Database
1.SQL 명령어
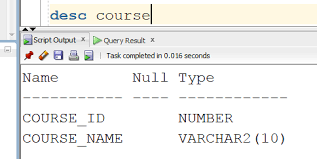
SQL (Strutured Query Language) 관계형 데이터베이스에서 사용되는 표준 질의언어를 말합니다. SQL의 종류로는 MySQL, PostgreSQL, MariaDB, Oracle등이 있습니다. 1. SQL 명령의 종류 (1) 데이터 정의 언어 (DDL
2.SQL vs NoSQL

SQL : 고정된 형식의 스키마가 필요합니다. 형식을 준수하지않으면 레코드를 추가할 수 없고, 스키마를 변경하고 싶다면 데이터베이스 전체를 수정하거나 오프라인으로 전환할 필요가 있습니다. 그래서 '엄격한 스키마'라고 표현합니다.NoSQL : 관계형 데이터베이스보다 동적
3.SQL : DDL

DDL 데이터 정의 언어로서 스키마 내의 객체를 관리할 때 사용합니다. 테이블은 데이터베이스 객체의 대표적 유형입니다.CREATE 명령어를 사용해서 작성할 수 있습니다.CREATE TABLE 테이블명 (열 정의1, 열 정의2...)DROP TABLE 테이블명테이블 정의
4.SQL : DML
DML : Data Manipulation Language 1. SELECT
5.SQL : 복수 테이블
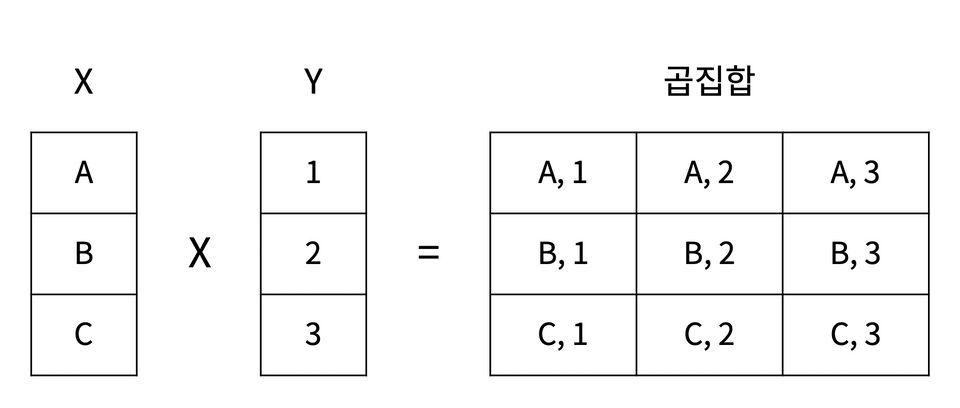
