
ElasticSearch
면접 준비 중에, 엘라스틱 서치에 대해서 묻는게 많다는 걸 보게되었습니다. 언뜻보기에 '검색엔진'인거 같은데 .., 기존에도 검색 기능이 있는데 이건 뭘까 라는 생각이 들었습니다.
하지만 그렇게 단순하지 않고 중요하니 물어보겠지요! 그래서 정리해보았습니다.
1. 엘라스틱 서치
엘라서틱 서치는 Apache Lucene 기반의 Java 오픈소스 분산 검색 엔진입니다.

이 분이 엘라스틱 서치를 만든 개발자입니다. 과거 한국 생활한 적이 있어서 트위터와 공식아이디가 kimchy라고 하네요, 아무튼 이 샤이 배논이라는 분이 요리학원을 다니는 아내를 위해 요리법 검색 엔진을 만들기 위해 시작하였고 처음에는 Compass => 루신 이것이 지금의 ES가 되었다고 합니다.
2. 특징
A. 분산 시스템, 확장성
ES는 여러 개의 노드로 구성되어있는 분산 시스템입니다. 이 노드는 데이터를 색인하고 검색 기능을 수행하는 ES 단위 프로세스입니다. 소규모 시스템에서 적은 수의 노드로 시스템을 구성한 후에, 시스템 규모가 늘어나면 기존 노드에 새 노드를 실행해서 연결하는 것으로 쉽게 시스템을 확장할 수 있고, 데이터는 각 노드에 분산 저장되고 복사본을 유지해서 각종 충돌로부터 노드 데이터의 유실을 방지합니다.
B. 높은 가용성
ES 는 하나 이상의 노드로 구성되어있으며, 각 노드는 1개 이상의 데이터 원본과 복사본을 가지고 있어서 다른 위치에 나누어 저장하고 있습니다. 노드가 종료되거나 실행에 실패하는 경우 ES는 노드들의 상태를 감지하고 종료된 노드가 가지고 있던 데이터를 다른 노드로 옮기는 작업을 실행합니다.
이러한 과정이 ES가 항상 일정한 데이터 복사본 개수를 유지하고 높은 가용성과 안전성을 보장합니다.
C. 멀티 테넌시(Multi-tenancy )
ES의 데이터는 여러개로 분리된 인덱스들에 그룹으로 저장이 됩니다. ES에서는 데이터를 검색할 때 서로 다른 인덱스의 데이터를 바로 하나의 질의로 묶어서 검색하고 여러 검색 결과를 하나로 출력할 수 있습니다. 이러한 특징을 멀티 테넌씨라고 부릅니다.
D. 전문검색
ES는 데이터 색인을 이용해 전문검색을 지원하고 있습니다. 데이터의 전체 문장에서 검색어를 추출해 저장하고 이를 바탕으로 검색하는 전문검색을 지원합니다.
E. JSON 문서 기반
ES의 모든 데이터는 기본적으로 문서의 모든 필드가 색인되어 JSON구조로 저장됩니다. 그러므로 모든 레벨의 필드에 접근이 쉽고, 매우 빠른 속도로 검색이 됩니다. 또한, NoSQL과 같이 스키마 프리를 지원하므로 별도의 사전 매핑 없이도 JSON 문서 형식으로 데이터를 입력하면 바로 검색 가능한 형태로 색인 작업이 수행됩니다.
F. RESTful API
RESTful API를 지원하므로 URI를 사용한 동작이 가능합니다. 또 HTTP 프로토콜로 JSON 문서의 입출력과 다양한 제얼르 할 수 있습니다.
왜 엘라스틱 서치인가?
특징들을 보면, 확장성도 좋고, JSON 문서 형태로 공유가 가능하며, 역색인 구조로 저장하기 떄문에 데이터 검색에 있어서는 RDB보다 뛰어납니다. 또 REST API와 같이 표준 인터페이스를 지지하니 사용하기도 편리합니다.
