
🐼 Pandas
- DataFrame
- R의 핵심 역할
- 데이터 보관, 정리, 분석
- Python의 pandas 라이브러리의 기능
- Numpy와의 관계
- Numpy를 통해 pandas 라이브러리 제작
- Numpy의 기능 포함
- 데이터 정리
- 외부 데이터 읽고 쓰기
- 데이터 분석 / 시각화
- Pandas는 표 형식의 데이터를 다루는 것에 특화 됨
- Numpy는 빠른 연산에 특화 됨
🐼 DataFrame
- Pandas의 DataFrame
- 대부분의 데이터셋은 2차원 배열의 형태
- 2차원 형태의 데이터를 다루기 위한 자료형
- 표 형식의 데이터를 담는 자료형
- DataFrame의 구성
- 열(Column)
- 가로로 나열
- 데이터의 특징(예: 이름, 국적, 키)
- 행(Row/Index): 세로로 나열
- 레코드
- 각 레코드가 하나의 대상을 의미(예: 사람)
- 열(Column)
- Numpy Array와의 관계
- 일반적인 numpy array로부터 부가적인 기능을 추가한 것
- 부가 기능
- 인덱스 네이밍(번호가 아닌 이름 지정)
- 다양한 자료형 함께 사용 가능
- numpy array의 경우, 같은 자료형(숫자)만 가능
🐼 DataFrame 사용해보기
- 코드
import pandas as pd
two_dimensional_list = [['A', 30, 70], ['B', 50, 20], ['C', 60, 40]]
some_df = pd.DataFrame(two_dimensional_list)
some_df- 출력 결과
- 이름을 지어주지 않으면 인덱스 번호로 출력
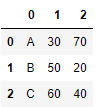
- 이름을 지어주지 않으면 인덱스 번호로 출력
- 결과 자료형 확인
type(some_df)pandas.core.frame.DataFrame- 네이밍
- 열 이름: columns 리스트 추가
- 행 이름: index 리스트 추가
some_df = pd.DataFrame(two_dimensional_list,
columns=['student', 'kor_score', 'eng_score'])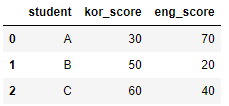
some_df.columnsIndex(['name', 'kor_score', 'eng_score'], dtype='object')- 자료형
- object: pandas에서 문자열 의미
- int64: 64비트 정수
- 같은 column 내에서는 같은 자료형
some_df.dtypes
🐼 DataFrame 사용해보기
- From list of lists, array of arrays, list of series
- 2차원 리스트나 2차원 numpy array로 DataFrame 생성 가능
- pandas Series를 담고 있는 리스트로도 가능
import numpy as np
import pandas as pd
two_dimensional_list = [['A', 30, 70], ['B', 50, 20], ['C', 60, 40]]
two_dimensional_array = np.array(two_dimensional_list)
list_of_series = [
pd.Series(['A', 30, 70]),
pd.Series(['B', 50, 20]),
pd.Series(['C', 60, 40]),
# 동일한 출력 결과
df1 = pd.DataFrame(two_dimensional_list)
df2 = pd.DataFrame(two_dimensional_array)
df3 = pd.DataFrame(lists_of_series) 0 1 2
0 A 30 70
1 B 50 20
2 C 60 40- From dict of lists, dict of arrays, dict of series
- Python 사전(dictionary)으로도 가능
- 사전의 key: column 이름
- 사전의 value: column에 해당하는 리스트, numpy array, pandas Series
pandas.Series: 1차원 데이터 프레임
import numpy as np
import pandas as pd
names = ['A', 'B', 'C']
kor_score = [30, 50, 60]
eng_score = [70, 20, 40]
dict1 = {
