
1. 두 패러다임의 출발점
RAG(Retrieval-Augmented Generation)는 외부 지식을 LLM에 주입해 hallucination을 줄이는 기법이다. 그러나 "외부 지식을 어떻게 표현하고 검색하는가"에 따라 두 갈래로 나뉜다.
- Vector RAG: 텍스트를 chunk로 쪼개 embedding한 뒤 의미 유사성으로 검색
- Graph RAG: 텍스트에서 entity와 relationship을 추출해 knowledge graph로 구성한 뒤 관계망을 따라 검색
질문의 성격이 검색 방식을 결정한다. "비슷한 문서 찾기"는 vector, "관계 따라 추론하기"는 graph다.
| 구분 | Vector RAG | Graph RAG |
|---|---|---|
| 검색 단위 | chunk | entity, subgraph, path |
| 유사도 척도 | cosine similarity | traversal, pattern matching |
| 인덱스 | ANN (FAISS 등) | property graph, RDF |
| 강점 영역 | local retrieval | global sensemaking |
| 표현 한계 | 관계가 암묵적 | 구조화 비용 높음 |
2. Vector RAG: 평면 표현의 강점과 한계
2.1 동작 구조
표준 파이프라인은 다음과 같다.
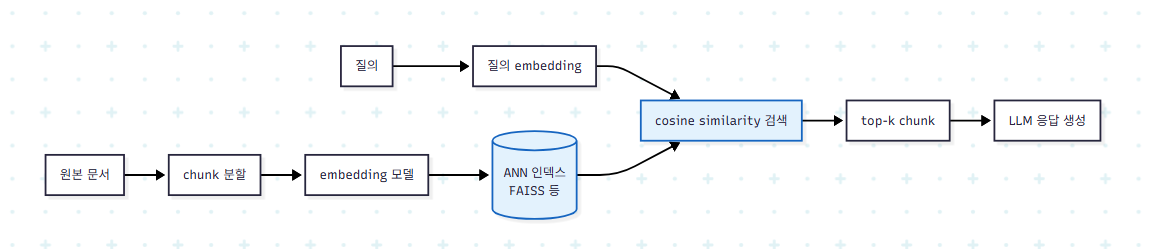
ANN 인덱스 위에서 단일 단위인 chunk를 빠르게 돌려주는 단순한 구조다. 긴 문서 하나를 통째로 embedding하면 여러 주제가 섞여 정보성이 희석되므로, 작게 쪼개야 의미 포착이 살아난다.
2.2 강점이 드러나는 영역
Vector RAG가 잘 작동하는 자리는 명확하다.
- 문서 QA: long-form 문서에서 답이 있는 문단 찾기
- Technical support: Jira, Slack, 콜센터 로그 검색
- 사내 문서·FAQ: 근무 규정, 온보딩, 제품 매뉴얼
- Code/doc search: 함수명·설명·주석을 넘나드는 검색
2.3 한계가 드러나는 지점
Vector RAG는 본질적으로 평면 표현이다. chunk A와 B의 관계, entity 간 참여·소유·계층, 시간적 선후 관계는 embedding 안에 암묵적으로만 들어간다. 질문이 "비슷한 문서 찾기"에서 "관계 따라 추론하기"로 바뀌는 순간 이 한계가 표면화된다.
3. Graph RAG: 개체와 관계의 저장소
3.1 핵심 발상
Graph RAG는 문서가 아니라 개체와 관계를 저장한다. unstructured 텍스트에서 entity와 relationship을 추출해 knowledge graph 또는 property graph로 구성하는 방식이다.
Microsoft GraphRAG의 사례에서, source document로부터 entity graph를 만든 뒤 인접 entity group에 대해 community summary를 미리 생성하고, query 시점에 partial response를 합성한다. "데이터셋 전체의 주요 테마는 무엇인가"와 같은 global question에서 naive RAG 대비 comprehensiveness와 diversity가 개선된다고 보고되었다.
