옵티마이저와 힌트
1. 개요
(1) 쿼리 실행 절차
쿼리가 실행되는 과정
A. SQL 파싱
서버으 'SQL 파서'라는 모듈로 처리합니다. 사용자로부터 요청된 SQL문장을 잘게 쪼개서 MySQL 서버가 이해할 수 있는 수준으로 분리합니다.
B. 최적화 및 실행 계획 수립
MySQL서버의 '옵티마이저'에서 처리하며, 첫 번째 단계에서 만들어진 SQL 파스트리를 참조하여서, 어떤 테이블부터 읽고 어떤 인덱스를 이용해 읽을지 선택합니다.
- 불필요한 조건 제거 및 복잡한 연산 단순화
- 여러 테이블의 조인이 있는 경우 어떤 순서로 테이블을 읽을지 결정
- 각 테이블에 사용된 조건과 인덱스 통계정보를 이용해 사용할 인덱스를 결정
- 가져온 레코드들을 임시 테이블에 넣고 다시 한번 가용해야 하는지 결정
C. 수립된 실행 계획
쿼리의 '실행계획'이 만들어지면, 실행계획대로 스토리지 엔진에 레코드를 읽어오도록 요청하고 MySQL엔진에서 스토리지 엔진으로부터 받은 레코드를 조인하거나 정렬하는 작업을 수행합니다.
(2) 옵티마이저의 종류
-
비용 기반 최적화
기본적으로 대상 테이블의 레코드 건수나 선택도 등을 고려하지 않고 옵티마이저에 내장된 우선순위에 따라 실행 계획을 수립하는 방식 의미
이 방식에는 통계 정보를 조사하지않고 실행계획이 수립되기 떄문에 같은 쿼리에 대해서는 항상 같은 실행 방법을 만들어냅니다 -
규칙 기반 최적화
쿼리를 처리하기 위해서 여러가지 방법을 만들고, 각 단위 작업의 비용 정보와 대상 테이블의 예측된 통계 정보를 이용해 실행 계획별 비용을 산출합니다. 이렇게 산출된 실행 방법별로 비용이 최소로 소요되는 처리방식을 선택해 최종적으로 쿼리를 실행합니다.
2. 기본 데이터 처리
(1) 풀 테이블 스캔과 풀 인덱스 스캔
풀 테이블 스캔이란 인덱스를 사용하지않고 테이블의 데이터를 처음부터 끝까지 읽어서 요청된 작업을 처리하는 작업을 의미합니다.
다음의 경우에 사용합니다.
- 테이블의 레코드 건수가 너무 작아서 인덱스를 통해 읽는 것보다 풀 테이블을 스캔 하는 편이 더 빠른 경우
- WHERE 절이나 ON절에 인덱스를 이용할 수 있는 적절한 조건이 없는 경우
- 인덱스 레인지 스캔을 사용할 수 있는 쿼리라고 하더라도 옵티마이저가 판단한 조건 일치 레코드 건수가 너무 많은 경우
InnoDB 스토리지 엔진은 특정 테이블의 연속된 데이터페이지가 읽히면 백그라운드 스레드에 의해 Read ahead 작업이 자동으로 시작됩니다.
풀 테이블 스캔이 실행이 되면 처음에는 몇개의 데이터페이지를 포그라운드 스레드가 페이지 읽기를 실행하지만 특정 시점부터는 읽기 작업을 백그라운드 스레드로 넘깁니다.
백그라운드 스레드가 읽기는 넘겨받는 시점부터는 한번에 4개 8개 페이지를 읽으면서 계속 증가시킵니다. 64개의 페이지까지 읽어서 버퍼 풀에 저장해둡니다
포그라운드 스레드는 버퍼 풀에 저장된 데이터를 가져다 사용하기만 하면 되므로 쿼리가 빨리 처리됩니다.
Read ahead
어떤 영역의 데이터가 앞으로 필요해지리라는 걸 예측해서 요청이 오기 전에 미리 디스크에서 읽어 InnoDB 버퍼 풀에 가져다 두는 걸 의미합니다.
(2) 병렬 처리
MySQL 서버에서도 쿼리의 병렬 처리가 가능해졌습니다. 'innodb_parallel_read_threads' 시스템 변수를 이용해서 테이블의 전체 건수를 가져오는 쿼리만 병렬로 처리할 수 있습니다.\
(3) ORDER BY 처리(Using filesort)
정렬을 처리하는 방법은 인덱스를 이용한 방법과 쿼리를 실행할 때 'Filesort'라는 별도의 처리를 이용하는 방법으로 나눌 수 있습니다.
