
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 AI 핵심 기술 집중 클래스의 자연어처리(NLP) 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
1. NLP(Natrual Language Processing) 개요
자연어 처리(NLP, Natural Language Processing) 는 컴퓨터가 인간의 언어를 이해하고 생성할 수 있도록 하는 기술을 말하며, 크게 두가지 범주의 작업 :
자연어 이해(Natural Language Understanding, NLU),
자연어 생성(Natural Language Generation, NLG)을 수행하는데 사용된다.
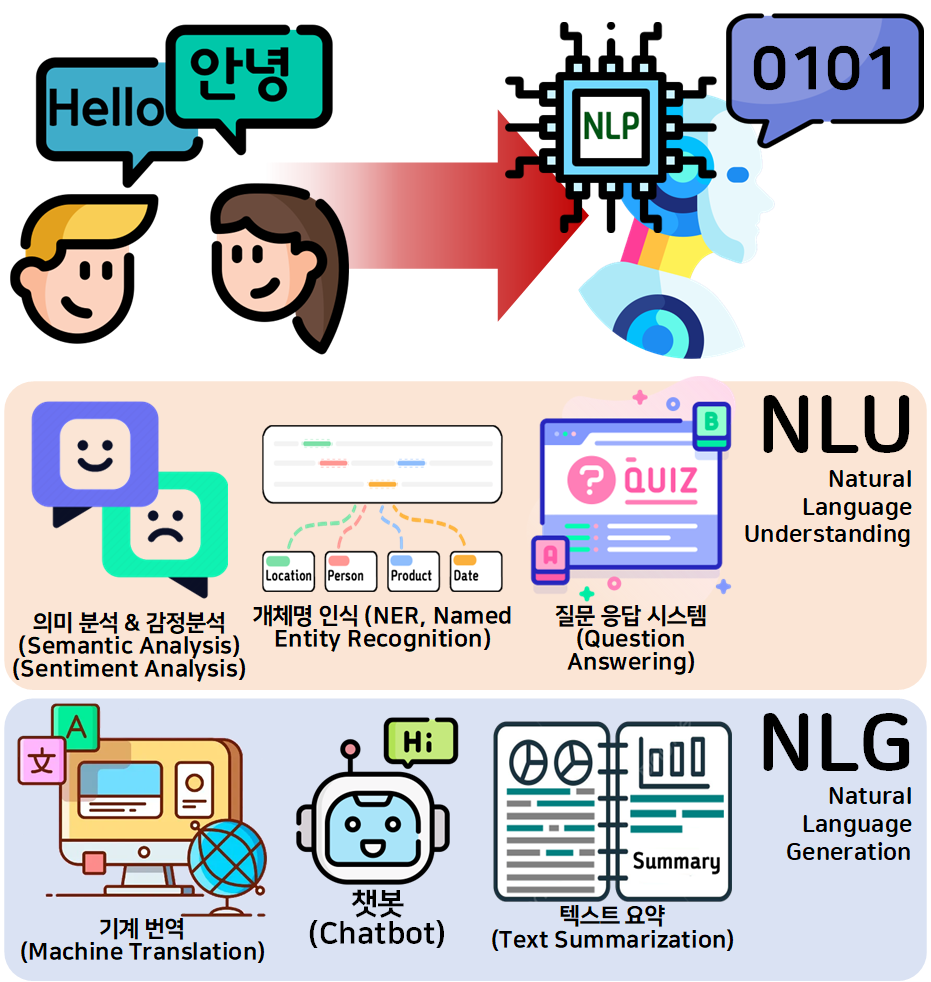
NLP기술의 작동과정을 이미지 처리(Image Precessing)과정과 비교한다면 아래와 같이 표현할 수 있다.
