저번 시간에는 기본 자료 구조인 배열의 개념과 배열 탐색 방법, 정적 배열과 동적 배열 등 배열에 관한 여러 지식들을 함께 배웠습니다.
이번 시간에는 시간 복잡도와 분할 상환 분석에 대한 개념, 그리고 동적 배열의 추가 연산과 삽입 연산에 대해 알아보겠습니다.
👫 Python 리스트의 비밀
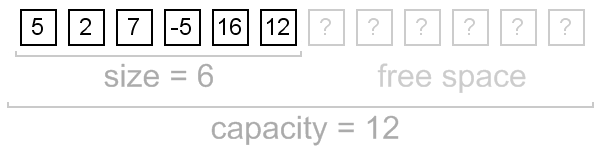
Python의 리스트는 동적 배열에 속합니다. C 배열을 이용해서 동적 배열을 구현한 것이 바로 Python의 리스트인 것이죠. 따라서, append를 이용하면 리스트에 새로운 요소를 추가할 수 있었던 것입니다.
지금껏 리스트를 선언하며 리스트의 크기에 대해 고민했던 적이 있으셨나요? 아마 없었을 겁니다. 왜냐하면 크기를 고민할 필요 없이 자유롭게 값을 추가할 수 있었으니까요.
그런데 len 함수를 기억하시나요? 리스트의 크기를 알고 싶을 때 사용했었죠? 사실 실제 사용하고 있는 메모리 공간이 더 많을지라도 Python은 리스트 요소의 개수를 셀 때에는 값을 저장해 놓은 공간에 대해서만 알려줍니다. 따라서, 우리는 나머지 공간에 대해 전혀 신경 쓸 필요가 없었던 것이죠.
만약 채워지지 않은 공간에 접근하려고 하면 오류가 나게 됩니다. 이는 우리가 값을 저장해 놓은 공간에만 접근할 수 있도록 Python이 미리 처리를 해놓았기 때문입니다.
Python 뿐만 아니라 동적 배열을 자료형으로 제공하는 대부분의 언어들은 이렇게 실제 사용하는 배열의 크기와 상관 없이 저장해 놓은 공간만 사용할 수 있도록 처리가 되어 있습니다.
👫 동적 배열 추가 연산 시간 복잡도
배열의 끝에 새로운 값을 넣는 것을 추가 연산(append operation)이라고 합니다. 동적 배열에 추가 연산을 할 때, 시간이 얼마나 걸리는지 알아보겠습니다.
동적 배열은 내부적으로 정적 배열을 사용하죠? 그래서 새 값을 추가하려고 할 때, 내부적으로 사용 중인 정적 배열에 남은 공간이 있을 수도 있고 꽉 찼을 수도 있습니다. 이 두 가지 경우를 나눠서 생각해보겠습니다.
먼저, 배열에 남은 공간이 있는 경우에는 비어 있는 공간 중에 가장 앞쪽에 있는 칸에 데이터를 저장하면 되므로 매우 쉽습니다. 인덱스를 이용해서 접근하기 때문에 시간 복잡도는 O(1)입니다. 이 경우, 동적 배열에 데이터를 추가하는 것은 굉장히 효율적이라는 얘기죠.
다음으로 배열이 꽉 차있는 경우에는 새로운 값을 추가하기 위해 현재 사용 중인 배열보다 (임의로) 두 배로 큰 메모리 공간을 예약합니다. 그리고 기존 배열에서 새로운 배열로 값을 싹 다 복사 붙여넣기 하고 새 값을 빈 칸에 추가합니다. 이렇게 하는 데 얼마나 걸릴까요?
기존에 저장되어 있던 데이터의 개수가 n이라고 가정합시다. 이미 있던 n개의 데이터를 새 배열에 복사할 때, 일일히 하나씩 해야 하는데요. 기존 배열의 0번 인덱스에 접근해서 값을 복사하고 새 배열의 0번 인덱스에 접근해서 값을 붙여 넣습니다. 데이터의 개수가 n이므로 이 과정을 총 n번 반복해야 합니다.