관계형 모델에서 관계형은 수학 집합론의 관계형 이론에서 유래했습니다.';' 맨 마지막에 붙입니다.각 SELECT 명령의 실행 결과를 합집합으로 계산해 최종적으로 결과를 반환합니다.UNION 으로 SELECT 명령을 결합해 합집합을 구하는 경우, 각 SELECT 명령에
6.SQL : 데이터베이스 설계
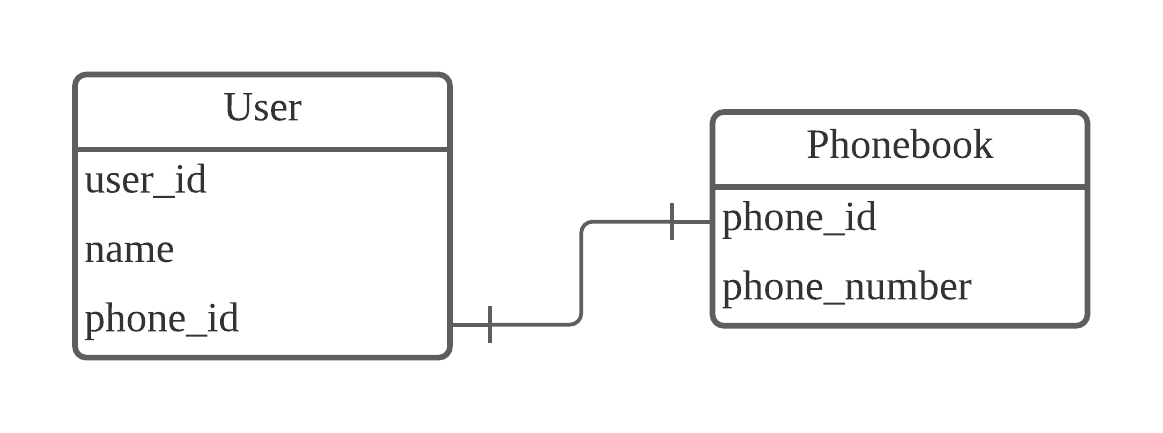
데이터베이스를 설계한다는 것은 스키마 내에 테이블, 인덱스 뷰등의 데이터베이스 객체를 정의하는 것을 말합니다.테이블 설계의 주된 내용은 테이블의 이름이나 열, 자료형을 결정하는 것입니다.논리명과 물리명자료형고정길이와 가변길이기본키테이블의 각 레코드를 구분 할 수 있는
7.SQL : 조건분기
UNION을 사용한 조건 분기는 성능적 측면에서 단점을 가지고 있습니다. 하나의 SQL구문 이지만 내부적으로는 여러개의 SELECT 구문을 실행하는 실행 계획으로 해석되기 때문입니다. 따라서 테이블에 접근하는 횟수가 많아집니다.위의 코드는 쓸데없이 길고 같은 쿼리를 두
8.DBMS 아키텍처
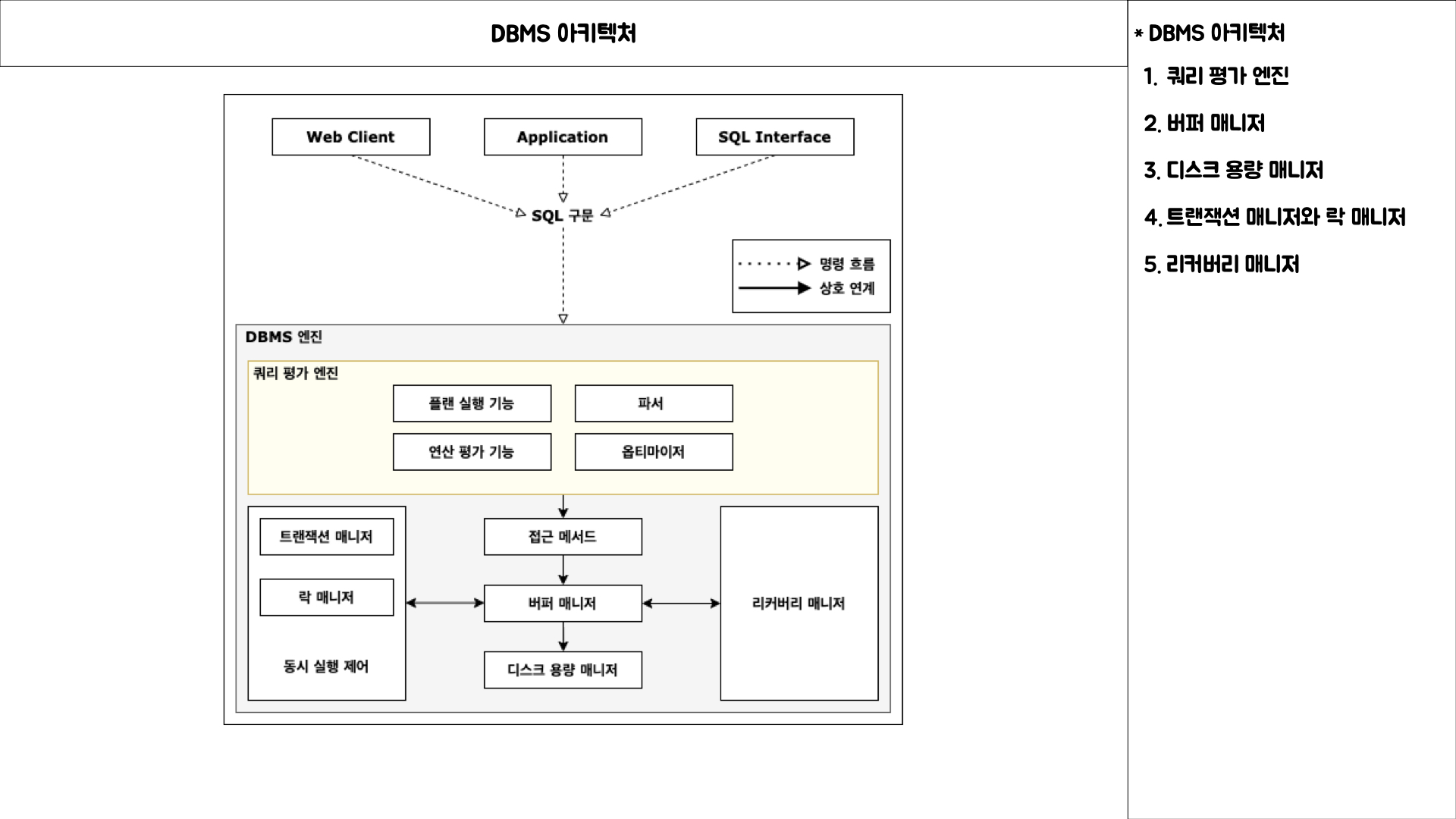
