💽 디지털 공학 개론
8진수와 16진수
- 8진수
- 0~7까지 숫자를 이용하여 수를 표현
- 7보다 더 큰 숫자를 표시할 때는 두 개 이상의 8진 숫자를 이용한다
- 두 자리를 사용하는 경우 좌측 숫자의 자릿수는
8^1=8이고, 우측 숫자의 자릿수는8^0=1이 된다
- 16진수
- 0~15까지의 숫자를 한자리 수로 표현 가능
- 0~9, A~F까지로 한자리에 수를 표현
- 비트 패턴
- 8진수 1자리는 2진수 3비트로 표현 가능 (
2^3=8) - 16진수 1자리는 2진수 4비트로 표현 가능(
2^4=16) - 8진수와 16진수의 2진 비트 패턴
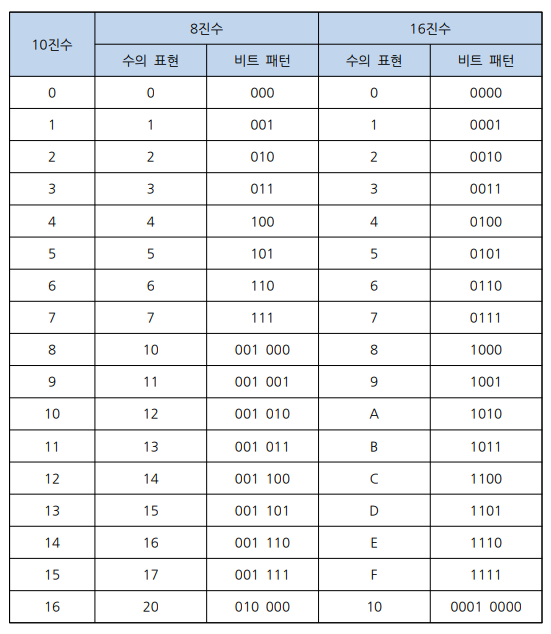
- 8진수 1자리는 2진수 3비트로 표현 가능 (
진법 변환
- 10진수 >> 8진수 변환
- 반복 8분법(repeated division by-8 method)
- 8로 반복하여 나눈 다음에 나머지 수들을 역으로 나열
- 반복 8분법(repeated division by-8 method)
- 2진수 >> 8진수 변환
- 비트 분할 방법(bit-partition method)
- 3비트씩 묶어서 변환하는 방법

- 8진수 >> 2진수 변환
- 각 8진 숫자 한 자리를 2진 3비트 단위로 변환

- 각 8진 숫자 한 자리를 2진 3비트 단위로 변환
- 10진수 >> 16진수 변환
- 반복 16분법을 사용할 경우 작업이 번거롭고 오류가 나기 쉽다
- 10진수를 먼저 2진수로 변환 >> 비트 분할 방법
- 2진수 >> 16진수 변환
- 2진 소수점을 중심으로, 좌측 및 우측 방향으로 네 비트씩 분활하여 변환
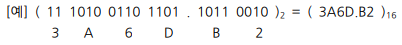
- 2진 소수점을 중심으로, 좌측 및 우측 방향으로 네 비트씩 분활하여 변환
- 16진수 >> 2진수 변환
- 각 16진 숫자에 대해 4비트 단위로 변환

- 각 16진 숫자에 대해 4비트 단위로 변환
💻 마이크로프로세서
함수(function)
- 함수
- 입력에 대해 적절한 출력을 발생시켜주는 것
- 프로그래머가 작성한 명령문을 연산, 처리, 실행해주는 부분(모듈)
- 자체적으로 실행되지 않으며, 반드시 함수 호출문에 의해서만 실행됨
- 함수의 이름과 괄호()로 구성
- 머리(header) 부분
- 명령문이 있는 중괄호로 구성된 몸체(body)
함수 이름()
{
변수 선언 및 실행 문장들;
}#include <stdio.h>
void sub(); // 함수의 선언
void main()
{
...
sub(); // 함수 호출
}
void sub() // 호출되는 함수(피 호출 함수)의 정의
{
...