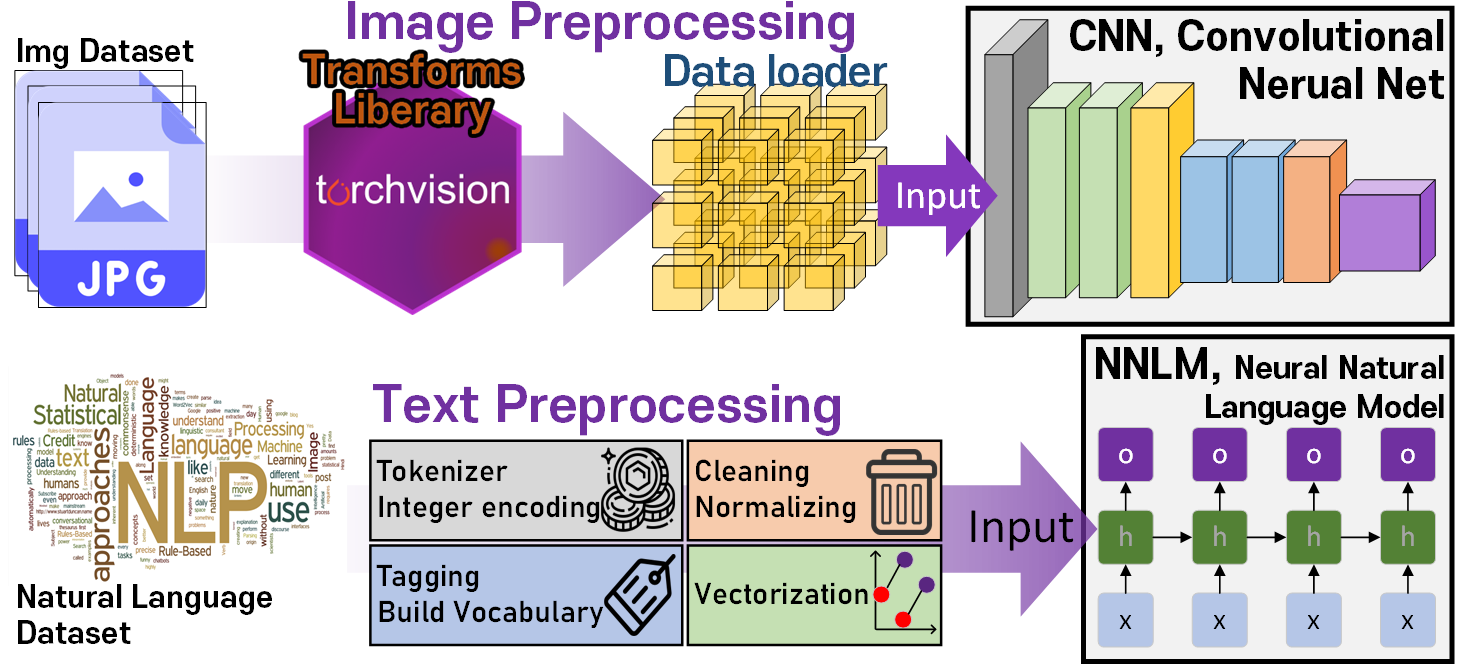
CV(Computer Vision)영역의 이미지 처리과정을 자연어 처리와 비교한다면 입력되는 데이터셋 : Image Dataset은 데이터의 포맷 및 구성이 일반화 및 표준화가 완료되어 있기에
Image Preprocessing(이미지 전처리)과정이 크게 어렵지 않으며, 통상적으로 Torchvision과 같이 정립된 Tensor 자료형 변환 라이브러리만 잘 사용한다면 대부분의 Image Preprocessing(이미지 전처리)를 수행하는데 문제가 없는 수준이다.
그러나 자연어 처리에서 입력되는 데이터셋 : Natural Language Dataset은 데이터의 포맷 및 구성이 전혀 일반적이지 않아
Text Preprocessing(텍스트 전처리)과정에 대해서
전처리 순서 및 기법에 대한 절차가 정리됫을 뿐, 이를 구현한 라이브러리나, 코드 개발 방식이 천차만별이다.