데이터베이스와 데이터베이스 관리시스템, 데이터베이스 시스템은 각각 다른 개념이다.데이터베이스는 저장소를 뜻하고 데이터베이스 시스템은 DB를 접근하거나 관리하는 데이터베이스 사용자이고 데이터베이스 관리시스템(DBMS)는 이를 관리하는 소프트웨어를 의미한다아키텍처하드웨어와
9.MVC 와 Sequelize
MVC Desing pattern 애플리케이션을 세 가지 역할로 구분하는 설계도 입니다. 이러한 패턴을 사용하는 이유는 물론 효율입니다. 세 가지 역할로 분리함으로 각자의 역할에 집중할 수 있고, 유지보수성과 애플리케이션의 확장, 유연성이 증가하게됩니다. 각자의 역할
10.Sequelize query
sequelize에서 CRUD 작업은 sql문을 자바스크립트를 통해 만듭니다. sql 쿼리는 프로미스를 반환하므로 then이나 asnyc/await문법으로 다룰 수 있습니다.SQLsequelizeSQLsequelizeSQLsequelizeSQLSequelizeSQLSe
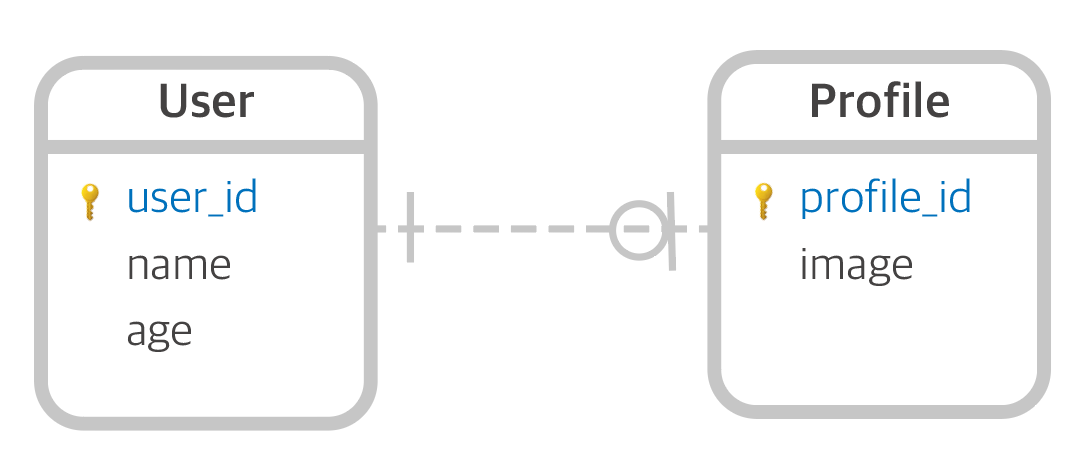
11.MongoDB : Aggregation Framework
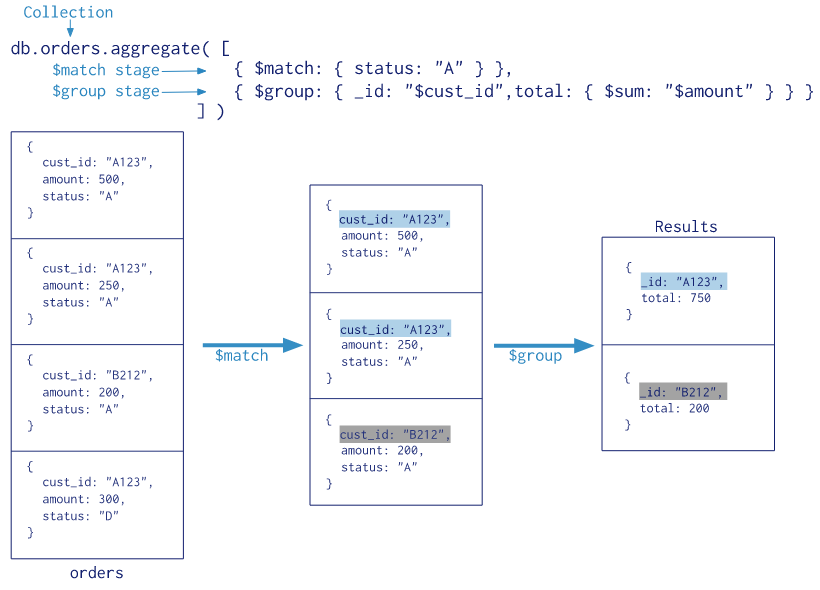
