
저번 시간에는 자료 구조의 개념과 스토리지와 메모리, RAM, 레퍼런스 등 자료 구조와 관련된 주요 개념들에 대해 알아봤습니다.
이번 시간에는 가장 기본적인 자료 구조인 배열에 대해 함께 배워봅시다.
👫 배열
배열은 기본적인 자료 구조이지만 Python을 배운 사람들에게는 낯선 용어일 수 있습니다. Python에서는 배열이 쓰이지 않기 때문이죠. 대신 Python의 리스트 자료형을 떠올리면 이해하기 쉬우실 것 같습니다.
사실 Python은 C를 기반으로 만들어진 언어이고 Python의 리스트는 C의 배열을 이용해서 만들어진 자료형입니다.
그런데 이 두 개념에는 몇 가지 핵심적인 차이가 있습니다. 먼저, 리스트는 append를 통해 언제든지 새로운 값을 추가할 수 있지만 배열은 그 크기가 고정되어 있고 요소의 값을 수정할 수는 있지만 삭제할 수는 없습니다.
또 다른 차이점은 여러 타입의 데이터를 한 곳에 담을 수 있는 리스트와는 달리, 배열은 같은 타입의 데이터만 담을 수 있습니다.
.jpg)
이해를 돕기 위해 C 코드를 잠깐 살펴보겠습니다.
int numArray[4];위 코드는 배열을 선언하는 C 코드입니다. 앞에서부터 int는 정수 자료형을 뜻하고 numArray는 배열의 이름, 배열 이름 뒤의 괄호와 숫자는 배열의 크기를 나타냅니다. 이 배열은 정수 타입의 데이터 네 개를 담을 수 있습니다.
배열을 선언할 때부터 자료형과 그 크기를 정해놓기 때문에 같은 타입의 데이터만 담을 수 있고 크기도 고정되어 있는 것입니다.
참고로, 지금은 C 언어를 공부하려는 것이 아니기 때문에 문법에 대해서는 외울 필요가 없습니다. 배열의 특징만 익혀두시길 바랍니다.
이렇게 배열은 메모리에 필요한 만큼의 공간을 미리 할당해야 합니다. 배열이 쓸 공간을 사전에 예약해두는 거죠. C에서는 정수 하나가 4byte이기 때문에 4개의 정수를 담기 위해서는 총 16byte의 메모리가 필요합니다.
앞서 1 byte는 메모리 한 칸이라고 배웠죠? 따라서, 총 16칸의 메모리 공간이 필요한 건데요. 중요한 것은 아무 16칸이 아닌 연속적인 16칸이 필요하다는 겁니다.
사용할 메모리 공간이 정해지면 값들을 채워 넣을 수 있게 됩니다.
numArray[0] = 4;
numArray[1] = 7;
numArray[2] = 1;
numArray[3] = 3;위 코드와 같이 각 인덱스에 해당하는 공간에 값들을 채워넣으면 되는데요. 이렇게 하면 0번 인덱스 공간에는 정수 4, 1번 인덱스 공간에는 정수 7, 2번 인덱스 공간에는 정수 1, 3번 인덱스 공간에는 정수 3이 저장됩니다.
총 16칸 중, 한 정수가 차지하는 공간은 4칸이므로 각 정수가 4칸씩을 나누어 차지하고 있습니다.

그럼 Python의 리스트는 어떻게 다를까요?
num_list = [4, 7, 1, 3]이렇게 리스트 하나를 선언해보겠습니다.
앞서, C 배열의 경우에는 각 정수값들이 실제로 메모리 공간에 저장된다고 했는데요. 이때, 네 개의 정수 모두 연속적으로 나란히 저장됩니다.
그러나 Python 리스트의 경우에는 각 값들이 서로 다른 메모리 공간에 저장되기도 합니다. 물론 연속적인 공간에 있을 수 있지만 항상 그렇지는 않습니다.
그럼 선언된 16칸의 공간에는 어떤 것이 저장되어 있는 걸까요? 바로 각 정수값에 대한 레퍼런스가 연속적으로 저장되어 있습니다. 즉, 각 정수값을 저장하는 것이 아닌 각 정수값을 가리키고 있다는 표현이 더 정확합니다.
