
🌟 새로운 값 계산하기
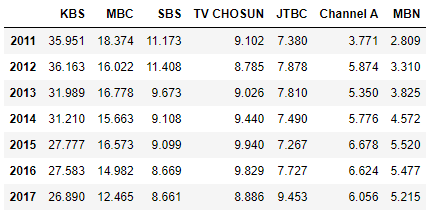
- 새로운 컬럼을 통해 인사이트 얻기
- 각 방송사들의 연간 총 시청률
- 각 행의 합을 구한다
df.sum(axis='columns')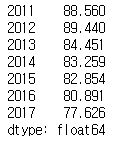
df['Total'] = df.sum(axis='columns')
df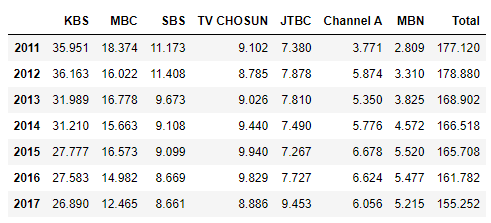
- 그래프로 결과 확인하기
- 해마다 시청률이 점점 떨어지고 있다
df.plot(y='Total').png)
- 지상파 vs. 종편
- 해마다 종편의 시청률이 오르고 있다
- 종편에서 제작하는 드라마나 예능이 인기가 있다
- 해마다 종편의 시청률이 오르고 있다
df['Group1'] = df.loc[:, 'KBS':'SBS'].sum(axis='columns')
df['Group2'] = df.loc[:, 'TV CHOSUN':'MBN'].sum(axis='columns')
df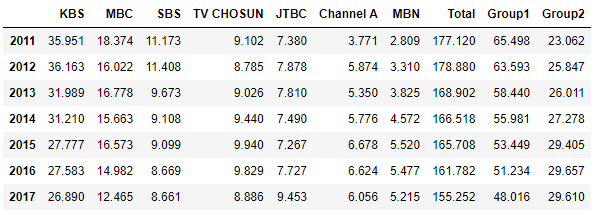
df.plot(y=['Group1', 'Group2'])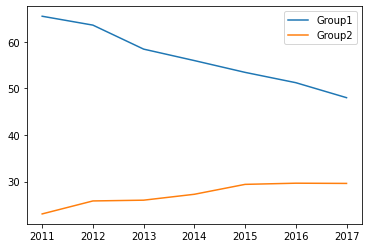
🌟 문자열 필터링
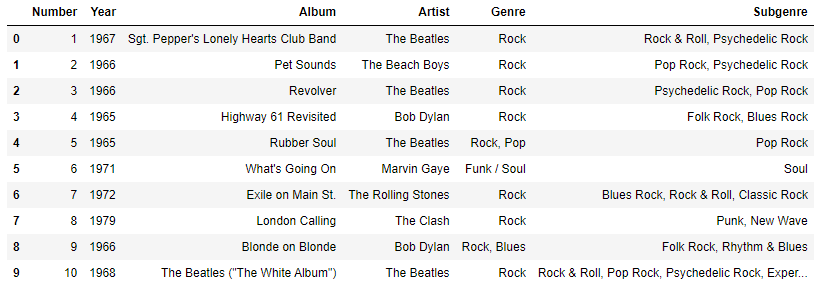
- 장르 컬럼만 추출하기
df['Genre'].unique()
- 특정 값을 포함한 결과만 필터링
[df['Genre']=='Blues']