데이터를 파이프 라인에 따라 처리할 수 있는 프레임워크입니다.aggregation framework를 사용하는 이유는기존의 find로 원하는 데이터를 가공하는데 어렵기 때문에빅데이터를 다루려면 새로운 데이터 가공 방식이 필요하기 때문에document에 grouping,
12.MongoDB: index
인덱스는 DB의 검색을 빠르게 하기 위해 데이터의 순서를 미리 정리해 두는 과정입니다. 원하는 데이터 필드를 인덱스로 지정하여 검색 결과를 빠르게 하는 것이 가능합니다.index는 한 쿼리에 한 index만 유효합니다. 두 개의 index가 필요하다면 복합 index를
13.MongoDB 기초

MongoDB NoSQL MongoDB는 NoSQL 데이터베이스 입니다. 그중에서도 NoSQL 도큐먼트 데이터베이스 입니다. Atlas Cloud MongoDB에서는 아틀라스로 클라우드에 데이터베이스를 설정합니다. 아틀라스 사용자는 클러스터를 배포할 수 있습니다.
14.MongoDB: Sharding
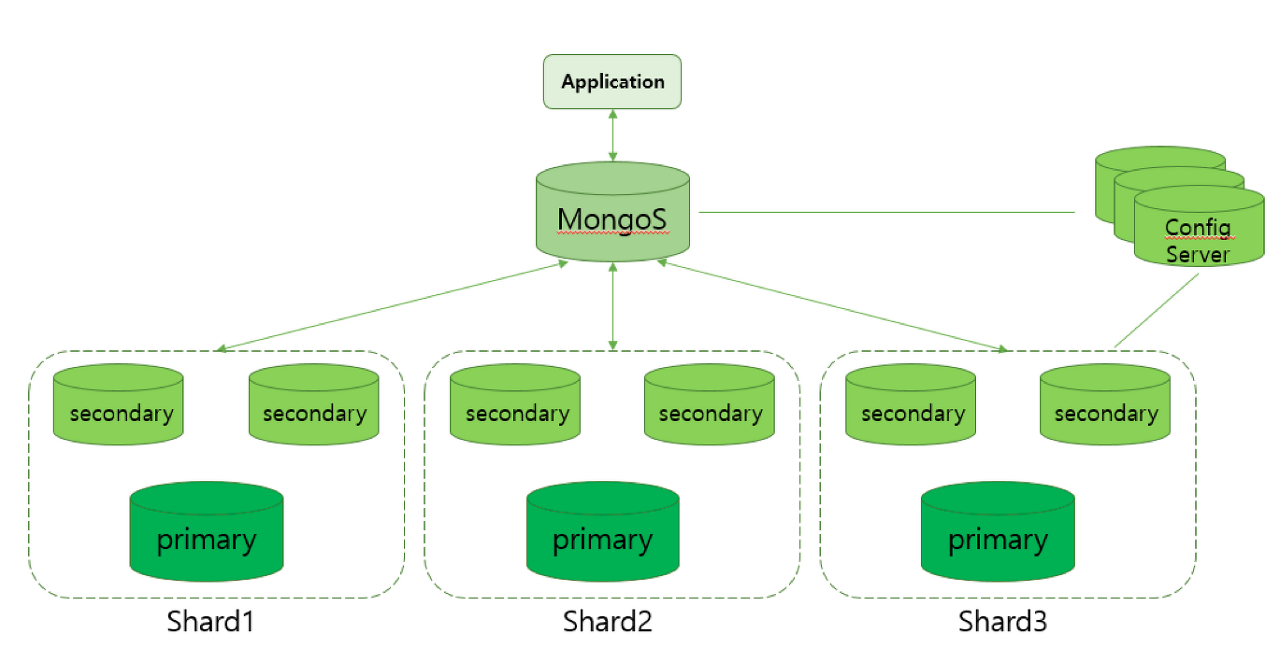
샤딩은 데이터를 여러 서버에 분산해서 저장하고 처리할 수 있는 기술을 말합니다.Shard : 샤드 데이터의 집합, 샤드는 Replica set으로 구성되어 있습니다.Mongos : 몽고스는 쿼리 라우터와 같은 역할로 애플리케이션과 샤드 클러스터 간의 인터페이스를 제공합