이렇게 되면 사실 값 자체를 저장하는 것이 아니기 때문에 메모리의 크기가 크게 의미가 없습니다. 값이 크든 작든 이 공간은 값을 가리키는 역할만 하기 때문이죠. 이 때문에 배열과 달리 리스트에서는 다양한 타입의 데이터를 저장할 수 있는 것입니다.
여러 번 강조드리지만 배열은 자료 구조의 기본이기 때문에 배열에 대해 잘 이해해야 앞으로 배울 여러 자료 구조도 잘 이해할 수 있습니다. 차근차근 이해하며 따라오시길 바랍니다.
👫 배열 데이터 저장/접근법
배열에 데이터를 저장하고 가지고 오는 방법에 대해 알아봅시다. Python에서는 배열을 사용하지 않기 때문에 C를 통해 배열을 설명하고자 하는데요. 다시 한번 강조하지만 C언어를 배우기 위한 목적이 아니기 때문에 문법은 가볍게 보고 넘어가시면 됩니다.
int numArray[4];
numArray[0] = 4;
numArray[1] = 7;
numArray[2] = 1;
numArray[3] = 3;다시 이 코드를 봅시다. 4개의 정수값(4byte)을 담아야 하므로 16칸(16byte)의 공간이 필요한데요. 이 배열이 선언되면 컴퓨터는 메모리에서 현재 사용하고 있지 않은 16byte의 공간을 찾습니다. 예를 들어 주소가 1000부터 1015까지의 메모리를 찾았다고 합시다.
이제 이 공간에 값을 저장할 건데요. 값을 저장할 때는 인덱스가 활용됩니다. 중요한 것은 메모리 주소는 1000부터 1015까지이지만 네 개의 정수값을 담아야 하므로 인덱스는 네 개만 필요합니다. 0부터 3까지 말이죠. 이는 Python의 리스트와 유사한 부분입니다.
이렇게 하면 첫번째 정수 4는 주소 1000부터 1003까지를 차지하고 다음 수 7은 1004부터 1007까지, 그 다음 수 1은 1008부터 1011까지, 마지작 수 3은 1012부터 1015까지를 차지합니다.
이렇게 배열의 요소들이 메모리의 순서대로, 그리고 연속적으로 저장됩니다. 여기까지는 앞서 배운 내용과 동일합니다.
그렇다면 저장된 데이터를 받아오는 것은 어떻게 하면 될까요? 저장할 때와 마찬가지로 인덱스를 활용하면 됩니다. 그런데 내부적으로는 어떻게 동작하는 걸까요?
우선 numArray는 이 배열이 시작되는 지점의 주소를 가리키고 있습니다. 그리고 받아오고 싶은 인덱스에 따라 주소를 찾는데요.
예를 들어, 3번 인덱스를 받아오고 싶다고 가정해 봅시다. 배열의 값들이 연속적으로 저장되어 있다는 걸 고려했을 때, 0번 인덱스가 주소 1000이고 정수형 하나는 4byte이므로 다음과 같은 식이 성립됩니다.
1000 + 4 x 3 = 1012위 식을 다시 차례로 설명하면, 정수형 크기 4를 인덱스 3에 곱한 값을 배열의 시작 주소 1000에 더해주면 찾고자 하는 값의 시작 주소 1012가 나옵니다. 이렇듯 배열이 시작하는 지점의 주소만 알면 어떤 인덱스든 주소를 쉽게 계산할 수 있습니다.
여기서 잠깐 앞서 배운 RAM의 임의 접근 방식에 대해 떠올려 봅시다. 임의 접근이라는 건 주소가 있으면 그 주소가 어디있든 상관 없이 효율적으로 접근할 수 있다는 개념이었습니다. 그래서 시간 복잡도도 O(1)이었죠.