3.2 구축·검색 파이프라인
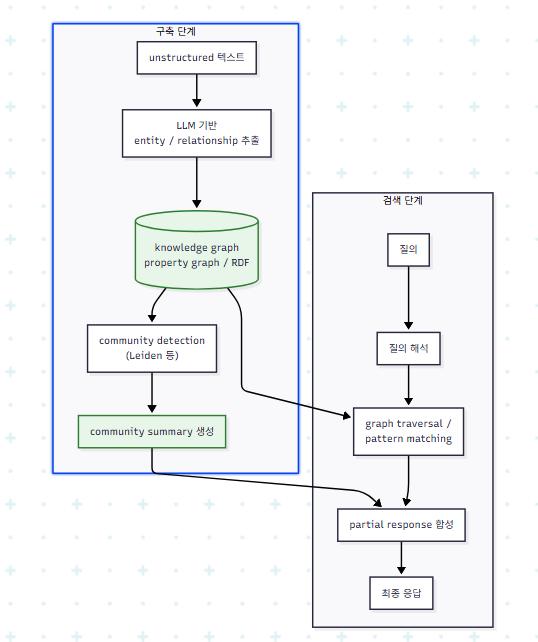
검색 대상이 chunk 한 단위가 아니라 구조 전체라는 점이 vector RAG와의 결정적 차이다.
4. 네 가지 Graph 패턴
"Graph RAG"라는 이름 안에는 최소 네 가지 서로 다른 graph 구성 방식이 존재한다. 답해야 할 질문 유형에 따라 선택이 달라진다.
| 패턴 | 노드 구성 | 적합 시나리오 |
|---|---|---|
| Lexical Graph | Document → Chunk | 가장 기본 형태. Basic Retriever |
| Hierarchical Lexical Graph | + Chapter / Section / Subsection | 문서 자체 구조 계승. bottom-up·top-down |
| Domain Graph | Entity ↔ Entity | 실세계 비즈니스 지식 (Movie graph 등) |
| Lexical + Entities + Communities | Chunk · Entity · Community | Global/Local Retriever 기반 |
4.1 Lexical Graph
가장 단순한 형태다. Document 노드는 문서명·출처를 갖고, Chunk 노드는 human-readable text와 vector embedding을 가지며, 두 노드는 PART_OF 관계로 연결된다. 질문 embedding과 chunk embedding 간 vector similarity로 top-k를 찾는 Basic Retriever의 그래프 기반이 된다.
4.2 Hierarchical Lexical Graph
문서 구조를 그대로 계승한다. HAS_CHAPTER, HAS_SECTION, HAS_SUBSECTION, PART_OF 등의 edge로 계층을 구성한다. 두 가지 retrieval 모드가 가능하다.
- Bottom-up: leaf에서 similarity search 후 상위 chunk로 확장
- Top-down: 상위 노드에서 subtree 선택 후 좁혀가며 탐색
4.3 Domain Graph
실세계 entity와 그 사이 관계를 담는 그래프다. Movie graph, Northwind schema가 대표적이다. 도메인마다 모양이 다르기 때문에 일반 blueprint를 제공하기 어렵지만, schema에 따르는 structured data라는 공통점을 갖는다. 자연어 질문이 deterministic한 구조적 조회로 풀릴 때 유용하며, Text2Cypher나 Pattern Matching의 기반이 된다.
4.4 Lexical + Entities + Communities
세 층의 그래프를 결합한 가장 풍부한 형태다.
- Chunk에서 entity와 relationship 추출
- Domain Graph 위에서 Leiden 알고리즘으로 계층 커뮤니티 형성
- 각 커뮤니티에 대해 LLM이 community summary 생성
Community 노드는 level, name, summary, weight 속성을 갖는다. "데이터셋 전체 테마는 무엇인가"와 같은 global 질문에서 특히 강하다.
5. KG와 LLM의 상호 보완
책에서는 두 기술의 결합을 단순한 조합이 아닌 패러다임 전환으로 본다. KG는 명시적·검증 가능·갱신 가능한 지식 표현을 제공하고, LLM은 자연어 이해·생성 능력을 제공한다.