15.Sequelize 여러항목 update
v
16.[sequelize] transaction
Transaction 프로젝트 진행과정 중에, 하나의 API에서 데이터베이스에 여러개 접근해야하는 일이 생겼습니다. 일일히 then.catch 를 하려다보니 코드가 길어지고.. 이걸 어떻게 깔끔하게 정리할 수 있을지 생각하던 중에 sequelize에 transact
17.[Sequelize] error : transaction

database접근을 비동기적으로 어떻게 할까 알아보다 transaction을 알게되었고, 써먹을려다보니 무수한 에러에 마주치게되었습니다.(정작 비동기적으로 작동한다는 건 안된다는 걸 알게되었고, promise.all을 사용하면 그래도 효율을 올릴 수 있다는 걸 알았습
18.[Sequelize] error : transaction
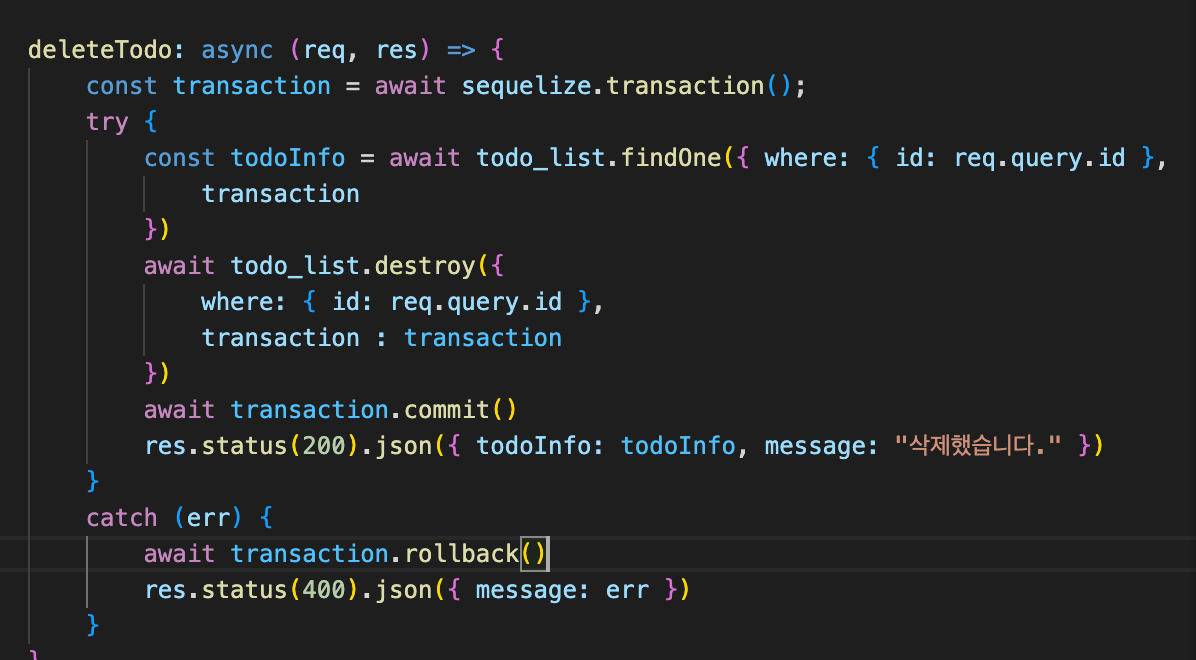
transaction 을 사용한 이유는 여러개의 update를 돌릴 때, 하나가 실패했을 경우 원래대로 모두 다 돌리기위해 사용했지만 예상과는 다르게 update가 돌아가지않았습니다. 심지어 없는 id값을 집어넣어도 동작한다는 걸 확인하게 되었습니다우선 update와
19.엘라스틱 서치란?