-
인덱스 이용 : INSERT, UPDATE, DELETE 쿼리가 실행될 때 이미 인덱스가 정렬돼 있어서 순서대로 읽기만하면 되므로 매우 빠릅니다. 하지만 위에 작업시 부가적인 인덱스 추가/삭제 작업이 필요하므로 느립니다. 인덱스 떄문에 디스크 공간이 더 필요합니다.
-
Filesort : 인덱스를 생성하지 않아도 되므로 인덱스를 이용할 때의 단점이 장점으로 바뀝니다. 정렬 작업이 쿼리 실행 시 처리되므로 레코드 대상 건수가 많아질수록 쿼리 응답 속도가 느립니다
A. 소트 버퍼
MySQL은 정렬을 수행하기 위해서 별도의 메모리 공간을 할당받아서 사용합니다. 이 메모리 공간을 '소트 버퍼'라고합니다. 이는 정렬이 필요한 경우에만 할당되며, 버퍼의 크기는 정려해야 할 레코드의 크기에 따라 가변적으로 증가하지만, 최대 사용 가능한 소트 버퍼의 공간은 sort_buffer_size라는 시스템 변수로 설정할 수 있습니다.
메모리의 소트버퍼에서 정렬을 수행하고, 그 결과를 임시로 디스크에 기록해둡니다. 그리고 다음 레코드를 가지고와서 다시 정렬해서 반복적으로 디스크에 임시 저장합니다. 각 버퍼 크기만큼 정렬된 레코드를 다시 병합하면서 정렬을 수행해야합니다. 이 병합 작업을 '멀티 머지'라고 합니다.
B. 정렬 알고리즘
레코드를 정렬 할 때 레코드 전체를 소트 버퍼에 담을지, 정렬 기준 칼럼만 소트 버퍼에 담을지에 따라 '싱글 패스'와 '투 패스' 2가지 정렬 모드로 나눌 수 있습니다.
- 싱글 패스 정렬 방식
소트 버퍼에 정렬 기준 칼럼을 포함해 SELETE 대상이 되는 칼럼 전부를 담아서 정렬을 수행하는 정렬 방식입니다.
정렬 대상 레코드의 크기나 건수가 작을 경우 빠른 성능을 보입니다.
- 투 패스 정렬 방식
정렬 대상 칼럼과 프라이머리 키 값만 소트 버퍼에 담아서 정렬을 수행하고, 정렬된 순서대로 다시 프라이머리 키로 테이블을 읽어서 SELECT할 칼럼을 가져오는 정렬 방식으로, 싱글 패스 이전에 사용하던 방식입니다.
레코드의 크기가 max_length_for_sort_data 시스템 변수에 설정된 값보다 클 때, BLOB이나 TEXT 타입의 칼럼이 SELECT 대상에 포함될 떄 사용됩니다.
- 정렬 처리 방법
옵티 마이저는 정렬 처리를 위해 인덱스를 이용할 수 있는지 검토합니다. 인덱스를 이용할 수 있다면 별도의 'Filesort'과정 없이 인덱스를 순서대로 읽어서 결과를 반환합니다.
인덱스를 사용할 수 없다면 WHERE 조건에 일치하는 레코드를 검색해서 정렬 버퍼에 저장하면서 정렬을 처리할 것입니다. 이 정렬 대상 레코드를 최소화하기위해 조인의 드라이빙 테이블만 정렬한 다음 조인을 수행 하거나 조인이 끝나고 일치하는 레코드를 모두 가져온 후 정렬을 수행할지 선택합니다.
- 인덱스를 이용한 정렬
인덱스를 이용한 정렬을 위해서는 반드시 ORDER BY에 명시된 칼럼이 제일 먼저 읽는 테이블에 속하고, ORDER BY에 순서대로 생성된 인덱스가 있어야합니다. 또한 WHERE절에 첫 번째로 읽는 테이블의 칼럼에 대한 조건이 있다면 그 조건과 ORDER BY는 같은 인덱스를 사용할 수 있어야합니다.
- 조인의 드라이빙 테이블만 정렬
조인이 수행되면 레코드의 건수가 몇 배로 불어나고, 크기도 늘어납니다. 조인을 실행하기 전에 첫 번째 테이블의 레코드를 먼저 정렬한 다음 조인을 실행하는게 정렬의 차선책이 됩니다.
