MachineLearning
1.K-NN알고리즘
K-NN 알고리즘 (K-Nearest Neighbor) (K-최근접이웃) 인접한 주변 데이터의 타깃 정보를 바탕으로 새로운 입력 데이터에 대한 타깃을 추론하는 알고리즘을 말합니다. 쉽게말하면 근처에 있는 데이터를 바탕으로, 해당 데이터가 어떤 데이터인지 파악하는 겁
2.선형 회귀
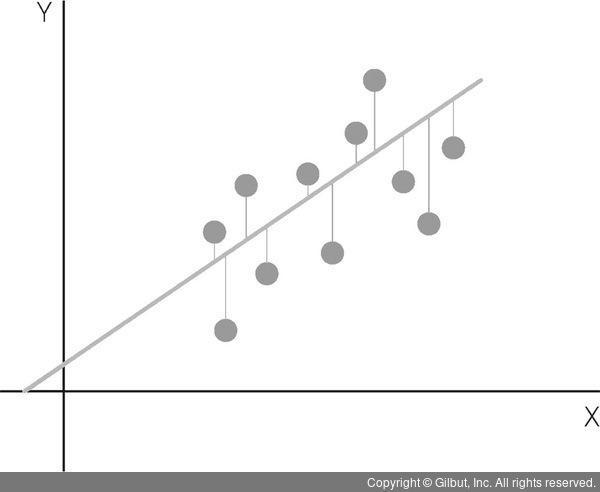
데이터의 관계를 가장 잘 표현하는 직선을 어떻게 그릴 것인가위의 영상이 가장 단순선형의 예시를 잘보여줍니다. 위의 영상에서 여러 선이 그어질 때 각 선마다, 각 점과 차이는 다 다를 것입니다.그 차이를 잔차 제곱의 합이라고 합니다. 식은 이렇게 됩니다. 이식에서 데이터
3.K-평균 알고리즘
K-평균 알고리즘(K-Means)
4.의사결정트리
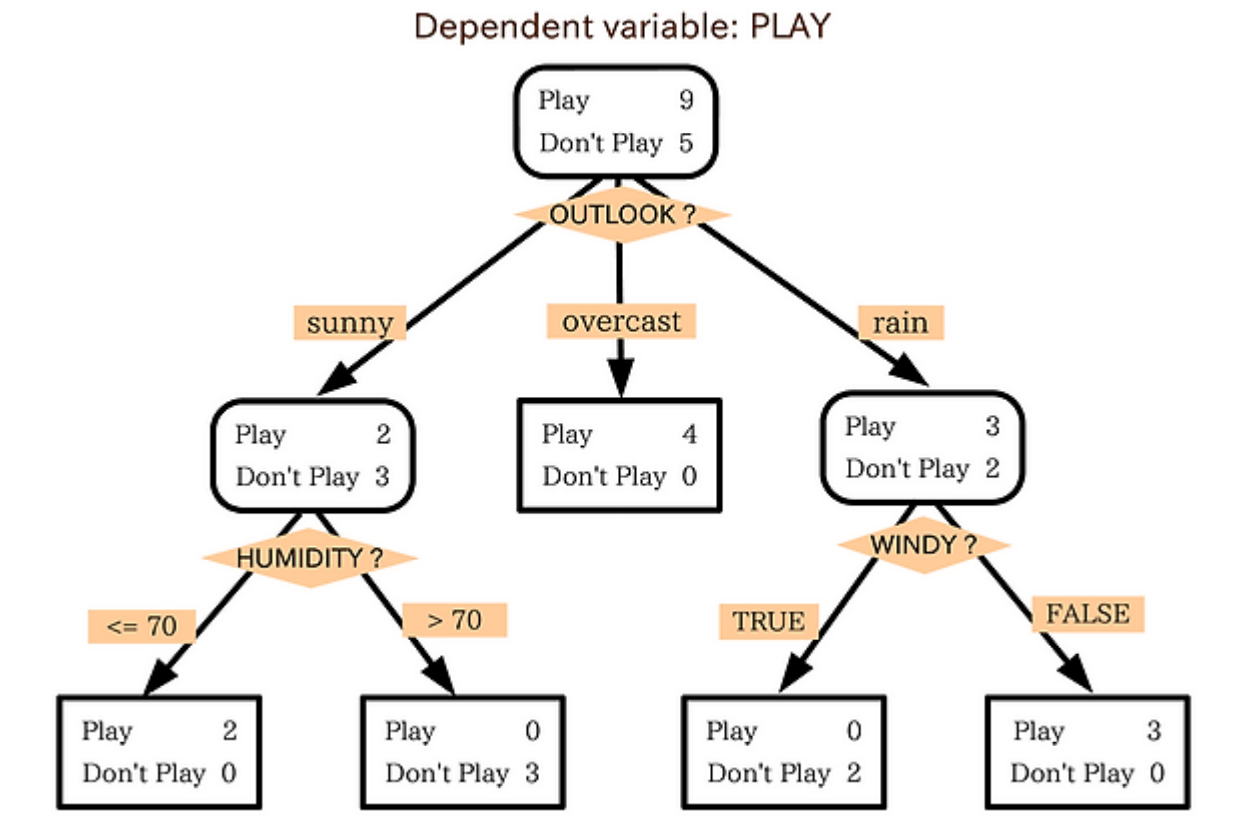
의사 결정 규칙을 트리구조로 도표화하여 분류와 예측을 수행하는 분석 방법입니다. 분류하는 방식은 '스무 고개'와 비슷합니다. 해당 조건에 대해 분류하고 그 다음 조건에 분류하고 이를 계속 반복하는 것입니다.이 질문과 분류 과정을 알고리즘으로 바꿔야합니다.이를 '재귀적
