💽 디지털 공학 개론
2진수의 표현
- 비트(bit)
- 2진숫자(binary digit)의 약어
- 디지털 시스템에서 수 혹은 문자와 같은 정보를 표현하는 기본 단위
- 0 혹은 1의 값을 가짐
- 비트 수에 따른 정수 표현 범위
- 비트 수(n) 많아질수록, 표현 범위 증가: 0~
2^n-1 - 예: n=3 >> 0~7(
2^3-1)
- 비트 수(n) 많아질수록, 표현 범위 증가: 0~
10진수에서 2진수로의 진법 변환
- 10진수 >> 2진수 변환
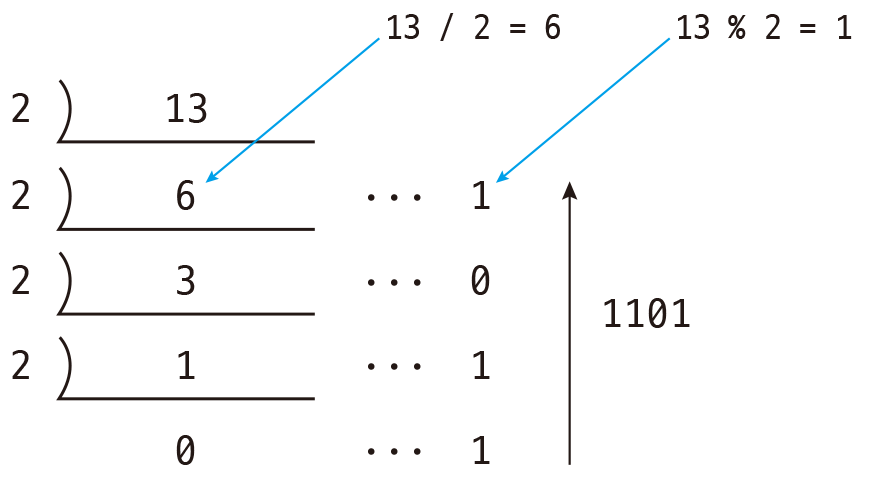
- 반복 2분법
- 10진수를 2로 나누고 나머지 값을 기록한다
- 몫이 0이 될 때까지 위 동작을 계속한다
- 가장 나중에 발생한 나머지 값부터 시작하여 이전의 나머지 값들을 순서대로 나열하여 2진수 비트 배열을 구한다
- 반복 2분법
- 2진수 >> 10진수 변환
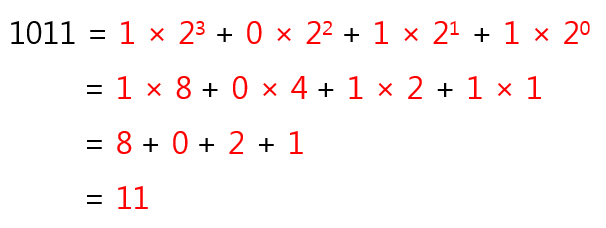
- MSB: 최상위 비트(맨 왼쪽)
- LSB: 최하위 비트(맨 오른쪽)
- 자릿수의 가중치만큼 곱한다
- 소수점 이하의 10진수를 2진수로 변환하는 절차
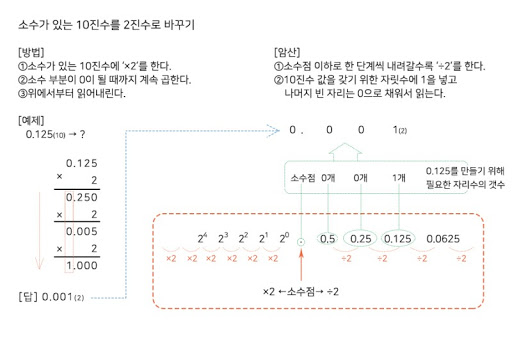
- 10진수에 2를 곱한다
- 결과값이 1보다 작으면 0을 기록하고 1보다 크면 1을 기록한 다음 1을 뺀다
- 위 결과값이 0이 될 때까지 위의 과정을 반복한다
- 소수점 이하의 2진수를 10진수로 변환하는 절차
- MSB의 좌측에 2진 소수점이 있는 소수

- MSB의 좌측에 2진 소수점이 있는 소수
- 오차 발생
- 10진수를 2진수로 변환하는 과정에서 제한된 개수의 비트로만 표현하기 때문이다
- 컴퓨터에 따라 8비트, 16비트 등 비트 수를 다르게 제한한다
- 0.6의 경우에 변환 과정에서 무한대로 연산이 이루어져서 8비트로 제한하면 다시 10진수로 복원했을 때, 0.59765625이 된다
- 워드(word)
- 디지털 컴퓨터에서 한 번에 저장 및 처리되는 비트 수
- 컴퓨터의 성능이나 가격에 따라 8비트, 16비트, 32비트, 혹은 64비트로 다양하다
- 작은 수를 표현할 때도 단어 내의 상위 비트들을 0으로 셋팅하여 정해진 비트수를 모두 채워야 해당 위치에 예상치 못한 값이 저장되는 것을 방지할 수 있다
- 예: 00000001
💻 마이크로프로세서
C언어의 제어문
- 문법 기능
- 순차: 순차적으로 문장을 수행하는 기능
- 선택: 참(true)과 거짓(false)에 따라 특정 루틴을 비교 선택하는 기능
- 반복: 어떤 조건을 만족할 때까지 일련의 문장을 반복 수행하는 기능
- IF문
if (조건식)
제어문1;
else
제어문2;if (x>0)
x+=1;
else
x-=1;- else if
if (a>0)
제어문1;
else if (a<0)
제어문2;
else
제어문3;- switch문
- 상수식은 int형으로 사용
- case의 어느 식에도 선택X >> default문 실행
- default 없고 일치하는 case 없을 때, 어떠한 문장도 실행X
- switch문을 벗어나기 위해서는 break이나 return문 사용
- switch문이 루프 속에 있으면 continue문을 사용하여 루프 벗어남
switch (수식) {
[ case 상수1 : ] [제어문1]
[ case 상수2 : ] [제어문2]
..