- 임시테이블을 이용한 정렬
쿼리가 여러 테이블을 조인하지않고, 하나의 테이블로부터 SELECT해서 정렬하는 경우라면 임시 테이블이 필요하지않습니다. 하지만 2개 이상의 테이블을 조인해서 결과를 정렬해야한다면 임시 테이블이 필요할 수도 있습니다. 이방법은 3가지 방법 가운데 가장 느린 정렬방법입니다.- 정렬 처리 방법의 성능 비교
- 스트리밍 방식
조건에 일치하는 레코드가 검색될 때마다 바로바로 클라이언트로 전송해주는 방식을 의미합니다. 스트리밍 방식으로 처리되는 쿼리는 쿼리가 얼마나 많은 레코드를 조회하느냐에 상관없이 빠른 응답 시간을 보장해줍니다. -버퍼링 방식
ORDER BY나 GROUP BY 같은 처리는 쿼리의 결과가 스트리밍 되는 것을 불가능하게 합니다. 우선 WHERE 조건에 일치하는 모든 레코드를 가저온 후에, 정렬하거나 그루핑해서 차례대로 보내야하기 때문입니다.
-
정렬 관련 상태 변수
처리하는 주요 작업에 대해서 해당 작업의 실행 횟수를 상태 변수로 저장합니다. 'SHOW STATUS LIKE 'Sort%' 로 확인할 수 있습니다.- Sort_merge_passes : 멀티 머지 처리 횟수를 의미 - Sort_range : 인덱스 레인지 스캔을 통해 검색된 결과에 대한 정렬 작업 횟수 - Sort_scan : 풀 테이블 스캔을 통해 검색된 결과에 대한 정렬 작업 횟수 - Sort_raws : 지금까지 정렬된 전체 레코드 건수를 의미
(4) GROUP BY 처리
GROUP BY 절에 있는 쿼리에서는 HAVING 절을 사용할 수 있습니다. HAVING은 GROUP BY에 대해 필터링 역할을 수행합니다.
A. 인덱스 스캔을 이용하는 GROUP BY
인덱스가 있다면 인덱스를 차례대로 읽으면서 그루핑 작업을 수행하고 그 결과로 조인을 처리합니다. GROUP BY가 인덱스를 통해 처리되는 쿼리는 이미 정렬된 인덱스를 읽는 것으로 쿼리 실행 시점에 추가적인 정렬 작업이나 내부 임시 테이블은 필요로 하지않습니다.
B. 루스 인덱스 스캔을 이용하는 GROUP BY
인덱스의 레코드를 건너뛰면서 필요한 부분만 읽어서 가져오는 걸 의미, 옵티마이저가 루스 인덱스 스캔을 사용할 때는 실행계획 Extra 칼럼에 'Using index for group-by'코멘트가 표시됩니다.
MySQL 루스 인덱스 스캔 방식은 단일 테이블에 대해 수행되는 GROUP BY처리에만 사용할 수 있습니다.
C. 임시 테이블을 사용하는 GROUP BY
GROUP BY가 필요한 경우 내부적으로 GROUP BY절의 컬럼들로 구성된 유니크 인덱스를 가진 임시 테이블을 만들어서 중복 제거와 집합 함수 연산을 수행합니다.
(5) DISTINCT 처리
A. SELECT DISTNCT...
SELECT 되는 레코드 중에서 유니크한 레코드만 가져오고자 하면 SELECT DISTNCT 형태의 쿼리문장을 사용합니다.
DISTNCT 자주 실수하는게, SELECT하는 레코드를 유니크하게 SELECT하는 것이지, 특정 칼럼만 유니크하게 조회하는게 아닙니다.
B. 집합 함수와 함께 사용된 DISTNCT
Distinct는 집합함수가 없는 select 쿼리에서는 Distinct는 조회하는 모든 칼럼의 조합이 유니크한 것만 가지고 오지만, 집합 함수 내에서 사용된 Distinct는 집합 함수의 인자로 전달된 칼럼값이 유니크한 것들로 가져옵니다.
집합함수없이 사용된 경우와 집합 함수 내에서 사용된 경우 쿼리의 결과가 조금씩 달라지기 때문에 차이를 정확하게 이해해야만 합니다.