면접 준비 중에, 엘라스틱 서치에 대해서 묻는게 많다는 걸 보게되었습니다. 언뜻보기에 '검색엔진'인거 같은데 .., 기존에도 검색 기능이 있는데 이건 뭘까 라는 생각이 들었습니다.하지만 그렇게 단순하지 않고 중요하니 물어보겠지요! 그래서 정리해보았습니다.엘라서틱 서치는
20.Mysql 스토리지 엔진
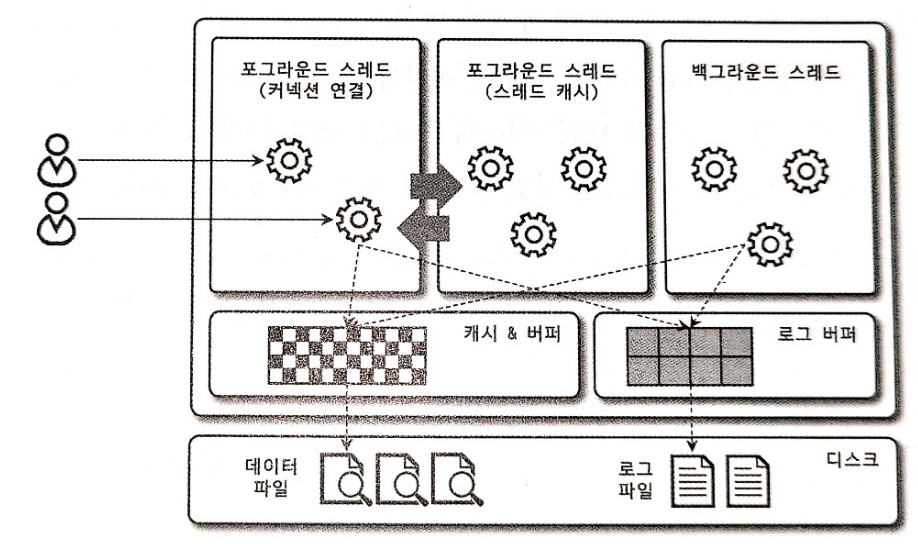
Mysql 스토리지 엔진 프로젝트 당시, transaction이 안됐던게 짜증이나서 Mysql 관련책을 샀습니다. mysql 더 자세히 알고 싶어서 유명한 real Mysql 책을 읽으면서 하나하나 정리하고자합니다. 아키텍쳐 mysql 서버는 mysql 엔진과 스
21.트랜잭션 , 데이터 압축 , 암호화
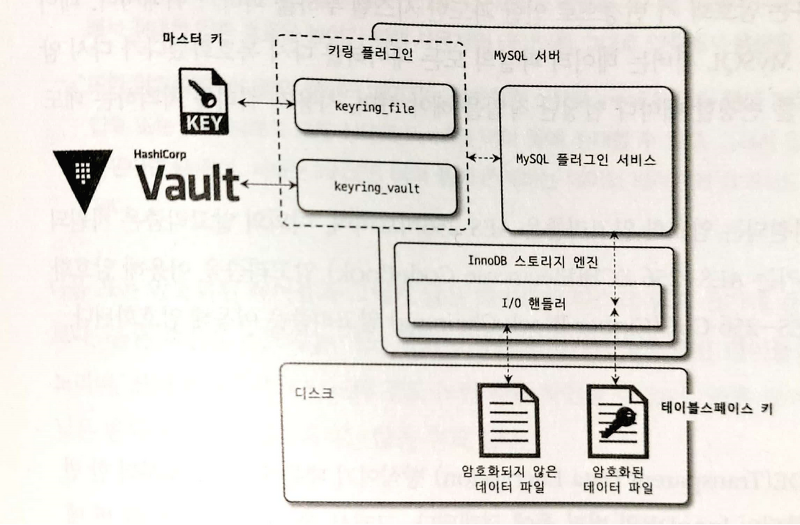
트랜잭션은 논리적인 작업 셋 자체가 100% 적용이 되거나, 아무것도 적용되지않아야함을 보장해 주는 것입니다. 트랜잭션과 함께 나오는게 잠금인데 잠금은 동시성을 제어하기 위한 기능이고 트랜잭션은 데이터의 정합성을 보장하기 위한 기능입니다.잠금은 스토리지 엔진과 MySQ
22.인덱스