배열의 특정 인덱스에 접근하는 건 O(1)이지만 복사하고 붙여넣는 과정이 n번 반복되므로 O(n)이 걸립니다. 그리고 새 값을 추가하는 마지막 단계도 O(1)이니까 총 O(n+1)이라 할 수 있는데요. 마지막 상수 1은 무시할만한 수이므로 결과적으로는 O(n)이 걸린다고 할 수 있습니다.
정리하자면, 동적 배열 추가 연산의 시간 복잡도는 정적 배열에 남는 공간이 있을 때(최선의 경우)는 O(1), 공간이 꽉 찼을 때(최악의 경우)는 O(n)입니다.
👭 분할 상환 분석

앞서 우리는 동적 배열에 값을 추가하는 추가 연산의 시간 복잡도에 대해 알아봤는데요. 당시 시간 복잡도를 최선의 경우와 최악의 경우로 나누어 구했었죠? 보통 보수적으로 표현하기 위해 시간 복잡도는 최악의 경우로 얘기하는 경우가 많습니다. 따라서, 동적 배열에 값을 추가하는 연산은 최악의 경우인 O(n)이라고 할 수 있습니다.
그런데 생각해보면 동적 배열의 추가 연산에서 최악의 경우보다 최선의 경우가 더 많습니다. 다시 말해, 배열이 꽉 차 있는 경우보다는 배열에 빈 공간이 있는 경우가 더 흔하다는 것이죠. 그래서 동적 배열 추가 연산의 시간 복잡도를 O(n)이라고 단정 짓는 것은 조금 비합리적입니다.
이렇듯 최악의 경우로 시간 복잡도를 산정했을 때, 비합리적인 경우가 종종 발생합니다. 이런 상황에 대비해서 시간 복잡도를 조금 다르게 계산하는 몇 가지 방법들이 있습니다. 그 중 하나가 바로 분할 상환 분석(Amortized Analysis)입니다.
분할 상환은 회계에서도 자주 쓰이는 표현인데요. 쉽게 말하자면 할부라고 할 수 있습니다. 200만원짜리 컴퓨터를 산다고 가정해봅시다. 이를 5개월 할부로 구매하면 5개월에 200만원, 혹은 1개월에 40만원이라고 할 수 있습니다.
분할 상환 분석도 마찬가지입니다. 같은 동작을 n번 했을 때 드는 시간이 x라면, 동작을 한 번 하는데 걸린 시간은 x / n이라고 할 수 있습니다. 따라서, 분할 상환 분석은 최악의 경우가 아닌 평균을 구해서 시간 복잡도를 계산하는 방법입니다. 이렇게 하면 보다 합리적인 시간 복잡도를 구할 수 있습니다.
👭 분할 상환 분석 적용
그럼 분할 상환 분석을 동적 배열에 적용해 봅시다.
❗ 동적 배열 동작
동적 배열에 추가를 할 때에는 새로운 인덱스에 데이터를 저장하는 시간과, 기존 배열의 크기가 부족해서 더 큰 배열을 만들고 기존 배열의 데이터들을 옮기는 시간으로 나눠서 생각하면 됩니다.
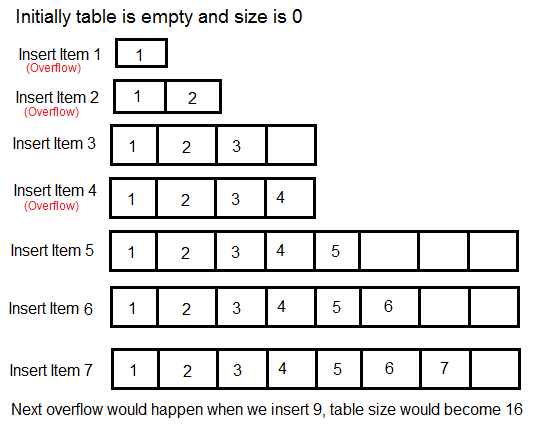
여기서 기억을 상기하기 위해 이전 시간에 배운 내용을 복습해보겠습니다. 비어 있는 동적 배열에 추가 연산을 5번 한다고 가정해봅시다. 처음 시작할 때의 크기가 1인 동적 배열입니다.