df[df['Genre']=='Blues'] # Boolean_Series >> df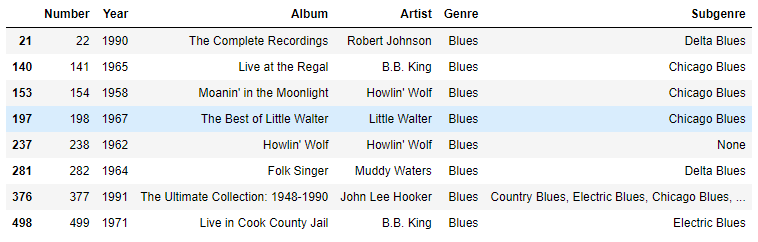
- 특정 문자열을 포함한 결과 필터링
.str.contains('Blues')- 앞글자가 특정 문자열인 경우만 필터링
.str.startswith('Blues')
df[df['Genre'].str.contains('Blues')]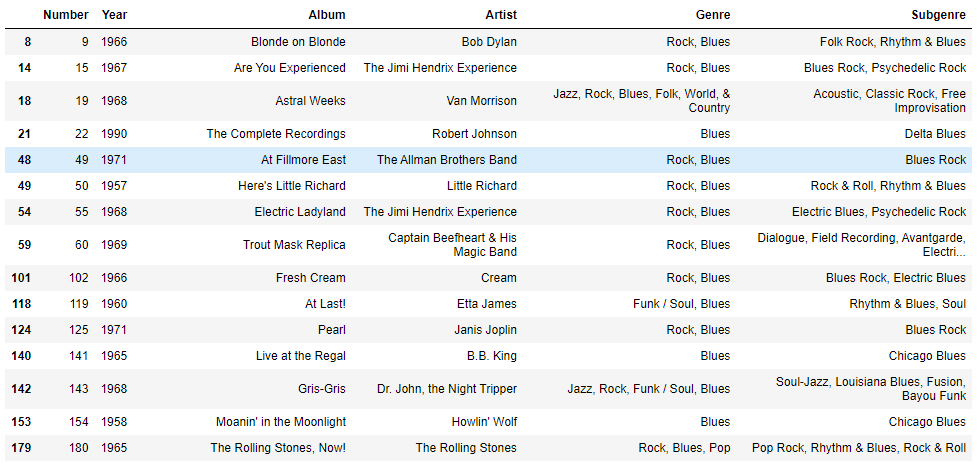
df[df['Genre'].str.startswith('Blues')]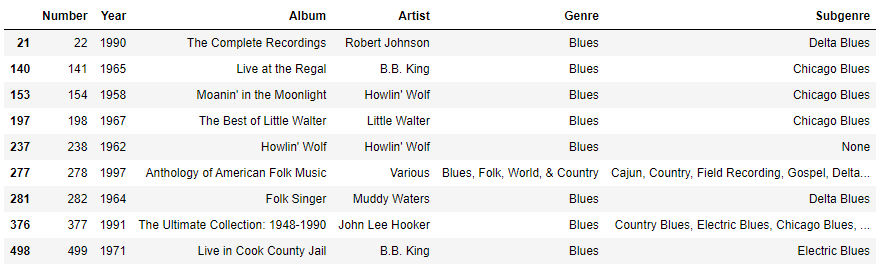
- 새 컬럼으로 추가하기
- 특정 문자열을 포함하고 있는지를 불린값으로 표현
df['Contains Blues'] = df['Genre'].str.contains('Blues')
df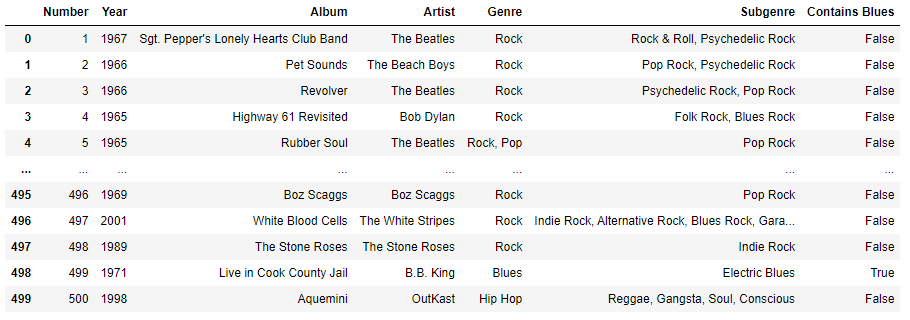
🌟 문자열 분리
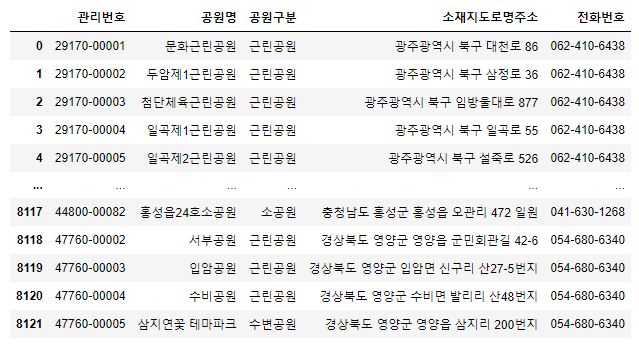
- 문자열 분리
str.split- 공백을 기반으로 단어들을 분리한 후, 리스트 생성
df['소재지도로명주소'].str.split()
# 첫번째 공백만 분리
df['소재지도로명주소'].str.split(n=1)
# DataFrame 생성
df['소재지도로명주소'].str.split(n=1, expand=True)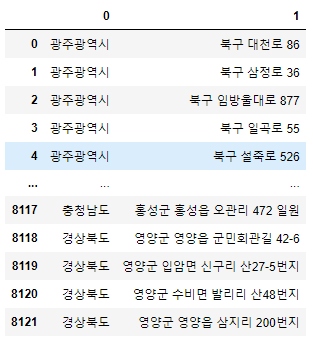
- 기존 DataFrame에 새로운 열로 추가하기
