
지난 시간에 알고리즘을 공부하는 데에는 알고리즘의 효율성을 분석하는 것도 포함된다고 말씀 드렸습니다. 이번 시간에는 알고리즘의 효율성을 분석할 수 있도록 알고리즘 평가법에 대해 배워보도록 하겠습니다.
⏰ 평가의 두 기준: 시간 vs. 공간
만약 우리에게 주어진 시간이 무한대거나 컴퓨터의 성능이 무한대로 좋다면 효율적인 알고리즘을 고안할 필요가 없을 것입니다. 그러나 현실적으로 우리에게 주어진 자원은 한정되어 있습니다. 따라서, 알고리즘을 공부할 때 신경 써야 하는 것은 시간과 공간입니다.
현대인들은 시간을 매우 중요시합니다. 인터넷을 할 때도 조금만 렉이 걸리면 화를 내는 사람들이 많죠? 이는 영화 스트리밍이나 어플을 다운로드 받을 때도 마찬가지입니다.
그렇다면 공간은 왜 중요한 걸까요? 엄밀히 말하면 지금 말하고자 하는 공간의 개념은 컴퓨터의 저장공간인 메모리를 말합니다. 통상 컴퓨터의 메모리를 적게 사용할수록 좋은 프로그램이라고 인정받을 수 있습니다.
시간과 메모리 둘 다 중요하지만 굳이 둘 중 하나를 고르자면 시간이 더 중요하다고 말할 수 있습니다. 용량은 돈을 줘서라도 늘릴 수 있지만 시간은 돈으로 살 수 없으니까요.
그럼 지금부터 시간과 공간에 따른 알고리즘 평가법에 대해 알아봅시다.
⏰ 시간 복잡도
우리가 원하는 것은 문제를 빨리 해결하는 알고리즘입니다. 그럼 특정 알고리즘이 얼마나 빠르게 프로그램을 동작시키는지 어떻게 확인할 수 있을가요? 프로그램을 돌리고 시간을 재면 되는 걸까요? 그렇지 않습니다.
같은 알고리즘이라도 컴퓨터 환경에 따라 이를 테면 컴퓨터 사양이 낮다든지, 무거운 프로그램을 돌리고 있다든지, 느린 프로그래밍 언어를 사용한다든지 하면 프로그램을 느리게 동작시키기 때문입니다.
프로그램이 돌아가는 시간을 기준으로 체크하게 되면 외부 환경에 따라 영향을 받는 요인이 너무 많기 때문에 적합하지 않습니다. 따라서, 컴퓨터 과학에서는 단순히 시간을 재는 것이 아니라 시간 복잡도(Time Complexity)라는 개념을 사용합니다.
시간 복잡도는 데이터가 많아질수록 걸리는 시간이 얼마나 급격히 증가하는가를 따집니다. 예시를 한 번 들어볼까요?
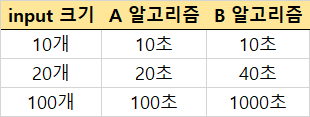
위 사례를 보면 같은 input을 돌리는데 A 알고리즘에 비해 B 알고리즘이 input 크기가 커질수록 걸리는 시간이 급격하게 증가합니다. B와 같은 알고리즘을 시간 복잡도가 큰 알고리즘이라고 하고 반대로 A와 같은 알고리즘을 시간 복잡도가 작은 알고리즘이라고 합니다.
그리고 일반적으로 시간 복잡도가 작은 알고리즘이 더 빠른 알고리즘이고 시간 복잡도가 큰 알고리즘을 더 느린 알고리즘이라고 합니다.
⏰ 거듭 제곱과 로그
시간 복잡도를 계산할 때는 약간의 수학적인 개념이 필요한데요. 학창 시절에 이미 배운 개념이지만 너무 오래돼서 까먹었을 수도 있기 때문에 다시 한 번 복습해보도록 합시다.
우리에게 필요한 두 가지 개념은 거듭 제곱과 로그입니다.
먼저, 거듭 제곱부터 보도록 하죠. 익히 알다시피 거듭 제곱의 지수는 밑을 곱한 횟수를 뜻합니다. 예컨대, 2를 세 번 곱하면 지수는 3이 되죠. 그렇다면 지수가 0이거나 -1일 때는 뭘 뜻하는 걸까요?
2^3 = 2 * 2 * 22의 세 제곱과 2의 제곱은 어떤 관계일까요? 8과 4를 생각해보면 쉽습니다. 8을 2로 나눈값이 4죠? 그렇다면 2의 0제곱은 2의 1제곱인 2를 2로 나눈 값 1입니다. 그리고 2의 -1제곱은 1을 2로 나눈 2분의 1이 되겠죠.