- 첫 번째 요소 추가
- 새로운 데이터를 저장합니다.
- 두 번째 요소 추가
- 배열이 꽉 찼습니다. 크기가 2인 배열을 새로 만들고 기존 데이터(1개)를 옮겨 저장합니다.
- 맨 뒤의 인덱스에 새로운 데이터를 저장합니다.
- 세 번째 요소 추가
- 배열이 꽉 찼습니다. 크기가 4인 배열을 새로 만들고 기존 데이터(2개)를 옮겨 저장합니다.
- 맨 뒤의 인덱스에 새로운 데이터를 저장합니다.
- 네 번째 요소 추가
- 맨 뒤의 인덱스에 새로운 데이터를 저장합니다.
- 다섯 번째 요소 추가
- 배열이 꽉 찼습니다. 크기가 8인 배열을 새로 만들고 기존 데이터(4개)를 옮겨 저장합니다.
- 맨 뒤의 인덱스에 새로운 데이터를 저장합니다.
이런 식으로 내부 배열이 꽉 찼을 때는 새로운 배열을 만들고 기존 요소들을 복사하고 새로운 요소들을 저장하면 됩니다. 배열에 여유가 있을 때는 그냥 새로운 요소만 저장하면 됩니다.
❗ 분할 상환 분석
분할 상환 분석을 하면 이 동작을 n번 반복한다고 가정합니다. 앞서 시간을 계산하기 쉽게 두 가지 경우로 나눠서 생각한다고 했었는데요. 두 개의 시간을 각각 따로 계산해보겠습니다.
먼저, 배열 끝에 새로운 데이터를 저장하는 데 걸리는 총 시간에 대해 생각해 봅시다. 아래 표를 참고해주시길 바랍니다.
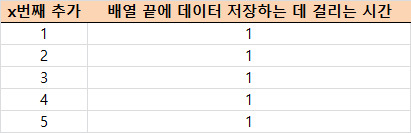
인덱스에 데이터를 저장하는 데 걸리는 시간은 1입니다. 이걸 총 n번 반복하니 O(n)이 되겠죠?
다음으로, 내부 배열이 꽉 차서 기존 데이터를 복사하는 데 걸리는 시간을 생각해 봅시다. 이 부분은 좀 어려우니 집중해서 봐주세요.
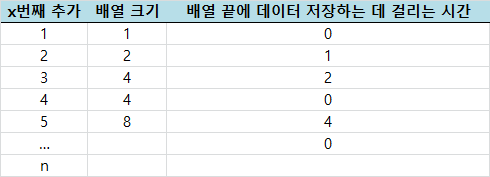
새로운 배열에 기존 데이터를 옮겨 저장하는 시간은 위와 같습니다. 2번째, 3번째, 5번째 추가 때 배열의 크기를 늘리고 데이터를 옮깁니다. 이때, 데이터를 각각 1, 2, 4개씩 복사하고 붙여 넣습니다. 데이터를 복사해서 붙여 넣는 총 시간 비용은 이 시간들을 더한 4+2+1이 되는데요. 이 식을 좀 더 일반화해서 생각해볼까요?
추가 연산을 n번 했을 때, 가장 마지막에 데이터를 m개 옮겨서 저장했다고 합시다. 그럼 데이터를 복사해서 저장하는 데 걸린 총 시간은 m+(2/m)+(4/m)+...+1 이런 식으로 표현이 가능한데요. 처음에는 m이 있고 그 다음에 계속 반으로 줄어든 값을 더해주게 됩니다.
이렇게 어느 자연수든 반씩 줄여서 1까지 계속 더해주면 그 결과는 절대 2m(m+m)을 넘을 수 없습니다. 정확히 표현하면 딱 2m-1이 되죠.