adress = df['소재지도로명주소'].str.split(n=1, expand=True)
# adress의 0번 인덱스 값을 관할구역 column의 값으로 지정
df['관할구역'] = adress[0]
df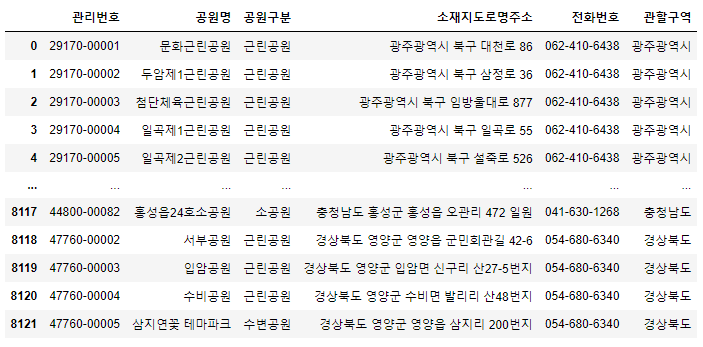
🌟 카테고리로 분류
- map
- 특정 값을 지정 값으로 변경하기
- 파라미터: 지정 값(변경할 값)
# 사전형을 통해 df의 값에 대응하는 새로운 값 지정
brand_nation = {
'Dell': 'U.S.',
'Apple': 'U.S.',
'Acer': 'Taiwan',
'HP': 'U.S.',
'Lenovo': 'China',
'Alienware': 'U.S.',
'Microsoft': 'U.S.',
'Asus': 'Taiwan'
}
df['brand'].map(brand_nation)
df['brand_nation'] = df['brand'].map(brand_nation)
df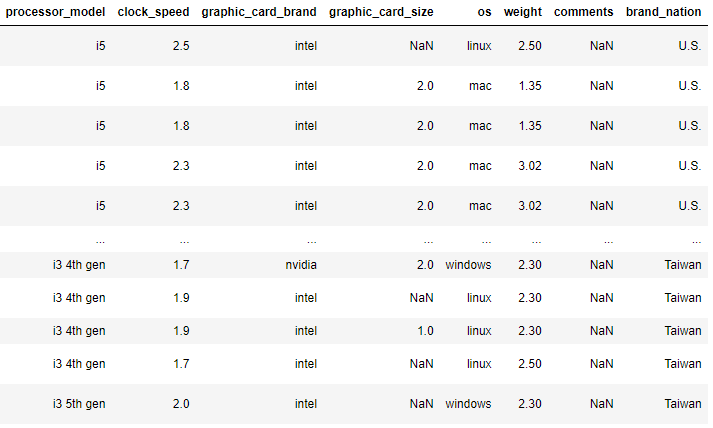
🌟 Groupby
- 카테고리별 분석하기
groupby메소드- 파라미터: 그룹으로 묶을 column
- 결과 자료형: DataFrameGroupBy
nation_groups = df.groupby('brand_nation')
type(nation_groups)pandas.core.groupby.generic.DataFrameGroupBy- 각 국가별 column에 있는 값의 수 비교
nation_groups.count()
각 국가별 column의 최댓값 비교- pandas 1.0.0 버전에서 지원X
