vector RAG는 의미가 비슷한 chunk를 모아오고, graph RAG는 관계를 따라 추론한다. 두 retrieval은 서로 다른 질문에 답한다.
1. AI Agent와 LLM의 한계
LLM 기반 챗봇은 단순 질의응답을 넘어 AI agent 형태로 진화하고 있다. AI agent는 환경과 상호작용하면서 자율적으로 판단·행동하는 시스템으로 정의된다. 사전에 정해진 명령만 따르는 전통적 프로그램과 달리, agent는 사용 가능한 tool을 스스로 선택하고 결과를 평가해 다음 행동을 결정한다.
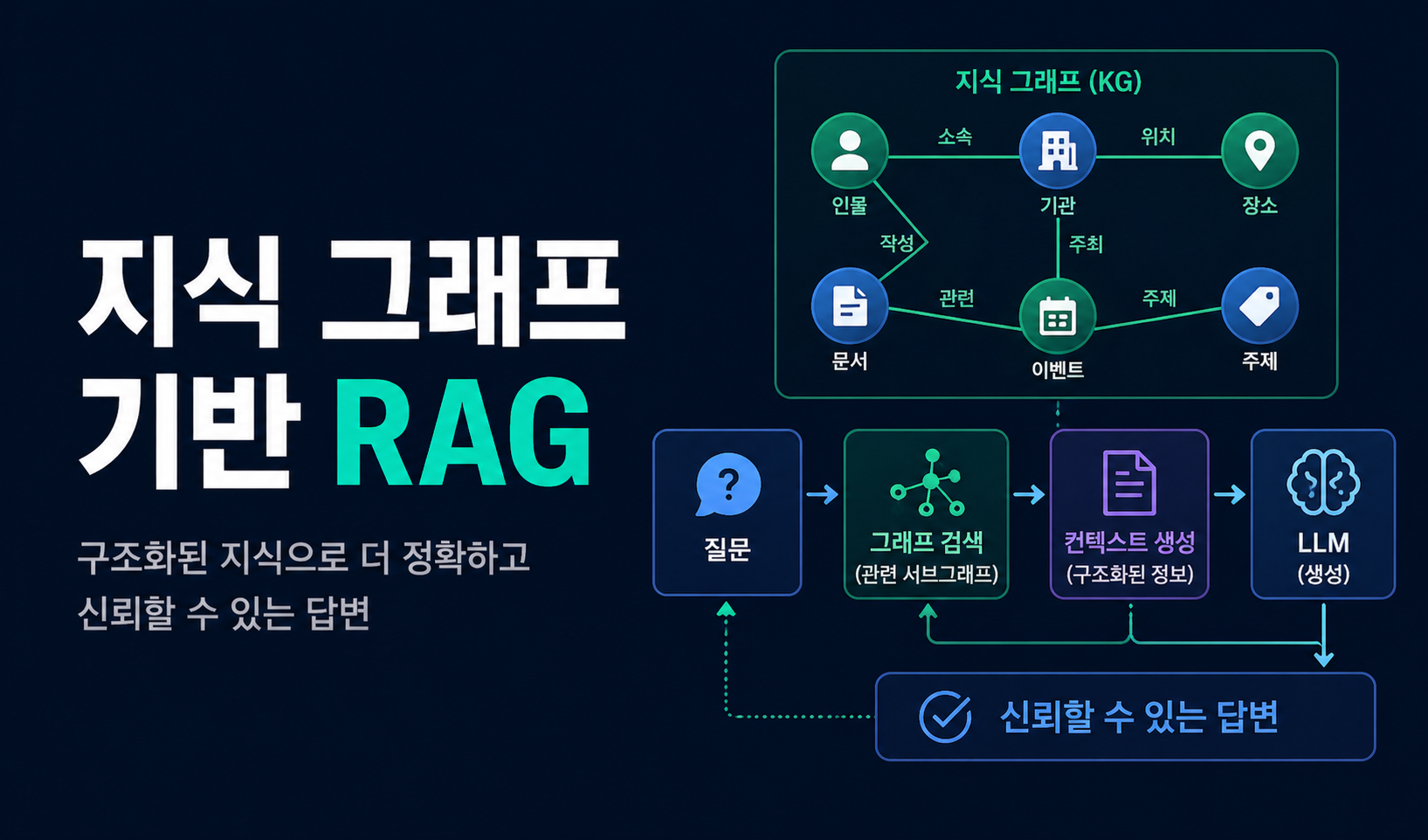
이전 편들에서 다룬 내용 — 비정형 문서로부터 entity·relationship을 추출해 KG로 모델링하는 과정 — 은 결국 이 agent가 활용할 외부 지식 소스를 만드는 작업이다. 본 편은 그렇게 구축된 KG를 retrieval 백엔드로 사용하는 RAG 구조를 다룬다.
