🚵♀️ EDA란?
- Exploratory Data Analysis
- 탐색적으로 데이터를 분석하는 것
- 데이터셋을 다양한 관점에서 살펴보고 탐색하면서 인사이트를 찾는 것
- EDA 질문 예시
- 각 row의 의미
- 각 column의 의미
- 각 column의 분포
- 두 column 사이의 연관성
- EDA 사례
- 설문 조사 결과 EDA
- 참여자 수 / 연령대 / 최종 학력 / 가족 관계 / 관심사 ...
- EDA에는 공식이 없다
- 시각화
- 통계적 개념
- 창의적 조합
- 다양한 방면으로 데이터 살펴보기
🚵♀️ 기본 정보 파악하기
- 설문조사 사례
- 997명 참여
- 147개의 항목
- 19개: 음악 취향
- 12개: 영화 취향
- 32개: 취미, 관심사
- 10개: 공포증
- 3개: 건강 습관
- 57개: 성격, 인생관, 다양한 의견
- 7개: 소비 습관
- 7개: 기본 정보(나이, 키, 몸무게, 성별)
- 기본 정보 파악하기
- 나이, 키, 몸무게, 성별, 최종학력 등
- 숫자 column에 대한 통계적 파악:
.describe()- 참여 연령대: 15세~30세
- 주로 20대 초반이 많다
basic_info = df.loc[:, 140:]
basic_info.head()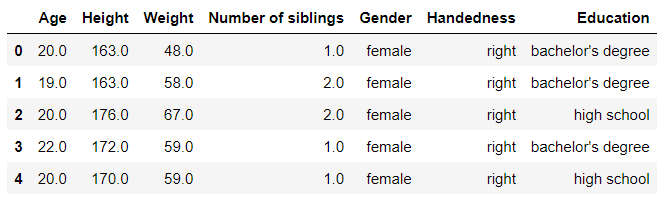
basic_info.describe()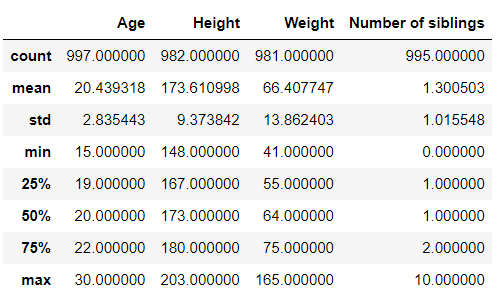
- 문자형 column에 대한 통계적 파악
value_counts()를 통한 응답수 추출
basic_info['Gender'].value_counts()
basic_info['Handedness'].value_counts()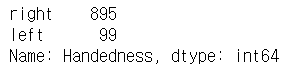
basic_info['Education'].value_counts()
- 그래프로 결과 파악하기
- 나이 분포
- 10대 후반과 20대 초반에 집중됨
- 성별에 따른 나이 분포
- 비슷한 분포
- 오른손잡이, 왼손잡이 특성 추가
- 비슷한 분포
- 키와 몸무게의 연관성
- 나이 분포
sns.violinplot(data=basic_info, y='Age').png)
sns.violinplot(data=basic_info, x='Gender', y='Age').png)
sns.violinplot(data=basic_info, x='Gender', y='Age', hue='Handedness')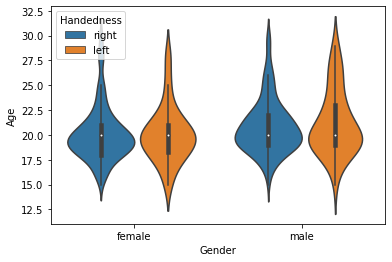