[ case 상수n: ] [제어문n]
[default : 제어문]
}i = 2
switch (i) {
case 1: a = 2;
break;
case 2: a = 4;
break;
case 3: a = 8;
break;
default: a = 0;C언어의 반복문
- For문
- 반복 작업을 제어하기 위해 세미콜론으로 구분된 세 가지 제어를 사용
- 초기식, 조건식, 증감식
- 초기화 조건문은 루프 문장의 다른 것이 수행되기 전에 한번만 수행
- 루프 내의 명령문을 수행하기 전에 조건을 검토하는 문장은 진입 조건 루프
- 실행문 부분은 단문 혹은 복문
for (초기식;조건식;증감식) {
statement(s);
}int i, sum=0;
for (i=1; i<11; i++) {
sum+=i
i+=1
}- While문
- while문은 while의 다음에 있는 괄호 안의 식을 보고
- 그 결과가 참이면 while문 다음의 문장을 실행
- 그 결과가 거짓이면 그 시점에서 루프를 벗어남
- while문 안에 while문을 탈출할 수 있는 수단이 필요하다
- while 문장은 프로그램 제어에 편리하고 융통성 있는 수단 제공
- 조건식이 참일동안 {} 사이의 문장들인 statement(s)를 반복하여 실행
- 조건식이 거짓이 되면 {} 부분을 더 이상 실행하지 않고 빠져나옴
- while(1)의 형식은 식의 값이 항상 1(참)이므로 무한 루프 수행
while (조건식) {
statement(s);
}while (c>0) {
...
c++;
}- do~while문
- 루프의 본체 부분이 먼저 한번 수행
- 그 후 테스트가 이루어지므로 루프 형식
- for 루프나 while 루프에서는 수행 전에 테스트
- do~while문은 반드시 한번은 do에 이어지는 문장 실행하고 조건 판정 수행
- 조건식에 관계 없이 일단 {} 사이의 제어문을 한번 실행한 후에 조건식 검사
- 조건식이 참일 동안 {} 사이의 문장들을 반복해서 실행
- 조건식이 거짓이 되면 {} 부분을 더이상 실행하지 않고 탈출
do {
제어문;
} while (조건식);do {
...
c--;
} while (c>0);기타 문법
- break문
- while문, do~while문, for문 안에서 루프를 탈출하기 위해서 사용
- switch 문에서 블록을 빠져나올 때 사용
- continue문
- continue문을 만나면 루프의 중간이더라도 다음 문장들은 실행시키지 않고 루프의 처음으로 돌아가 조건식과 비교하여 루프를 순환
- 루프의 중간에 어떤 조건 하에서 나머지 문장들을 실행할 필요가 없을 때 사용
int num=0, sum=0;
while (num++<100) {
if (num%2)
continue; // num이 홀수면 뒷 부분 실행하지 않음
sum+=num;
}- goto문
- 프로그램 수행 도중 goto문을 만나면 goto문 다음에 나오는 레이블로 점프 >> 레이블로부터 프로그램 수행
- 실행 도중 점프하면 프로그램 꼬임 >> 사용 권장X
goto 레이블;
...