5.나이브 베이즈 분류
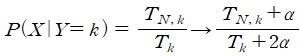
나이브 베이즈 분류 나이브 베이즈 분류는 스팸 메일 필터, 텍스트 분류, 감정 분석 넓게 활용되는 분류 기법입니다. 1. 베이즈 정리 나이브 베이즈 분류를 알기전에 '베이즈 정리'에 대해 알아야합니다. P(B|A) : A가 일어나고서 B가 일어날 확률 => 사
6.keras와 모델
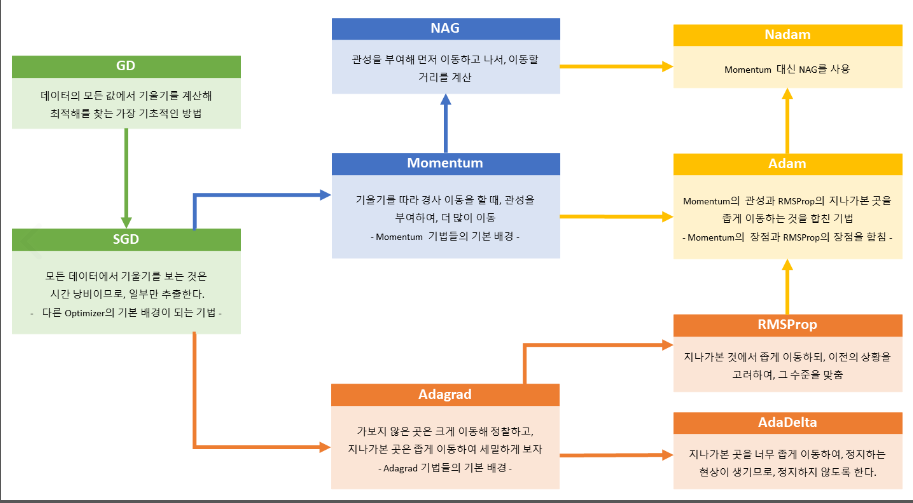
순차적인 층으로 구성돼 있고 하나의 입력츠응로 시작해 하나의 출력층으로 끝나는 모델units : 해당 은닉층에 활동하는 뉴런의 수activation : 활성화 함수, 해당 은닉층의 가중치와 편향의 연산 결과를 어느 함수에 적용하여 출력input_shape : 입력 벡터
7.활성화 함수
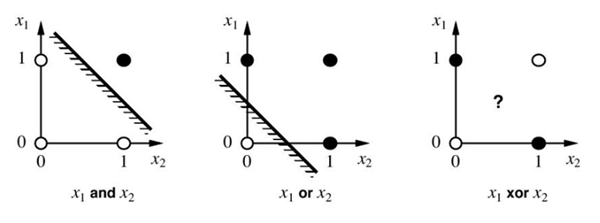
활성화 함수 딥러닝을 공부하다보면, 가중치와 편향을 구하는게 정말 중요합니다. 가중치, 편향의 연산 결과를 함수에 넣어 선형을 비선형 결과로 변형을 해줘야합니다. 1. relu relu 함수는 0 이하의 함수는 모두 0으로 리턴되고 0 이상의 값을 그대로 출력합니다