이 챕터의 thesis는 단순하다. LLM은 KG를 직접 생산하지 않는다. LLM은 KG를 만들기 위한 중간 산출물(metagraph)을 생산하고, 정규화·entity resolution을 거쳐야 비로소 KG가 된다.
이전 편까지 vector RAG와 graph RAG의 구조적 차이, 그리고 chunk 기반 검색의 한계를 다뤘다면, 이번 글은 그 graph RAG의 입력이 되는 KG를 비정형 텍스트로부터 어떻게 구축하는가에 대한 실제 파이프라인을 다룬다. 사례는 록펠러 재단(RAC) 프로젝트로, 1939년에 타이핑된 Warren Weaver의 다이어리 10,000여 페이지를 KG로 변환하는 작업이다.
1. 비정형 아카이브를 KG로 만들 때 마주치는 문제
KG 구축 파이프라인 설명에 앞서, 어떤 입력 조건에서 어떤 어려움이 발생하는지 먼저 정의한다. 이 문제들이 이후 등장하는 3-layer 설계와 entity resolution 전략의 동기다.
| 문제 유형 | 내용 | 함의 |
|---|---|---|
| Analog 문서 | OCR 처리 필요 (Tesseract, Amazon, Microsoft 등) | OCR 오류로 인한 entity 표기 변형이 entity resolution 부담을 가중 |
| Historical 문서 | 더 이상 연구되지 않는 분야가 다수 → 참조용 NER dictionary/knowledge base 부재 | WikiData 등 외부 disambiguation 기반 약함 |
| 비표준 표기 | "S." for "J. R. Smith", "U.Cal." for "University of California" 같은 축약 | off-the-shelf coreference 모델 실패. LLM이 implicit하게 NER+RE+resolution 수행 가능 |
| Domain-specific entity | 자연과학 분야의 연구 disciplines, treatments, diseases 등 — granularity가 제각각 | 전통 NER 모델 부재. custom ML 기반 NER + unsupervised entity resolution 필요 |
| 높은 relational complexity | 한 페이지에 수십 개 relation 등장 | RE schema 설계가 정확도와 직결 |
| 다중 source 매칭 | diary와 board minutes를 하나의 KG로 연결 시 추가 정규화 | 본 챕터 범위 밖 |
여기서 핵심 통찰은 "LLM era 이전이라면 traditional ML 모델 구축에 막대한 자원이 들었을 작업이, 적절한 knowledge representation + LLM + prompt engineering 조합으로 해결 가능해졌다"는 점이다.
2. 3-Layer Graph 설계
문서를 KG로 직접 변환하는 single-shot 접근은 실패한다. 중간 표현이 필요하고, 책은 이를 세 layer로 분리한다.
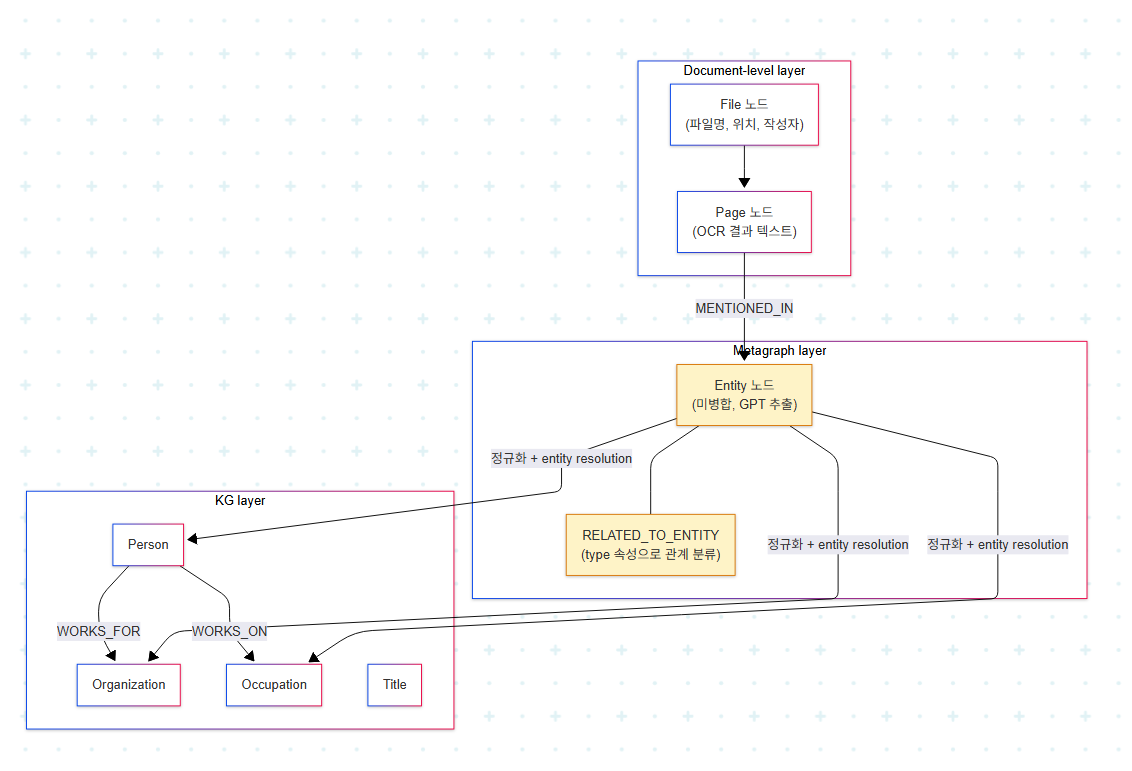
이 설계의 핵심은 metagraph layer를 중간 단계로 두는 것이다. LLM이 추출한 entity를 곧바로 최종 노드로 merge하지 않고, 일단 페이지에 link된 mention 단위로 저장한다. 이 구조가 주는 이점은 다음과 같다.