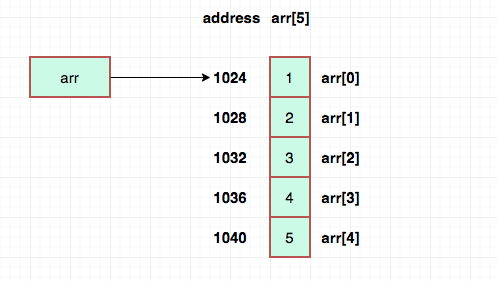
정리하자면, 배열에 어떤 인덱스의 값을 받아오기 위해서는 그 값의 주소를 알아야 합니다. 그리고 그 주소는 간단한 계산식으로 구할 수 있습니다. 일단 주소를 알고 나면 O(1)로 접근이 가능합니다. 이는 다시 말해, 배열의 값을 가져오는 것의 시간 복잡도가 O(1)이라는 거죠. 이는 값을 저장할 때도 마찬가지인데요. O(1) 방식으로 특정 인덱스의 주소에 접근하여 값을 저장하기 때문이죠.
어떤 인덱스든 접근하거나 값을 저장할 때 O(1) 밖에 걸리지 않는다는 점은 배열의 가장 큰 장점입니다. 배열은 주소만 정확히 알고 있으면 한 번에 접근이 가능하다는 RAM의 특성을 잘 이용한 자료 구조입니다.
👫 배열 탐색
탐색은 접근과 유사하지만 조금 다른 개념입니다. 인덱스를 통해 값을 찾는 접근과 달리, 탐색은 특정 조건을 만족하는 값만을 찾습니다. 예를 들어, 특정 배열에 4라는 수가 있는지 없는지를 찾는 거죠.
배열에서 탐색은 접근보다는 비효율적일 수밖에 없습니다. 그 이유는 특정 조건을 만족하는 값을 찾기 위해서는 배열을 하나하나 둘러봐야 되기 때문인데요.
만약 앞서 본 numArray에서 마지막 값 3을 찾으려면, 0번 인덱스를 보고 없으면 1번 인덱스, 없으면 2번 인덱스, 없으면 3번 인덱스까지 3을 찾을 때까지 쭉 봐야 합니다. 이와 같이 순서대로 값을 찾아가는 탐색을 선형 탐색이라고 합니다. 배열이 특정 순서로 정렬되어 있지 않은 이상 이 방법보다 효율적인 탐색은 없습니다.

배열 탐색의 효율성을 시간 복잡도로 어떻게 나타낼 수 있을까요? 최선의 경우를 따져보면 맨 처음 인덱스에 값이 있을 수 있습니다. 반대로 최악의 경우에는 찾는 값이 아예 배열 내에 없을 수도 있습니다. 이 경우, 배열의 크기가 4라면 네 개의 값을 봐야하고 배열의 값이 1000개라면 1000개까지도 봐야합니다. 그러니 배열의 크기가 n일 때, 탐색에 걸리는 시간은 이 n에 비례한다고 할 수 있습니다. 이를 시간 복잡도로 표현하면 O(n)입니다.
정리하자면, 배열의 값에 접근하여 저장하고 불러오는 것은 시간 복잡도 O(1)로 매우 효율적입니다. 그러나 특정 조건을 만족하는 값을 탐색하는 것은 시간 복잡도 O(n)으로 배열의 크기에 따라 시간이 오래 걸릴 수 있습니다.
👫 정적 배열
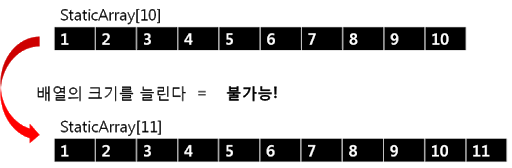
배열에는 정적 배열과 동적 배열이 있습니다. 정적 배열(static array)은 처음 정의할 때 크기를 정해 놓기 때문에 정해진 크기 이상의 값을 추가할 수 없습니다. 그에 반해, 동적 배열(dynamic array)은 꽉 차더라도 계속해서 값을 추가할 수 있습니다.
지금까지 우리가 본 C의 배열은 정적 배열에 속합니다. 또한, 일반적으로 배열은 정적 배열을 나타내는 것이고 동적 배열은 따로 동적 배열이라고 부릅니다.
정수 다섯 개를 담을 수 있는 정적 배열(이하 배열) 하나를 선언했다고 가정합시다. 이 배열 안에 각각 1,2,3,4,5 다섯 개의 정수를 채워 넣었습니다. 그럼 배열 안이 꽉 차겠죠?