그런데 가장 최근에 데이터를 옮겨 저장할 때 4가 걸렸다는 건 어떤 의미일까요? 원래 배열의 수용 가능 크기가 4였지만 크기가 부족해서 8개의 데이터를 담을 수 있는 새로운 배열로 복사했다는 뜻입니다. 그럼 결국에 현재 배열 안에 있는 데이터는 5개에서 8개 사이라는 말입니다. 8개보다 더 많은 요소가 있으면 가장 최근에 옮겨 저장한 요소의 수가 4가 아니라 8이겠죠?
이를 바탕으로 우리가 일반화했을 때 사용했던 배열 안 요소의 수 n과 가장 최근 옮겨 저장한 요소 수 m의 관계에 대해서 알 수 있는 사실이 한 가지 있는데요. 가장 최근에 복사하는 데 걸린 시간이 4일 때, 배열 안에 있는 데이터는 5개에서 8개 사이이기에 m은 무조건 n보다 작다는 것입니다.
따라서, 추가 연산을 연속으로 n번 하고 가장 마지막에 옮겨 저장한 데이터 요소 수를 m이라고 할 때, 복사해서 저장하는 데 걸리는 총 시간은 2m-1이고 m은 n보다 작습니다. 다시 말해, 연속으로 추가 연산을 n번 하면 데이터를 옮겨서 저장하는 데 걸리는 총 시간은 2n보다 작습니다.
❗ 두 경우 합치기
지금까지 나온 내용들을 종합해보면, 동적 배열에 n개의 데이터를 연속으로 추가했을 때, 새로운 데이터를 저장하는 데에는 n의 시간이 들고, 데이터를 옮겨 저장하는 데에는 2n보다 적은 시간이 걸리는데요. 이 두 시간을 합치면 총 소요되는 시간은 3n보다 적은 시간이 걸리겠죠? 이를 시간 복잡도로 표현하면 O(3n) 즉, O(n)이 됩니다.
그런데 이는 추가 연산을 한 번 한 게 아니라 연속으로 n번 하는 데 걸리는 시간 복잡도입니다. 그러니까 총 n번의 추가 연산을 하는 데 걸리는 시간이 O(n)이라는 건데요. 그렇다면 1번 하는 데는 O(n)/n 즉, O(1)이 걸린다는 것이죠.
따라서, 최악의 경우인 O(n)이 아니라 분할 상환 분석을 적용하면 O(1)이 되는 것입니다.
❗ 어떤 계산이 더 적합할까?
사실 분할 상환 분석을 적용한다고 해서 항상 시간 복잡도가 줄어드는 것은 아닙니다. 그러나, 만약 최악의 경우보다 분할 상환 분석을 적용한 시간 복잡도가 더 적다면 더 적은 쪽의 시간 복잡도를 채택합니다. 그러니까 동적 배열의 추가 연산에 대해서는 분할 상환 분석을 적용한 시간 복잡도로 표현하는 것이 적합하다는 것이죠.
또한, 혼란을 방지하기 위해 보통은 최악의 경우와 분할 상환 분석을 적용한 시간 복잡도 모두를 나타내 주는 것이 좋습니다.