레이블 문장int num=0;
while (num++<100) {
if (num==50)
goto label_1; // num이 50이면 label_1로 점프
P1=num;
}
label_1;
P1=100; // P1에 100 입력
}배열(Array)
- 배열의 개념
- 같은 형태의 변수들을 여러 개 묶은 변수의 집합
- 배열 변수는 여러 개의 변수들을 묶어 놓은 형태로 여러 개의 값을 저장
자료형 배열 변수 이름 [배열 요소 수]>> int a[100]- 배열에 정수 값을 저장할 경우 모든 값은 정수형
- 실수 값을 저장할 경우 모든 값은 실수형
- 최대 몇 개까지 값을 저장할 수 있는지를 나타내기 위해 배열 요소(크기) 지정
- 배열의 요소가 1개일 경우, 1차원 배열
- 2개인 경우([M][N]), 2차원 배열 >> 다차원 배열
- 배열 요소 수는 반드시 상수
- 1차원 배열
- 배열 요소의 수를 나타내는 [N]이 하나인 경우
- 선형 배열, 리스트, 벡터
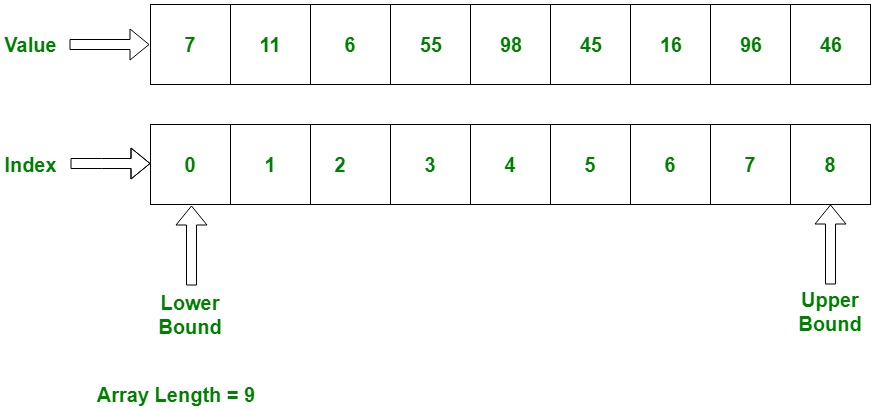
- 인덱스
- 요소의 위치값
- 임의의 위치에 존재하는 배열 요소에 접근하기 위해 사용
- 인덱스는 항상 0부터 시작(첫번째 배열 요소의 인덱스)
- 배열 요소 지정 시, 변경 불가 >> 비효율적
int arr[5];
arr[0]=10; // 인덱스 값 지정해서 초기화
arr[1]=20;
arr[2]=30;
arr[3]=40;
arr[4]=50;- 배열 초기화
- 선언과 동시에 초기화 가능
- 초기화시킬 값들을 모두 콤마로 구분해서 쓰고 전체를 중괄호로 묶음
int arr[5] = {1, 2, 3, 4, 5};
int arr[] = {6, 7, 8, 9, 10};- 2차원 배열 초기화
- 1차원 배열이 2개 이상 포함된 배열
- 배열 요소 크기[]가 2개인 배열로 행과 열의 구조
- 앞은 행(가로줄)을, 뒤는 열(세로줄)을 나타냄
- 2차원 배열의 초기화도 1차원 배열과 동일함
- 각각의 행별로 나누어서 초기화하는 2차원 배열만의 독특한 방법도 존재
- 행은 생략 가능하나 열은 절대로 생략하면 안된다
int arr[2][2];
int arr[2][2] = {1, 2, 3, 4};
int arr[2][2] = {{1,2}, {2,4}};
int arr[][2] = {{1,2}, {2,4}};💾 시스템 프로그래밍
저수준 파일 입출력 개요
- 특징
- 파일 기술자(file descriptor) 사용
- 바이트 단위
- 시스템 호출 이용
- 특수, 일반 파일
- 주요 함수
- open, close, read, write, ...
- 파일 기술자
- 현재 열려있는 파일 구분하는 정수값
- open 함수 사용하여 파일 열 때 순차적으로 부여
- 0: 표준 입력(키보드) / 1: 표준 출력(모니터) / 2: 표준 오류
- 0부터 순서대로 할당
- 파일 생성 및 열고 닫기
- 파일 열기 >> 파일 작업(읽고 쓰기) >> 파일 닫기