(6) 내부 임시 테이블 활용
A. 메모리 임시 테이블과 디스크 임시 테이블
메모리는 TempTable이라는 스토리지 엔진을 사용하고, 디스크에 저장되는 임시 테이블은 InnoDB 스토리지 엔진을 사용하도록 개선되었습니다.
'internal_tmp_mem_storage_engine'시스템 변수를 이용해 메모리용 임시 테이블 'Memory'와 'TempTable'중에서 선택할 수 있습니다. 기본값은 'TempTable'입니다.
B. 임시 테이블이 필요한 쿼리
- order by와 group by에 명시된 칼럼이 다른 쿼리
- order by나 group by에 명시된 칼럼이 조인의 순서상 첫 번째 테이블이 아닌 쿼리
- distinct와 order by가 동시에 쿼리에 존재하는 경우 또는 distinct가 인덱스로 처리되지 못하는 쿼리
- union이나 union distinct가 사용된 쿼리
- 쿼리의 실행 계획에서 select_type이 derived인 쿼리
이 패턴의 쿼리는 MySQL 엔진에서 별도의 데이터 가공작업을 필요로해 내부 임시 테이블을 생성하는 케이스입니다.
C. 임시 테이블이 디스크에 생성되는 경우
- union이나 union all에서 select되는 칼럼 중에서 길이가 512바이트 이상인 크기의 컬럼이 있는 경우
- group by나 distinct 칼럼에서 512바이트 이상인 크기 칼럼이 있는 경우
- 메모리 임시 테이블의 크기가 tmp_table_size 또는 max_heap_table_size 시스템 변수보다 크거나 temptable_max_ram 시스템 변수 값보다 큰 경우
위 경우에는 메모리 임시 테이블을 사용할 수 없고 디스크 기반의 임시 테이블을 사용합니다.
D. 임시 테이블 관련 상태 변수
임시테이블이 디스크에 생성됐는지 메모리에 생성됐는지 확인하려면 'SHOW SESSION STATUS LIKE 'Created_tmp%';)를 확인해보면 됩니다.
'Created_tmp_tables' : 쿼리의 처리를 위해 만들어진 내부 임시 테이블의 개수르 ㄹ누적한느 상태 값입니다. 이 값은 내부 임시 테이블이 메모리에 만들어졌는지 디스크에 만들어졌는지 구분하지않고 모두 누적합니다.