- 각 entity mention의 출처 페이지를 보존한다. 시각화 플랫폼에서 "이 entity는 어디서 추출되었는가"를 즉시 보여줄 수 있어 explainability가 자연스럽게 확보된다.
- entity resolution 로직을 수정하면 metagraph로부터 KG layer를 언제든 재생성할 수 있다. resolution 알고리즘은 한 번에 완성되지 않으며, 시행착오가 필수적이다.
- 페이지 간 분산된 entity 정보를 aggregate하면서도 원본 정보 손실이 없다.
3. Normalization과 Cleansing
metagraph가 만들어지면 통계 분석으로 연결성 향상 기회를 찾는다. 대표적인 정규화 작업은 다음과 같다.
- lowercasing: Occupation처럼 case가 의미 없는 entity는 소문자로 통일하면 동일 개념의 분산 저장을 막을 수 있다.
- token stripping: GPT는 prompt에서 분리하라고 지시해도 종종 person name에 title을 포함시킨다 ("Dr. Eleanor Smith"). title을 제거하지 않으면 동일 인물이 KG에 두 번 등장한다.
핵심은 정규화 결과를 원본 name 속성을 덮어쓰지 않고 name_normalized라는 새 속성에 저장한다는 것이다. 원본은 trace 용으로 유지되고, KG layer에 link할 때만 정규화된 값을 쓴다.
// title 제거 예시 (의사코드 수준)
MATCH (e:Entity)
WHERE e.name STARTS WITH "Dr. " OR e.name STARTS WITH "Prof. "
SET e.name_normalized = trim(replace(replace(e.name, "Dr. ", ""), "Prof. ", ""))
// case 정규화
MATCH (e:Entity {class: "Occupation"})
SET e.name_normalized = toLower(e.name)4. Entity Resolution: 같은 사람을 같은 노드로
Generative LLM은 traditional NER/RE 모델과 달리 prompt가 잘 설계되었다면 entity의 full clean form만 반환한다. 이는 implicit coreference resolution이 일어난다는 뜻이고, 후처리로서의 entity resolution 부담을 줄인다. 그러나 줄인다는 것이지 없앤다는 것이 아니다. 문서 간 resolution은 여전히 별도 작업이다. 한 다이어리에서 "Eleanor Smith"가 다른 다이어리의 "E. Smith"와 같은 사람인지를 판정해야 한다.
4.1 String similarity만으로 부족하다
이름 문자열이 비슷하다는 것만으로는 신뢰도가 낮다. 사람 이름은 first / middle / surname 구조를 갖고, middle name은 축약되거나 생략된다. surname만 같으면 false positive가 폭증하고, surname + first name 일부 조합 정도에서 신뢰도가 생긴다. 또한 도메인 stopword 처리가 중요하다. 많은 재단 명칭에 "Foundation"이 포함되어 있는데, 이를 무시하지 않으면 무관한 organization들이 모조리 SIMILAR로 묶인다.
4.2 관계 그래프를 entity resolution에 활용한다
여기가 graph 기반 접근의 진가다. metagraph의 mention들은 이미 다른 mention들과 관계로 연결되어 있고, 이 관계 자체가 resolution 신호가 된다.