👭 동적 배열 삽입 연산
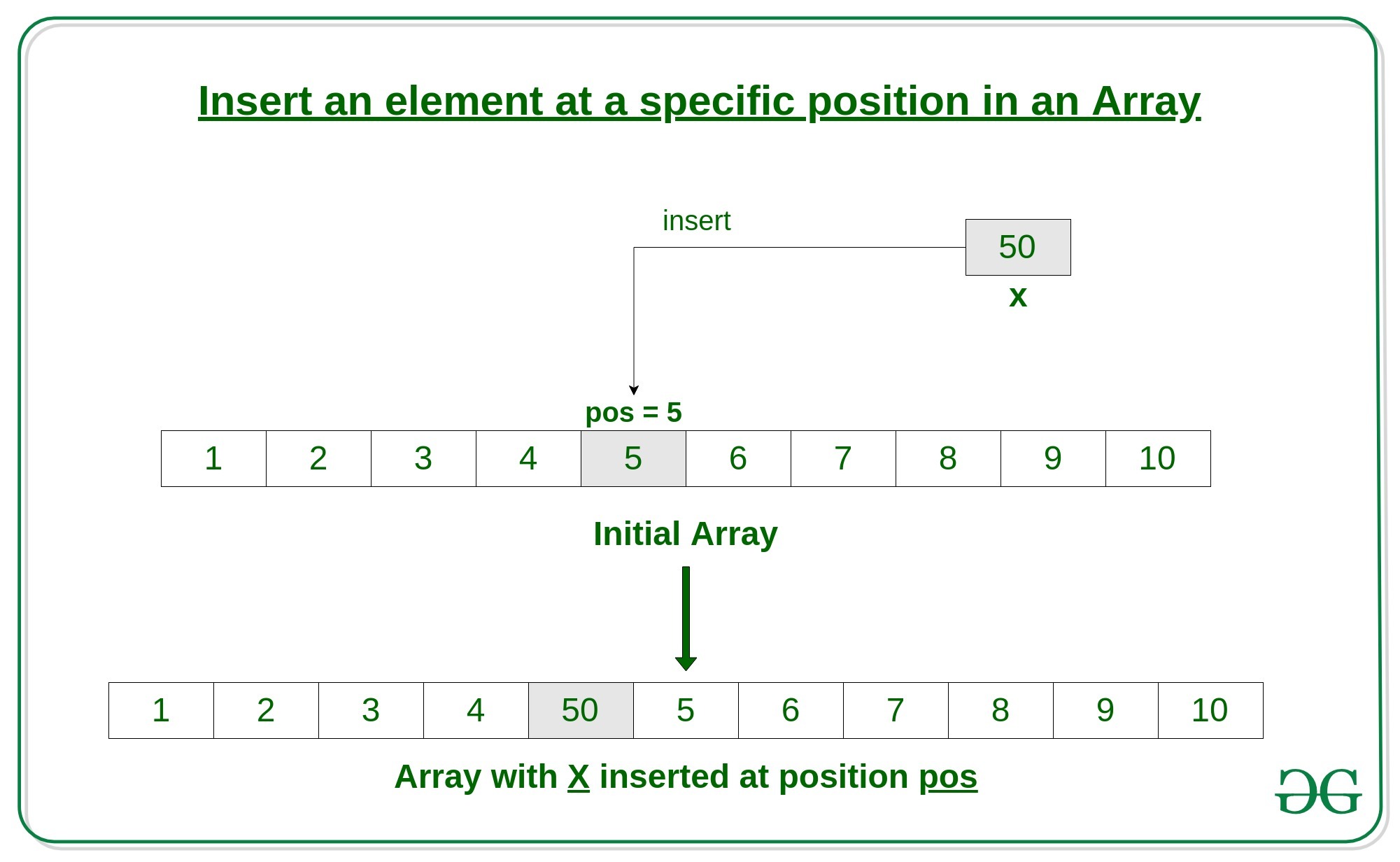
배열에 요소를 추가할 때, 배열 끝이 아닌 아무 위치에나 추가하는 것도 가능합니다. append는 배열의 끝에 데이터를 '추가'한다는 의미로 사용되고 방금 언급한 것과 같이 아무 위치에나 요소를 추가할 때에는 insertion 즉, '삽입'한다는 의미의 단어를 사용합니다. 따라서, 이러한 방식을 삽입 연산(insert operation)이라고 합니다.
삽입 연산 시에도 추가 연산과 마찬가지로 정적 배열에 남는 공간이 있는 경우와 꽉 찬 경우 이 두 가지 경우로 나뉩니다.
배열에 남는 공간이 있을 때부터 봅시다.
int numArray[8] = {4, 7, 6, 5, 2, 3, 8}배열의 크기는 8인데, 선언된 요소의 수는 7개입니다. 이때, 6과 5 사이에 1이라는 수를 삽입하고자 합니다. 배열은 연속적으로 데이터를 저장한다고 했죠? 이때, 새로운 숫자를 중간에 삽입하려면 데이터 사이에 틈을 벌려야 합니다. 이를 위해서는 인덱스 3의 값과 인덱스 3 뒤의 모든 값들을 한 인덱스씩 뒤로 밀어야 합니다. 마지막 인덱스 6의 값을 인덱스 7에 넣고 그 다음 인덱스 5의 값을 인덱스 6에 넣고... 이런 식으로 말이죠. 이렇게 하면 원하는 위치인 인덱스 3에 빈 공간이 생깁니다. 여기에 1을 저장하면 됩니다.
