저번 시간에는 객체를 만드는 방법에 대해 배우며 인스턴스와 메소드 등 여러 개념을 익혔습니다.
이번 시간에는 Python으로 객체 지향 프로그래밍을 할 때, 알아 두어야 하는 것들에 대해 설명하고자 합니다.
🟪 순수 객체 언어, Python

우리가 Python으로 객체 지향 프로그래밍을 배우는 이유는 뭘까요? Python이 다른 언어에 비해 비교적 쉬워서이기도 하지만 Python이 순수 객체 언어이기 때문이기도 합니다. 이 말은 곧, Python의 모든 요소들이 객체라는 것을 의미합니다.
우리가 지금껏 써왔던 함수, 여러 자료형 등은 모두 어떤 클래스의 인스턴스에 해당합니다.
class User:
def __init__(self, name, id, password):
self.name = name
self.id = id
self.password = password
def say_hi(self):
print(f"안녕! 나는 {self.name}이야!")
user1 = User("타키탸키", "tataki26", "123456")지난 시간부터 쭉 봐왔던 코드입니다. User 클래스에 user1이라는 인스턴스를 생성했습니다. Python에는 type이라는 함수가 있는데 이 함수는 파라미터로 인스턴스를 받고 그 인스턴스가 어떤 클래스에 만들어졌는지를 알려줍니다.
print(type(user1))<class __main__.User>던더 main은 지금 실행되고 있는 파일을 나타냅니다. 따라서, 인스턴스를 type에 넣으면 해당 파일에 정의되어 있는 User 클래스가 실행되고 있음을 알려줍니다.
만약 평소에 쓰고 있는 자료형들을 type 함수에 넣으면 어떤 결과가 나올까요?
print(type(3)) # 정수
print(type("hi")) # 문자열
print(type([])) # 리스트
print(type({})) # 사전
print(type(())) # 튜플
print(type(print_hi)) # 함수<class 'int'>
<class 'str'>
<class 'list'>
<class 'dict'>
<class 'tuple'>
<class 'function'>이 자료형들은 모두 Python에서 기본으로 제공됩니다. 출력 결과를 보니 클래스 다음에 자료형의 이름이 나와있는데요. 이 말은 곧, 자료형들이 어떤 클래스의 인스턴스임을 의미합니다.
그런데 우리는 자료형의 이름으로 클래스를 생성한 적이 없습니다. 그럼에도 이러한 결과를 얻을 수 있는 이유는 Python의 개발자들이 사전에 이 자료형들을 가지고 미리 클래스를 만들었기 때문입니다.
예를 들어 '2'라는 수를 쓰면 이는 int 클래스로 만든 2를 나타낸 인스턴스가 생성된 것임을 뜻합니다. 함수 또한 function이라는 클래스의 인스턴스를 만든 것입니다.
사실 우리는 지금까지 개발자들이 만들어 놓은 인스턴스 메소드를 써왔습니다. 대표적인 예가 바로 리스트에 새로운 요소를 추가하는 append 메소드입니다. 이 메소드는 개발자들이 사전에 만들어 놓은 것으로 필요할 때 언제든 가져다가 사용할 수 있습니다.
이 외에도 사실상 Python에 있는 모든 것들은 특정 클래스의 인스턴스로 생성됩니다. Python 코드를 쓴다는 것은 곧, 객체를 생성한다는 뜻이며 이러한 과정 자체가 객체 지향 프로그래밍에 해당합니다.
🟪 가변 vs. 불변 타입
앞서 가변형 자료형과 불변형 자료형을 배운 적이 있습니다. 이 개념은 객체에도 적용이 되는데요. 자료형이 곧 인스턴스이고 인스턴스와 객체는 유사한 개념이기 때문입니다.
Python의 객체는 가변 타입과 불변 타입으로 나누어집니다. 어떤 타입이냐에 따라 같은 상황에서도 다른 결과가 나오기 때문에 이러한 실수를 방지하려면 두 타입의 차이를 숙지하고 있어야 합니다.
