🦏 큰 DataFrame 살펴보기
import pandas as pd
laptops_df = pd.read_csv('data/laptops.csv')- 대부분의 데이터셋은 매우 크다
- 중간의 데이터들이
...으로 생략되기도 한다
- 중간의 데이터들이
- 데이터셋 크기 확인하기
laptops_df.shape(167, 15) # 167rows(노트북 종류) / 15columns(특징)- 원하는 줄 수만큼 출력하기
laptop_df.head(3) # 맨 위 세 줄 출력
laptop_df.tail(6) # 마지막 여섯 줄 출력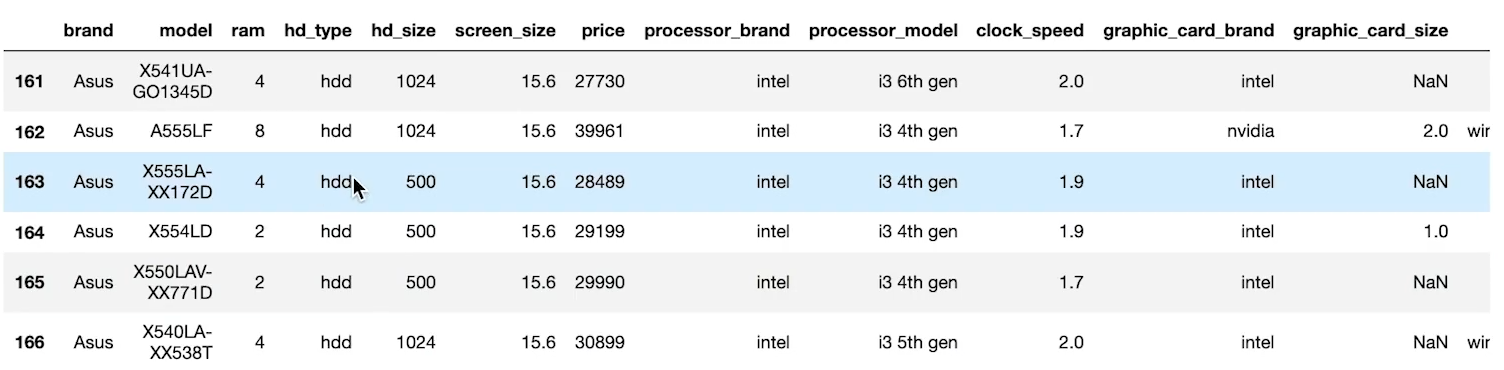
- columns 파악하기
laptops_df.columns
laptops_df.info() # 각 컬럼의 기본 정보 확인
# row 수 다른 경우는 해당 값이 비어있는 것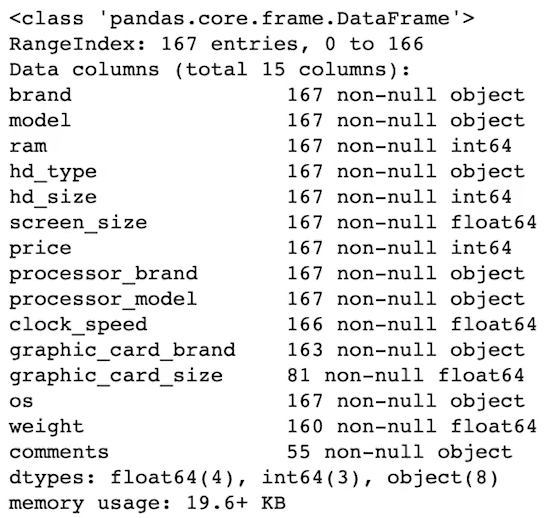
- DataFrame의 통계 정보 확인하기
laptops_df.describe() # 평균, 중간값, 최소최댓값, 표준편차 등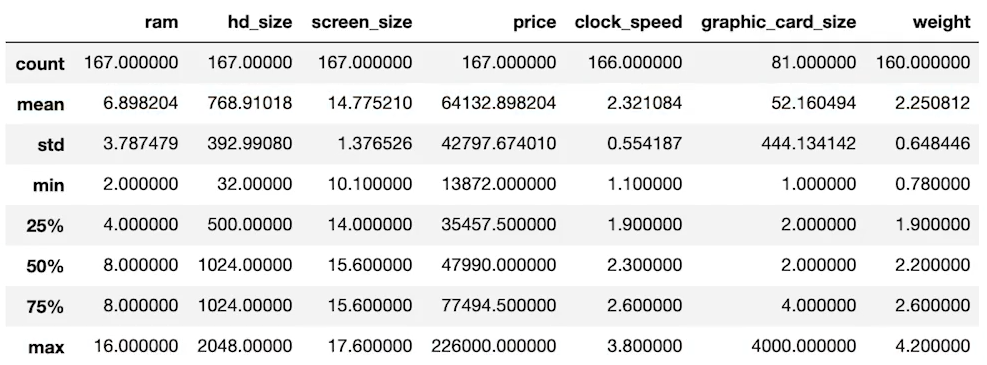
- 원하는 기준으로 정렬하기
- 기존 DataFrame 변경하지 않는다