'Created_tmp_disk_tables' : 디스크에 내부 임시 테이블이 만들어진 개수만 누적해ㅓㅅ 가지고 있는 상태 값입니다.
3. 고급 최적화
옵티마이저가 실행 계획을 수립할 때 통계 정보와 옵티마이저 옵션을 결합해서 최적의 실행 게획을 수립하게 됩니다.
옵티마이저 옵션은 크게 '조인과 관련된 옵티마이저 옵션'과 '옵티마이저 스위치'로 구분할 수 있습니다.
(1) 옵티마이저 스위치 옵션
'optimizer_switch' 시스템 변수를 이용해서 제어합니다.
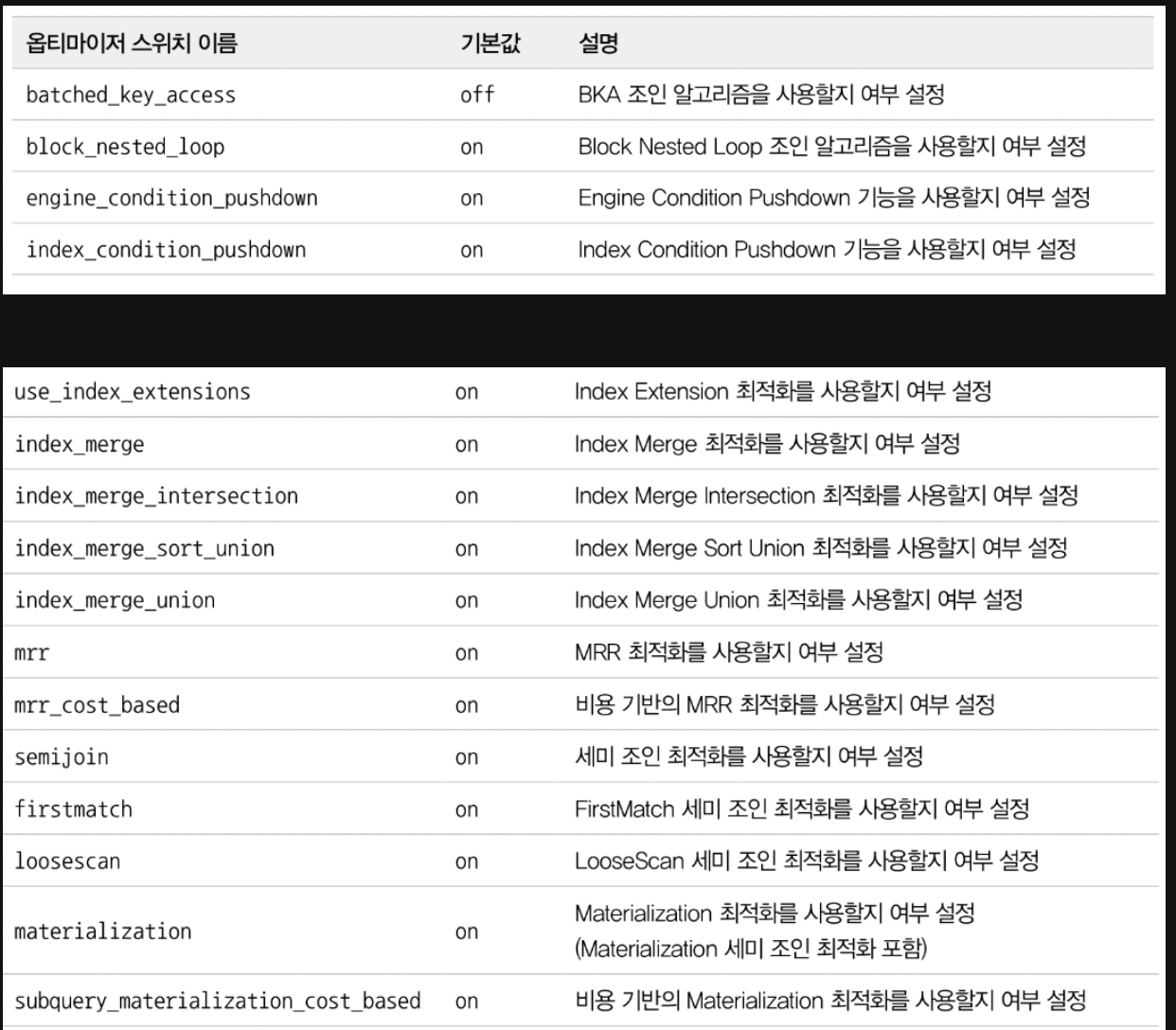
A. MRR과 배치 키 액세스(mrr & batched_key_access)
B. 블록 네스티드 루프 조인
MySQL에서 사용되는 대부분 조인은 네스티드 루프 조인입니다. 조인의 연결 조건이 되는 칼럼에 모두 인덱스가 있는 경우 사용되는 조인 방식입니다.
네스티드 루프 조인의 경우 이중반복문 처럼 동작합니다. 이 네스티드 루프 조인과 블록 네스티드 루프 조인의 차이는 '조인 버퍼'가 사용되는지 여부와 '조인에서 드라비빙 테이블과 드리븐 테이블이 어떤 순서로 조인되느냐' 입니다.
'조인 버퍼'란 드리븐 테이블의 풀 테이블 스캔이나 인덱스 풀 스캔을 피할 수 없다면 옵티마이저는 드라이빙 테이블에서 읽은 레코드를 메모리에 캐시한 후에 드리븐 테이블과 메모리 캐시를 조인하는 형태로 처리합니다. 이때 사용되는 메모리 캐시를 의미합니다. 조인이 완료되면 조인 버퍼는 바로 해제됩니다. 이때 조인 버퍼가 사용되는 조인에서 결과의 정렬 순서가 흐트러질 수 있습니다.
C. 인덱스 컨디션 푸시다운
'index_condition_pushdown=on'
(중요)
D. 인덱스 확장
'use_index_extensions' 옵티마이저 옵션은 InnoDB 스토리지 엔진을 사용하는 테이블에서 세컨더리 인덱스에 자동으로 추가된 프라이머리 키를 활용할 수 있게 할지를 결정하는 옵션입니다.
E. 인덱스 머지
인덱스를 이용해서 쿼리를 실행하는 경우에는 대부분 옵티마이저는 테이블별로 하나의 인덱스만 사용하도록 실행계획을 수립합니다. 인덱스 머지 실행 계획을 사용하면 하나의 테이블에 대해 2개 이상의 인덱스를 이용해서 쿼리를 처리합니다.