쉽게 말해, 한번 생성한 인스턴스의 속성을 변경할 수 있으면 가변 타입 객체이고 변경할 수 없으면 불변 타입 객체입니다. 대표적인 가변 타입 객체는 리스트 클래스이고, 대표적인 불변 타입 객체는 튜플 클래스입니다.
mutable_object = [2, 4, 6]
immutable_object = (2, 4, 6)가변형 객체라는 이름의 변수에는 리스트를, 불변형 객체라는 이름의 변수에는 튜플을 넣어주었습니다.
mutable_object[1] = 8
print(mutable_object)리스트의 첫번째 인덱스 값을 8로 바꾸려는데요.
[2, 8, 6]성공적으로 잘 출력되었습니다.
immutable_object[1] = 8
print(immutable_object)마찬가지로 튜플의 요소도 바꿔보려는데요.
TypeError: 'tuple' object does not support item assignment
이번에는 에러 메세지가 뜹니다. 왜일까요? 그 이유는 바로 튜플이 불변 타입이기 때문입니다. 튜플은 한번 인스턴스를 생성하면 그 이후로는 속성을 바꿀 수 없습니다.
하지만 속성을 바꿀 수 없다는 것이 변수가 가리키는 객체 자체를 바꿀 수 없다는 뜻은 아닙니다.
immutable_object = (2, 4, 6)
immutable_object = (2, 8, 6)
print(immutable_object)(2, 8, 6)다음과 같이 요소를 바꾸지 않고 같은 변수명에 다른 값을 넣으면 해당 변수의 값이 바뀝니다. 이처럼 변수에 아예 새로운 인스턴스를 지정해주는 것은 문제가 되지 않습니다.
다시 말해, 같은 변수로 속성이 다른 튜플을 사용하고 싶으면 기존 튜플의 속성을 바꾸는 것이 아니라 새로운 튜플 인스턴스를 생성하고 해당 변수가 새로 생성된 인스턴스를 가리키게 하면 됩니다.
리스트의 경우에는 append 메소드를 사용하면 기존 리스트의 속성을 바꿀 수 있습니다.
my_list = []
my_list.append(2)
my_list.append(8)
my_list.append(6)
print(my_list)[2, 8, 6]Python에서 기본적으로 제공하는 자료형의 타입을 나누면 다음과 같습니다.
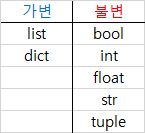
그렇다면 직접 만든 클래스는 어떤 타입에 속할까요? 바로 가변 타입에 속합니다. 따라서, 직접 만든 클래스로 인스턴스를 생성하면 새로운 인스턴스를 생성할 필요 없이 기존 인스턴스의 속성을 바꿀 수 있습니다.
🟪 절차 지향 vs. 객체 지향
객체 지향 프로그래밍이 등장하기 전에는 절차 지향 프로그래밍이 있었습니다. 두 프로그래밍 기법의 차이에 대해 알기 전에 절차 지향 프로그래밍의 예시를 봅시다.
def print_info(name, age, gender):
print(f"{name}를 소개합니다.")
print(f"{name}는 {age}살이고 {gender}입니다.")
def is_overage(age):
return age > 20
taki_name = "타키탸키"
taki_age = 21
taki_gender = "여자"
print_info(taki_naem, taki_age, taki_gender)
print(is_overage(taki_age))타키탸키를 소개합니다.
타키탸키는 21살이고 여자입니다.
True절차 지향 프로그래밍에는 '객체'라는 개념이 없습니다. 하지만 '함수'라는 개념은 있죠. 절차 지향 프로그래밍에서 함수는 순서대로 특정 명령어들을 실행하는 부분을 하나로 묶은 것입니다. 따라서, 절차 지향 프로그래밍의 정의는 프로그램에 필요한 동작을 함수라는 단위로 묶어서 사용하는 것입니다.