2^1 = 2
2^0 = 1
2^-1 = 1/2그럼 이번에는 로그를 배워봅시다. 로그는 쉽게 말해 거듭 제곱의 반대 개념이라고 생각하시면 됩니다.
logaB = x여기서 a는 밑수를, B는 진수를 뜻하고 '로그 a의 B'라고 부르시면 됩니다. 로그를 구하기 위해서는 이런 질문을 하면 됩니다. 'a를 몇 번 곱해야 B가 나올 수 있을까?'
예를 들어 log(2)8은 3입니다. 2를 세 번 곱해야 8이 나오기 때문이죠. 마찬가지로 log(3)27도 3입니다. 3을 세 번 곱해야 27이 나오기 때문이죠.
다시 말해, 로그는 'B를 a로 몇 번 나누어야 1이 되는가'를 구하는 개념입니다. 특히, 컴퓨터 알고리즘을 풀 때에는 밑 수가 2인 경우가 많습니다.
이는 'B를 몇 번 반토막 내야 1이 나오는가'로 변형해서 생각할 수 있습니다. 예컨대, 길이가 16인 리스트가 주어졌다면 4번을 반토막 해야 1개의 리스트가 될 수 있죠.
반토막이라는 개념이 익숙하죠? 아마 저번 시간에 배운 이진 탐색에서 활용했던 방법과 유사하기 때문일 겁니다. 이처럼 '이진'은 컴퓨터 알고리즘에서 자주 활용되는 방법입니다.
지금처럼 밑 수가 2인 경우에는 줄여서 'lg16 = 4'로 표현합니다.
⏰ 1부터 n까지의 합
시간 복잡도에서 활용되는 수학적 개념을 한 가지 더 배워봅시다. 바로 1부터 n까지의 합을 구하는 건데요.
일단 1부터 n까지의 합을 t로 둡시다.
T = 1 + 2 + 3 + ... + (n-1) + n여기서 트릭 하나를 쓸 겁니다. 우선, 위 식을 반대로 써보겠습니다.
T = n + (n-1) + ... + 3 + 2 + 1이제 위 식과 아래 식을 한 번 더해 봅시다. 그럼 모든 항의 값이 n+1이 되는데요. 항의 개수가 n개이므로 2T는 (n+1)을 n과 곱한 것과 같습니다. 따라서, T를 구하면 다음과 같습니다.
T = n(n+1)/2 # 1부터 n까지의 합⏰ 점근 표기법
앞서 알고리즘의 복잡도는 인풋의 크기에 따라 달라진다고 했습니다. 인풋의 크기가 커질수록 알고리즘이 실행되는데 더 오래 걸립니다.
알고리즘이 실행되는데 소요되는 시간을 인풋 크기에 대한 수식으로 나타낼 수 있습니다. 예를 들어, 알고리즘의 인풋이 리스트라면 인풋의 크기는 리스트의 길이로 나타낼 수 있습니다.
리스트의 길이를 n으로 두면 알고리즘의 소요 시간은 '10n + 20' 혹은 '3n^2 + 4n + 128', '10lgN + 30'과 같이 나올 수 있습니다. 수식에 있는 숫자들은 컴퓨터의 환경에 따라 달라집니다. 이 말은 곧, 수식만 가지고는 알고리즘을 표현하기가 부족하다는 것입니다.
따라서, 컴퓨터 과학자들은 한 가지 약속을 합니다. '점근 표기법'이라는 개념으로 말이죠. 먼저, 예시부터 봅시다.
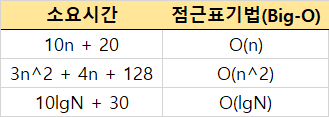
여기서 O는 'Big-O'라고 부릅니다.
첫번째 수식부터 봅시다. 10과 20 중 n에 대한 영향력이 큰 것은 10입니다. 따라서, 상수 20은 없애줍니다. 10n을 두고 봤을 때, 앞에 10도 n에 큰 영향을 주지 않는 것으로 판단되므로 없애줍니다. 결과적으로 n만이 남고 이를 점근 표기법으로 나타내면 'Big-O of n 알고리즘'이라고 합니다.
두번째 수식도 마찬가지입니다. n에 영향력이 가장 큰 곳부터 찾습니다. 아무래도 n 제곱이 그냥 n보다는 더 크겠죠? 따라서 n 제곱 부분만 남깁니다. n 제곱 앞에 수도 n에 별다른 영향을 주지 않는 것으로 판단되어 없애줍니다. 이를 점근 표기법으로 나타내면 'Big-O of n제곱 알고리즘'이라고 합니다.