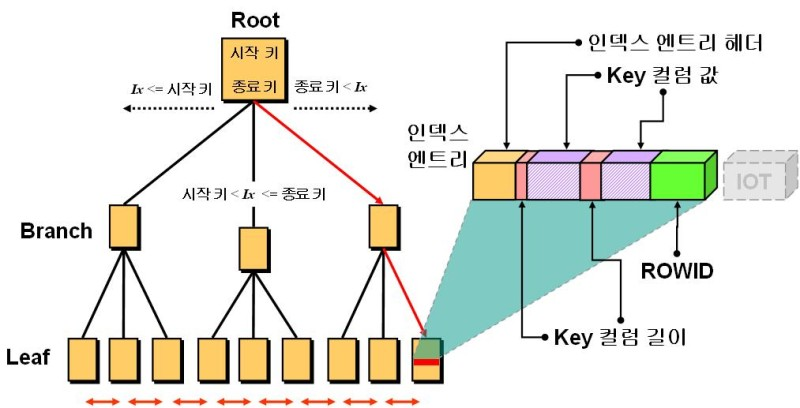
랜덤 I/O는 3개의 페이지를 디스크에 기록하기 위해서 디스크 헤더를 3번 시스템콜을 요청합니다. 하지만 순차 I/O는 디스크 헤더를 1번 움직입니다. 당연히 순차 I/O가 성능히 더 좋습니다.DBMS도 데이터베이스 테이블의 모든 데이터를 검색해서 원하는 결과를 가져오
23.옵티마이저와 힌트
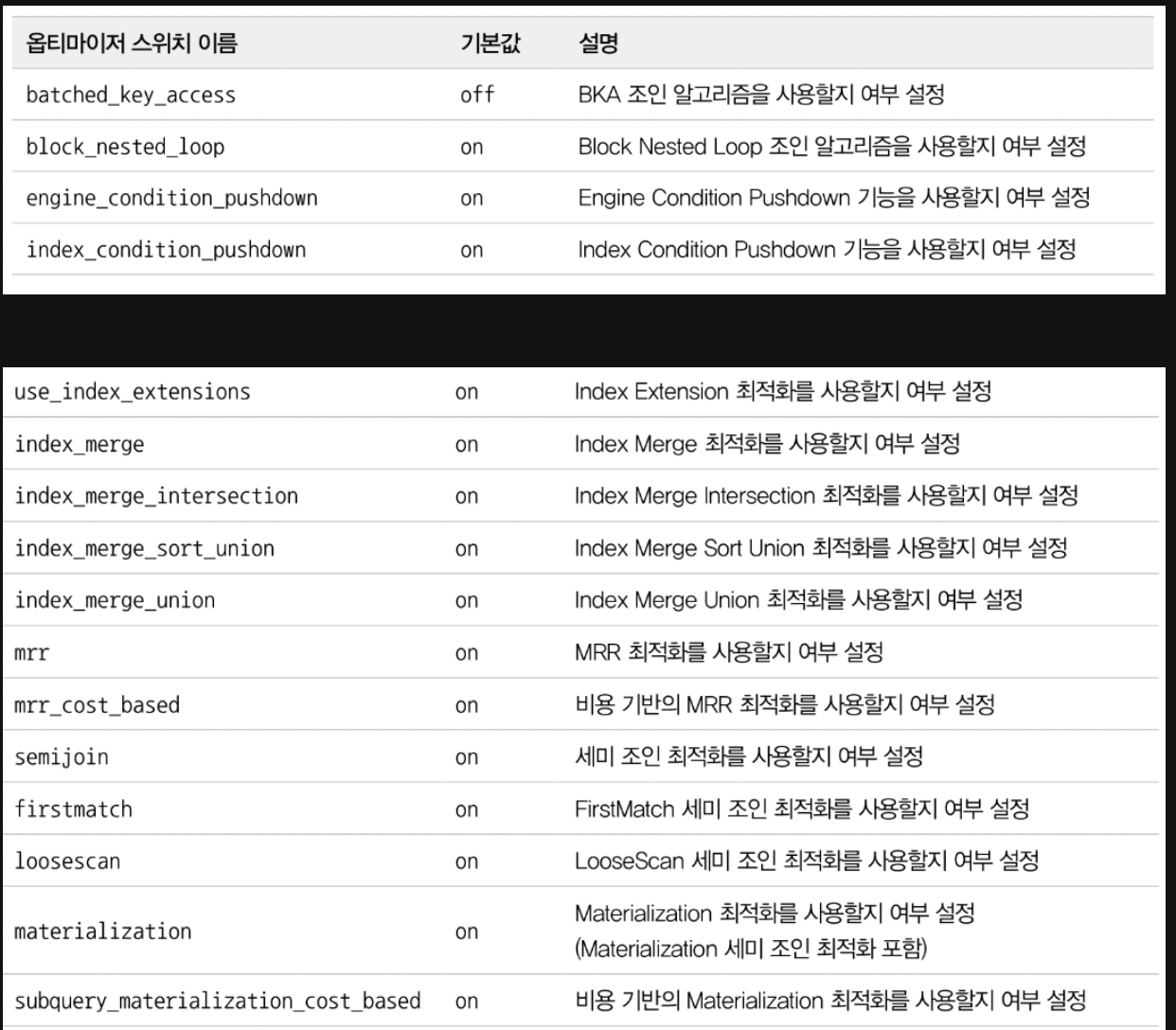
쿼리가 실행되는 과정서버으 'SQL 파서'라는 모듈로 처리합니다. 사용자로부터 요청된 SQL문장을 잘게 쪼개서 MySQL 서버가 이해할 수 있는 수준으로 분리합니다.MySQL서버의 '옵티마이저'에서 처리하며, 첫 번째 단계에서 만들어진 SQL 파스트리를 참조하여서, 어
24.실행계획
각 테이블의 통계 정보는 innodb_index_stats, innodb_table_stats 테이블로 관리할 수 있습니다.히스토그램 정보는 칼럼 단위로 관리됩니다. ANALYZE TABLE... UPDATE HISTOGRAM 명령을 실행해 수동으로 수집 및 관리됩니다
25.[Zookeeper]
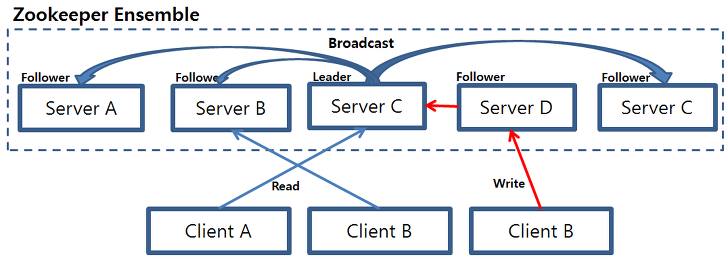