이 경우의 시간 복잡도는 어떻게 될까요? 시간 복잡도는 주로 최악의 경우를 생각한다고 했죠? 삽입 연산의 최악의 경우는 인덱스 0에 요소를 삽입할 때입니다. 제일 앞 인덱스이므로 기존의 모든 값을 뒤로 이동시켜야 하기 때문이죠. 다시 말하면, 모든 인덱스에 바로 전 인덱스의 값을 저장하게 됩니다.
배열의 인덱스에 새로운 값을 저장할 때의 시간 복잡도는 O(1)이고 이를 총 n번 해야 하니까 총 O(n)이 걸립니다. 마지막에 삽입되는 값에 대한 시간 복잡도가 O(1)이므로 O(n+1)이 되지만 이는 무시할만한 수치이므로 최종적으로는 O(n)이 됩니다.
다음으로 배열이 꽉 찼을 때의 경우를 봅시다.
int numArray[4] = {4, 7, 6, 5}크기가 4인 배열에 4개의 요소가 꽉 차있습니다. 이 배열의 6과 5 사이에 1을 삽입하려 합니다. 수용 공간이 부족하기 때문에 수를 저장하기 위해서 새로운 배열을 만들겠죠? 새로운 배열을 만든 후에는 기존 데이터를 복사해서 저장합니다. 그 다음에는 위 경우와 동일합니다. 원하는 위치 뒤의 모든 수를 밀어내고 그 사이로 새로운 수가 들어가는 거죠.
이 경우의 시간 복잡도를 알아봅시다. n개의 요소가 담긴 배열이 있다고 가정합시다. 새로운 배열을 만들고 기존 요소들을 하나하나 옮겨 저장하는 데 걸리는 시간은 O(n)입니다. 하나의 데이터를 인덱스에 저장하는 데 O(1)이 걸리고 n개의 요소를 모두 복사해야하니까요.
그 다음, 원하는 위치에 공간을 만들기 위해서 해당 위치 뒤에 있는 모든 요소들을 한 칸씩 뒤로 밀어주면 됩니다. 최악의 경우는 배열에 여유가 있었을 때와 마찬가지로 인덱스 0에 요소를 삽입하는 것입니다. 이때, n개의 요소 모두를 뒤로 밀어야 하므로 시간 복잡도는 O(n)이 됩니다. 마지막으로 새로운 요소를 삽입하는 시간 복잡도는 O(1)입니다.
이들을 모두 더하면 총 시간 복잡도는 O(2n+1). 하지만 n을 제외한 나머지 수는 모두 무시할만한 수치이므로 최종적으로 시간 복잡도는 O(n)입니다.
그럼 첫번째 경우와 두번째 경우 모두 시간 복잡도가 O(n)인 셈인데요. 삽입 연산은 배열에 여유가 있든 없든 최악의 경우에 대한 시간 복잡도가 O(n)으로 동일합니다.
결국, 삽입 연산에서 마지막 위치에 새로운 요소를 삽입하면 O(1)이 걸리지만 아무 위치에 삽입하게 되면 O(n)이 걸립니다.
이번 시간에는 Python의 리스트의 바탕이 되는 동적 배열과 동적 배열의 추가, 삽입 연산, 그리고 시간 복잡도의 한계를 보완하는 분할 상환 분석에 대해 알아봤습니다. 오랜만에 시간 복잡도에 관한 내용을 배우니 머리가 복잡하시죠? 하지만 시간 복잡도는 개발을 할 때 꼭 고려해야 하는 내용이니만큼 익혀두시는 편이 좋습니다.
다음 시간에는 동적 배열의 삭제 연산에 대해 추가적으로 배우고 정적 배열과 동적 배열을 비교하여 정리하는 시간을 가져보겠습니다.
* 이 자료는 CODEIT의 '자료 구조' 강의를 기반으로 작성되었습니다.