production 환경에서 LLM 단독 사용이 어려운 이유는 다음과 같이 정리된다.
| 문제 | 정의 | 영향 |
|---|---|---|
| Hallucination | 학습되지 않은 주제에 대해 그럴듯한 거짓을 생성 | 신뢰도 저하 |
| Freshness (knowledge cutoff) | 재학습 주기가 길어 최신 정보 반영 불가 | 정보 정확성 저하 |
| Transparency | 답변의 근거·추론 과정을 추적 불가 | 엔터프라이즈 도입 장벽 |
| Data privacy | 민감한 사내 데이터 학습 시 유출 위험 | 컴플라이언스 위반 |
| Cost | 대규모 모델의 학습·운영 비용 | 접근성 제약 |
| Bias | 학습 데이터의 편향이 출력에 재생산 | 윤리적 리스크 |
LLM은 본질적으로 다음 token의 확률을 예측하는 모델이다. 학습 분포를 벗어난 질문에도 모델은 "가장 그럴듯한 출력"을 생성하므로, 응답이 틀려도 표면적으로는 일관되게 보인다. RAG는 이 구조적 한계를 외부 context 주입으로 보완하기 위한 접근이다.
2. Vector RAG의 동작과 한계
RAG는 사전학습된 LLM의 언어 이해력에 외부 데이터로부터 retrieval한 context를 결합하는 grounding 기법이다. 초기 RAG 구현은 거의 전적으로 텍스트 문서를 chunk 단위로 쪼개고 embedding으로 변환해 vector database에 색인하는 방식이었다.
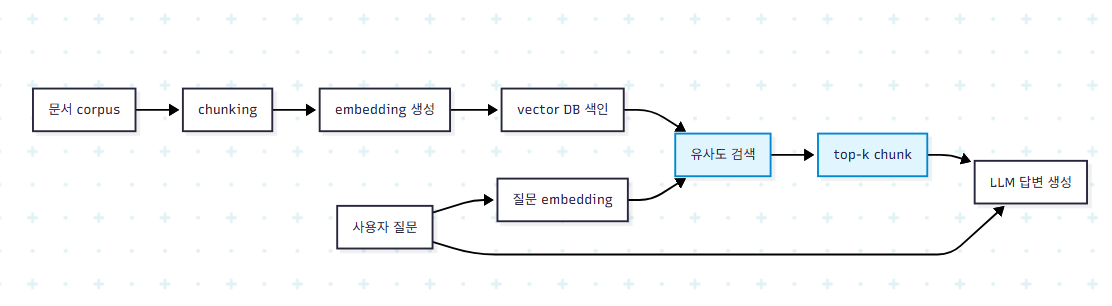
질문이 들어오면 동일한 embedding 모델로 질문을 vector로 변환하고, vector database에서 의미적으로 가장 가까운 chunk들을 retrieve한다. retrieved chunk들은 prompt context로 주입되어 LLM이 최종 답변을 생성한다. Neo4j는 graph 구조를 가진 데이터베이스이지만 Neo4jVector 같은 인터페이스를 통해 vector index도 제공한다.
# 문서 chunk를 embedding으로 변환하고 vector index 생성
vector_index = Neo4jVector.from_existing_graph(
embedding=OpenAIEmbeddings(),
url=NEO4J_URL,
username=NEO4J_USER,
password=NEO4J_PWD,
database=NEO4J_DB,
)이 구조는 단순하고 강력하지만 다음과 같은 한계를 가진다.
- Context fragmentation으로 인한 추론 제약: chunk 단위로 독립 retrieve되므로 여러 문서·entity를 가로지르는 multi-hop 관계 추론이 어렵다. 정답에 필요한 정보가 두 chunk에 걸쳐 있고 그중 하나만 retrieve되면 답변은 부정확해진다.
- Scalability: corpus 규모가 커질수록 정확한 nearest neighbor search 비용이 급증해 approximate search로 후퇴할 수밖에 없다.
- Embedding의 표현 한계: 문서 전체 의미를 단일 dense vector로 압축하는 과정에서 fine-grained semantic·도메인 특화 뉘앙스가 손실된다. embedding 모델 학습 데이터에서 sparse하게 등장한 용어는 더 부정확하게 표현된다.
- Retrieval noise: vector similarity가 높지만 실제로는 무관한 문서가 섞여 LLM의 distraction을 유발한다. 긴 context에서는 noise 증가가 출력 품질을 악화시킨다.