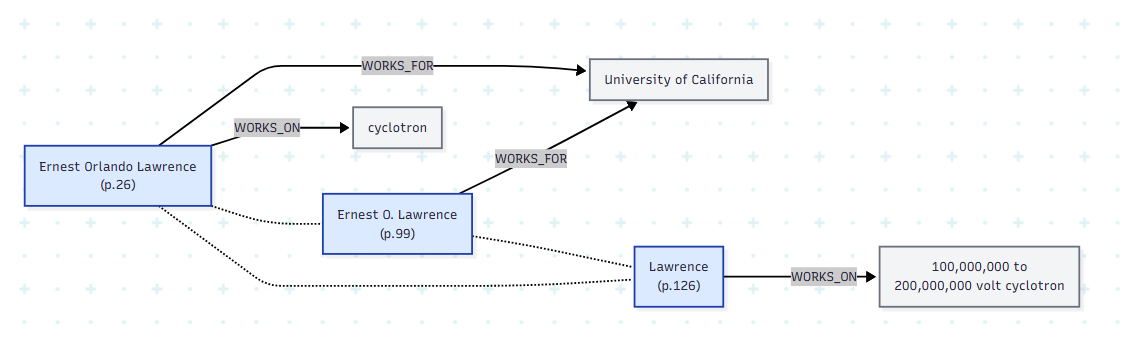
세 mention이 같은 인물(노벨 물리학상 수상자 Ernest Lawrence)이라는 판정 근거는 다음 신호의 결합이다.
- 이름 문자열 유사도 (rule 기반)
- 동일 organization (
WORKS_FOR→ University of California) 공유 → 3-hop 거리 - 의미적으로 연관된 occupation (
cyclotron↔100,000,000 to 200,000,000 volt cyclotron) 공유
특히 "Ernest Orlando Lawrence"와 단독 "Lawrence"는 6-hop 거리에 있다. 관계형 DB라면 이런 traversal은 매우 비싸지만, graph DB에서는 자연스러운 query다.
4.3 알고리즘 단계
resolution 파이프라인은 다음과 같다.

추가 옵션으로 다음이 거론된다.
- Community detection (Louvain 등): TALKED_ABOUT, TALKED_WITH 같은 intellectual network에 community detection을 적용하면, 동명이인을 분리할 수 있다. 남극에서 해양 연구를 하는 John Doe와 cosmology를 연구하는 John Doe는 다른 community에 속할 가능성이 높다.
- Embedding 기반 의미적 유사도: 문자열이 전혀 닮지 않았지만 개념적으로 가까운 occupation들 (
fertility와human ovulation)은 GPT embedding으로 vector화 후 agglomerative clustering으로 묶을 수 있다. 이 부분은 vector approach와 graph approach가 만나는 지점이다.
5. 완성된 KG로 무엇을 하는가: 지적 네트워크 분석
KG는 만드는 것 자체가 목적이 아니다. 주된 용도는 graph analytics다. 책에서 RAC 프로젝트가 보여주는 분석은 "과학자들의 지적 네트워크"를 추출하는 것이다. TALKED_ABOUT, TALKED_WITH, WORKS_WITH, STUDENT_OF 같은 관계로 구성된 subgraph에 Neo4j Graph Data Science library의 알고리즘을 적용한다.
| 분석 목표 | 알고리즘 | 해석 |
|---|---|---|
| Influencers | PageRank, out-degree | 다른 사람의 연구를 추천하는 빈도가 높은 인물 |
| Influencees | in-degree, eigenvector centrality | 추천·언급의 주된 대상 |
| Bridges | Betweenness centrality | 분리된 community를 잇는 연결자 |
betweenness centrality 시각화에서는 노드 크기가 통과하는 최단경로 수에 비례한다. 이 시각화에서 Niels Bohr나 Ernest Lawrence처럼 유명한 과학자가 부각되는 것은 예상대로지만, 덜 알려진 인물도 함께 드러난다. 이 "덜 알려진 bridge"가 도메인 분석가에게 새로운 가설의 출발점이 된다.
KG는 또한 더 좁은 질문에도 답한다. "cyclotron 연구와 그 펀딩에 핵심 역할을 한 사람은 누구인가" 같은 질문은 cyclotron을 연구한 인물에서 시작해 최대 2-hop 거리에 있는 인물로 path를 확장하면서 referral 패턴을 추적하는 query로 표현된다.
실용 시나리오 하나는 다음과 같다. project officer Warren Weaver가 자리를 떠나 후임이 들어온다. 후임은 Johns Hopkins와 Harvard 양쪽에 physics 도메인 연결이 있는 인물에게 비공식 자문을 받고 싶다. 이 질문은 KG의 영향력 네트워크에서 직접 답이 나온다. 게다가 TALKED_ABOUT relation에 sentiment 속성이 있다면, "Bernal은 Dorothy Wrinch에 부정적 태도를 보인다, Irving Langmuir는 Bernal에 부정적 태도를 보인다"처럼 정성적 정보까지 활용한 균형 잡힌 인터뷰 대상자 선정이 가능하다.
6. 한계와 트레이드오프
LLM 기반 KG 구축은 마술이 아니다. 책 본문에서 명시적으로 또는 암묵적으로 드러나는 한계는 다음과 같다.
