SQL (Strutured Query Language)
관계형 데이터베이스에서 사용되는 표준 질의언어를 말합니다.
SQL의 종류로는 MySQL, PostgreSQL, MariaDB, Oracle등이 있습니다.
1. SQL 명령의 종류
(1) 데이터 정의 언어 (DDL : Data Definition Language)
테이블 관계의 구조를 생성하는 데 사용
- CREATE : 테이블 혹은 데이터베이스 생성
- DROP : 테이블 혹은 데이터 베이스 삭제
- ALTER : 테이블 수정
- TRUNCATE : 테이블 초기화
(2) 데이터 조작 언어 (DML : Data Manipulation Language)
테이블에 데이터를 검색, 삽입 수정, 삭제하는 데 사용
-
SELECT 는 특별히 질의어(QUERY) 라고 합니다.
-
SELECT : 데이터 조회
-
INSERT : 데이터 생성
-
UPDATE : 데이터 수정
-
DELETE : 데이터 삭제
(3) 데이터 제어 언어 (DCL : Data Control Language)
데이터의 사용 권한을 관리하는 데 사용
- GRANT : 사용자에게 특정 권한 부여
- REVOKE : 사용자에게 특정 권한 회수
(4) 데이터 질의 언어 ( DQL : Data Query Language)
저장한 데이터를 원하는 방식으로 조회하는 명령어
- SELECT
(5) 트랜잭션 제어 언어 (TCL : Transaction Control Language)
논리적인 작업의 단위를 묶어서 데이터 조작어에 의해 조작된 결과를 작업단위 별로 제어하는 명령
- COMMIT
- ROLLBACK
- SAVEPOINT
2. SQL 명령어
(1) 데이터베이스 생성
CREATE DATABASE 데이터베이스 이름
(2) 데이터 베이스 사용
USE 데이터베이스 이름;
테이블을 만들거나 수정하거나 삭제하는 등 작업을 할려면, 데이터베이스를 사용하겠다는 명령 전달해야합니다.
(3) 테이블 생성
USE를 이용해 데이터 베이스를 선택했다면, 그 다음은 테이블을 만들어야합니다.
CREATE TABLE user ( // 필드를 가진 테이블을 생성
id int PRIMARY KEY AUTO_INCREMENT,
name varchar(255),
email varchar(255)
)
(4) 테이블 정보 확인
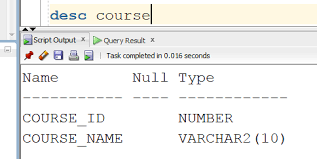
DESCRIBE user;
(5) 데이터 불러오기
데이터를 불러올 때는 SELECT문을 사용하는데 순서를 지켜야합니다.
-
작성 순서
SELECT - FROM - WHERE - GROUP BY - HAVING - ORDER BY
-
실행 순서
FROM - WHERE - GROUP BY - HAVING - SELECT - ORDER BY
SELECT
데이터 셋에 포함될 특성을 특정합니다.
FROM
테이블과 관련된 작업을 할 경우 반드시 입력해야 합니다. FROM 뒤에는 결과를 도출해낼 데이터베이스 테이블을 명시합니다.
SELECT 특성 , 특성2 OR * (모든 특성)
FROM 테이블_이름
WHERE
필터 역할을 하는 쿼리문입니다.
SELECT 특성1, 특성2TPR
FROM 테이블 이름
WHERE 특성1 = "특정 값" // 특정 값과 동일한 데이터를 찾습니다.
WHERE 특성2 <> "특정 값" // 특정 값을 제외한 값을 찾습니다.
WHERE 특성1 > or <"특정 값" // 크거나 작은 데이터를 필터할 때 사용합니다.
WHERE 특성2 LIKE "%특정문자열%" // 문자열에서 특정 값과 비슷한 값들을 필터할 때 사용합니다.
WHERE 특성2 IN ("특정 값1","특정 값2") // 라스트의 값들과 일치하는 데이터를 필터할 때 사용합니다
WHERE 특성1 IS NULL // 값이 없는 경우 'NULL'을 찾을 떄에는 "IS"와 같이 사용합니다.
WHERE 특성1 IS NOT NULL // 값이 없는 경우를 제외할 때에는 'NOT'을 추가해 사용합니다.
ORDER BY
돌려받는 데이터 결과를 어떤 기준으로 정렬하여 출력할지 결정합니다.
SELECT *
FROM 테이블 이름
ORDER BY 특성1 // 기본 정렬은 오름차순
ORDER BY 특성1 DESC // 내림차순
LIMIT
결과를 출력할 데이터의 개수를 정할 수 있습니다.
SELECT *
FROM 테이블 이름
LIMIT 200
DISTINCT
유니크한 값을 받고 싶을 때에는 SELECT DISTINCT를 사용할 수 있습니다.
SELECT
DISTINCT
특성1,
특성2,
특성3
FROM 테이블 이름 // 특성1, 특성2, 특성 3 유니크한 조합 값들을 선택
INNBER JOIN
SELECT *
FROM 테이블1
JOIN 테이블 ON 테이블1.특성A = 테이블2.특성B // 둘 이상의 테이블을 서로 공통된 부분을 기준으로 연결
OUTER JOIN
SELECT *
FROM 테이블1
LEFT OUTER JOIN 테이블2 ON 테이블1.특성A = 테이블2.특성B
마치며..
그디어 DB를 배우는 단계까지 왔습니다.
출처