- 파일 열기: open(2)
- path: 열리는 파일이 있는 경로
- mode: 접근 권한
- oflag: 파일 상태 플래그(정수)
#include <sys/types.h>
#include <sys/stat.h>
#include <fcnt1.h>
int open(const char *path, int oflag [, mode_t mode]);- 주요 oflag
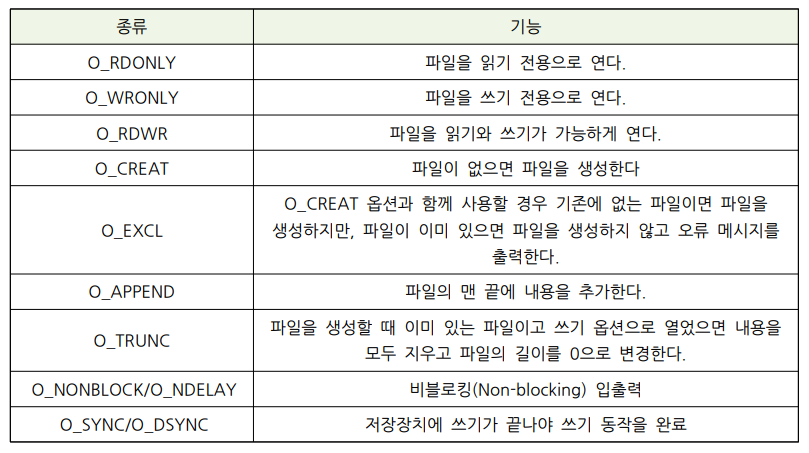
- 여러 개 플래그 사용:
|사용- 예: O_WRONLY | O_CREAT | O_TRUNC [쓰기 전용, 파일 없는 경우]
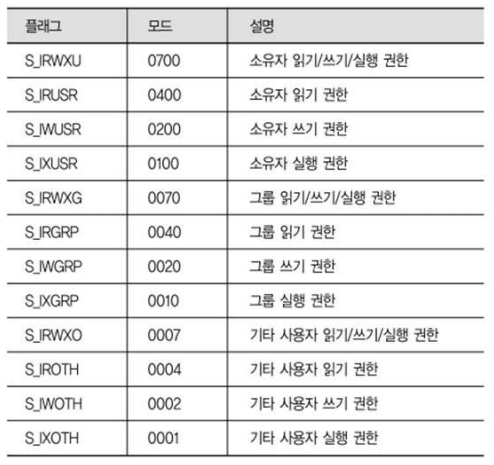
- mode
- O_CREAT 플래그 사용하여 파일 생성할 때만 사용
- <sys/stat.h> 파일에 정의된 플래그 사용 가능
- 파일 닫기: close(2)
- fildes: 파일 기술자
- 성공 시, 0 리턴
- 실패 시, -1 리턴
- 오류 코드를 외부 변수 errno에 저장
#include <unistd.h>
int close(int fildes);
- 파일 읽기: read()
- buf: 바이트를 읽어서 저장할 메모리 영역의 시작 주소
- nbytes: 읽어올 바이트 수
- 파일에서 nbytes로 지정한 크기만큼 바이트를 읽어서 buf에 저장
- 실제로 읽어온 바이트 개수를 리턴
- 리턴값이 0이면 파일의 끝에 도달했음을 의미
- 파일의 종류에 상관없이 무조건 바이트 단위로 읽어옴
#include <unistd.h>
ssize_t read(int fildes, void *buf, size_t nbytes);
- 파일 쓰기: write()
- buf가 가리키는 메모리에서 nbytes로 지정한 크기만큼 파일에 기록
- 실제로 쓰기를 수행한 바이트 수를 리턴(성공)
#include <unistd.h>
ssize_t write(int fildes, const void *buf, size_t nbytes);
- 파일 오프셋
- 파일을 읽고 쓸 위치를 알려줌
- 하나의 파일에 한 개만 존재
- off_t offset: 이동할 오프셋 위치(off_t 데이터형은 long)
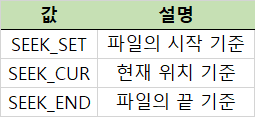
- whence: 오프셋 기준 위치(처음 or 뒤)
#include <sys/types.h>
#include <unistd.h>
off_t lseek(int fildes, off_t offset, int whence);- lseek
- 파일 기술자가 가리키는 파일에서 offset으로 지정한 크기만큼 오프셋을 이동시킨다
- 성공 시, 새로운 offset 값 리턴
- 실패 시, -1 리턴
- offset 값은 whence값을 기준으로 해석
- whence 값
- lseek(fd, 5, SEEK_SET): 파일의 시작에서 5번째 위치로 이동
- 파일 오프셋 현재 위치