마지막 수식도 봅시다. n에 영향력을 주지 않는 상수 30을 지우고 10logN에서 10도 제외시킵니다. 그럼 'Big-O of 로그n 알고리즘'으로 표현할 수 있습니다.
그런데 왜 이런 식으로 표현하는 걸까요? 점근 표기법의 핵심은 n이 엄청 크다고 가정하는 것입니다. 사실 n이 별로 크지 않으면 비효율적인 알고리즘을 쓰더라도 그리 크게 문제가 되지 않습니다.
n이 10일 때를 가정하여 좋은 알고리즘은 0.000001초 정도, 나쁜 알고리즘은 0.0001초 정도로 시간이 소요된다고 칩시다. 인간이 느끼기에는 둘 사이의 시간적 차이가 치명적인 문제를 일으킬 만큼 크다고는 판단되지 않습니다.
따라서, 곤란하다고 느낄 정도로 큰 시간적 차이를 내기 위해서는 n이 엄청 큰 숫자여야 하는 것입니다. n이 엄청 큰 경우가 되어서야 알고리즘의 중요성을 실감하게 되니까요.
또 하나 예를 들어봅시다. 앞서 '3n^2 + 4n + 128'이라는 수식을 썼었는데요. 이 수식을 '3n^2'와 '4n+128'으로 나누어 봅시다. 숫자가 커질수록 앞 부분은 급격하게 수가 커지는 반면 뒷 부분은 상대적으로 적게 증가합니다.
n이 10일 때는 300과 168로 둘 사이에 큰 차이가 나지 않지만 n이 10000일 때는 앞 부분은 '3억'이 되는 반면에 뒷 부분은 '4만 128'이 되어, 뒷 부분에 비해 앞 부분이 증가하는 폭이 훨씬 커집니다.
그래프 상으로도 숫자가 커질수록 앞 부분은 우상향 곡선을 그리지만 뒷 부분은 점차 수평 선에 가까워집니다. 이로 미루어볼 때, n값에 크게 영향을 주는 것은 앞 부분인 n제곱이라는 것이죠.
그럼 '0.01n^2 + 9000n + 128000'과 같은 경우는 어떨까요? n이 적당히 작은 경우에는 뒷 부분이 앞 부분에 비해 큰 수가 나올 수 있습니다. 그러나 이 수식조차 n이 1억처럼 엄청나게 큰 수가 되면 결국에는 앞 부분이 뒷 부분을 추월하게 되어 있습니다.
따라서, '어떤 식이든 결과적으로 앞 부분이 뒷 부분에 비해 n에 가장 큰 영향력을 주게 되어 있으니 뒷 부분은 그냥 무시하자'가 된 것이죠. 추월 시점만 다를 뿐 결국에는 앞 부분이 무서운 속도로 계속 더 커질테니까요.
점근 표기법의 두번째 핵심은 절대적인 시간보다 성장성이 중요하다는 것입니다. 따라서, n앞의 숫자도 신경쓰지 않기로 했습니다. 단순히 n만 두고 보더라도 성장성을 충분히 확인할 수 있으니까요.
⏰ 점근 표기법의 의미
점근 표기법을 더 직관적으로 이해할 수 있도록 자세히 설명해 보겠습니다.
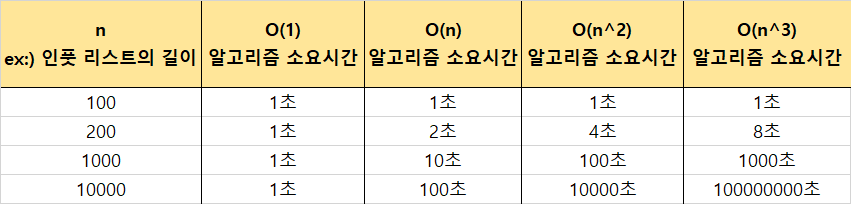
n을 기준으로 봅시다. n이 1일 때는 인풋의 크기에 상관없이 소요시간이 1초로 동일합니다. 그러나, n이 상수가 되면 인풋의 크기가 늘어남에 따라 소요시간이 배로 늘어납니다.
인풋 크기가 n인 경우, 인풋 크기가 두 배로 늘어나면 소요시간도 두 배, 열 배로 늘어나면 소요시간도 열 배로 늘어납니다.
인풋 크기가 n 제곱인 경우, 인풋 크기가 두 배로 늘어나면 소요시간은 2의 제곱인 네 배로 늘어나고 열 배로 늘어나면 소요시간은 10의 제곱인 백 배가 늘어납니다.
