나이브 베이즈 분류
나이브 베이즈 분류는 스팸 메일 필터, 텍스트 분류, 감정 분석 넓게 활용되는 분류 기법입니다.
1. 베이즈 정리
나이브 베이즈 분류를 알기전에 '베이즈 정리'에 대해 알아야합니다.
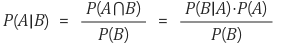
- P(B|A) : A가 일어나고서 B가 일어날 확률
=> 사후 확률
- P(A) : A가 일어날 확률
- P(B) : B가 일어날 확률
=> 사전 확률
나이브 베이즈 분류는 이 베이즈 정리를 이용하여 분류를 수행합니다.
2.실습
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer # 텍스트 데이터를 숫자로 변환
from sklearn.naive_bayes import MultinomialNB
news = datasets.fetch_20newsgroups() # 문자 데이터세트를 가지고 옵니다.
X, y = news.data, news.target
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
vectorizer =TfidfVectorizer()
X_train_vec = vectorizer.fit_transform(X_train)
X_test_vec = vectorizer.transform(X_test)
model = MultinomialNB(alpha=0.01)
model.fit(X_train_vec, y_train)
train_score = model.score(X_train_vec, y_train)
test_score = model.score(X_test_vec, y_test)
print(train_score)
print(test_score)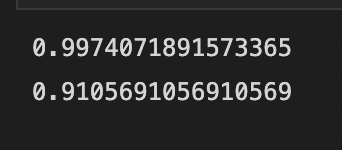
(1) sklearn.feature_extraction.text 메서드
-
CountVectorizer : 텍스트 말뭉치로부터 단어 딕셔너리를 생성하고 각 인스턴스는 문서에서 특정 단어가 나타나는 횟수가 원소인 수치 속성 벡터로 변환합니다.
-
HashingVectorizer : 토큰을 속성 색인으로 연결하는 해싱함수를 구현하고 CountVectorizer와 같이 카운트 계산합니다.
-
TfidVectorizer : CountVectorizer와 같이 작동하지만 단어 빈도와 역문서 빈도 TF-IDF 계산 사용 문서나 밀뭉치에서 단어의 중요성을 측정, 문서의 전체 말뭉치에서 단어 빈도와 비교해 현재 문서에서 빈도가 높은 단어를 찾습니다. 이러한 방법으로 결과를 정규화하고 너무 빈도가 높은 단어를 피합니다
(2) 나이브 베이즈 모형 분류
-
GaussianNB
-
BernoulliNB
-
MultinomialNB
라플라스 스무딩
여기서 alpha=1.0은 라플라스 스무딩이 적용되었음을 의미합니다.
라플라스 스무딩은 헌련 데이터에 없던 값이 들어오거나 이상값이 들어올 경우에 정상적인 분류가 되지 않을 떄가 있습니다. 이경우를 막기위해서 '라플라스 스무딩'을 적용합니다.
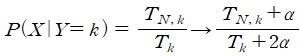
출처
https://angeloyeo.github.io/2020/01/09/Bayes_rule.html
https://childult-programmer.tistory.com/66#:~:text=%EA%B0%80%EC%9A%B0%EC%8B%9C%EC%95%88%20%EB%82%98%EC%9D%B4%EB%B8%8C%20%EB%B2%A0%EC%9D%B4%EC%A6%88%EB%8A%94,%EA%B2%B0%ED%95%A9%ED%95%9C%20%ED%98%95%ED%83%9C%EB%A1%9C%20%ED%91%9C%ED%98%84%ED%95%A9%EB%8B%88%EB%8B%A4.