}- 함수의 자료형(되돌려줄 값의 자료형)
- 함수는 어떠한 값을 호출 시켜준 함수에 다시 되돌려 줄 수 있는 기능이 있다
- return
#include
int cal(); // 함수(피 호출 함수)의 선언
int main()
{
int add = cal(); // cal() 함수의 호출 및 리턴 대기
printf("덧셈의 결과 값: %d\n", add);
return 0;
}
int cal() // 정수형 리턴 정의
{
int a=20, b=30, add;
add = a + b;
return add; // add 변수를 리턴포인터
- 포인터
- 메모리를 사용하는 방법 중 하나
- 주소 연산자로 변수가 할당된 메모리의 위치를 확인
- 포인터로 가리키는 변수를 사용할 때, 간접 참조 연산자를 쓴다
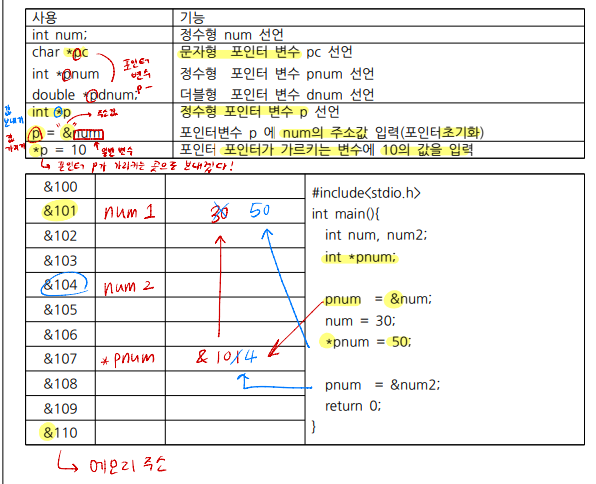
- 인수를 가지는 함수
- 모든 함수는 함수의 호출에 의해서만 실행된다
- 실행 제어권이 호출 함수에서 피 호출 함수로 넘어간다
- 피 호출 함수의 실행이 모두 끝나면 다시 호출 함수에게로 실행 제어권이 넘어간다
- 함수 간에는 실행 제어권과 같이 특정 값(변수, 상수 등)을 서로 주고 받을 수 있다
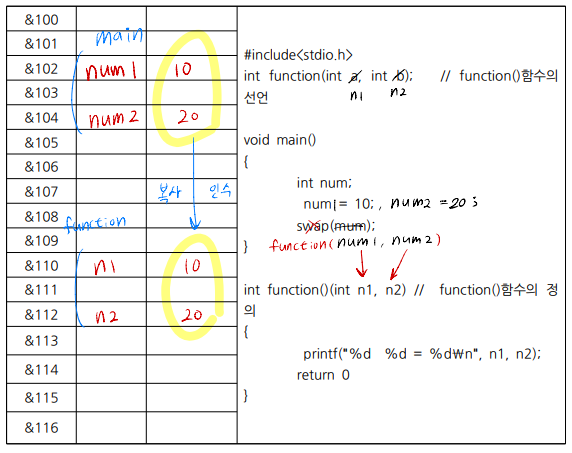
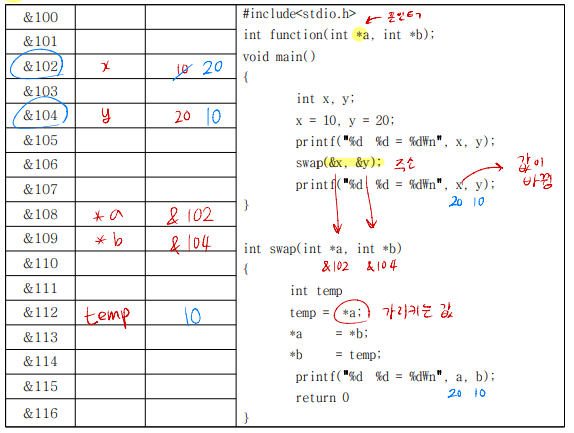
- Call by Value(값에 의한 함수 호출)
- C언어에서 함수로의 데이터 전달 방법 중 하나
- 실제 값을 복사해서 전달시켜주는 방식
- sub 함수에서의 변수 변화가 main 함수에 반영되지 않는다

- Call by Reference(주소에 의한 함수 호출)
- 실제 값이 존재하는 메모리 공간의 주소를 전달해 주는 방식
- 주소 연산자와 포인터 연산자를 이용해서 함수 간에 주소를 전달하는 방법
- sub 함수에서의 변수 변화가 main 함수에 반영된다
구조체
- 구조체
- 하나 이상의 기본 자료형을 기반으로 사용자가 임의로 정의한 자료형의 모음
- 서로 다른 타입을 하나의 그룹으로 묶는 것
- 멤버 변수: 구조체 안에서 정의된 변수로 일반적인 변수 선언과 동일
- 구조체의 멤버로는 배열, 포인터 변수, 이미 정의된 다른 구조체의 변수 등 모든 응용 자료형을 사용할 수 있다
struct 구조체형 이름{
데이터 형식 멤버 변수1;
데이터 형식 멤버 변수2;
...