- Retrieval miss: "이 데이터셋의 핵심 연구 주제는?" 같은 집계형 질문은 의미 유사도와 정답 적합도가 일치하지 않아 vector search 자체로는 답할 수 없다.
요약하면 vector RAG는 "의미적으로 비슷한 텍스트"를 잘 찾지만, "관계를 따라간 결과로서의 사실"을 답하는 데는 약하다.
3. Graph RAG: KG를 retrieval 백엔드로
위 한계의 해법으로 등장한 것이 Graph RAG이다. KG는 단순 텍스트가 아닌 entity·relationship과 메타데이터, 구조화된 데이터(table, ontology 등)를 한 곳에 통합한 central knowledge repository로 작동한다. 도메인 전문가가 직접 검증·수정할 수 있어 transparency가 높고, 사실의 추가·갱신이 쉬워 freshness 문제도 완화된다.
Graph RAG agent는 KG를 활용하는 방식에 따라 여러 retriever tool을 가진다.
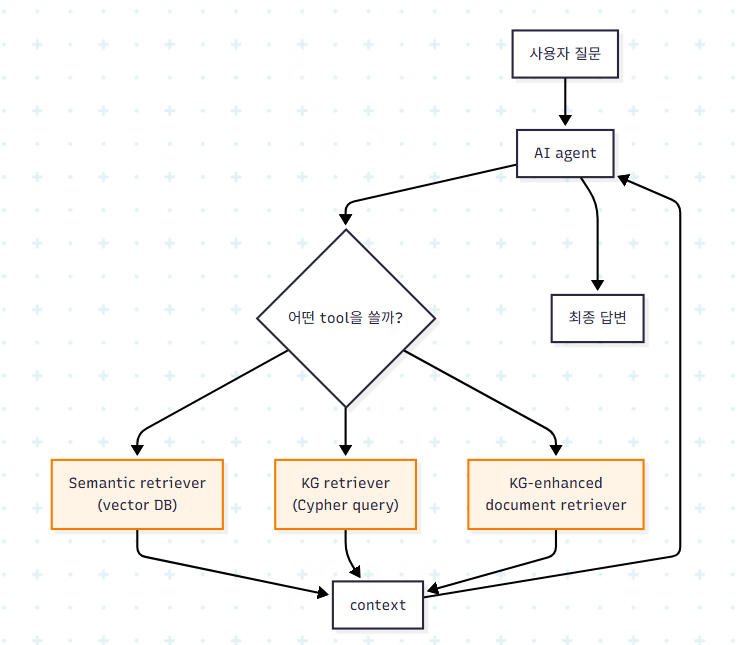
각 tool의 역할은 다음과 같이 구분된다.
| Tool 종류 | 입력 | 처리 | 적합한 질문 유형 |
|---|---|---|---|
| Semantic retriever | 자연어 질문 | embedding similarity | "X와 관련된 문서" |
| KG retriever | 자연어 질문 + KG schema | Cypher query 자동 생성, subgraph 반환 | "X와 Y의 관계", multi-hop |
| KG-enhanced document retriever | entity·relationship | KG로 후보 좁힌 후 문서 retrieve | "X를 언급한 문서만" |
| Combined retrieval | 복합 질문 | KG로 entity 식별 → 문서 검색 | 다중 소스 결합 질문 |
KG retriever는 사용자 질문과 KG schema를 LLM에 제공해 Cypher query를 생성하게 한다. 또는 질문에 등장한 entity들을 받아 그 사이의 shortest path subgraph를 반환하고, 어떤 부분을 답변에 사용할지는 LLM이 결정하게 한다.
KG-enhanced document retriever는 KG가 text-paired graph일 때 가능한 방식이다. node·relationship이 원본 문서까지 추적 가능하므로, "사용자가 언급한 모든 entity를 포함하는 문서만" 같은 정밀 필터링이 가능하다. vector search의 retrieval miss를 직접 해소한다.
Combined retrieval은 질문이 여러 소스에 걸칠 때 사용된다. 예를 들어 "범죄조직 X의 두목의 올해 거래 내역은?"이라는 질문은 법 집행 기관 KG에서 두목의 실명을 추출한 뒤, 그 이름으로 금융 문서 DB를 검색하는 두 단계로 분해된다.
4. Text-attributed graph와 Text-paired graph
Graph RAG의 retrieval 정밀도는 KG 설계에 직접적으로 좌우된다. 가장 유용한 설계는 두 종류의 graph 구조를 결합하는 형태이다.