이때, 정수 6을 새로 추가하고 싶으면 어떻게 해야 할까요? 정의에 따라 이미 만들어진 배열이 꽉 차면 더 이상 값을 추가할 수 없습니다. 유일한 해결 방법은 정수 여섯 개를 담을 수 있는 새로운 배열을 선언하는 것입니다. 하지만 이 방법은 좀 번거로워보이죠? 그냥 배열 끝에 6이라는 값만 추가할 수 있으면 매우 편할 텐데요.
왜 안 되는지 그 이유를 살펴봅시다. 배열을 선언할 때, 메모리에서 사용할 수 있는 공간을 찾는다고 했죠? 이때, 저장하려는 데이터 타입과 데이터의 개수에 따라 메모리의 공간이 정해집니다. 또한, 이 공간은 따로 떨어지면 안 되고 연속적이어야 합니다.
여기서 새로운 값을 추가하려고 하면 마지막 값 뒤에 공간이 있어야 하지만 그 공간이 비어있는지는 알 수 없습니다. 애초에 정해진 크기만큼의 공간만을 마련했기 때문이죠. 값이 비어있지 않은 공간을 함부로 사용하게 되면 다른 데이터를 침해할 수 있어 문제가 됩니다. 따라서, 배열은 이러한 문제를 방지하기 위해 처음부터 공간을 제한해 두는 것입니다.
그렇다면 처음부터 배열의 크기를 넉넉하게 정하면 어떻게 될까요? 만약 필요 이상으로 여유롭게 배열을 정의하면 메모리 공간을 낭비하게 됩니다. 나중에 다른 데이터를 저장하려는데 공간이 부족해지는 문제가 생기죠. 예를 들어, 5개의 정수를 저장하는데 크기 10000인 배열을 정의하면, 나머지 9995개의 정수를 저장할 수 있는 공간을 낭비하게 되는 겁니다.
👫 동적 배열
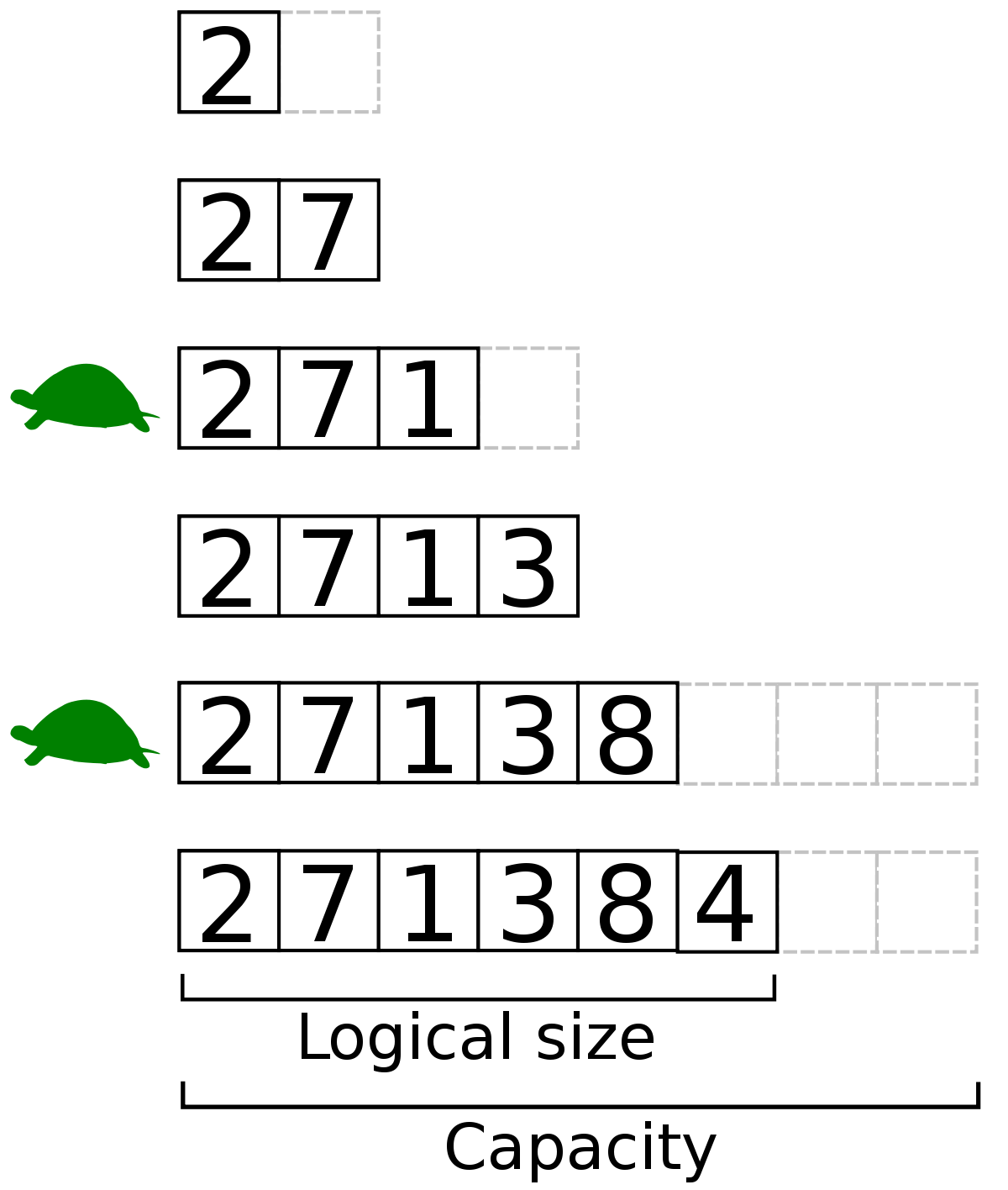
동적 배열은 정적 배열과 달리 상황에 맞게 크기가 바뀝니다. '동적'이라는 단어가 붙은 이유가 바로 크기에 대한 유연성 때문입니다.