'name': names,
'kor_score': kor_scores,
'eng_score': eng_scores
}
dict2 = {
'name': np.array(names),
'kor_score': np.array(kor_scores),
'eng_score': np.array(eng_scores)
}
dict2 = {
'name': pd.Series(names),
'kor_score': pd.Series(kor_scores),
'eng_score': pd.Series(eng_scores)
}
# 동일한 출력 결과
df1 = pd.DataFrame(dict1)
df2 = pd.DataFrame(dict2)
df3 = pd.DataFrame(dict3)
print(df1)- From list of dicts
- 사전이 담긴 리스트로도 가능
import numpy as np
import pandas as pd
some_list = [
{'name': 'A', 'kor_score': 30, 'eng_score': 70},
{'name': 'B', 'kor_score': 50, 'eng_score': 20},
{'name': 'C', 'kor_score': 60, 'eng_score': 40}
]
df = pd.DataFrame(some_list)
print(df) kor_score eng_score name
0 30 70 A
1 50 20 B
2 60 40 C
🐼 Pandas의 데이터 타입
- dtypes
- 각 column이 어떤 데이터 타입을 보관하는지 확인할 수 있다
import pandas as pd
two_dimensional_list = [['A', 52, 64], ['B', 38, 76], ['C', 55, 89]]
some_df = pd.DataFrame(two_dimensional_list, columns=['name', 'kor_score', 'eng_score'])
print(some_df.dtypes)name object
kor_score int64
eng_score int64
dtype: object # 문자열- 한 Column 내에서는 모든 값이 동일한 데이터
- pandas의 dtype 목록
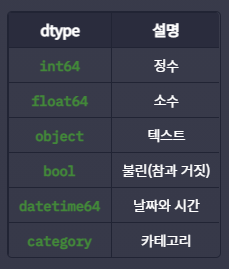
🐼 Pandas로 데이터 읽어들이기
- csv
- 데이터 분석에서 주로 활용되는 파일 확장자
- Comma-separated values
- 값들이 쉼표로 나뉘어져 있다
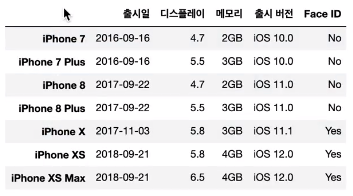
- csv 파일 예시
- 헤더(header)
- 컬럼 이름이 나열되어 있는 줄(첫번째 줄)
- 두번째 줄부터 실제 레코드
- 헤더(header)
,출시일,디스플레이,메모리,출시 버전,Face ID
iPhone 7,2016-09-16,4.7,2GB,iOS 10.0,No
iPhone 7 Plus,2016-09-16,5.5,3GB,iOS 10.0,No
iPhone 8,2017-09-22,4.7,2GB,iOS 11.0,No
iPhone 8 Plus,2017-09-22,5.5,3GB,iOS 11.0,No
iPhone X,2017-11-03,5.8,3GB,iOS 11.1,Yes
iPhone XS,2018-09-21,5.8,4GB,iOS 12.0,Yes
iPhone XS Max,2018-09-21,6.5,4GB,iOS 12.0,Yes- Python으로 csv 파일 읽어들이기
- read_csv 함수
- 파라미터는 데이터가 들어있는 경로
- read_csv 함수
import pandas as pd
iphone_df = pd.read_csv('data/iphone.csv')
iphone_df
type(iphone_df)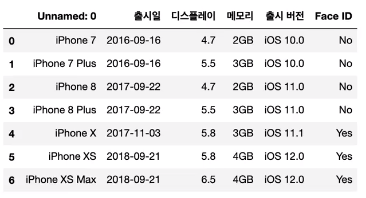
pandas.core.frame.DataFrame- 자동으로 헤더 인식
- 헤더가 없는 경우, read_csv의 파라미터로
header=None을 넘겨주어야 한다
- 헤더가 없는 경우, read_csv의 파라미터로
- 특정 column을 row 이름으로 지정하기
- read_csv의 파라미터로
index_col=0를 넘겨준다
- read_csv의 파라미터로
출처: CODEIT - 데이터 사이언스 입문
There's Only One Thing To Do: Learn All We Can