};
struct 구조체형 이름 구조체 변수;struct point
{
int x;
char y;
}- 구조체의 사용
struct point{
int x;
char y;
};
int main()
{
struct point p1 // 객체 p1 선언
p1.x=10; // p1의 멤버 x에 10 대입
p1.y='k'; // p1의 멤버 y에 'k' 대입
...
return 0;
}- 구조체 초기화
- 중괄호{} 안의 초기값을 콤마로 분리하여 대입
struct point{
int x;
double y;
};
int main()
{
struct point pin = {10, 10.5}; // 객체 선언과 함께 초기화
}- 구조체 배열
#include <stdio.h>
struct student{
char name[10];
int kor;
int eng;
float avg;
};
int main()
{
struct student s[3];
s[0].kor = 50;
s[1].eng = 55;
s[2].avg = 52.5;
}- 구조체 포인터
#include <stdio.h>
struct student{
char name[10];
int kor;
int eng;
float avg;
};
int main()
{
struct student s;
struct student *p;
p=&s;
s.kor = 50; // s를 이용한 직접 표현 방식
p->kor = 50; // *p를 이용한 간접 표현 방식
(*p).kor = 50; // *p를 이용한 직접 표현 방식
}💾 시스템 프로그래밍
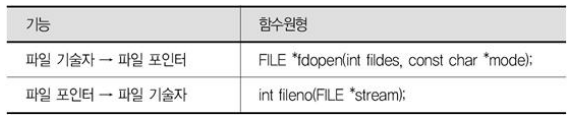
파일 기술자 / 파일 포인터
- 파일 기술자와 파일 포인터 간 변환
- 파일 기술자에서 파일 포인터 생성: fdopen(3)
- 파일 포인터에서 파일 기술자 정보 추출: fileno(3)
- fdopen(3)
- 성공 시, 파일 포인터 리턴
- 실패 시, NULL 리턴
- fildes: 파일 기술자
- mode: 열기 모드
#include <stdio.h>
FILE *fdopen(int fildes, const char *mode);
- fileno(3)
- stream: 파일 포인터
#include <stdio.h>
int fileno(FILE *stream);
임시 파일 입출력
- 임시 파일명 생성
- 임시 파일명이 중복되지 않도록 임시 파일명 생성
- tmpnam(3)
- 임시 파일명을 시스템이 알아서 생성
- 인자 있을 경우, 해당 인자가 가리키는 곳에 임시 파일명 저장
- 인자가 NULL일 경우, 임시 파일명을 리턴
- s: 파일명을 저장할 버퍼의 시작 주소
#include <stdio.h>
char *tmpnam(char *s);- tempnam(3)
- 임시 파일명에 사용할 디렉토리와 접두어 지정하여 임시 파일명 리턴
- 접두어는 다섯 글자만 사용
- dir: 임시 파일명의 디렉토리
- pfx: 임시 파일명의 접두어
#include <stdio.h>
char *tempnam(const char *dir, const char *pfx);- mktemp(3)
- 인자로 임시 파일의 템플릿을 받아 이를 임시 파일명으로 리턴