1) RE 실패의 silent propagation. 책의 사례에서 어떤 인물이 cyclotron subgraph에 잘못 등장한 사건이 보고된다. 이는 LLM의 RE 단계 오류이며, 다운스트림 분석 결과를 오염시킨다. 분석가가 graph 내용을 검증·반려할 수 있는 feedback loop가 application에 내장되지 않으면, 잘못된 entity가 의사결정에 영향을 미친다.
2) Entity resolution은 보수적일수록 유실, 공격적일수록 오염된다. Irving Langmuir가 두 노드(Langmuir와 Irving Langmuir)로 남은 사례는 책에 직접 등장한다. 한 페이지에서 surname만 등장하면서 다른 어떤 관계도 함께 추출되지 않으면 resolution에 사용할 신호가 없어 두 mention이 분리된 채로 KG에 들어간다. resolution rule을 더 공격적으로 풀면 동명이인 false merge가 발생한다. 이 trade-off는 알고리즘 튜닝만으로 해소되지 않는다.
3) Token limit과 multi-page 처리. LLM은 한 번에 처리할 수 있는 입력·출력 토큰이 제한된다. 다이어리가 수백 페이지일 때 단순 chunking은 entry 경계를 무시하고, 그러면 entity 간 관계가 끊긴다. RAC 프로젝트는 ChatGPT-3.5-Turbo로 entry boundary detection을 별도 단계로 두는 식으로 우회했지만, 이는 추가 LLM 호출 비용과 또 다른 오류 표면을 만든다.
4) Schema 설계는 사후 변경 비용이 크다. RE schema가 너무 좁으면 유용한 관계를 놓치고, 너무 넓으면 noise가 KG를 채운다. metagraph layer 덕분에 KG layer는 재생성 가능하지만, schema 변경은 LLM 추출 단계까지 거슬러 올라가야 한다.
7. 실무 적용 고려사항
위 한계를 인지한 상태에서 production-quality KG 시스템을 구축할 때, 책이 제시하는 next steps는 다음과 같이 압축된다.
- Knowledge extraction 정확도 향상: prompt engineering 추가 iteration 또는 LLM fine-tuning. 어느 시점부터는 prompt 튜닝의 한계가 분명해지므로, 도메인 데이터로 fine-tuning이 비용 대비 효과가 더 클 수 있다.
- 외부 knowledge base 연동: WikiData 등을 활용한 entity disambiguation은 historical 도메인이 아닌 현대 도메인에서 baseline resolution을 강력하게 끌어올린다.
- Occupation entity의 hierarchical resolution:
nuclear physics⊃isotopes⊃heavy nitrogen같은 granularity 차이를 단순 cluster로 처리하지 않고, embedding (SentenceBERT, GPT) + agglomerative hierarchical clustering으로 계층을 보존한다. 이렇게 해야 "주제의 전체 역사"를 query할 수 있다. - Conversation 노드 도입: date, interviewer, interviewee, topic을 갖는 Conversation 노드를 만들면 follow-up chain 분석과 grant 연결이 가능해진다.
- Cross-source 통합: 다이어리(diaries)와 이사회 의사록(board of directors minutes)을 같은 KG에 통합하면 "어떤 conversation이 어떤 grant로 이어졌는가" 같은 질문에 답할 수 있다.
8. 왜 LLM에 직접 묻지 않고 KG를 만드는가
이 챕터의 마지막 질문은 사실 시리즈 전체의 thesis를 압축한다. 답은 다섯 가지로 정리된다.
| 가치 | 의미 |
|---|---|
| Explainability | KG는 응답의 근거가 되는 노드·관계·원본 텍스트를 모두 추적 가능하게 한다. LLM 단독 응답은 "왜 이 답인가"를 답하지 못한다. |
| Demystification | LLM을 black box로 사용하지 않고, 정보 추출 단계에서만 LLM의 언어 이해 능력을 빌린다. 결과물(KG)은 검증 가능한 정형 데이터다. |
| Democratization | LLM 학습·fine-tuning은 비싸다. 한 번 LLM을 써서 KG를 만들고 이후엔 KG만 운용하는 방식은 비용을 분산시킨다. |
| Explorability | Graph 시각화는 사용자가 데이터를 새로운 각도에서 탐색·드릴다운하게 한다. 가설 생성 도구로 기능한다. |
| Advanced analytics | PageRank, community detection, centrality 등 graph algorithm은 LLM의 black box reasoning에 의존하지 않는 분석 경로를 제공한다. |
결론: LLM은 KG의 직접 생산자가 아니라 raw text에서 entity와 relation을 뽑는 추출기이며, KG의 가치는 추출 이후의 정규화·resolution·graph analytics 단계에서 결정된다.
참고 자료
- Knowledge Graphs and LLMs in Action. Manning, 2024 —
Chapter 6: Building knowledge graphs with large language models