3개의 세부 실행 계획으로 나눌 수 있습니다.
-
인덱스 머지 : 교집합(index_merge_intersection)
-
인덱스 머지 : 합집합(index_merge_union)
or연산자로 연결된 경우에 사용되는 최적화
MySQL 서버는 두 집합에서 하나씩 가져와 서로 비교하면서 프라이머리 키에 칼럼의 값이 중복된 레코드들을 정렬 없이 걸래낼 수 있습니다. 이렇게해서 정렬된 두 집합의 결과를 하나씩 가져와서 중복제거를 수행할 때 사용된 알고리즘을 '우선순위 큐'라고 합니다. -
인덱스 머지 : 정렬 후 합집합(index_merge_sort_union)
인덱스 머지 작업을 하는 도중에 결과의 정렬이 필요한 경우 'Sort union'알고리즘을 사용합니다 -
세미 조인(semijoin)
다른 테이블과 실제 조인을 수행하지는 않고, 다른 테이블에 조건에 일치하는 레코드가 있는지 없는지만 체크하는 형태의 쿼리를 세미 조인이라고 합니다. -
테이블 풀-아웃(Table Pull-Out)
Table pullout최적화는 세비 조인의 서브쿼리에 사용된 테이블을 아우터 쿼리로 끄집어낸 후에 쿼리를 조인 쿼리로 재작성하는 형태의 최적화입니다. -
퍼스트 매치(firstmatch)
IN(subquery) 형태의 세미 조인을 EXIST(subquery) 형태로 튜닝한 것과 비슷한 방법으로 실행됩니다. -
루스 스캔(loosescan)
-
구체화(Materialization)
세미 조인에 사용된 서브 쿼리를 통째로 구체화해서 최적화한다는 의미입니다. -
중복 제거(Duplicated Weed-Out)
Duplicate WeedOut은 세미 ㅈ인 서브쿼리를 일반적인 INNER JOIN 쿼리로 바꿔서 실행하고 마지막에 중복된 레코드를 제거하는 방법으로 처리되는 최적화 알고리즘입니다.
- 서브쿼리가 상관 서브쿼리라고 하더라도 사용할 수 있는 최적화
- 서브쿼리가 GROUP BY나 집합 함수가 사용된 경우에 사용될 수 없습니다.
- Duplicate Weedout은 서브쿼리의 테이블을 조인으로 처리하기 때문에 최적화할 수 있는 방법이 많습니다.
-
컨디션 팬아웃(condition_fanout_filter)
-
파생 테이블 머지(derived_merge)
-
인비저블 인덱스(use_invisible_indexes)
-
스킵 스캔(skip_scan)
-
해쉬 조인(hash_join)
해시 조인은 첫 번째 레코드를 찾는 데는 시간이 많이 걸리지만 최종 레코드를 찾는 데까지 시간이 덜 걸립니다. 그래서 '최고 스루풋' 전략에 적합합니다.
해시 조인은 '빌드 단계'와 '프로브 단계'로 나뉘어 처리됩니다.
- 빌드 단계 : 조인 대상 테이블 중에서 레코드 건수가 적어서 해시 테이블로 만들기에 용이한 테이블을 골라서 메모리에 해시 테이블을 생성하는 작업을 수행합니다.
- 나머지 테이블의 레코드를 읽어서 해시 테이블의 일치 레코드를 찾는 과정을 의미합니다.
- 인덱스 정렬 선호
옵티마이저는 Order by 또는 Group by를 인덱스를 사용해서 처리 가능한 경우 쿼리 실행 계획에서 인덱스의 가중치를 높이 설정해서 실행
(2) 조인 최적화 알고리즘
A. Exhaustive 검색 알고리즘
B. Greedy 검색 알고리즘
-
전체 N개의 테이블 중에서 optimizer_search_depth 시스템 설정 변수에 정의된 개수의 테이블로 가능한 조인 조합을 생성
-
1번에서 생성된 조인 조합 중에서 최소 비용의 실행 계획 하나를 선정
-
2번에서 선정된 실행 계획의 첫 번째 테이블을 '부분 실행 계획'의 첫 번째 테이블로 선정
-
전체 N-1 개의 테이블 중에서 optimizer_search_depth 시스템 설정 변수에 정의된 개수의 테이블로 가능한 조인 조합 생성
-
4번에서 생성된 조인 조합들을 하나씩 3번에서 생성된 '부분 실행 계획'에 대입해 실행 비용을 계산
-
5번의 비용 계산 결과, 최적의 실행 계획에서 두 번째 테이블을 3번에서 생성된 '부분 실행 계획'의 두 번째 테이블로 선정
-
남은 테이블이 모두 없어질 때까지 4-6번 과정을 반복 실행 '부분 실행 계획'에 테이블의 조인 순서를 기록
-
최종적으로 '부분 실행 게획'이 테이블의 조인 순서로 결정됩니다
4. 쿼리 힌트
(1) 인덱스 힌트
인덱스 힌트느느 SELECT 명령과 UPDATE 명령에서만 사용 할 수 있습니다.
