📊 평균값(mean)
- 통계에서의 평균
- 모든 데이터들의 합을 데이터의 개수로 나눈 것
# 데이터 셋
55 | 87 | 66 | 98 | 78 | 60 | 31
# 평균
(55 + 87 + 66 + 98 + 78 + 60 + 31) / 7 = 68📊 중간값
- 중간값
- 데이터 셋에서 정중앙에 있는 값
- 정렬이 되어 있으면 중간값 찾기 쉽다
- 데이터 개수가 홀수일 때
- 중앙에 있는 값
32 | 48 | 56 | 78 | 86 | 96 | 100
# 중간값: 78- 데이터 개수가 짝수일 때
- 중앙에 있는 두 값의 평균값
7 | 11 | 12 | 15 | 16 | 21 | 24 | 29
# 중간값: (15+16)/2 = 15.5📊 평균값 vs. 중간값
- 잘못된 데이터 한 두 개에 영향을 크게 받는 평균값
- 평균값은 데이터 셋의 중심을 제대로 표현하지 못하는 경우가 있다
1+2+3+4+100=110
110/5=22
1+2+3+4+5=15
15/5=3- 잘못된 데이터에 영향을 덜 받는 중간값
1 | 2 | 3 | 4 | 100
# 중간값: 3
1 | 2 | 3 | 4 | 5
# 중간값: 3- 평균값의 장점
- 위치에 기반하는 중간값은 개별 데이터들의 특징을 잘 담아내지 못한다
- 예:) A 매장, B 매장, C 매장의 실적이 모두 다름에도 중간값은 같다
- 평균값은 개별 데이터의 특성을 잘 담아낸다
- 예:) A 매장, B 매장, C 매장의 평균은 개별 점수에 따라 서로 다르다
- 위치에 기반하는 중간값은 개별 데이터들의 특징을 잘 담아내지 못한다
📊 상관 계수
- 두 변수의 연관성
- 예:) 수학 점수와 국어 점수의 연관성
- 산점도를 통해 시각화
- 상관 계수(Correlation Coefficient)
- 두 변수의 연관성을 수치적으로 표현한 것
- 피어슨(Pearson) 상관 계수
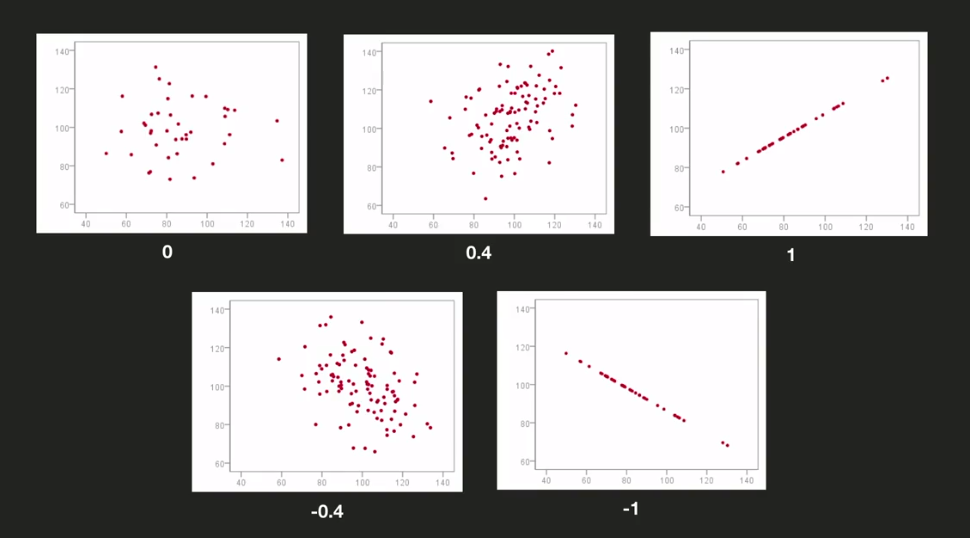
- 가장 널리 쓰이는 상관 계수
- -1부터 1까지의 값
- 상관계수가 0인 경우
- x와 y의 연관성 없음
- 상관계수 0보다 큰 경우
- 1에 가까워질수록 x와 y의 연관성이 강해진다
- 상관계수가 1인 경우
- x와 y의 확실한 연관성
- 상관계수가 0보다 작은 경우
- -1에 가까워질수록 x와 y의 연관성은 반대로 강해진다
- x가 작아질수록 y가 커진다
- 상관계수가 -1인 경우
- x와 y의 확실한 연관성
- x와 y는 음의 상관 관계
📊 상관 계수 시각화
- 학생들의 시험 점수 데이터 사이의 상관 계수 구하기
- DataFrame의 corr() 메소드
- 숫자 데이터 사이의 상관 계수
- DataFrame으로 출력
- DataFrame의 corr() 메소드
%matplotlib inline
import pandas as pd
df = pd.read_csv('data/exam.csv')
df.corr()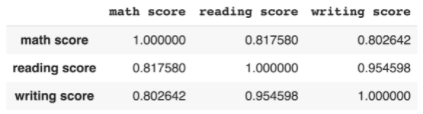
- 히트맵
- 상관 계수를 시각화하는 대표적인 방법
- Seaborn의 heatmap 메소드
- 색이 밝을수록 높은 상관 계수
- 읽기 점수(reading score)와 쓰기 점수(writing score) 사이의 상관 계수가 가장 강함
annot=True- 색상과 함께 숫자도 보여준다
%matplotlib inline
import pandas as pd
import seaborn as sns
df = pd.read_csv('data/exam.csv')
sns.heatmap(df.corr())
sns.heatmap(df.corr(), annot=True)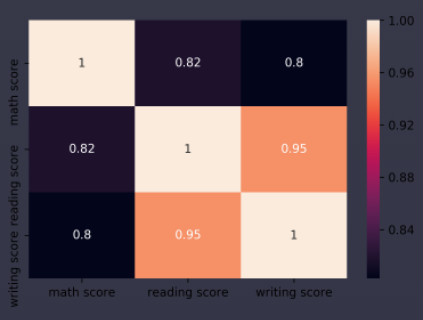
* 출처: CODEIT - 데이터 사이언스 입문
There's Only One Thing To Do: Learn All We Can