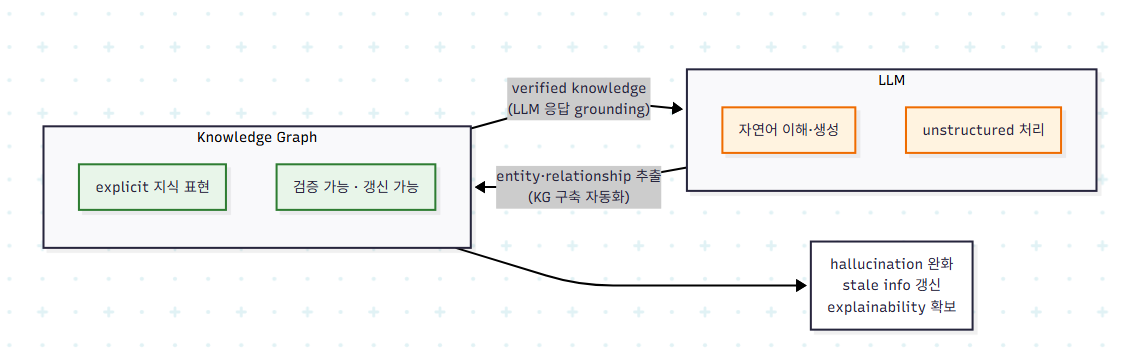
LLM은 unstructured 텍스트에서 entity와 relationship을 추출해 KG 구축을 자동화하고, KG는 신뢰할 수 있는 도메인 지식으로 LLM 응답을 grounding한다. 구체적으로는 다음 세 문제를 해결한다.
- Hallucination: KG의 verified knowledge가 사실 기반을 제공한다. text-to-cypher 변환은 자연어 질문을 정확한 graph query로 바꿔 신뢰 가능한 정보를 직접 추출한다.
- Stale information: LLM은 상시 재학습이 어렵지만 KG는 지속 갱신이 가능하다. GraphRAG는 community summary를 통해 최신 정보를 LLM에 주입한다.
- Explainability: KG는 추론 경로를 추적·검증 가능하게 만든다. LLM의 자연어 처리와 결합되어 결과가 사람이 읽을 수 있는 형태로 정리된다.
6. KG의 네 기둥
KG를 다음과 같이 정의할 수 있다. Knowledge graph는 typed entity, 속성, 의미 있는 named relationship으로 구성된 지속적으로 진화하는 graph data structure이며, 특정 도메인을 위해 structured·unstructured 데이터를 통합한다. 이 정의는 네 가지 축으로 정리된다.
| 기둥 | 의미 |
|---|---|
| Evolution | 새 정보를 단일 출처로 지속 통합. 전면 개편 없이 확장 가능 |
| Semantics | typed entity와 relationship으로 의미를 명시. explainability의 기반 |
| Integration | structured/unstructured, 다중 소스의 중앙 참조점 |
| Learning | centrality, network analysis, community detection으로 새 지식 추론 |
7. 한계와 주의사항
Graph RAG가 만능은 아니다. 다음 난제가 존재한다.
- Graph construction의 품질·비용 trade-off: LLM 기반 추출은 recall이 높지만 hallucinated edge를 만든다. rule-based는 precision이 좋지만 recall이 낮다. ontology를 정교하게 설계할수록 비싸고, 느슨할수록 결과가 지저분해진다.
- 튜닝 포인트의 차이: vector RAG가 chunk 크기·embedding 모델 중심이라면, graph RAG는 ontology, entity canonicalization, relation type 설계, source provenance, graph update 전략, confidence score, temporal validity 등 지식 모델링의 축을 다뤄야 한다.
- 평가 지표의 부재: "정답 맞췄나"만 측정하면 graph RAG의 가치를 제대로 보지 못한다. global sensemaking, explainability, multi-hop reasoning을 평가할 별도 지표가 필요하다.
- KG 자체의 채택 장벽: 책은 KG가 널리 보급되지 못한 이유로 구축·유지비용, 다중 hop을 요구하는 복잡한 access pattern, 다수 노드·관계에 분산된 결과를 든다.
결론: Vector RAG는 의미 유사성에 강하고 Graph RAG는 관계 추론에 강하다. 둘은 선택의 문제가 아니라 조합의 문제이며, KG와 LLM의 결합은 hallucination·stale information·explainability라는 LLM의 구조적 한계를 보완하는 패러다임 전환이다.
참고 자료
- Knowledge Graphs and LLMs in Action, Chapter 1: Knowledge graphs and LLMs: A killer combination