sns.jointplot(data=basic_info, x='Height', y='Weight')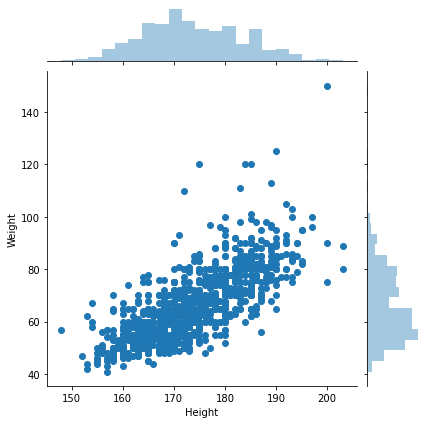
- 시각화를 활용하면 초기 인사이트를 얻을 수 있다
- 예:) 20대 초반에 집중 >> 20대 초반의 의견이 많이 반영되어 있다
🚵♀️ 상관 관계 분석(Correlation Analysis)
- 음악과 관련된 항목 분석
- 5점 척도
- 좋아하면 5점, 좋아하지 않으면 1점
- 5점 척도
music = df.iloc[:, :19]
music.head()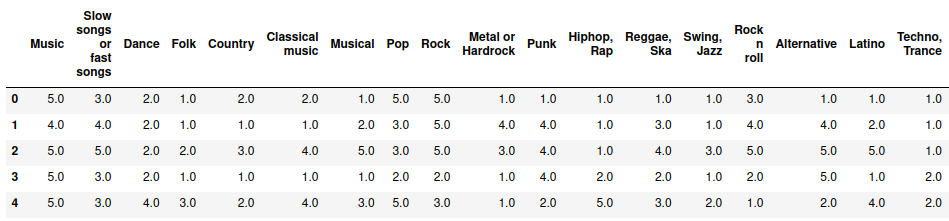
- 각 음악 장르 사이의 연관성 파악
- 히트맵 활용
- 연한 색일수록 더 확실한 연관성
- 진한 색일수록 연관성이 약하거나 반대되는 항목
- 오페라와 힙합은 검은색 >> 연관성이 약하다
- 오페라와 클래식은 주황색 >> 연관성이 강하
- 히트맵 활용
sns.heatmap(music.corr())
- 나이와 다른 항목 간의 연관성 파악
- 모든 컬럼들의 연관성 파악
df.corr()
- 나이에 대한 컬럼만 추출
- 큰 순서대로 정렬
- 양의 관계: 몸무게와 투표권
- 음의 관계: 과거에 대한 후회, 쇼핑에 대한 관심
- 모든 컬럼들의 연관성 파악
df.corr()['Age'].sort_values(ascending=False)
🚵♀️ 실습 - 스타트업 아이템 탐색하기
문제
- 스타트업 준비하는 A씨의 사업 아이템 가설
- 악기를 다루는 사람들은 시 쓰기를 좋아하는 경향이 있다
- 외모에 돈을 많이 투자하는 사람들은 브랜드 의류를 선호한다
- 메모를 자주 하는 사람들은 새로운 환경에 쉽게 적응한다
- 워커홀릭들은 건강한 음식을 먹으려는 경향이 있다
- 가설과 관련이 있는 column 목록
- Branded clothing: 나는 브랜드가 없는 옷보다 브랜드가 있는 옷을 선호한다.
- Healthy eating: 나는 건강하거나 품질이 좋은 음식에는 기쁘게 돈을 더 낼 수 있다.
- Musical instruments: 나는 악기 연주에 관심이 많다.
- New environment: 나는 새 환경에 잘 적응하는 편이다.
- Spending on looks: 나는 내 외모에 돈을 많이 쓴다.
- Workaholism: 나는 여가 시간에 공부나 일을 자주 한다.
- Writing: 나는 시 쓰기에 관심이 많다.
- Writing notes: 나는 항상 메모를 한다.