이는 자연어 데이터셋이 언어의 형태와 구성에 따라 판이하게 다르기에 Text Preprocessing(텍스트 전처리)과정은 통일된 방식이 발생하지 못하는 근본적인 문제가 존재한다.
라이브러리 및 코드 구현의 방식은 NLD(Natural Language Dataset)마다 다르지만, Text Preprocessing(텍스트 전처리)의 순서 및 사용 기법에 대해서는 어느정도 정리가 되었는데 이는 아래와 같다.
- Tokenization (Word & Sentence)
- Cleaning, Remove Stopword, Normalization
- Build vocalbulary
- Integer Encoding (word to index)
- Sentence Padding (max context length)
- Vectorization (Embedding)
2. 토크나이저(Tokenizer)
토크나이저는 입력된 NLD를 더 작은 단위(Token)으로 분리하여, 모델이 NLD에 포함된 텍스트를 이해하고 처리할 수 있도록 데이터를 분절하는 도구를 의미한다.

이때 토크나이저의 동작 원리를 알 필요성이 있는데
그림으로 도식화하면 아래와 같다.
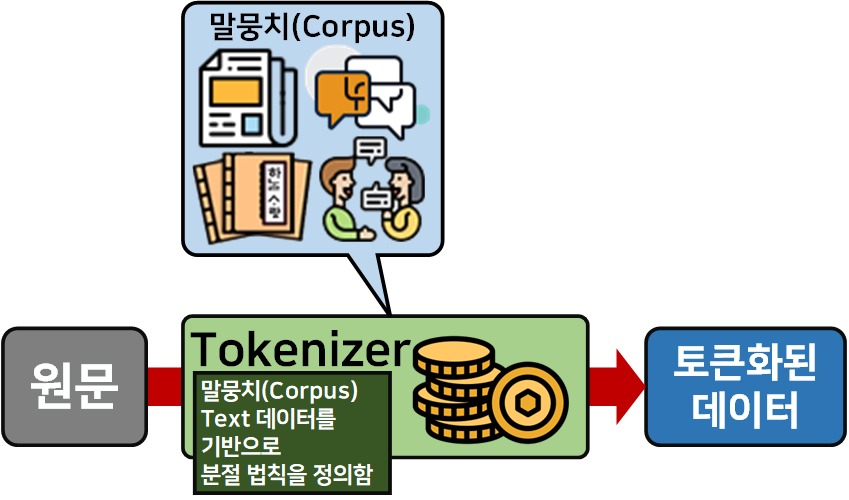
어떤 원문을 Tokenizer에 입력하여 이를 Tokenized_data로 변환하고자 할 때, Tokenizer는 분절하는 알고리즘은 내부에 내장되어 있으나, 어떤 단어나 문장을 기준으로 분절해야 하는지? 이것을 알아내려면
사전 데이터셋 인 말뭉치(Corpus)가 토크나이저에 입력되어야 한다.