같은 코드를 객체 지향 프로그래밍으로 구현해보겠습니다.
class Person:
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
def print_info(self):
print(f"{name}를 소개합니다.")
print(f"{name}는 {age}살이고 {gender}입니다.")
def is_overage(self):
return age > 20
taki = Person("타키탸키", 21, "여자")
taki.print_info()
print(taki.is_overage())객체 지향 프로그래밍은 필요한 동작뿐만 아니라 연관된 데이터도 객체로 묶어서 하나의 클래스로 나타냅니다.
정리하자면, 프로그램 안에서 서로 관련된 동작들만을 묶어서 관리하는 절차 지향 프로그래밍과 달리 객체 지향 프로그래밍에서는 관련된 동작들을 관련된 데이터와 함께 묶어서 관리합니다.
두 기법의 차이는 크게 두 가지로 나뉩니다.
첫째로, 절차 지향 프로그램에는 프로그램에 필요한 데이터를 관련 있는 함수와 묶어서 관리하기 어렵습니다. 객체 지향 프로그래밍은 클래스가 있기 때문에 가능합니다.
둘째로, 절차 지향 프로그래밍은 프로그램을 단순히 명령어들을 순서대로 실행하는 것으로 봅니다. 반면, 객체 지향 프로그래밍에서 프로그램은 객체 간의 소통 과정이라고 했죠? 즉, 객체가 프로그램의 기본 단위가 되고 객체 속에는 서로 간련된 데이터(객체의 속성)와 동작(객체의 행동)이 모여있습니다.
두 방식 중 더 뛰어난 방식을 가리기는 어렵습니다. 프로그램의 용도에 따라 적합한 방식이 다르기 때문입니다. 만약 데이터와 동작의 연관성이 높고 객체 단위로 묶을 수 있다는 판단이 들면 객체 지향 프로그래밍을 선택하는 것이 좋습니다. 혹은 복잡한 프로그래밍일수록 객체 지향 프로그래밍을 선택하는 경우가 많습니다.
🟪 유용한 함수들
앞으로 자주 사용하게 될 유용한 함수들을 살펴봅시다.
❗ max, min 함수
print(max(3, 6, 4))
print(min(3, 6, 4))6
4max 함수는 파라미터 중 가장 큰 값을, min 함수는 파라미터 중 가장 작은 값을 반환해줍니다. 파라미터 개수는 가변적으로 원하는 수 만큼 넘겨줄 수 있습니다.
❗ sum 함수
int_list = [2, 4, 6]
int_tuple = (1, 3, 5)
int_dict = {3: "three", 6: "six", 9: "nine"}
print(sum(int_list))
print(sum(int_tuple))
print(sum(int_dict))12
9
18sum 함수는 리스트, 튜플, 사전에 있는 숫자 요소들의 합을 반환합니다. sum 함수에 사전형을 파라미터로 넘길 경우, key의 합을 리턴한다는 사실을 잊지마세요.
❗ ternary expression
condition = True
if condition:
condition_str = "good"
else:
condition_str = "not good"
print(condition_str)condition = True
condition_str = "nice" if condition else "not good"
print(condition_string)good위 코드와 아래 코드는 동일한 코드로 같은 결괏값을 반환합니다. 두 번째 코드의 두 번째 줄과 같은 구문은
- condition이 True이면 "good"이 되고
- False이면 "not good"이다
라는 의미를 가지고 있습니다. 이렇게 불린값에 따라 다른 값을 반환하는 구문을 ternary expression이라고 합니다. 이를 활용하면 if 조건문을 간단하게 나타낼 수 있습니다.