- 문자열의 경우, 사전상 가장 마지막 순서의 단어
nation_groups.max()- 각 국가별 column의 평균 비교
nation_groups.mean()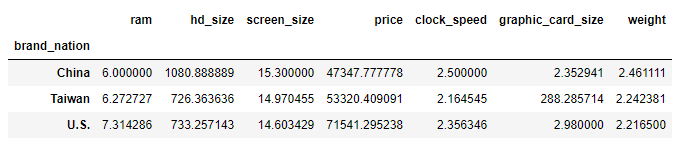
- 각 국가별 첫번째 행, 마지막 행의 값
nation_groups.first()
nation_groups.last()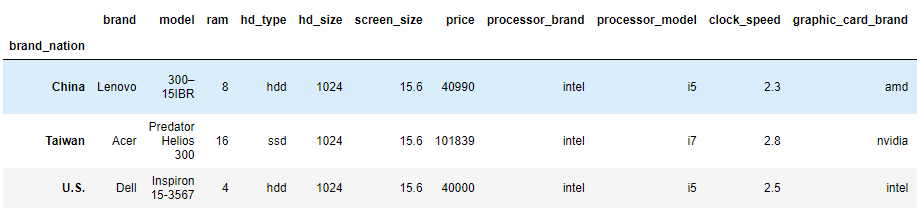
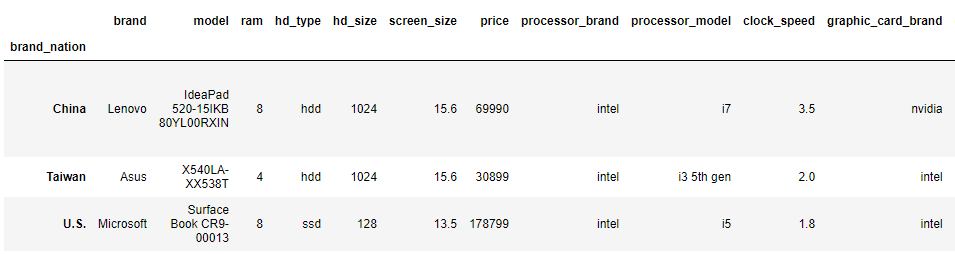
- Groupby 그래프
nation_groups.plot(kind='box', y='price')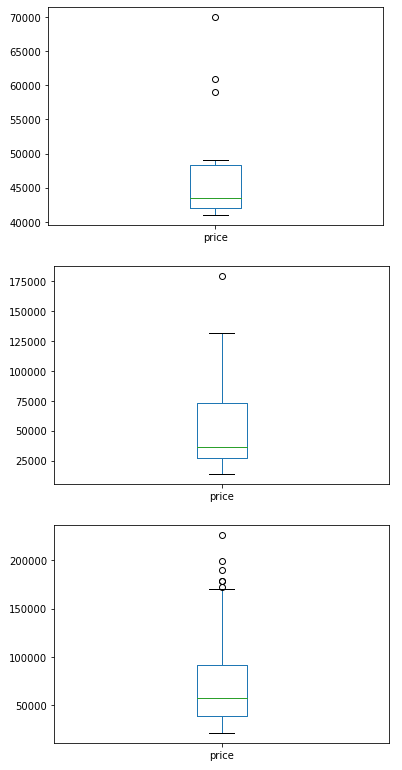
nation_groups.plot(kind='hist', y='price')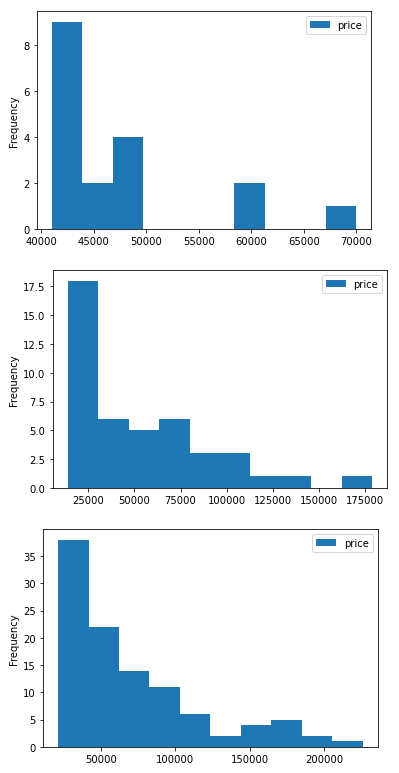
🌟 데이터 합치기
- Price
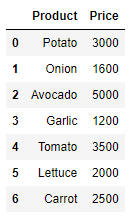
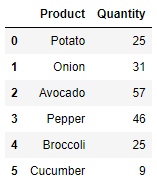
- Quantity
- 데이터 합치기
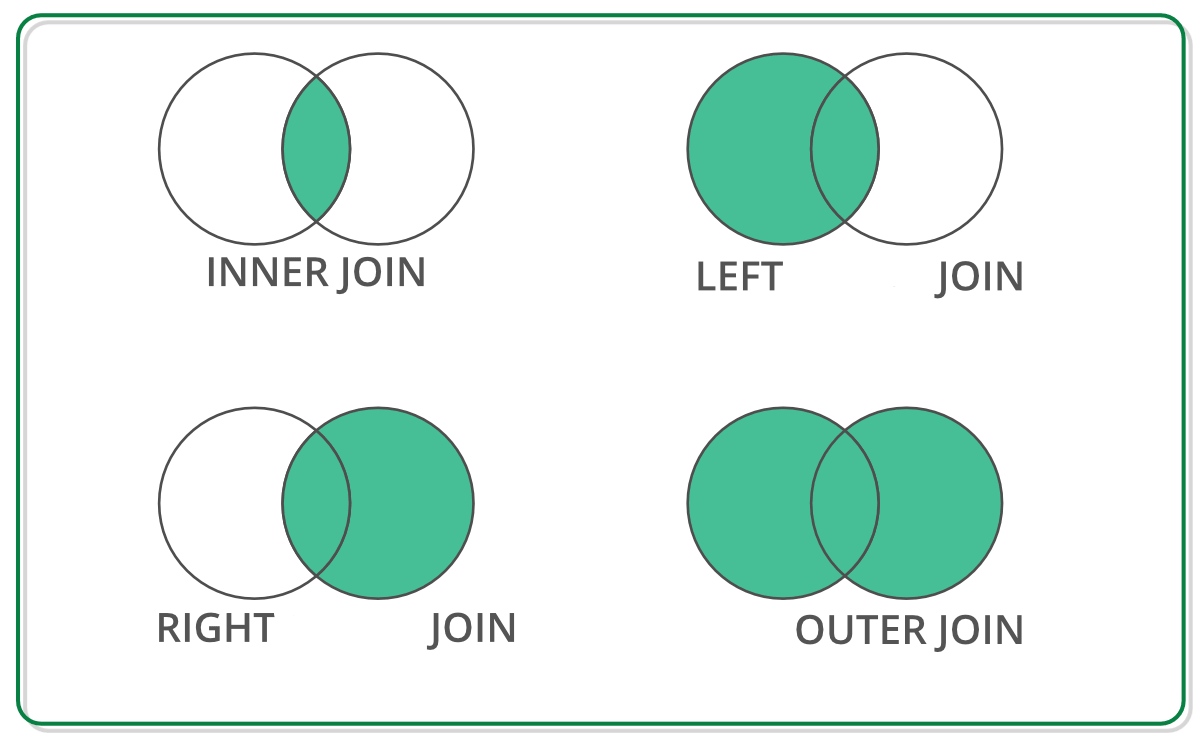
merge메소드- inner join
- left outer join
- right outer join
- full outer join
- inner join
- 두 DataFrame에서 겹치는 부분에 대해서만 합치는 join
- 기준:
