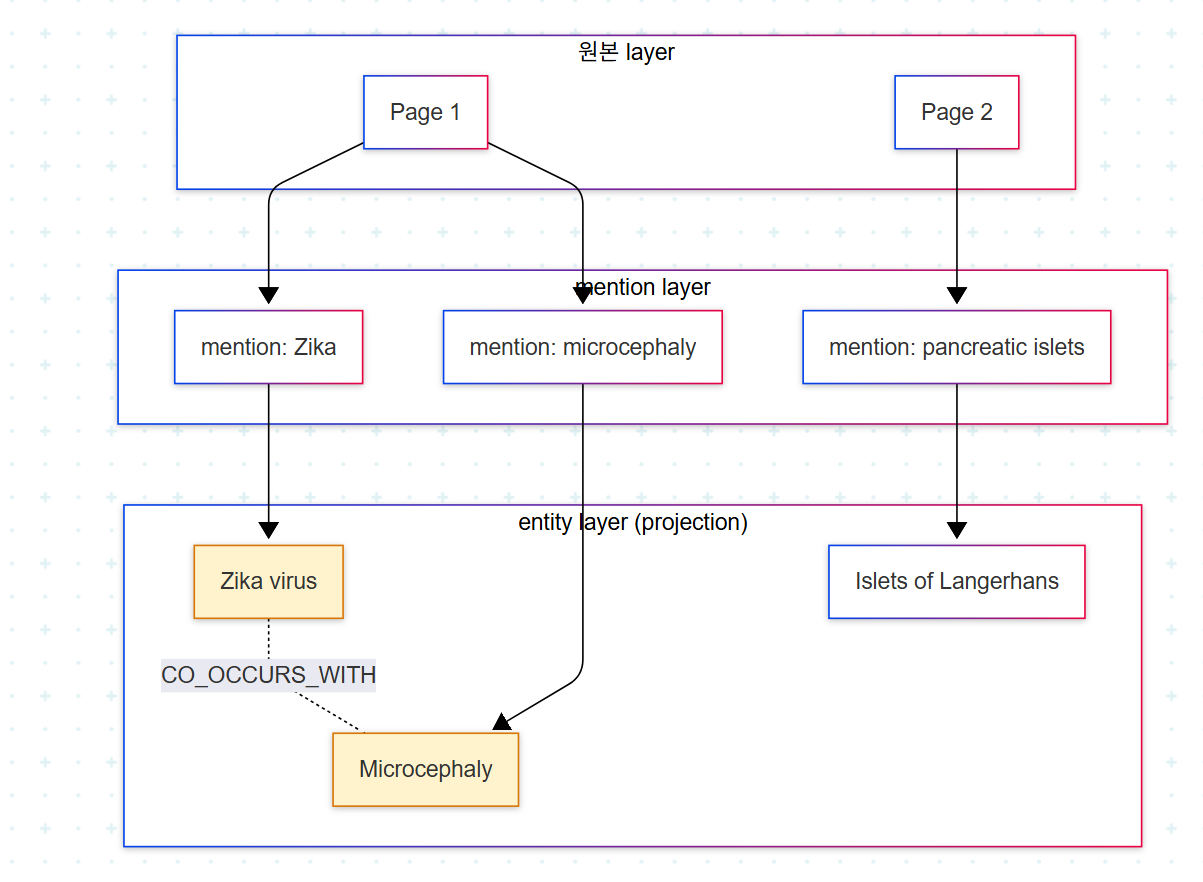
co-occurrence는 ontology에 등재되지 않은 관계도 데이터로부터 길어 올리는 장치다. 텍스트의 비정형 지식과 ontology의 구조적 지식을 잇는 다리 역할을 하며, 이 둘의 결합이 advanced use case의 토대가 된다.
6. KG 기반 분석: 네 가지 활용 사례
NED + ontology integration + co-occurrence가 결합된 KG 위에서 책은 네 가지 활용 사례를 제시한다.
| 사례 | 정의 | 핵심 메커니즘 |
|---|---|---|
| Conceptual search | 정확한 keyword가 아닌 의미 기반 검색 | ontology를 사용해 검색 공간을 확장한 뒤 문서 검색. full-text search가 표면형에서 끝나는 반면, conceptual search는 동의어·동치 표현을 흡수 |
| Structured knowledge-based search | ontology의 형식 지식으로 텍스트에서 정보를 retrieve | SNOMED 같은 ontology relationship을 따라 문맥적으로 연결된 정보 집계. 출발점과 직접 매칭되지 않는 정보도 ontology 경로를 통해 도달 |
| KG-based interpretability and discovery | ontology 경로가 텍스트의 "왜"를 설명(interpretability) 또는 텍스트가 말하지 않은 정보를 제공(discovery) | co-occurrence + ontology path 결합 분석 |
| Uncovering new knowledge | ontology에 아직 등재되지 않은 사실을 KG에서 발견 | co-occurring entity 사이에 ontology 경로가 부재한 경우, 새로운 도메인 지식의 후보로 식별 |
interpretability와 discovery의 구분이 미묘하지만 중요하다. 텍스트에 등장한 entity 쌍 사이에 ontology 경로가 존재하면, 그 경로가 "왜 이 둘이 함께 등장하는가"의 임상적·역학적 근거가 된다. 반대로 그 경로가 텍스트에 없는 추가 정보를 끌어오면 discovery가 된다. 동일한 ontology 경로가 어느 방향으로 사용되느냐의 문제다.