이 말뭉치(Corpus)의 내부 데이터를 까보면
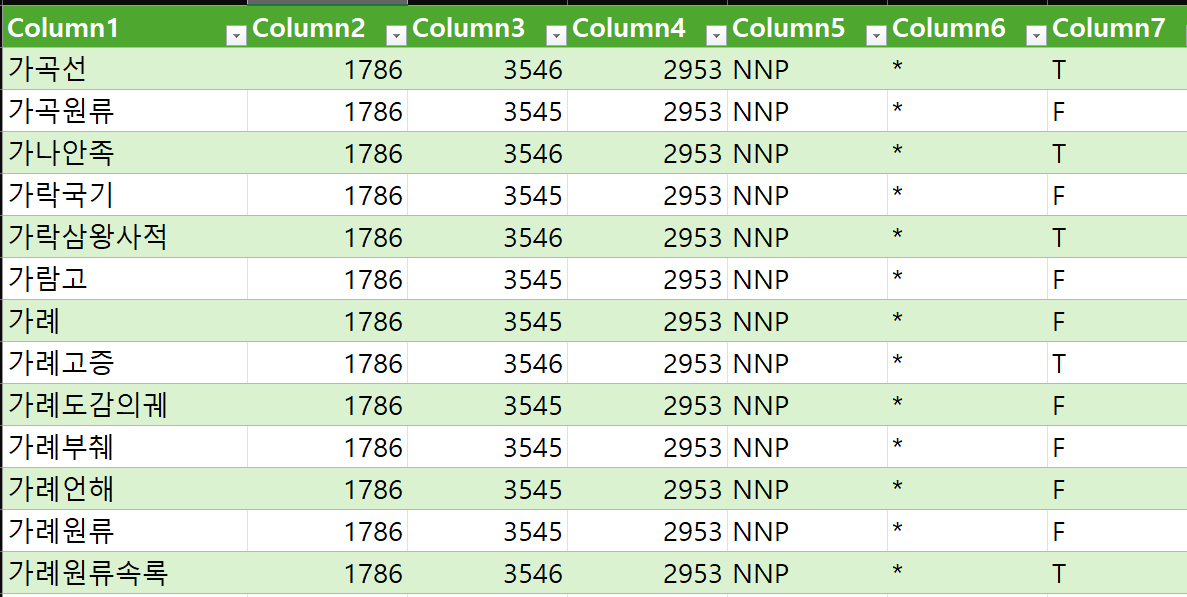 위 사진처럼 누군가가 열심히 노가다로 후처리한 단어장이라 보면 된다.
위 사진처럼 누군가가 열심히 노가다로 후처리한 단어장이라 보면 된다.
즉, 말뭉치는 후처리된 단어 목록이고, https://kli.korean.go.kr/corpus/main/requestMain.do
위 사진처럼 단어 목록이 특정 목적이나 분야 별로 묶여있는 모음이 말뭉치(Corpus) 인 것이다.
따라서 위 사진처럼 적합한 말뭉치(Corpus)를 토크나이저의 사전 데이터셋으로 준비해줘야 모델의 토크나이징 성능이 극대화 될 수 있다.
여기까지는 일반론 적인 이야기에 속하나, 지금부터 필자가 설명하는 규칙 기반 토크나이저(Rule-based tokenizer)는 Default로 사용되는 말뭉치(Corpus)가 주로 몇가지 종류로 고정되어 있다.
3. Rule-based Tokenizer
자연어 처리에서 사용되는 토크나이저 중 초기에 제작된 규칙 기반 토크나이저(Rule-based Tokenizer)는 가벼운 리소스를 요구하고, 빠른 처리속도와 간편하게 사용할 수 있기에 자연어 처리 입문 시 거의 필수적으로 실습을 해보고 지나가는 토크나이저라 볼 수 있다.
이 항목들에 대한 소개 및 사용방법에 대해 포스팅을 진행하겠다.
3.1. NLTK (영문 토크나이저)
https://www.nltk.org/
NLTK는 영어 데이터의 단어 분류(Classification), 토큰화(Tokenization), 태깅(tagging), 구문 분석 및 의미처리 작업을 지원하는 NLP 라이브러리로 주로 English언어 처리에 특화된 도구이다.
설치 및 사용 방법은 아래와 같으며,
! pip install nltkimport nltk
nltk.daowload('[사용할 corpus(말뭉치)]', quite=True)nltk.daowload() 메서드는 전처리 대상 NLD의 도메인 영역에 적합한 말뭉치(Corpus) 다운로드를 수행하는 메서드로 NLTK라이브러리에서 자체적으로 50여종의 말뭉치(Corpus)를 지원하고 있다.
이 중 주요 Text Preprocessing(텍스트 전처리)별로 널리 사용되는 말뭉치(Corpus)항목은 아래와 같다.