- cur_offset = lseek(fd, 0, SEEK_CUR);
- 파일 기술자 복사하기: dup()
- 기존 파일 기술자를 인자로 받아 새로운 기술자 리턴
- 새로운 기술자는 자동 할당
#include <unistd.h>
int dup(int fildes);- 새로운 파일 기술자 지정 가능: dup2()
#include <unistd.h>
int dup2(int fildes, int fildes2);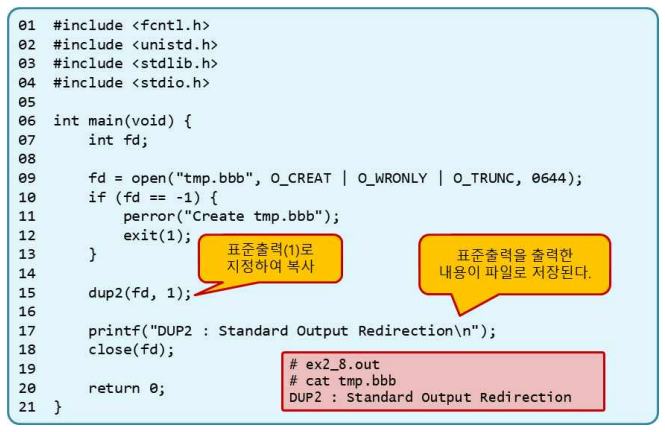
- 파일 기술자 제어: fcntl(2)
- 파일 기술자가 가리키는 파일에 cmd로 지정한 명령을 수행
- cmd의 종류에 따라 인자를 지정할 수 있음
- 자주 사용하는 cmd
- cmd: 명령
- arg: 인자
- F_GETFL: 상태 플래그 정보를 읽어온다
- F_SETFL: 상태 플래그 정보를 설정한다, 설정할 수 있는 플래그는 대부분 open 함수에서 지정하는 플래그다
#include <sys/types.h>
#include <unistd.h>
#include <fcntl.h>
int fcntl(int fildes, int cmd, /* arg */...)- 파일 삭제: unlink(2)
- path에 지정한 파일의 inode에서 링크 수를 감소시킨다
- 링크 수가 0이 되면 path에 지정한 파일이 삭제된다
- 파일 뿐만 아니라 디렉토리(빈 디렉토리 아니어도 됨)도 삭제된다
- path: 삭제할 파일의 경로
#include <unistd.h>
int unlink(const char *path);- 파일 삭제: remove(3)
- path에 지정한 파일이나 디렉토리를 삭제한다
- 디렉토리의 경우, 빈 디렉토리만 삭제한다
#include <stdio,h>
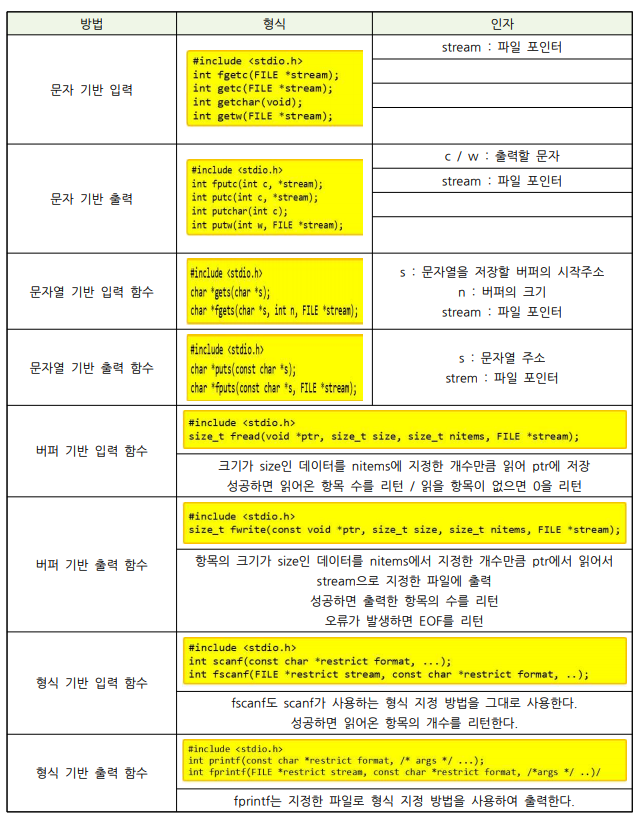
int remove(const char *path);고수준 파일 입출력 개요
- 특징
- 파일 포인터(file pointer) 사용
- 표준 함수 활용
- 표준 입출력 라이브러리라 함
- 입출력: 문자 단위, 행 단위, 버퍼 단위, 형식 기반 입출력 등 가능
- 파일 포인터
- 파일의 위치에 관한 정보 기억
- FILE *형
- FILE 구조체 가리키는 포인터
- 파일 열기: fopen(3)
- filename으로 지정한 파일을 mode로 지정한 모드에 따라 열고 파일 포인터를 리턴
- 성공 시, 파일의 주소를 파일 포인터로 리턴
- 실패 시, 0 리턴
- filename: 파일의 경로
- mode: 파일 열기 모드
#include <stdio.h>
FILE *fopen(const char *filename, const char *mode);
FILE *fp;
fp = fopen("unix.txt", "r");- 파일 닫기: fclose(3)
- fopen으로 연 파일을 닫는다
- 성공 시, 0 리턴
- 실패 시, EOF(-1) 리턴