- 템플릿은 대문자 'X' 6개로 마쳐야 함
- template: 임시 파일명의 템플릿
#include <stdlib.h>
char *mktemp(char *template);
- 임시 파일의 파일 포인터 생성
- tmpfile(3)
- 자동으로 w+ 모드로 열린 파일 포인터를 리턴
- tmpnam(), tempnam(), mktemp() 함수들을 임시 파일만 생성함
- 파일을 열어야 하는데 파일명을 알 필요 없고 파일 포인터만 알면 됨
#include <stdio.h>
FILE *tmpfile();
📠 운영체제
어셈블러
- 어셈블리어로 작성된 원시 프로그램을 기계어로 번역하는 언어 번역 프로그램
- 어셈블: 어셈블리어로 작성된 원시 프로그램을 목적 프로그램으로 번역하는 과정

- 어셈블 과정
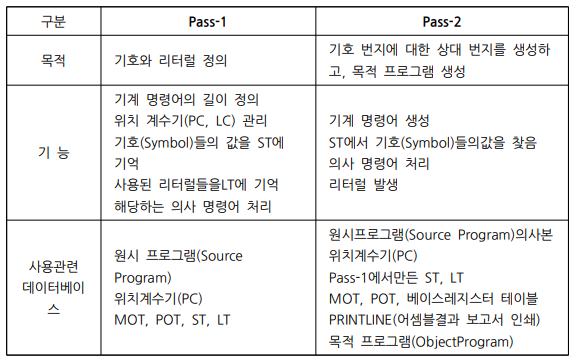
- 단일 패스 어셈블러(pass-1, One Pass Assembler)
- 원시 프로그램을 명령문 하나씩 읽어서 기계어로 번역하여 목적 프로그램을 생성
- 이중 패스 어셈블러(pass-2, Two Pass Assembler)
- 원시 프로그램을 두 번 읽는데 1단계 작업을 수행하기 위해 한 번 읽고 난 후, 2번째로 읽으면서 1단계 결과를 이용하여 완전한 목적 프로그램을 생성한다
- 단일 패스 어셈블러(pass-1, One Pass Assembler)
- Table의 종류 및 구성
- 기계 명령어 테이블(MOT, Machine Operation Table)
- 의사 명령어 테이블(POT, Pseudo Operation Table)
- 기호 테이블(ST, Symbol Table)
- 리터럴 테이블(LT, Literal Table)
- Pass-1과 Pass-2 비교
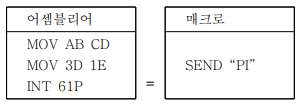
매크로 프로세서(Macro Processor)
- 어셈블리어 + 매크로 >> 매크로 프로세서 >> 어셈블러 >> 기계어
- 매크로 프로세서의 역할
- 어셈블리어를 사용하기 쉽게 명령어들을 문자로 치환
- 매크로 라이브러리: 자주 사용되는 매크로들을 모아놓은 곳
- 문자열 치환처럼 사용된 횟수만큼 명령어를 생성/삽입해서 실행
- 매크로 정의 내에 또 다른 매크로 정의를 할 수 있다
- 파스칼 언어는 매크로 프로세서 기능이 없다
- 매크로 프로세서의 기능
- 매크로 정의 인식
- 매크로 정의 저장
- 매크로 호출 인식
- 매크로 확장 및 인수
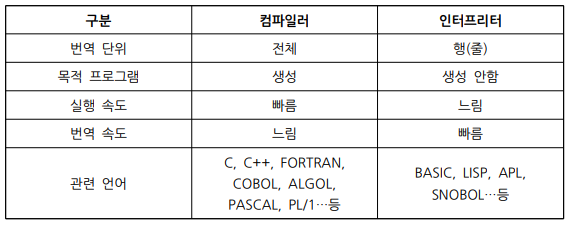
컴파일러와 인터프리터의 비교
- 컴파일러
- 언어 번역 프로그램이 고급 언어 종류마다 다름
- 고급 언어를 이용하여 작성된 프로그램을 번역하고 실행하는 과정
- 고급 언어로 작성된 프로그램을 목적 프로그램으로 번역한 후, 링킹과 로더의 작업을 하여 컴퓨터에서 실행 가능한 실행 프로그램(기계어)으로 바꿔줌
- 번역하는 과정이 번거롭거나 복잡하고 시간이 오래 걸릴 수 있음
- 컴파일러에 의해 번역이 끝난 실행 프로그램은 실행 속도가 빠름
- 컴파일러를 이용하는 고급 언어: C, C++, FORTRAN, COBOL...