1) 토큰화
텍스트를 개별 단어로 분할하는 작업을 말한다
해당 작업에 주로 사용되는 말뭉치는 아래와 같다.
| 토큰화 | 설명 | 코드 |
|---|---|---|
| Punkt Tokenizer Models | 구두점을 이용한 문장 토큰화에 사용되는 사전 학습 모델 | nltk.download('punkt') |
| Treebank Tokenizer | Penn Treebank 규칙을 사용하여 토큰화 | nltk.download('treebank') |
| Wordlist Corpora | 다양한 언어의 단어 목록 제공, 토큰화 작업에 유용 | nltk.download('words') |
| CMU Pronouncing Dictionary | 영어 단어 발음 정보를 포함한 말뭉치, 발음 기반 토큰화에 유용 | nltk.download('cmudict') |
| Moses Tokenizer | 기계 번역을 위한 다국어 텍스트 처리용 토큰화 도구 | nltk.download('perluniprops') |
2) 품사 태깅
텍스트에서 단어의 품사를 식별하는 작업을 의미한다.
| 품사 태깅 | 설명 | 코드 |
|---|---|---|
| Brown Corpus (tagged) | 품사 태그가 포함된 Brown 말뭉치, 품사 태깅 모델 학습에 유용 | nltk.download('brown') |
| Treebank Corpus | Penn Treebank의 품사 태그가 포함된 말뭉치, 정밀한 품사 태깅 작업에 적합 | nltk.download('treebank') |
| CONLL 2000 | 품사 태그와 청크 정보가 포함된 말뭉치, 품사 태깅과 청크링에 유용 | nltk.download('conll2000') |
| Universal POS Tags | 다양한 언어에서 사용되는 공통 품사 태그 세트, 다국어 품사 태깅에 유용 | nltk.download('universal_tagset') |
| Brill Tagger | Eric Brill의 규칙 기반 품사 태깅 모델 | nltk.download('brill') |
3) 문장 분석
텍스트의 구문 구조를 파악하는 작업을 의미함
주로 사용되는 말뭉치는 아래와 같다.
| 문장 분석 | 설명 | 코드 |
|---|---|---|
| Penn Treebank | 구문 트리가 포함된 영어 문장 말뭉치, 구문 분석 모델 학습에 유용 | nltk.download('treebank') |
| Dependency Treebank | 의존 구문 구조를 포함한 말뭉치, 의존 구문 분석에 적합 | nltk.download('dependency_treebank') |
| PropBank Corpus | 의미역 라벨이 추가된 Penn Treebank 문장, 의미 기반 구문 분석에 유용 | nltk.download('propbank') |
| FrameNet | 의미 프레임 구조를 포함한 말뭉치, 구문 구조와 의미 간의 상관 관계 분석에 유용 | nltk.download('framenet_v15') |
| TIMIT Corpus | 음성 데이터와 문장 구문 트리를 포함한 말뭉치, 음성 기반 구문 분석에 사용 | nltk.download('timit') |
4) 데이터 분석
텍스트 데이터 수집 및 분석 작업을 의미함
| 데이터 분석 | 설명 | 코드 |
|---|---|---|
| Brown Corpus | 영어 텍스트로 구성된 다양한 장르의 말뭉치, 통계적 언어 모델링에 유용 | nltk.download('brown') |
| Reuters Corpus | 뉴스 기사를 기반으로 한 대규모 말뭉치, 텍스트 분류 작업에 유용 | nltk.download('reuters') |
| Gutenberg Corpus | 공공 도메인 책들을 포함한 대규모 텍스트 말뭉치, 자연어 처리 작업에 유용 | nltk.download('gutenberg') |
| Inaugural Address Corpus | 미국 대통령 취임 연설 말뭉치, 시계열 분석 및 정치적 담론 분석에 유용 | nltk.download('inaugural') |
| Web Text Corpus | 웹에서 수집된 텍스트 말뭉치, 비공식적 영어 텍스트 분석에 유용 | nltk.download('webtext') |
이 외에도 각 도메인별로 적합한 말뭉치(Corpus)에 대한 정보를 확인하려면 https://www.nltk.org/nltk_data/ 를 참조하길 바란다.