회사 시스템에 zookeeper를 사용하여서 알아보는겸 찾아보았습니다. zookeeper란 분산 시스템을 위한 오픈소스 분산 코디네이션 서비스입니다.여기서 '분산 시스템'이란 복수의 컴퓨터가 네트워크를 통해 통신하며 하나의 목적을 위해서 서로 간에 상호작용하는 걸 의미
26.[Redis] cluster
[Redis] Cluster docker ps
27.mysql - express 연결
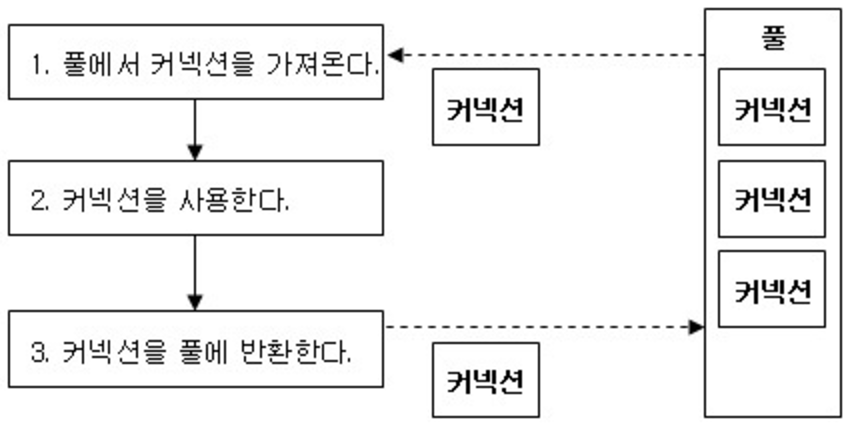
MySQL - Express 연결 오늘은 mysql과 express연결을 해볼려고 합니다. 이전에 프로젝트 할때는 express - sequelize - mysql 이렇게 함으로, 연결도 편하게 할 수 있었습니다. 하지만 공부를 하다가보니 sequelize가 편하고 간
28.MySQL - Explain

원티드에서 프리온보딩 백엔드 mysql 강의를 듣다가, explain을 사용하는 걸보고 6개월 동안 왜 한번도 이걸 사용하지않았을까 싶어 정리해볼려고합니다.EXPLAIN은 MySQL 해당 쿼리를 실행할 때, 실행계획이 무엇인지 알고 싶을때 사용한는 명령어 입니다. 실행