- 인터프리터
- 언어 번역 프로그램이 고급 언어 종류마다 다름
- 고급 언어를 이용하여 작성된 프로그램을 한 줄 단위로 받아들여서 번역함과 동시에 프로그램을 한 줄 단위로 실행
- 목적 프로그램이 생성되지 않고 프로그램이 직접 실행
- 목적 프로그램 생성X >> 번역 속도 빠름
- but 실행할 때마다 번역해야 하는 번거로움 >> 실행 속도 느림
- 원시 프로그램의 수정과 변화에 빠르게 반응
- 줄 단위로 번역과 실행이 되므로 시분할 시스템에 유용
- 시분할 시스템을 사용하지 않을 경우, CPU 사용 시간에 따른 시간 낭비가 큼
- 인터프리터를 이용하는 고급 언어: BASIC, LISP, APL...
- 컴파일러 vs. 인터프리터
링커와 로더
- 링커
- 언어 번역 프로그램에 의해 생성된 목적 프로그램, 라이브러리, 실행 프로그램 등을 연결해 주는 시스템 소프트웨어
- 로더
- 실행 프로그램 또는 실행 프로그램에 필요한 정보와 자료를 보조기억장치로부터 주기억장치로 적재하는 시스템 소프트웨어
- 로더의 기능
- 할당: 목적 프로그램이 실행될 주기억장치(RAM)의 공간을 마련
- 연결: 여러 개의 독립 모듈을 연결
- 재배치: 주기억장치 공간 내에서 프로그램의 위치 변경
- 적재: 주기억장치에 프로그램을 한꺼번에 적재하거나 필요할 때마다 부분별로 적재
- 로더의 종류
- Compile And Go 로더: 번역 프로그램과 로더가 하나로 구성되어서 번역 프로그램이 로더의 역할까지 담당하는 방식
- 절대 로더: 로더의 역할이 축소되어 가장 간단한 프로그램을 구성한 것, 기억 장소 할당이나 연결을 프로그래머가 직접 지정
- 직접 연결 로더: 로더가 할당, 연결, 재배치, 적재를 모두 수행하는 일반적인 형태
- 동적 적재 로더
- Binding 로더: 할당, 연결, 재배치만 하는 로더로써 프로그램을 실행하기 전에 모든 준비만 담당
- Module 로더: 적재만 담당하는 로더