사실 동적 배열은 정적 배열로부터 나온 것입니다. 그런데 어떻게 값이 꽉 찼을 때도 새로운 값을 추가할 수 있는 걸까요?
꽉 찬 동적 배열에서 새로운 값을 추가 할 때에는 더 큰 메모리 공간을 확보합니다. 기존에 있는 배열보다 두 배로 더 큰 배열을 만들죠. 예컨대, 정수 2개를 담을 배열이었다면 정수 4개를 담을 배열을 만드는 겁니다. 사실 항상 두 배로 커지지는 않지만 편의상 두 배라고 하겠습니다.
배열의 크기가 커졌으니 새로운 값을 추가할 수 있겠죠? 그러다 이 배열도 꽉 차게 되면 또 다시 두 배 큰 배열을 만듭니다. 이렇게 메모리 공간을 확보하면 기존 배열에서 값들을 다 복사해서 새로운 값을 추가할 수 있습니다.
정리하면, 동적 배열은 정적 배열로 만들어진 자료 구조이지만 정적 배열의 크기를 상황에 맞게 조절하도록 미리 구현되어 있어 공간이 꽉 차도 계속해서 크기를 늘릴 수 있습니다. 이때, 크기를 무조건적으로 크게 늘리는 것이 아니라 적당한 기준을 가지고 늘리기 때문에 메모리 낭비를 방지합니다. 개발자 입장에서는 배열의 크기를 고민할 필요가 없어 매우 편하겠죠.
이번 시간에는 가장 기본 자료 구조인 배열에 대해 알아봤습니다. 구조뿐만 아니라 메모리 공간에 대해 생각해야 하니 머리가 복잡하시죠? 하지만 컴퓨터 구조를 이해하는 것은 동작 원리와 자료 구조를 이해하는데 매우 도움이 됩니다. 컴퓨터적으로 사고하는 능력을 기를 수 있는 거죠!
다음 시간에는 배열에 대한 시간 복잡도와 분할 상환 분석, 그리고 동적 배열의 다양한 연산에 대해 알아보겠습니다.
* 이 자료는 CODEIT의 '자료 구조' 강의를 기반으로 작성되었습니다.