- Text-attributed graph: node와 relationship이 텍스트 속성을 가진다. entity 자체에 description, type 등이 붙어 LLM이 직접 활용할 수 있다.
- Text-paired graph: node와 relationship이 출처 문서로 추적 가능하다. KG로 좁힌 결과를 문서 retrieval로 연결할 수 있다.
이 둘이 결합되면 정형화된 지식과 원문 문서를 함께 활용할 수 있어 metadata 기반 community 식별, 최신 버전 문서 우선 retrieval 등 다양한 전략이 가능해진다. 답변 예시로 "Harvard와 Johns Hopkins의 공통 연구 주제는?"이라는 질문에 KG의 university-topic 관계를 traversal 해 "astronomy, climatology"라는 정확한 사실을 반환할 수 있다.
5. 한계와 트레이드오프
Graph RAG가 vector RAG의 약점을 상쇄한다고 해서 만능은 아니다. 본 챕터의 개념에서 도출되는 한계는 다음과 같이 정리된다.
- KG 구축 비용이 선행 부담으로 전이된다: vector RAG는 chunking·embedding으로 인덱스가 빠르게 구축되지만, KG는 entity·relationship 추출과 ontology 설계에 사람의 손이 필요하다. retrieval 단계의 정확도를 얻는 대가로 ETL 비용이 앞단에 집중된다.
- Cypher query 생성 자체가 또 다른 hallucination 지점: KG retriever는 LLM이 schema를 보고 Cypher를 생성하게 한다. schema가 복잡하거나 질문이 모호하면 잘못된 query가 생성되어 빈 결과·오답으로 이어진다. retrieval의 정확성을 확보하려면 schema 설계 자체가 자기 설명적이어야 한다.
- Entity coverage의 함정: KG에 존재하지 않는 entity·관계는 graph traversal로는 절대 도달할 수 없다. text-paired graph가 없는 환경에서는 "KG에 없는 사실을 묻는 질문"이 silent failure를 일으킨다. 이 때문에 vector retriever와 fallback 구조가 여전히 필요하다.
- 확률적 모델의 한계는 잔존: RAG는 hallucination 확률을 낮출 뿐 제거하지 못한다. context가 정확해도 LLM은 여전히 가장 그럴듯한 token을 생성하는 모델이며, 시스템은 사람을 대체하기보다 augment하는 방향으로 설계되어야 한다. feedback·검증 루프 없이는 production 도입이 어렵다.
6. 실무 적용 시 고려사항
Graph RAG를 실제 시스템에 도입할 때 결정적인 설계 포인트는 어떤 retriever를 어떤 질문에 어떻게 라우팅할 것인가이다. 모든 질문을 KG retriever로 보내면 단순한 의미 검색에서 오히려 비효율적이고, 모든 질문을 vector retriever로 보내면 multi-hop 추론이 끊긴다. agent의 tool 선택 prompt와 fallback 정책 설계가 시스템 품질을 좌우한다.
또한 KG는 살아있는 자산이다. 도메인 전문가가 검증·수정 가능한 인터페이스를 제공해 출력 품질을 직접 개선할 수 있게 만들면 transparency와 user confidence가 함께 올라간다. 반대로 한 번 구축하고 방치된 KG는 stale knowledge로 변해 freshness 문제를 다시 끌어들인다. KG의 운영 거버넌스 — 누가, 어떤 주기로, 어떤 검증을 거쳐 갱신하는가 — 가 retrieval 알고리즘만큼 중요하다.
7. 정리
| 측면 | Vector RAG | Graph RAG |
|---|---|---|
| 표현 단위 | chunk + embedding | entity, relationship, subgraph |
| 강점 | 의미 유사도, 빠른 구축 | multi-hop 추론, transparency |
| 약점 | 추론 제한, retrieval noise/miss | 구축 비용, schema 의존성 |
| 적합 질문 | "비슷한 내용 찾기" | "관계 따라가기", 집계, multi-source |
| transparency | 낮음 | 높음 (graph 추적 가능) |
| 갱신 비용 | 재임베딩 | node/edge 단위 수정 |
두 방식은 대체재가 아니라 보완재이다. production 시스템은 보통 두 retriever를 함께 두고 질문 유형에 따라 라우팅하거나 결과를 병합한다.
결론: Graph RAG는 vector RAG의 "비슷한 chunk 모으기"가 놓치는 관계·집계·multi-hop 질문을 풀기 위한 구조이며, 두 retrieval은 경쟁이 아니라 역할 분담 관계로 설계되어야 한다.
참고 자료
- Knowledge Graphs and LLMs in Action. Manning Publications, 2025. Chapter 13: Knowledge graph-powered retrieval-augmented generation.