- 동적 적재 로더: Load-on-call, CPU가 현재 사용 중인 부분만 적재하고 미사용 프로그램은 보조기억장치에 저장해 두는 방식
📺 전산 개론
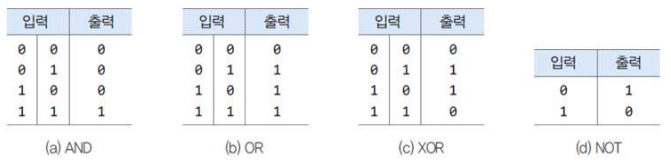
부울 대수
- 2진 연산 정보를 이용해서 컴퓨터에서 명제를 참과 거짓으로 판정하는 논리인 것을 강조
- 2진 연산 논리는 집합의 연산과 같음을 강조
- 1974년 수학자 부울(George Boole)에 의해 고안
- 참/거짓(True/False)에 대한 논리 자료의 연산
- 부울 대수가 디지털 논리 회로에 적용 >> 스위칭 대수에서 0은 전기가 흐름, 1은 전기가 끊긴 상태
- AND(교집합), OR(합집합), NOT(여집합)(=기본 논리 회로), XOR, NAND(=NOT+AND), NOR(=NOT+OR) 등
- 집합과 달리 불 대수는 원소가 0(거짓)과 1(참)으로 구성되며, 인간의 지식이나 사고 과정을 수학적으로 해석한 것으로 논리 대수라고도 함
- 진리표(Truth Table)
디지털 논리 회로
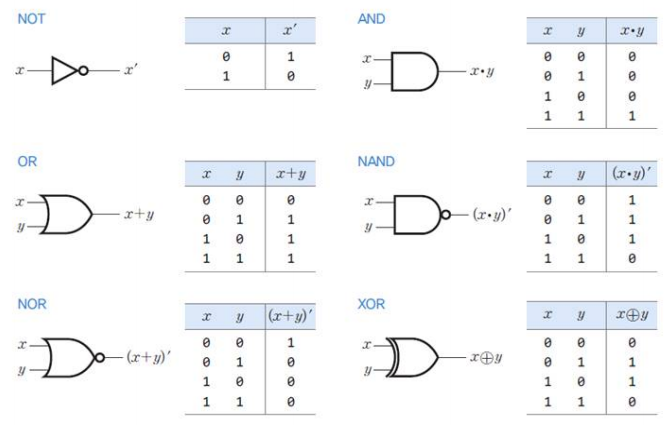
- 컴퓨터 내부에서 명제를 참과 거짓으로 판단하기 위해서는 논리 연산이 필요하고 이를 하드웨어로 구현한 것이 논리 회로
- 논리 게이트 개념
- 게이트: 가장 작은 단위의 디지털 논리 회로로서 부울 연산을 처리하는 장치로 한 개 이상의 입력과 하나의 출력으로 구성
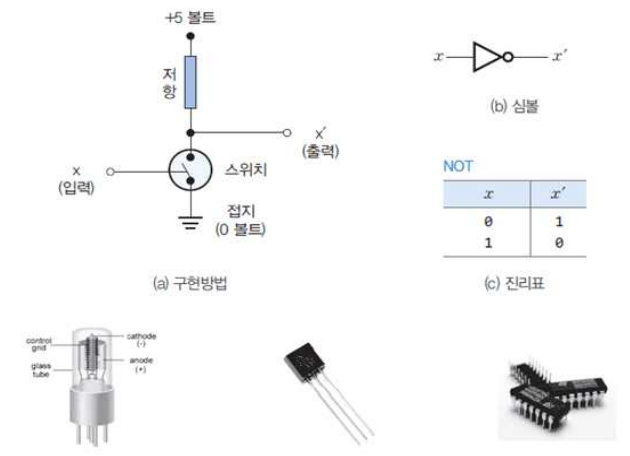
- NAND 게이트와 NOR 게이트가 가장 자주 사용하는 게이트로 NOT 게이트(inverter)에 의해 실현
- 인버터는 트랜지스터에 의해 실현, 과거에는 릴레이와 진공관 이용
- 인버터와 같이 작동하는 회로를 스위치라 부름
- 인버터를 직렬과 병렬로 연결하여 NAND 회로, NOR 회로 구성
- 디지털 논리 회로의 구성 요소인 게이트
- 스위치 기능을 수행하는 인버터(NOT 게이트)
- NOR 게이트의 실현
- 두 개의 스위치를 병렬로 연결