방대한 양의 데이터를 신속하게, 실시간(Near Real Time)으로 저장, 검색, 분석할 수 있으니 사용합니다.
역색인(Inverted Index)
키워드를 통해 문서를 찾아내는 방식입니다
색인구조를 가진 RDBMS의 경우 처음부터 끝까지 읽어야만 검색된 내용이 포함된 결과를 알 수 있습니다. 하지만 역새인 은 해당 단어만 찾으면 단어가 포함된 위치를 알 수 있으므로 검색이 빠릅니다.

3. ES와 관계형 DB비교
(1)ES와 RDBMS
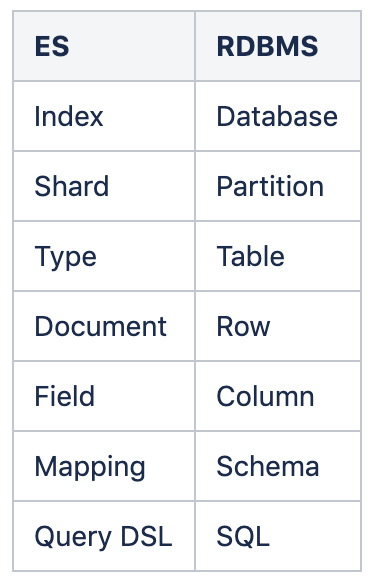
(2)ES와 RDBMS SQL
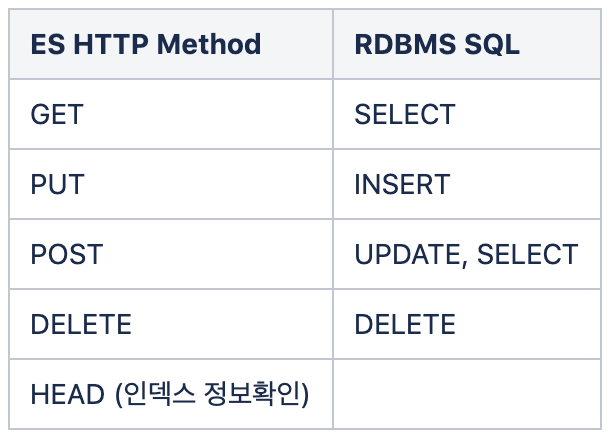
3. 아키텍처

(1) Cluster
클러스터란 하나 이상의 노드로 구성된 노드의 집합을 말합니다.
(2) Node
노드는 ES가 실행중인 하나의 프로세스 혹은 인스턴스에 해당합니다. 모든 노드는 클러스터 내에서 각자의 역할을 부여받습니다.
-
Master-eligible Node
클러스터 관리 노드로 노드 추가/제거, 인덱스 생성/삭제 등 클러스터의 전반적 관리를 담당합니다. -
Data Node
데이터가 저장되는 노드로 데이터가 분산 저장되는 물리적인 공간인 샤드가 배치되는 노드입니다. -
Coordination Node
사용자의 요청을 받고 라운드 로빈 방식으로 분산시켜 주는 노드입니다. 클러스터에 관련된 것은 마스터 노드로 데이터에 관련된 것은 데이터 노드로 넘깁니다. -
Ingest Node
문서 전처리 작업을 수행합니다.
(3) Shard(샤드)
인덱스 내부에는 색인된 데이터들이 존재합니다. 이 데이터들은 모여있지않고 물리적 공간에 여러개로 나누어 존재합니다. 이러한 부분을 샤드라고합니다.
ES는 기본적으로 인덱스를 5개의 샤드로 나누어 저장합니다. 나누어 저장하기 때문에 수평분할/확장이 가능하고, 작업을 여러 샤드에서 수행하기 때문에 성능/처리량을 늘릴 수 있습니다.
-
Primary Shard : 데이터의 원본, ES에서 데이터 업데이트 요청을 날리면 반드시 Primary Shard에 요청을 하게 되고 해당 내용은 레플리카에 복제됩니다.