- stream: fopen에서 리턴한 파일 포인터
#include <stdio.h>
int fclose(FILE *stream);
- 파일 오프셋: fseek(3)
- stream이 가리키는 파일에서 offset에 지정한 크기만큼 오프셋을 이동
- whence는 lseek과 같은 값을 사용
- 성공 시, 0 리턴
- 실패 시, EOF 리턴
- offset: 이동할 오프셋
- whence: 오프셋의 기준 위치
#include <stdio.h>
int fseek(FILE *stream, long offset, int whence);- 파일 오프셋: ftell(3)
- 현재 오프셋을 리턴
- 오프셋은 파일의 시작에서 현재 위치까지의 바이트 수
#include <stdio.h>
int ftell(FILE *stream);- 파일 오프셋: fsetpos(3)
- 파일의 현재 오프셋을 pos가 가리키는 영역에 저장
- 성공 시, 0 리턴
- 실패 시, 0이 아닌 값
- pos: 오프셋을 저장하고 있는 영역 주소
- 파일 오프셋: fgetpos(3)
- pos가 가리키는 영역의 값으로 파일 오프셋 변경
- 성공 시, 0 리턴
- 실패 시, 0이 아닌 값 리턴
#include <stdio.h>
int fsetpos(FILE *stream, const fpos_t *pos);
int fgetpos(FILE *stream, fpos_t *pos);📠 운영체제
저급 언어
- 기계어
- 컴퓨터 시스템을 위하여 직접 사용되는 언어
- 컴퓨터가 직접 이해 가능한 언어 사용
- 사용자가 이해하고 작성하기 어려움
- 2진수 형태로 표현
- 프로세스 시간이 빠름
- CPU 내장 명령어를 직접 사용
- 컴퓨터 시스템 간 언어 호환이 어려움
- 어셈블리어
- 기계어 또는 컴퓨터 시스템을 제어하기 위한 언어
- 명령어를 쉽게 연상할 수 있는 기호를 기계어와 1:1로 연관시켜 만든 언어
- 니모닉(연상/상징)언어
- 컴퓨터 시스템이 직접 이해하기 어려우나 기계어에 가까운 언어
- 사용자가 이해 가능한 언어
- 컴퓨터 시스템마다 호환 어려움
- 기계어로의 번역을 위한 어셈블러라는 언어 번역 프로그램을 활용해야 함
- 어셈블리어 명령
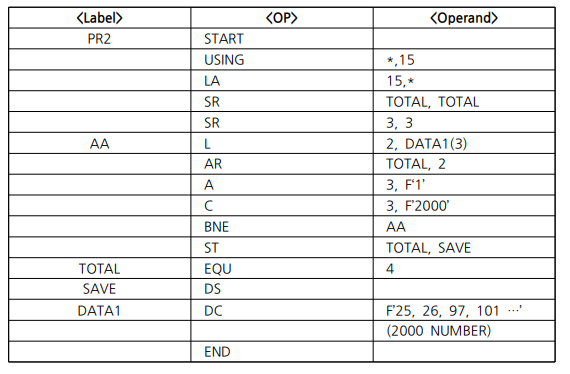
- [의사 명령어]: 원시 프로그램을 어셈블할 때 어셈블러가 해야할 동작 지시(START, END, USING, DROP)
- [실행 명령]: 데이터 처리 명령
- 어셈블리어 명령어 형식
- Label: 데이터를 기억할 장소, 분기할 위치, 기호 상수 등에 대한 기호(symbol)를 기술하는 부분 >> 생략 가능
- OP: 명령어(OP-code)를 기술하는 부분
- Operand: 명령어(OP-code)가 연산을 수행하기 위한 연산의 대상이 되는 Literal(상수, 데이터)이나 주소, register 번호 등을 기술하는 부분
- DATA1 기억 장소에 있는 데이터 2000개의 합을 구하여 SAVE 기억 장소에 저장하는 프로그램