풀이
- 악기를 다루는 사람들은 시 쓰기를 좋아하는 경향이 있다
df.corr().loc['Musical instruments', 'Writing']0.3441930532038243- 외모에 돈을 많이 투자하는 사람들은 브랜드 의류를 선호한다
df.corr().loc['Spending on looks', 'Branded clothing']0.41839894464589139- 메모를 자주 하는 사람들은 새로운 환경에 쉽게 적응한다
df.corr().loc['Writing notes', 'New environment']-0.07745384812012578- 워커홀릭들은 건강한 음식을 먹으려는 경향이 있다
df.corr().loc['Workaholism', 'Healthy eating']0.23678959462190083🚵♀️ 클러스터 분석
- 클러스터 분석(Cluster Analysis)
- 클러스터
- 뭉쳐 있는 무리
- 클러스터 분석
- 데이터를 몇 가지 부류로 나누어 분석
- 예:) 중학생 데이터 - 문과 / 이과 / 예체능
- 클러스터
- 관심사 관련 column 추출
interests = df.loc[:, 'History':'Pets']
interests.head()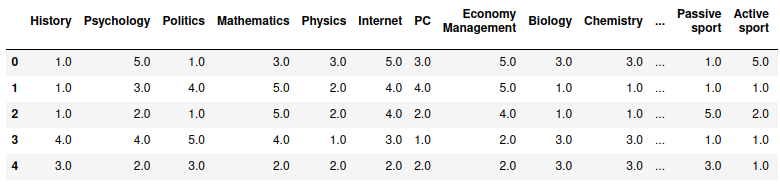
- 관심사 간 상관관계
corr = interests.corr()
corr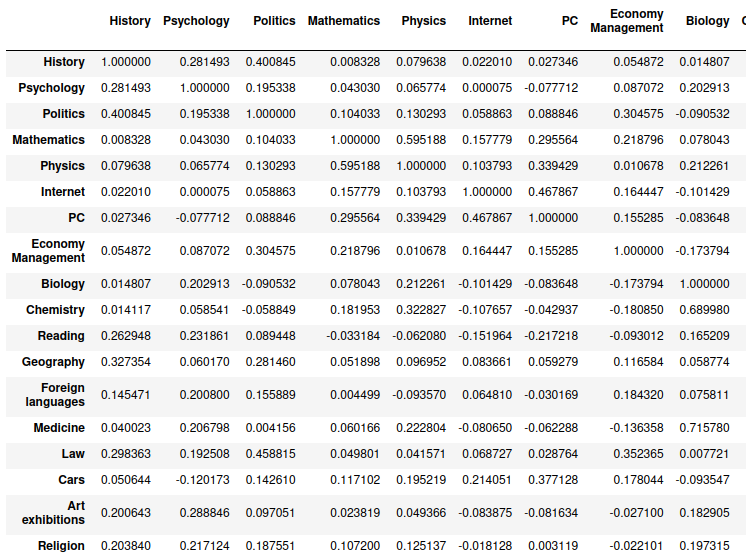
- 역사와 관련 있는 관심사들
corr['History'].sort_values(ascending=False)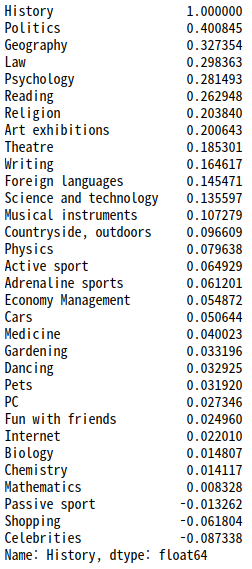
- 클러스터 맵(cluster map)
- seaborn 라이브러리 기능
.clustermap- 히트맵과 유사
- 관련 있는 관심사끼리 묶음
- 예:) Biology-Medicine-Chemistry
sns.clustermap(corr)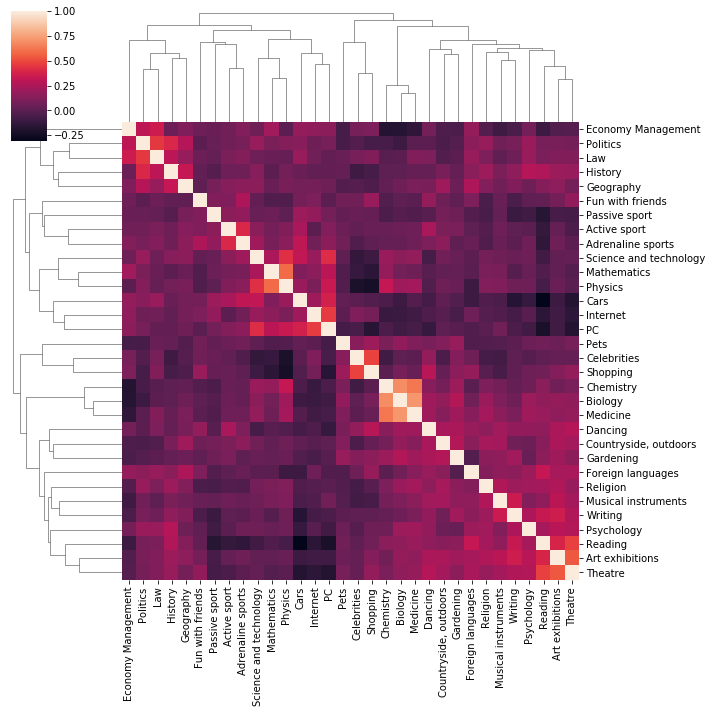
* 출처: 코드잇 - 데이터 사이언스 입문
There's Only One Thing To Do: Learn All We Can