-
Replica Shard : Primary Shard에 복제본으로 기존 원본 데이터가 무너졌을 때 대신 쓰면서 장애 극복 역할을 수행합니다.
(4) Segment(세그먼트)
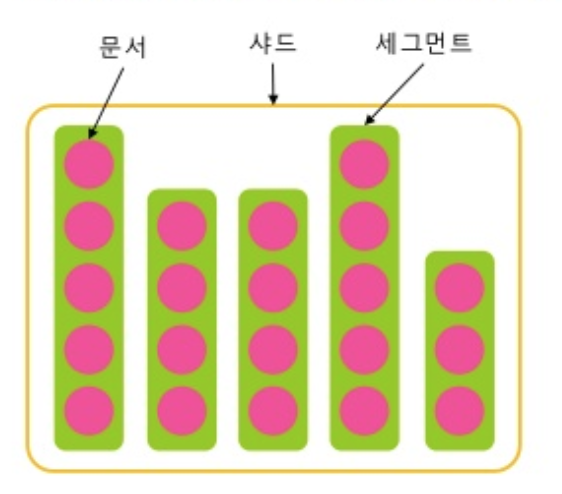
각 샤드는 Segment로 구성되어있습니다. ES에서 데이터를 저장하면 , 엘라스틱 서치는 이걸 메모리에 모아두고 새로운 세그먼트를 디스크에 기록해서 검색을 리프레쉬합니다.
샤드에서 검색 시, 먼저 각 세그먼트를 검색하며 결과를 조합하고 최종 결과를 해당 샤드의 결과로 리턴합니다.
세그먼트는 불변의 성질을 가지고 있기 떄문에 데이터가 업데이트 되면 실제로는 삭제되었다고 마크만하고 새로운 데이터를 가리킵니다. 삭제되었다고 마크된 데이터는 디스크에 남아있다가 백그라운드에 주기적으로 또는 특정 임계치를 넘기면 필요없어진 데이터를 정리하고 새로운 세그먼트로 병합한 후 세그먼트를 삭제하며 이때 비로소 완전히 삭제가 됩니다. 이를 세그먼트 병합이라고 합니다.
라이브러리 일 줄 알고 시작했다가, 데이터베이스라 분량이 너무 많다는 걸 알게되었습니다. 그러다보니 대략적인 어떤게 안에 있는지 살펴보았습니다. 내부 원리로 들어가게되면 더 복잡해집니다.
그리고 자바에서만 작동한다고 되어있는데, Node에서도 할 수 있게 라이브러리가 있는 걸 확인했습니다. 요즘 대규모 설계 책을 보고있는데, 엘라스틱 서치라는 데이터베이스를 따로 둬서 검색에 활용할 수 있도록 해야되나? 고민하면서 공부를 했습니다.
좀 더 정리가되면, 엘라스틱 서치에 대해 공부하고 적용했으면 좋겠습니다!
출처
https://jaemunbro.medium.com/elastic-search-%EA%B8%B0%EC%B4%88-%EC%8A%A4%ED%84%B0%EB%94%94-ff01870094f0
https://www.samsungsds.com/kr/insights/elastic_data_modeling.html
https://velog.io/@jakeseo_me/%EC%97%98%EB%9D%BC%EC%8A%A4%ED%8B%B1%EC%84%9C%EC%B9%98-%EC%95%8C%EC%95%84%EB%B3%B4%EA%B8%B0-2-DB%EB%A7%8C-%EC%9E%88%EC%9C%BC%EB%A9%B4-%EB%90%98%EB%8A%94%EB%8D%B0-%EC%99%9C-%EA%B5%B3%EC%9D%B4-%EA%B2%80%EC%83%89%EC%97%94%EC%A7%84
https://wonyong-jang.github.io/elk/2021/02/05/ELK-Elastic-Search.html
https://victorydntmd.tistory.com/308
https://twofootdog.tistory.com/53
https://victorydntmd.tistory.com/311?category=742451