- 변경:
inplace=True
- 변경:
- 기존 DataFrame 변경하지 않는다
laptops_df.sort_values(by='price') # 가격이 낮은 순으로 정렬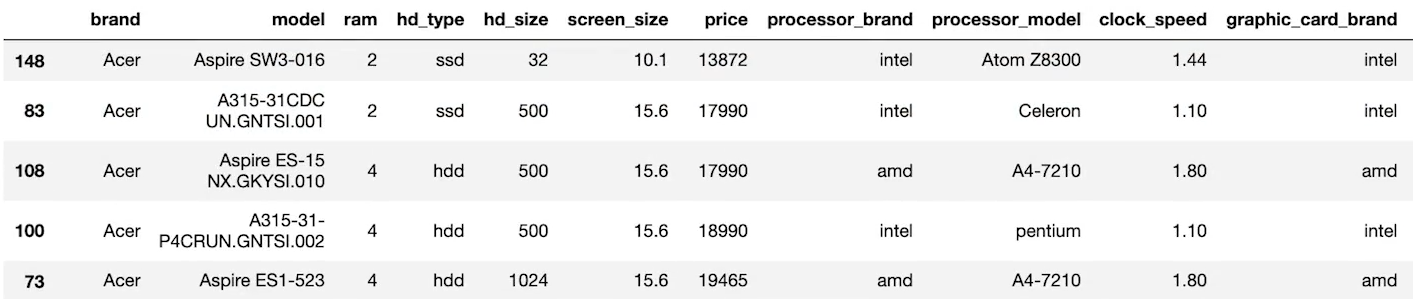
laptops_df.sort_values(by='price', ascending=False) # 가격이 높은 순으로 정렬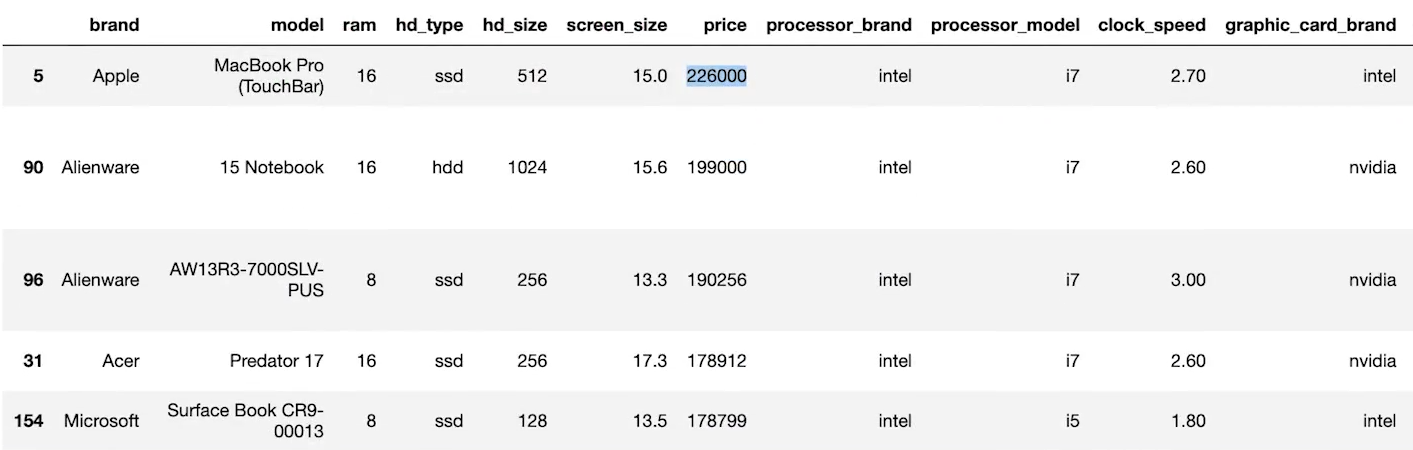
🦏 큰 Series 살펴보기
- 큰 Seires 살펴보기
- 중간에
...으로 생략된다
- 중간에
laptop_df['brand']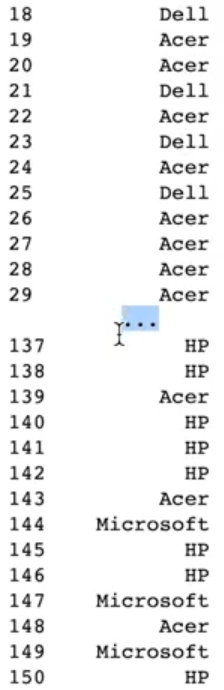
- 중복 데이터 제외하기
laptop_df['brand'].unique()
- 각 row 개수 파악하기
laptops_df['brand'].value_counts()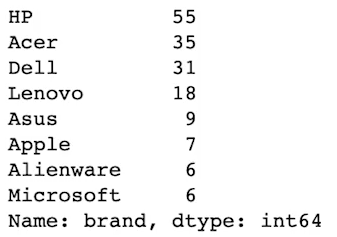
- 특정 row 정보 파악하기
laptops_df['brand'].describe()
* 출처: CODEIT - 데이터 사이언스 입문
There's Only One Thing To Do: Learn All We Can