마지막으로 인풋 크기가 n 세 제곱인 경우, 인풋 크기가 두 배로 늘어나면 소요 시간은 2의 세 제곱인 여덟 배로 늘어나고 열 배로 늘어나면 소요 시간은 10의 세 제곱인 천 배가 늘어납니다.
이런 식으로 나아가다보면 인풋의 크기가 늘어날 때마다 소요 시간이 급격하게 증가합니다.
그래프 상으로 보면 차이를 더 직관적으로 볼 수 있습니다.
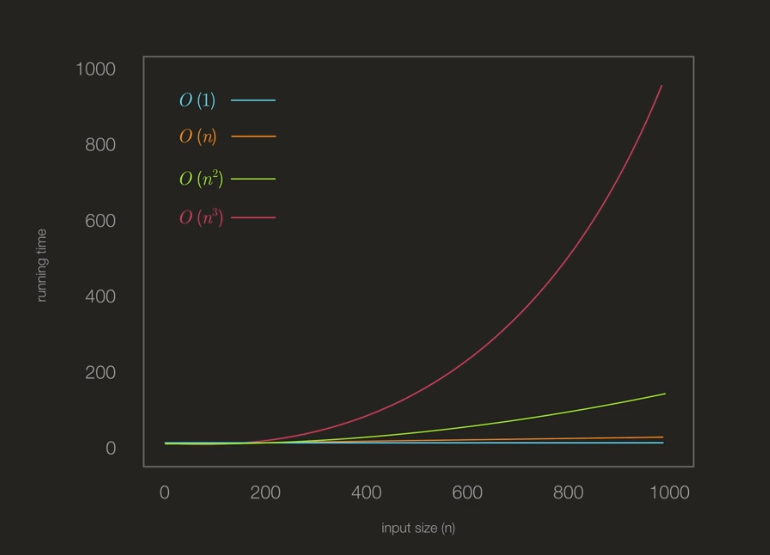
다른 세 그래프에 비해 n 세 제곱 그래프의 경우 인풋의 크기가 커짐에 따라 소요 시간이 급격하게 증가합니다.
이번에는 조금 다른 가정을 해봅시다. 만약 소요 시간이 가장 적게 걸리는 알고리즘을 가장 오래된 컴퓨터에서 구동하고 소요 시간이 가장 오래 걸리는 알고리즘을 최신 컴퓨터에서 구동하면 결과에 차이가 있을까요?
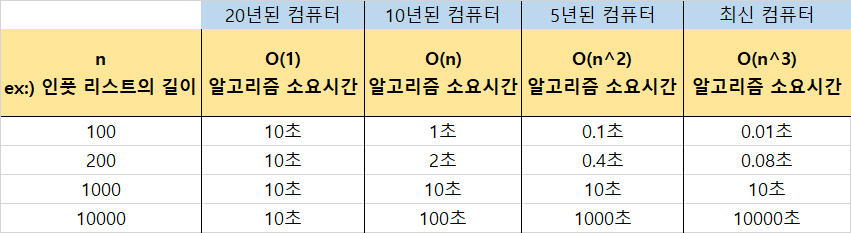
인풋 리스트가 짧을 때는 'Big-O of 1 알고리즘'의 소요 시간이 가장 오래 걸리는 듯 했으나 리스트의 길이가 길어질수록 소요 시간에서 우위를 점하는 걸 볼 수 있습니다.
반대로 최신 컴퓨터에서 구동한 'Big-O of n 세 제곱 알고리즘'의 소요 시간은 리스트의 길이가 짧을 때는 가장 빨랐지만 리스트의 길이가 길어질수록 소요 시간이 급격히 증가하며 결국에는 위 표와 같은 결과를 보이게 됩니다.
이로 미루어 볼 때, 컴퓨터 사양이 아무리 좋아도 혹은 빠른 프로그래밍 언어로 코드를 짜더라도 결국 알고리즘이 별로면 소요 시간에 있어 한계가 있다는 것을 알 수 있습니다.
⏰ 탐색 알고리즘 평가하기
이제 점근 표기법을 기반으로 탐색 알고리즘을 평가해보겠습니다.
❗ 선형 탐색 알고리즘 평가
지난 시간에 배웠던 선형 탐색 알고리즘을 구현한 코드 중 하나를 보여드리겠습니다.
def linear_search(value, my_list):
i = 0
n = len(my_list)
while i < n:
if my_list[i] == value:
return i
i += 1
return -1여기서 변수를 선언한 첫 번째 줄은 리스트의 크기와 상관 없으므로 'Big-O of 1 알고리즘'입니다. 두 번째 줄도 마찬가지로 len 함수가 리스트의 크기에는 별 다른 영향을 주지 않기 때문에 'O(1)'로 표기할 수 있습니다.
while의 반복문에서 while문을 딱 한 번 돌 때에는 리스트의 크기에 영향을 주지 않습니다. 값을 반환하는 리턴 명령어도 마찬가지죠. 따라서 이들 모두 'O(1)'입니다.