3.2. NLTK 실습
Rule-Based Tokenizer의 말뭉치(Corpus)에 대해 설명을 하긴 했지만 코드실습을 하면서 느낀점은 대체적으로 몇개의 말뭉치(Corpus)를 거의 Default로 사용하고, Custom Corpus를 도입하여 토크나이저의 성능실험을 딥하게 하는 예는 별로 없긴 하다.
이유는 필자가 생각하기로는
1) Rule-Based Tokenizer는 Custom Corpus를 생성할 때 별도의 사전 데이터 생성 작업을 수행해야 한다.
이 말이 조금 어렵게 들릴지 모르겠지만, 각 토크나이저 라이브러리 별로 Import가 가능한 말뭉치(Corpus) 데이터 규격 및 서식이 존재한다. 그리고 말뭉치를 제작하는 기관과 토크나이저를 배포하는 단체가 파편화 되어있고 서로 교류 및 표준화도 이뤄지지 않았기에 약간 중구난방식으로 생태계가 유지되고 있는것 같다.
따라서 어떤 특정한 토크나이저를 사용한다면 해당 토크나이저 라이브러라에서 제공하는 말뭉치(Corpus)를 함께 패키지로 사용하는 경우가 흔하고, 그 말뭉치(Corpus)마저도 1종에서 2종만 주로 사용되는 형국이다.
Word Tokenizer 실습
import nltk
# 토크나이저 작업을 수행하기 위한 사전 데이터 다운로드
nltk.download('punkt', quiet=True)
nltk.download('treebank',quiet=True)