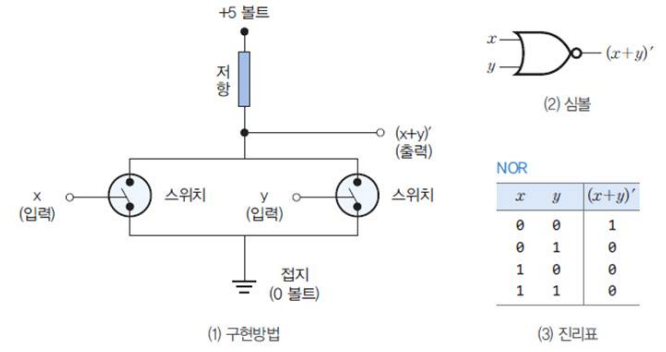
- 두 개의 스위치를 병렬로 연결
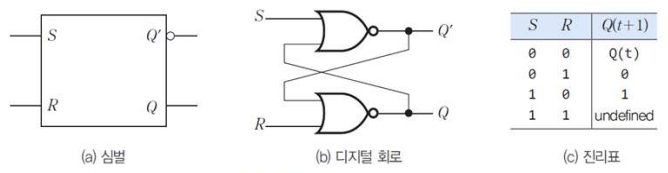
- Flip-Flop 회로
- 현 상태를 기억하는 디지털 논리 회로
- SR 플립-플롭(SR Latch): 1비트의 데이터를 저장
- S: set, R: reset, 순차 논리회로
- 출력 값은 현재 입력되는 값뿐만 아니라 SR 래치의 이전 상태(즉, 이전에 저장된 값)에 따라 다르게 작동
- NAND 게이트의 실현
- 두 개의 스위치를 직렬로 연결
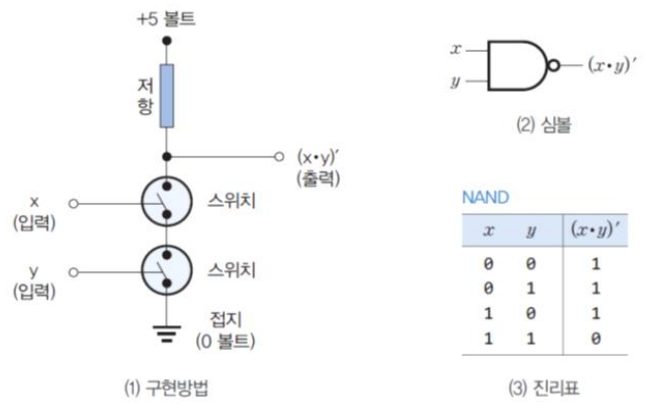
- 두 개의 스위치를 직렬로 연결
- 논리 회로의 활용
- (One bit) Full Adder
- 덧셈기는 컴퓨터의 논리회로 중 가장 기본인 연산회로
- 덧셈기(Adder), 곱셈기(Multiplier), 나눗셈기(Devider)도 논리회로로 구성
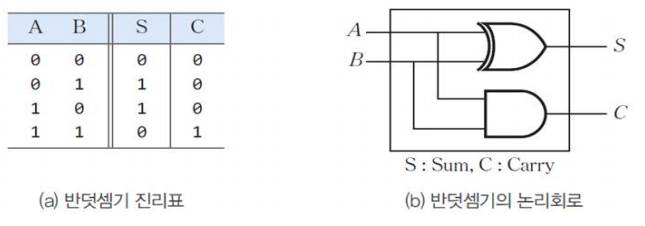
- 반덧셈기(Half Adder)
- 아랫 자리에서 올라오는 캐리 비트가 없다고 가정하여 2비트 덧셈
- s: sum, c: carry 비트
- 풀덧셈기(Full Adder)
- 아랫 자리에서 올라오는 캐리 비트(Carry-in) 고려, 2비트와 자리올림 1비트를 더할 수 있는 덧셈기
- 2개의 반가산기와 1개의 OR 회로로 구성
- 조합 논리 회로
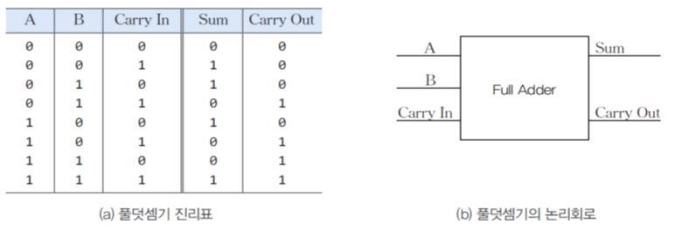
- (One bit) Full Adder
- 정보의 압축과 오류
- 정보를 압축할 필요성과 데이터 오류를 찾아내는 방법 중에 하나가 패리티 방법
- 정보의 크기
- 정보의 단위: KB, MB, GB, TB, PB, EB, ZB
- 메모리 용량이 급증하고 특히 인터넷을 통해 소셜 미디어가 활성화되면서 최근 정보량이 기하 급수적으로 급격히 증가
- 전 세계의 정보량이 매년 21%씩 증가