그런데 while 반복문의 내부는 좀 더 유심히 살펴볼 필요가 있습니다. 리스트의 크기에 관련이 있기 때문인데요. 여기서 우리는 두 가지 사례를 가정해볼 수 있는습니다. 먼저, 최고의 경우를 가정하여 원하는 값이 리스트의 첫 인덱스에 있다면 반복을 딱 한 번만 해도 되므로 'O(1)'입니다.
최악의 경우는 리스트에 원하는 값이 없을 때였죠? 그럼 반복문이 리스트의 길이만큼 돌아야 하므로 반복 횟수는 리스트의 크기 n이 됩니다. 그리고 총 소요 시간을 구하려면 'O(1)'에 반복 횟수 n을 곱해야 합니다. 따라서, 최악의 경우 반복문의 점근 표기법은 'O(n)'이 되겠네요.
최선의 경우, 총 걸리는 시간은 O(1)을 네 번 더한 O(4)가 됩니다. 그런데 O(4)는 O(1)과 큰 차이가 없기 때문에 O(1)로 표기하여도 무방합니다.
최악의 경우에는 총 걸리는 시간이 O(1)을 세 번 더하고 O(n)을 더하여 O(n+3)이 됩니다. 마찬가지로 n 뒤의 연산은 n 값에 큰 영향을 주지 못하므로 그냥 O(n)으로 표기하면 됩니다.
❗ 이진 탐색 알고리즘 평가
그럼 이진 탐색 알고리즘도 평가해볼까요? 코드 하나를 보여드리겠습니다.
def binary_search(value, my_list):
first_index = 0
last_index = len(my_list) - 1
while first_index <= last_index:
middle_index = (first_index + last_index) // 2
if my_list[middle_index] == value:
return middle_index
elif value < my_list[middle_index]:
last_index = middle_index - 1
else:
start_index = middle_index + 1
return None위 코드에서 리스트 크기와 상관 없는 곳은 변수 선언 부분, while을 딱 한 번 돌 때의 수행 부분, 그리고 리턴 명령어 부분입니다. 이들은 모두 'O(1)'입니다.
이제 while문 안에서 경우를 나누어 봅시다. 먼저, 최고의 경우는 첫번째 시도에서 값을 발견했을 때입니다. 총 걸리는 시간을 계산하면 'O(1)*4'로 'O(4)'가 나오며 이는 점근 표기법 규칙에 따라 'O(1)'이 됩니다.
최악의 경우는 리스트 안에서 원하는 값을 발견 못했을 때입니다. 이진 탐색은 선형 탐색과 달리 반복문을 돌 때마다 리스트의 크기를 반씩 줄입니다. 이에 따라 반복 횟수를 lgn으로 나타낼 수 있고 이 부분을 점근 표기법으로 나타내면 'O(lgn)'이 됩니다.
결과적으로 최악의 경우에 이진 탐색 알고리즘의 총 소요시간은 'O(lgn) + O(3)'이 되지만 점근 표기법 상 'O(lgn)'이 됩니다.
지금까지 정리한 내용을 요약하면 다음과 같습니다.
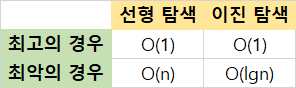
이렇게만 보면 둘 다 최고의 경우 동일하게 O(1)이므로 차이를 모르겠죠? 하지만 통상 알고리즘을 평가할 때는 너무 긍정적인 경우보다는 보수적인 경우를 가정하고 접근하는 경향이 있습니다. 그래야 안전하기 때문입니다.
그래서 지금부터는 최악의 경우를 기준으로 두고 선형 탐색을 'Big-O of n 알고리즘'으로, 이진 탐색을 'Big-O of 로그 n 알고리즘'으로 부르겠습니다.
이번 시간에는 알고리즘의 평가하는 기준 중 시간 복잡도와 평가에 필요한 몇 가지 수학적 개념, 그리고 점근 표기법에 대해 알아보았습니다. 그리고 이를 바탕으로 두 탐색 알고리즘을 평가해봤죠. 다음 시간에는 알고리즘 평가 시 주의 사항과 주요 시간 복잡도, 그리고 공간 복잡도에 대해 더 알아보겠습니다.
* 이 자료는 CODEIT의 '알고리즘의 정석' 강의를 기반으로 작성되었습니다.