nltk.download('words', quiet=True)#예제 영문 데이터(NLD)
sentence = "The quick, brown fox can't wait to jump over the lazy dog's back."from nltk.tokenize import WordPunctTokenizer # punkt 코퍼스 기반
from nltk.tokenize import TreebankWordTokenizer # treebank 코퍼스 기반
from nltk.tokenize import word_tokenize # words코퍼스 기반
tokenized_punk = WordPunctTokenizer().tokenize(sentence)
tokenized_treebank = WordPunctTokenizer().tokenize(sentence)
tokenized_words = word_tokenize(sentence)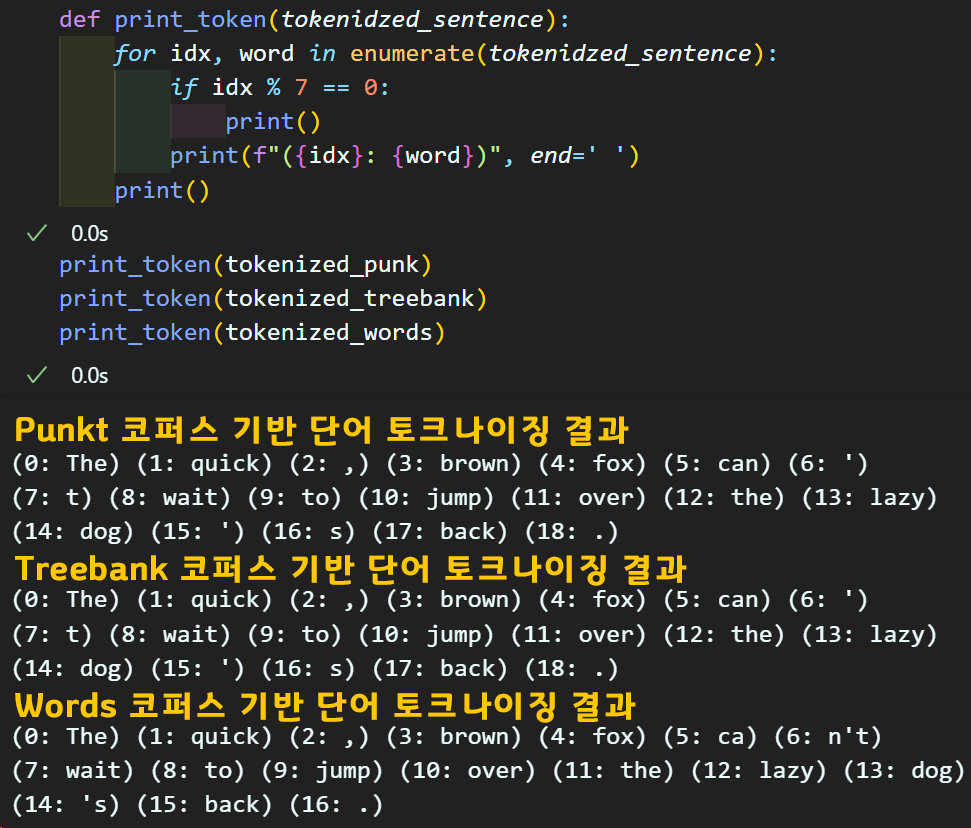
Sentence Tokenizer 실습
# 문장 토크나이저 실습용 데이터
ex_NLD = "The mayor announced new plans for the city park today. Local residents are excited about the