고급 언어
- 고급 언어
- 인간이 사용하는 언어(자연어)와 비슷한 형태의 언어
- 자연어를 기계어로 번역하기 위한 컴파일러 혹은 인터프리터라는 언어 번역 프로그램이 필요한 언어
- 컴파일러 언어라고도 함
- 프로그램 흐름을 충분히 파악한다면 프로그램의 작성과 수정이 쉬움
- 사용자가 사용하는 프로그래밍 언어 대부분이 고급언어(저급 언어 제외)
- 컴파일러를 사용하는 고급 언어
- C, C++, FORTRAN, COBOL, ALGOL, PASCAL, PL/1...
- 인터프리터를 사용하는 고급 언어
- BASIC, LISP, APL...
- 언어 번역 프로그램의 종류
- 어셈블러
- 기계 명령과 절대 주소에 기호를 부여한 어셈블리 언어를 입력 받아서 목적 프로그램을 생성하는 번역기
- 1패스, 2패스(일반적)
- 2패스: 첫 패스에서 기호표를 만들고 두 번째 패스에서 기호표를 이용하여 기계어 번역 완성
- 컴파일러
- 고급 언어로 작성된 프로그램 모듈 전체를 번역하여 목적 프로그램을 생성하는 번역기
- 인터프리터
- 고급 언어로 작성된 원시 프로그램을 한 문장씩 번역하여 즉시 실행하는 번역기
- 매크로 프로세서
- 매크로 명령문을 해당 어셈블리 언어의 명령문으로 확장시켜주는 프로세서
- 매크로 정의 인식, 매크로 정의 저장, 매크로 호출 인식, 매크로 호출 확장, arguement 치환
- 프리 프로세서
- 고급 언어인 원시 프로그램을 또 다른 고급 언어로 번역하는 번역기
- 크로스 컴파일러
- 한 컴퓨터에서 실행되는 프로그램을 다른 컴퓨터에서 실행될 수 있도록 번역할 때 사용하는 컴파일러
- 어셈블러
📺 전산 개론
수치와 문자의 표현
- 연산에 사용하지 않는 수와 문자는 약속된 코드인 아스키코드나 유니코드를 사용
- 컴퓨터 내부의 모든 정보는 이진수로 표현한다
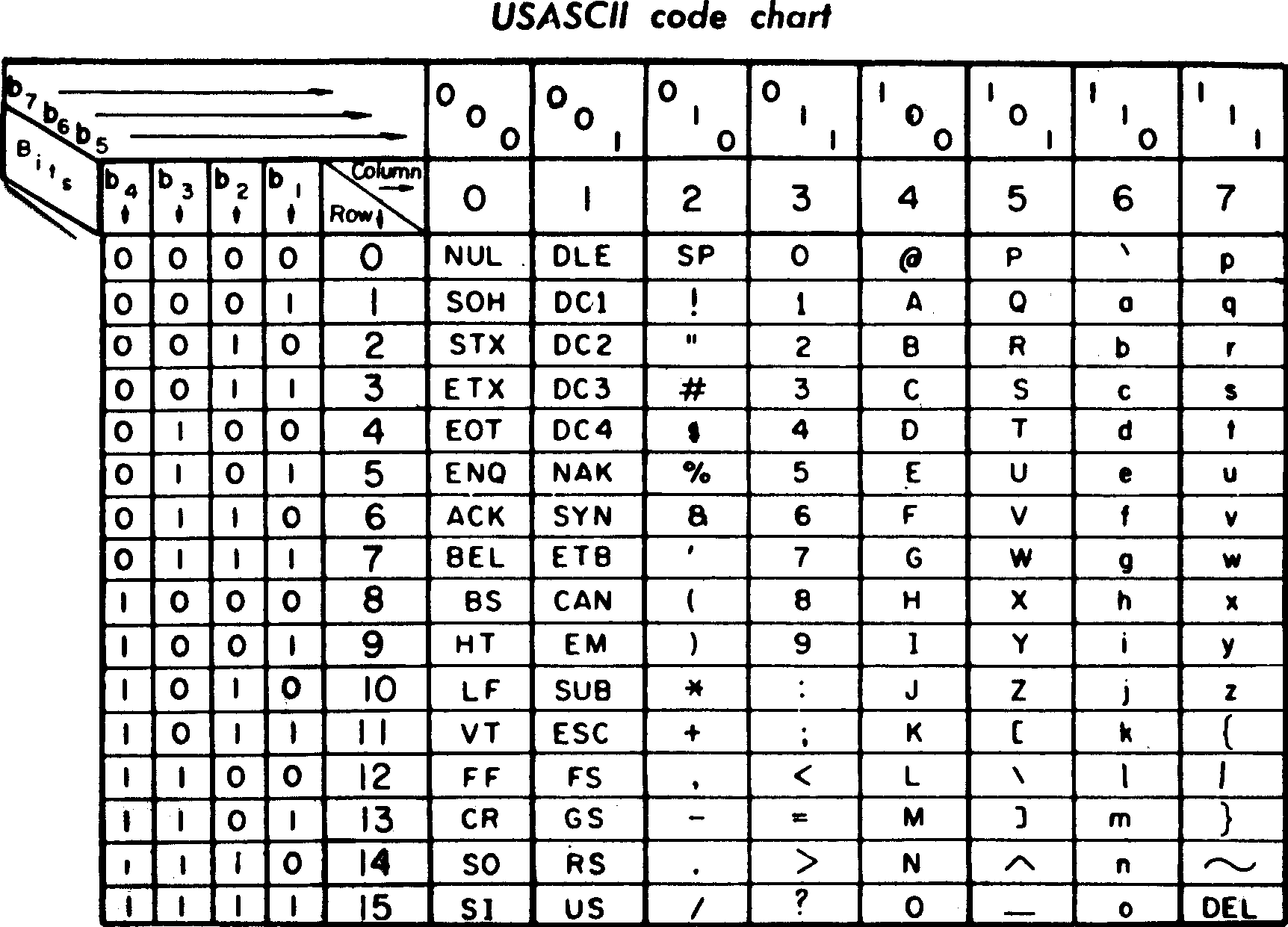
- ASCⅡ코드
- 미국 표준(ANSI)에서 영문자를 이해 제정된 코드
- 3개의 존(zone)과 4개의 디지트(digit)로 127가지 서로 다른 문자로 표현
- 오늘날에는 1비트 추가(패리티비트)해서 8비트로 사용
- 유니코드
- 영어를 제외한 언어에 사용할 수 있는 확장된 16비트 새로운 코드
- ASCⅡ코드 포함
- 한글, 중국어, 일본어, 히브리어 등 다양한 언어를 위해 코드 영역 지정
- 16비트 혹은 32비트로도 확장
- 텍스트 호환성
- 한글
- 초성, 중성, 종성
- ASCⅡ코드와 같이 8비트로는 불가능하여 2바이트로 표현
- 조합형 및 완성형 코드에서 글꼴이 예쁜 완성형 사용
- 자음 + 모음 >> 음절 >> 단어
- 한글
멀티미디어 정보의 표현
- 정보 단위와 수의 표현
- 비트(bit), 바이트(byte), 워드(word)
- 비트: 0과 1과 같은 가장 작은 정보를 나타내는 단위
- 바이트: 비트 8개의 모임, 영어 한 글자를 표현