Product- 야채 가격, 야채 수량 모두 가지고 있는 column
- Potato, Onion, Avocado
pd.merge(price_df, quantity_df, on='Product')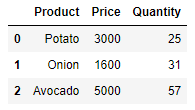
- left outer join
- 왼쪽 DataFrame에 존재하는 것들을 합치는 join
- 오른쪽 DataFrame에 없더라도 포함
- 왼쪽과 오른쪽에 중복으로 있는 Product
- 없는 값은 공백(NaN)
pd.merge(price_df, quantity_df, on='Product', how='left')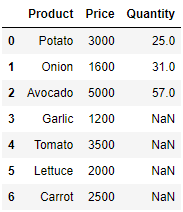
- right outer join
- 오른쪽 DataFrame에 존재하는 것들을 합치는 join
- 왼쪽 DataFrame에 없더라도 포함
pd.merge(price_df, quantity_df, on='Product', how='right')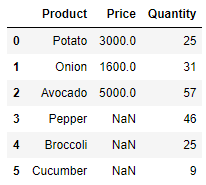
- full outer join
- 양쪽에 있는 모든 데이터를 합치는 join
- 없는 값은 공백
- 수량이 비거나 가격이 비거나
pd.merge(price_df, quantity_df, on='Product', how='outer')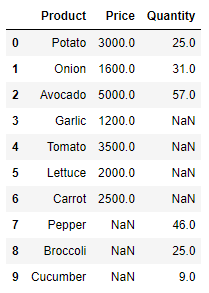
* 출처: 코드잇 - 데이터 사이언스 입문
There's Only One Thing To Do: Learn All We Can