A. STRAIGHT_JOIN
STRAIGHT_JOIN은 SELECT, UPDATE, DELETE 쿼리에서 여러 개의 테이블이 조인되는 경우에 조인 순서를 고정하는 역할을 합니다.
-
USE INDEX / FORCE INDEX / IGNORE INDEX
인덱스 힌트는 사용하려는 인덱스를 가지는 테이블 뒤에 힌트를 명시해야합니다.
- USE INDEX : 자주 사용되는 인덱스 힌트
- FORCE INDEX : USE INDEX보다 옵티마이저에게 미치는 영향이 더 강한 힌트입니다.
- IGNORE INDEX : 반대로 특정 인덱스를 사용하지 못하게하는 용도로 사용되는 힌트입니다. -
SQL_CALC_FOUND_ROWS
MySQL의 LIMIT을 사용하는 경우, LIMIT을 만족하는 만큼 레코드를 찾으면 검색작업을 멈춥니다. 하지만 SQL_CALC_FOUND_ROWS는 끝까지 검색을 수행합니다.
B. 옵티마이저 힌트
- 옵티마이저 힌트 종류
- 인덱스 : 특정 인덱스의 이름을 사용할 수 있는 옵티마이저 힌트
- 테이블 : ㅋ특정 테이블의 이름을 사용할 수 있는 옵티마이저 힌트
- 쿼리 블록 : 특정 쿼리 블록에 사용할 수 있는 옵티마이저 힌트로서, 특정 쿼리 블록으 ㅣ이름을 명시하는게 아니라 힌트가 명시된 쿼리 블록에 대해서 영향을 미치는 옵티마이저 힌트
- 글로벌 : 전체 쿼리에 대해 영향을 미치는 힌트
-
MAX_EXECUTION_TIME
옵티마이저 힌트 중에서 유일하게 쿼리 실행계획에 영향을 미치지않는 힌트, 단순히 쿼리의 최대 실행 시간을 설정하는 힌트입니다 -
SET_VAR
SET_VAR 힌트는 실행 계획을 바꾸는 용도뿐만 아니라 조인 버퍼나 정렬용 버퍼의 크기를 일시적으로 증가시켜 대용량 처리 쿼리 성능을 향상시키는 용도로 사용할 수 있습니다. -
SEMIJOIN & NO_SEMIJOIN
-
SUBQUERY
서브쿼리 최적화는 세미 조인 최적화가 사용되지 못할 때 사용하는 최적화 방법입니다. -
BNL & NO_BNL & HASHOJOIN & NO_HASHJOIN
-
JOIN_FIXED_ORDER & JOIN_ORDER & JOIN_PREFIX & JOIN_SUFFIX
- JOIN_FIXED_ORDER : STRAIGHT_JOIN 힌트와 동일하게 FROM 절의 테이블 순서대로 조인을 실행하게 하는 힌트
- JOIN_ORDER : FROM 절에 사용된 테이블의 순서가 아니라 힌트에 명시된 테이블의 순서대로 조인을 실행하는 힌트
- JOIN_PREFIX : 조인에서 드라이빙 테이블만 강제하는 힌트
- JOIN_SUFFIX : 조인에서 드리븐 테이블만 강제하는 힌트
-
MERGE & NO_MERGE
-
INDEX_MERGE & NO_INDEX_MERGE
하나의 테이블에 대해 여러 개의 인덱스를 동시에 사용하는 걸 INDEX MERGE라고 합니다. -
NO_ICP
-
SKIP_SCAN & NO_SKIP_SCAN
인덱스 스킵 스캔 인덱스의 선행 칼럼에 대한 조건이 없어도 옵티마이저가 해당 인덱스를 사용할 수 있게 해주는 최적화 기능입니다. -
INDEX & NO_INDEX