- 예: 비트 패턴 "10011100"
- 워드: 컴퓨터에 따라 상이하고 주소나 명령어를 표기하는 데 사용
- 예: 16비트, 32비트, 64비트 등
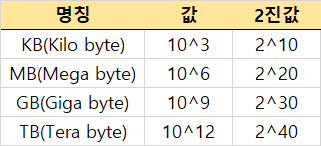
- 1KB(Kilo Byte) = 2^10Byte = 1024Byte
- 1MB(Mega Byte) = 2^20Byte = 1048576Byte(약 100만)
- 1GB(Giga Byte) = 2^30Byte = 1073741824Byte(약 10억)
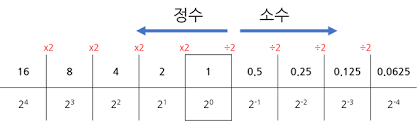
- 수의 표현과 진법
- 각 진법(2, 8, 10, 16)은 진법을 구성하는 숫자와 밑으로 구성된다
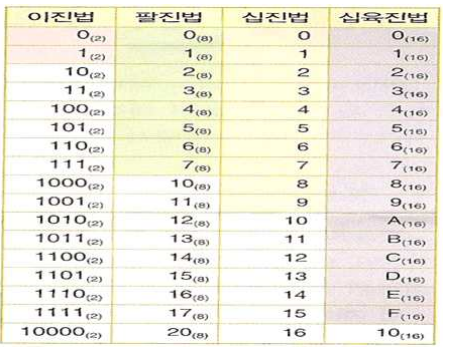
- 각 진법(2, 8, 10, 16)은 진법을 구성하는 숫자와 밑으로 구성된다
- 수의 변환
- 10진수에서 다른 진수로 변환
- 구하고자 하는 진수의 밑 수로 나누어 생긴 나머지를 역순으로 표기하면 된다
- 나눗셈 이용
- 다른 진수에서 십진수로 변환
- 십진수로 표현하려면 변환하는 수의 각 자리에 해당하는 자리 값을 곱한 수를 각각 더하면 된다
- 다항식(폴리노미오) 표현
- 2진수, 8진수, 16진수의 상호 변환
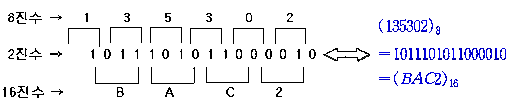
- 8진수 한 자리는 2진수 세 자리, 16진수 한 자리는 2진수 네 자리로 각각 나누어서 표현하면 된다
- 소수점이 있는 경우는 소수점을 기준으로 구분하여 좌, 우로 나누어서 변환하고 필 캐릭터는 0으로 채운다
- 10진수에서 다른 진수로 변환
- 정수의 표현
- 부호-크기 방식
- 제일 왼쪽 비트(MSB: Most Significant Bit): 정수의 부호(음수는 1, 양수는 0)
- 나머지 비트: 정수의 절대값, 부호만 다름
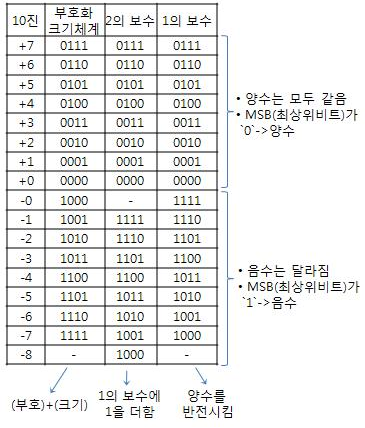
- 2의 보수
- 보수 = 반전
- +1 >> 2의 보수
- 010 >> 101(1의 보수) + 1 >> 110(2의 보수)
- 부호-크기 방식
- 정수의 덧셈과 2의 보수 방식
- 부호-크기 방식
- a+b >> a, b의 부호와 절대값에 따라 복잡한 과정
- 2의 보수 방식
- a+b >> 정수 a,b의 부호와 크기에 관계 없음
- 0의 표현이 한 가지

- 부호-크기 방식
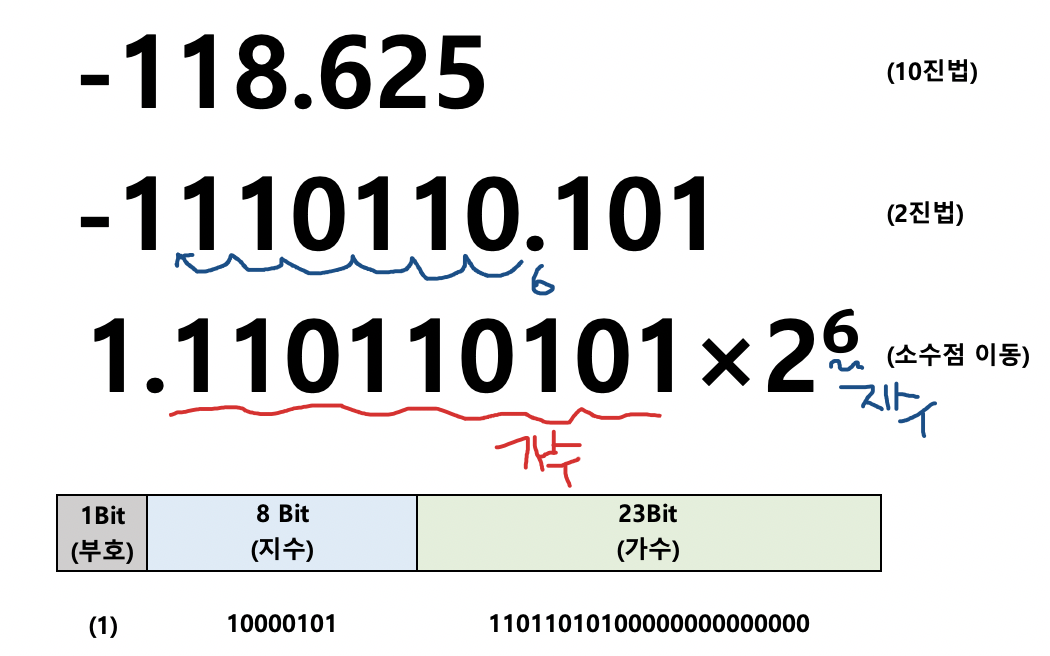
- 실수의 표현
- 아주 큰 수나 아주 작은 수를 표현하는 데 사용
- 부동 소수점 실수
- 상용로그 밑 10
- 상용로그 밑 10
- 정규화 부동 소수점 실수
- 소수점 다음에 항상 1이 오도록 정규화

- 소수점 다음에 항상 1이 오도록 정규화
- 아주 큰 수나 아주 작은 수를 표현하는 데 사용
출처: kg 아이티뱅크
There's Only One Thing To Do: Learn All We Can