Aggregation Framework
데이터를 파이프 라인에 따라 처리할 수 있는 프레임워크입니다.
aggregation framework를 사용하는 이유는
- 기존의 find로 원하는 데이터를 가공하는데 어렵기 때문에
- 빅데이터를 다루려면 새로운 데이터 가공 방식이 필요하기 때문에
- document에 grouping, filtering등 다양한 연산을 적용할 수 있기 때문에
더 자세한 이유가 알고싶다면 https://secretartbook.tistory.com/21
1. Stage
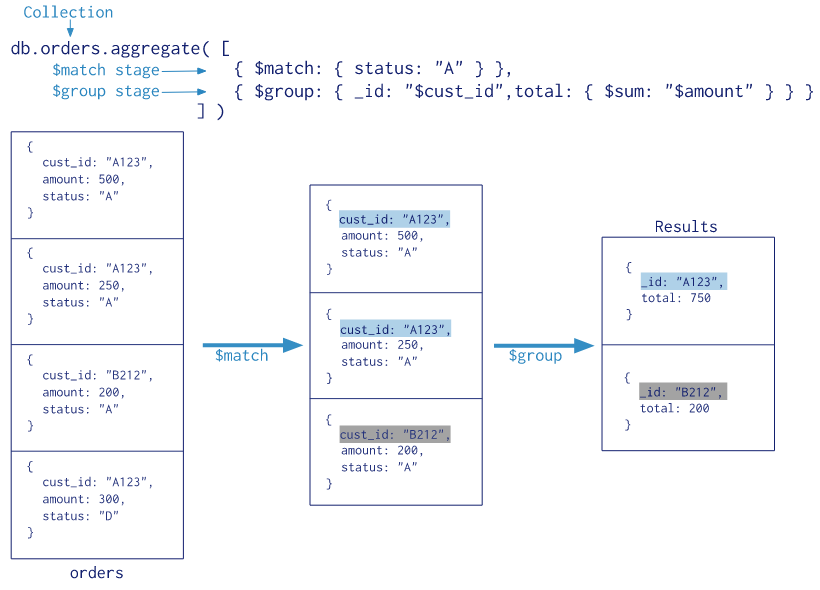
db.user.aggregate 메서드는 파이프라인 단계를 Array형태로 나타냅니다.
db.user.aggregate{[{stage}, ...], options}(1) Match
조건에 만족하는 Document만 filtering하는 과정입니다.
-
입력 형식:
{$match: {<query>}} -
예시
db.user.aggregate([{$match: {<ield: value}}])(2) Group
Document에 대해 Grouping 연산을 수행합니다
- 입력 형식:
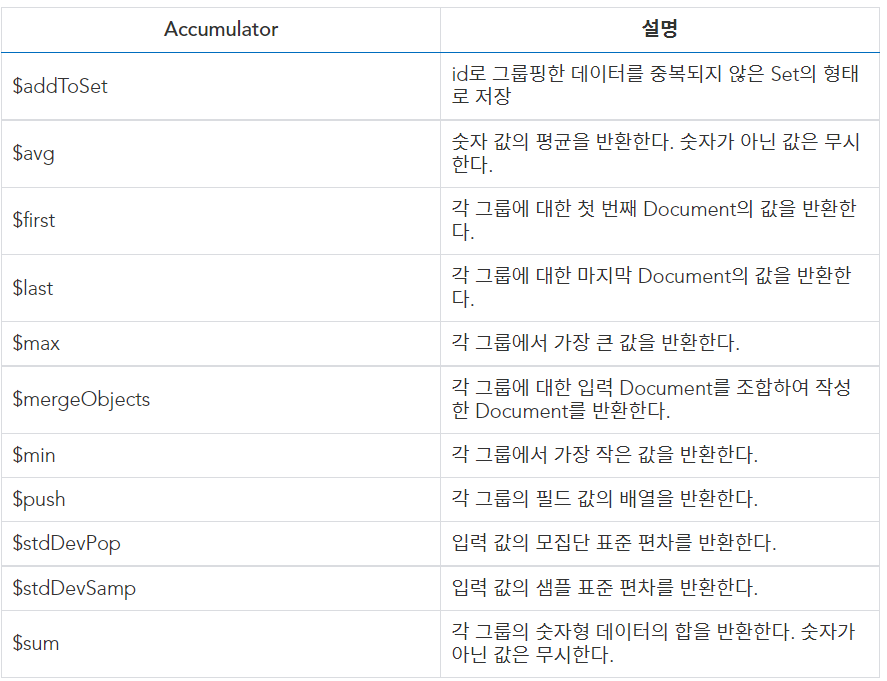
{$group: {
_id: <expression>, // 표현식을 기준으로 그룹화
<field 1>: {<accumulatro 1>: <expression 1>},
...
}}
(3) project
Project에서 지정한 필드 값을 다음 파이프라인 단계로 전달합니다. RDBMS의 SELECT와 같은 역할을 수행합니다.
$project: {
<field 1>: 0, // 0일 경우 보여주지않습니다.
<field 2>: 1 // 1일 경우 보여줍니다
}- _id 필드는 기본적으로 포함됩니다. 다른 필드는 다음 단계에서 사용할 수 있도록 명시적으로 지정해야합니다.
- 제외를 구체적으로 지정하면 제외 필드를 제외한 모든 필드가 반환됩니다.
- 기존 필드 경로를 할당하여 새 이름을 지정하여 필드 이름을 바꿀 수 있습니다.
- 기존 필드에서 표현식을 생성하여 새 필드를 추가할 수 있습니다.
2. other stage
(4) sort
정렬 조건에 맞게 파이프라인의 연산결과를 정렬합니다.
$sort: {
field: 1, // 1일경우 ASC로 정렬합니다.
field2: -1, // -1일경우 DESC로 정렬합니다.
}(5) skip
입력한 갯수만큼 차례대로 Document를 skip한 데이터를 다음 파이프라인으로 전달합니다.
$skip: value // value 수만큼 skip 한 데이터를 다음 파이프라인으로 전달합니다.(6) sample
컬렉션 내에서 입력한 갯수만큼 랜덤하게 Document를 출력합니다.
$sample: {
field: value // value 값만큼 랜덤하게 document를 출력합니다.
}(7) count
입력하는 문서 수의 카운트가 포함된 문서를 다음 단계로 전달
{
$match: {
score: {
$gt: 80
}
}
},
{
$count: "value" // 값의 이름
}
// {value : count된 수 } 가 결과로 나옵니다.(8) $addField
document에 새 필드를 추가합니다. Documnet 및 새로 추가된 필드에서 모든 기준 필드가 포함된 문서를 출력합니다.
(9) limit
파이프라인 연산으로 출력된 Document 갯수를 제한합니다.
$limit : value // value 값만큼 출력됩니다.(10) unwind
Document내의 배열 필드를 기반으로 각각 Document로 분리합니다.
$unwind:
{
path: <field path>,
includeArrayIndex: <string>,
preserveNullAndEmptyArrays: <boolean>
}
나머지..https://docs.mongodb.com/manual/meta/aggregation-quick-reference/
출처
https://jaehun2841.github.io/2019/02/24/2019-02-24-mongodb-2/#aggregation-pipeline
https://www.fun-coding.org/mongodb_advanced1.html
https://ozofweird.tistory.com/entry/MongoDB-Aggregation-Pipeline