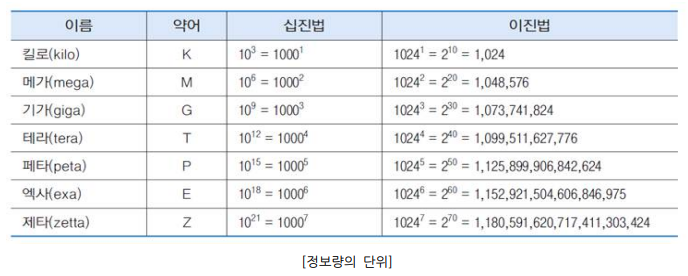
- 정보량의 증가
- 소셜미디어, SNS, 스마트폰, 사물인터넷(IoT)에 기인
- 특히, 동영상은 수 Giga
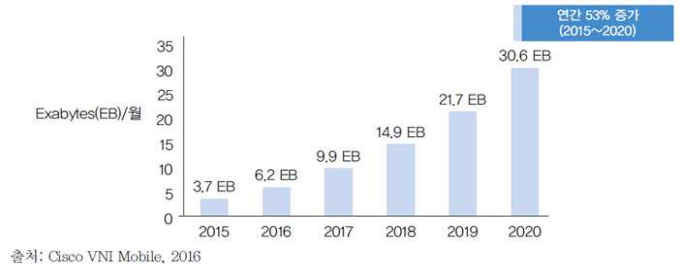
- 멀티 미디어 정보의 압축 필요성
- 데이터 압축 >> 데이터 전송 시간의 단축
- 다양한 압축 기법: 압축률이 높으면 복원 시 데이터 품질이 떨어짐
- 멀티미디어 데이터의 표준화

- 손실(Lossy) 압축과 비손실(Lossless) 압축
- 손실 압축: 온전한 복원 가능, x-레이 / 런-길이 부호화
- 손실 압축 예: aaaabbbccccc >> a4b3c5
- 비손실 압축 예: JPEG 이미지, MP3 파일
- 멀티 미디어 데이터의 압축
- 이미지, 그래픽: BMP, GIF, PNG, ...
- 사운드: WAV, MP3, ACC, ...(스트리밍: RealAudio)
- 동영상: MPEG-21, H.264, ...
- 목적과 환경에 따라 다름
- 정보의 오류 탐지(Error Detection)
- 컴퓨터 내부에서 구성 요소 간의 전송 오류
- 원거리의 컴퓨터로 전송되는 디지털 데이터의 통신 오류
- 패리티 비트(Parity bit): 홀수 패리티, 짝수 패리티
- 홀수 패리티 예시
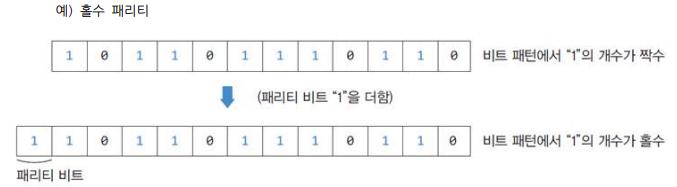
- 오류 복원(Error Correction)
- 데이터 전송 오류를 발견하여 원래의 올바른 데이터로 복원
- 해밍(Richard Hamming)이 제시
- '1011101'과 '1001001' 사이의 해밍 거리는 2
- '2143896'과 '2233796' 사이의 해밍 거리는 3
- 해밍 거리(Hamming distance) 기법 적용: 데이터 전송 시 발생한 오류를 원래의 데이터로 복원
출처: kg 아이티뱅크
There's Only One Thing To Do: Learn All We Can