❗ list comprehension
my_list = [1, 3, 5, 7, 9]
squares_list = []
for x in my_list:
squares_list.append(x ** 2)
print(squares)my_list = [1, 3, 5, 7, 9]
squares = [x ** 2 for x in my_list]
print(squares)[1, 9, 25, 49, 81]위 코드와 아래 코드는 동일한 코드로 같은 결괏값을 반환합니다. list comprehension은 새로운 리스트를 만드는 간단한 방법인데요. 특정 리스트나 튜플을 바탕으로 리스트를 생성할 때,
- [] 안에 원하는 값을 반환해줄 식(x 2) 뒤**에
- for문을 써줍니다(for x in my_list)
이런 식으로 작성하면 my_list의 각 요소들을 제곱해준 값들로 이루어진 새로운 리스트가 생성됩니다.
❗ zfill 메소드
zfill 메소드는 문자열을 최소 몇 자리 이상을 가진 문자열로 바꿔줍니다. 이때, 모자란 부분이 있다면 왼쪽에 '0'을 채워줍니다. 예를 들어, "1".zfill(3)을 하면 "001"을 반환합니다.
반대로 설정된 자릿수보다 더 긴 문자열이면 그 문자열을 그대로 출력합니다. 예를 들어, "4444".zfill(2)라면 문자열 그대로 "4444"를 반환해주는 거죠.
이 메소드는 문자열을 예쁘고 통일감 있게 출력하고자 할 때 자주 사용됩니다.
print("1".zfill(4))
print("ab".zfill(8))0001
000000ab🟪 모듈
Python 기초 챕터에서 모듈에 대해 배웠습니다. 간단히 복습해볼까요?
모듈(module)은 변수, 함수, 클래스 등을 모아놓은 파일입니다. 모듈은 다른 곳에서 가져다 쓸 수 있다는 특징이 있는데요.
caculator.py라는 모듈을 만들고 다른 파일에서 써보겠습니다.
def sum(x, y):
return x + y
def difference(x, y):
return x - y이제 test.py라는 파일을 만들어 방금 만든 모듈을 사용해보겠습니다. 모듈 안에 있는 변수, 함수, 클래스를 사용하려면 test.py 파일 맨 위에 다음과 같이 적으면 됩니다.
from 모듈 이름 import 불러올 변수/함수/클래스 이름이때, 모듈의 이름은 파일명에서 확장자(.py)를 빼고 적으면 됩니다. 이제 difference 함수를 호출해봅시다.
from caculator import difference
print(difference(6, 3))caculator.py 모듈에 정의된 것들을 활용하려면 필요한 변수/함수/클래스의 이름을 나열하면 됩니다. 만약 모듈의 모든 것들을 활용하고 싶은데 그 수가 너무 많다면 import 옆에 '*'을 쓰면 됩니다.
from caculator import *
print(sum(6, 3))
print(difference(6, 3))9
3❗ randint 함수 & uniform 함수
이번에는 Python에 기본적으로 내장된 모듈에서 함수를 가져다 써보겠습니다. random이라는 모듈에는 randint라는 함수가 있습니다. 이 함수는 두 정수 사이에서 무작위 정수(난수)를 반환해줍니다.
from random import randint
x = randint(1, 10)
print(x)위 코드를 실행하면 정수 1부터 10까지의 정수 중 무작위로 한 가지 정수가 출력됩니다.
uniform도 random 모듈에 있는 함수 중 하나입니다. 이 함수는 두 수 사이의 무작위 소수를 반환해줍니다.
from random import uniform
y = uniform(0, 1)
print(y)위 코드를 실행하면 0부터 1까지 소수 중 무작위로 한 가지 소수가 출력됩니다.
이번 시간에는 Python에서 객체 지향 프로그래밍을 할 때 필요한 사항들을 함께 살펴 봤습니다. Python이라는 언어의 모든 요소들이 객체로 되어 있다는 사실이 놀랍지 않으신가요?
다음 시간에는 객체 지향 프로그래밍을 간단히 연습해 보는 시간을 가져보겠습니다.
* 이 자료는 CODEIT의 '객체 지향 프로그래밍' 강의를 기반으로 작성되었습니다.