네 번째 사례인 uncovering new knowledge는 KG와 ontology의 관계를 역전시킨다. 통상은 ontology가 KG를 enrich하지만, 텍스트로 만든 KG가 ontology를 enrich할 수 있다는 발상이다. 책은 이를 virtuous circle로 부른다.
7. 허브 노드 문제와 GDS 기반 필터링
ontology 경로를 따라 entity 쌍의 관계를 추론할 때 실무적으로 가장 자주 부딪히는 문제는 허브 노드(hub node)다. Infectious process (qualifier value)나 Inflammation 같은 노드는 수많은 다른 entity와 연결되어 있어, 거의 모든 entity 쌍 사이의 최단 경로에 끼어든다. 이 경로는 형식적으로는 valid하나 정보 가치는 낮다.
해결책은 두 갈래다.
- 허브 노드 필터링: degree가 일정 임계 이상인 노드를 경로 탐색에서 배제. Neo4j Graph Data Science(GDS) 라이브러리로 degree 계산 후 제외 set을 구성한다.
- 추출된 관계 기반 시작점 전환: co-occurrence라는 약한 연결 대신, 텍스트에서 추출한 구체적 관계를 출발점으로 삼으면 경로가 더 specific해지고 허브 의존이 줄어든다.
후자는 RE(relation extraction)의 결과를 NED와 결합하는 방향으로, 이 챕터의 파이프라인을 한 단계 더 정교화하는 확장점이다.
8. 한계와 트레이드오프
- Reference KB 의존성: NED의 정확도는 reference knowledge base의 coverage와 quality에 직접 비례한다. UMLS·SNOMED가 잘 정비된 헬스케어와 달리, 신생 도메인이나 multilingual·historical archive에서는 reference KB 자체가 빈약하거나 부재한다. 이 경우 candidate selection 단계에서 false negative가 폭증한다.
- Candidate ranking의 문맥 한계: ranking은 mention 주변 단어에 의존하나, 문서 내 멀리 떨어진 정보나 문서 외부 배경 지식이 결정적인 사례에서는 실패한다. 단락 단위 ranking과 문서 단위 ranking을 분리해 ensemble하는 보완이 필요하다.
- Co-occurrence의 noise: 같은 문장 내 등장이 곧 의미 있는 관계는 아니다. 부정문(negation), 가정문, 비교문에서의 co-occurrence는 잘못된 관계를 KG에 주입한다. 단순 projection이 아닌 syntactic dependency 기반 co-occurrence 정제가 요구된다.
- Hub node의 정의 자체의 임계값 문제: degree threshold를 어디에 두느냐는 도메인마다 다르고 ontology version에 따라 달라진다. 정적 임계값보다 percentile 기반·도메인 expert review 기반 정의가 안정적이다.
- Schema 단순화의 비용:
SNOMED_RELATION을 단일 type으로 통합하는 결정은 schema는 단순화하나, Cypher 쿼리에서 type property를 매번 필터링해야 하는 부담을 만든다. 빈번한 relation type별로는 별도 relationship으로 분리하는 하이브리드가 실무 성능에 유리한 경우가 많다.
9. 실무 적용 시 고려사항
NED 파이프라인을 실서비스에 적용할 때 다음 사항을 추가로 점검해야 한다.
ontology 버전 관리는 별도의 운영 이슈다. SNOMED·UMLS는 정기적으로 업데이트되며, 기존에 NED된 mention의 매핑이 새 버전에서 deprecate되거나 분할될 수 있다. KG schema에 ontology version 메타데이터를 entity property로 저장하고, 재처리(reprocessing) 트리거를 명시해야 한다.
LLM과 전통 NED의 역할 분담도 설계 단계에서 결정해야 한다. LLM은 candidate generation에서 zero-shot 능력을 발휘하지만, candidate ranking에서는 hallucination 위험이 크다. ranking 단계만큼은 KB-grounded score(예: TF-IDF, embedding similarity, ontology path-based score)에 무게를 두고, LLM은 final tie-breaking이나 explanation 생성에 한정하는 것이 안전하다.
10. 정리
NED는 NER이 끝나는 지점에서 시작되는 별개 task이며, candidate selection·candidate ranking·ontology integration의 3단계로 분해된다. EntityMention과 disambiguated entity를 layer로 분리해 보존하는 schema 설계, co-occurrence를 통한 텍스트-ontology 결합, 그리고 conceptual search에서 uncovering new knowledge에 이르는 네 가지 활용 사례가 이 챕터의 골격이다.
결론: NER이 mention을 식별한다면, NED는 mention을 knowledge에 연결하고, ontology integration은 그 연결을 분석 가능한 KG로 확장한다.
참고 자료
- Knowledge Graphs and LLMs in Action. Manning, 2024 —
Chapter 7: Named Entity Disambiguation.