improvements. The project will include a playground and walking trails. Funding has been secured through state grants. Construction is set to begin early next year."
#문장 토크나이저 메서드 import
from nltk.tokenize import sent_tokenize
sent_tokenized = sent_tokenize(ex_NLD)
3.3. KoNLPy (한글 자연어 처리 라이브러리)
https://konlpy.org/ko/latest/index.html
다음으로는 한국어 자연어 처리를 위한 파이썬 패키지인 KoNLPy이다.
한국어의 경우 언어와 단어의 기원에 대한 TMI를 풀자면
우선 한국어는 우랄-알타이 어족에 포함되어 있던 것으로 연구가 되었지만 현재로써는 알타이어는 알타이제어라는 연관성을 찾기 힘든 큰 범주의 어족 내 고립 어족으로 한국어족, 일본어족 등을 분류하고 있다.
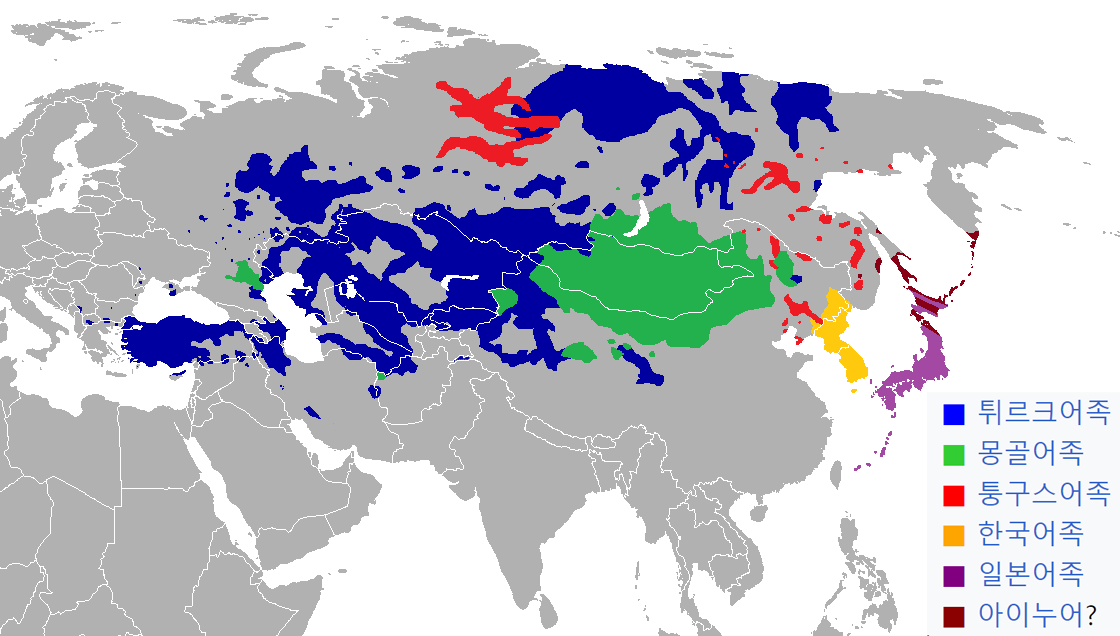
또한 한글 문자 기원도 인위적으로 발명한 인공어에 속하면서
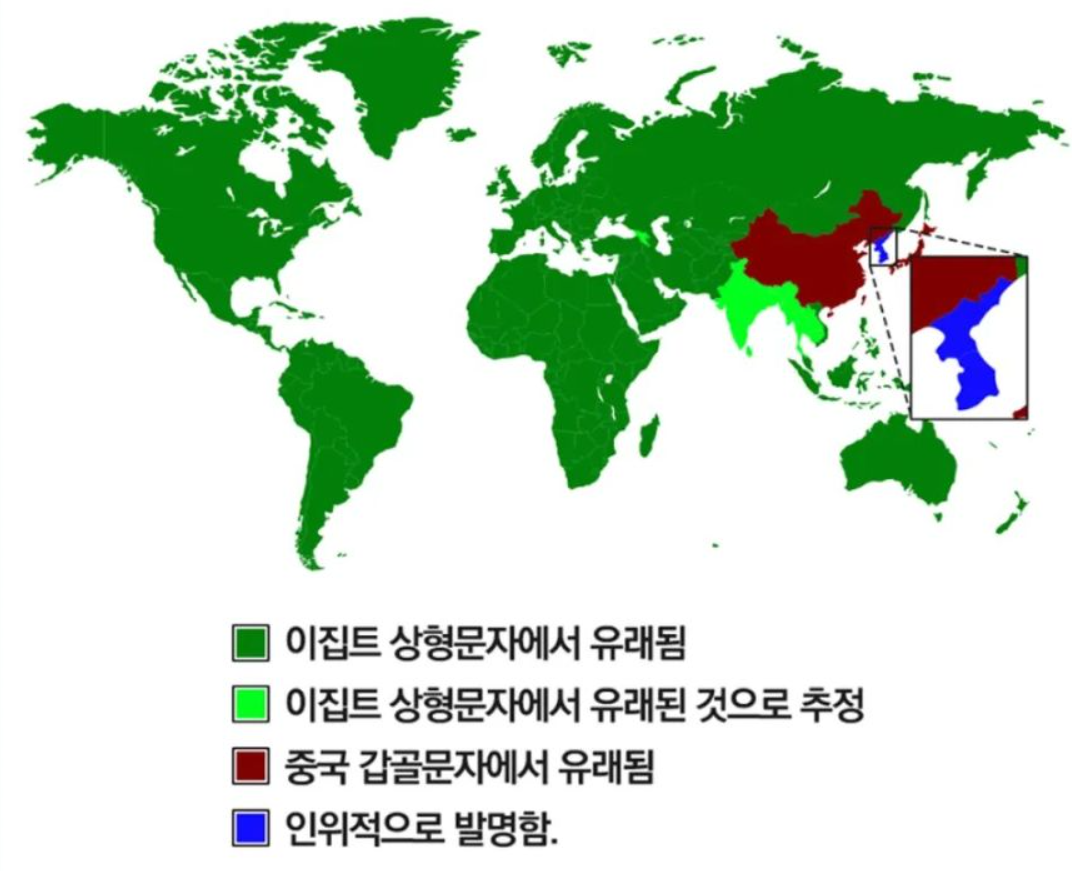
표의문자인 한자 문화권에 속하는 등.. 여러가지로 태생적으로 복잡한 언어에 속한다.
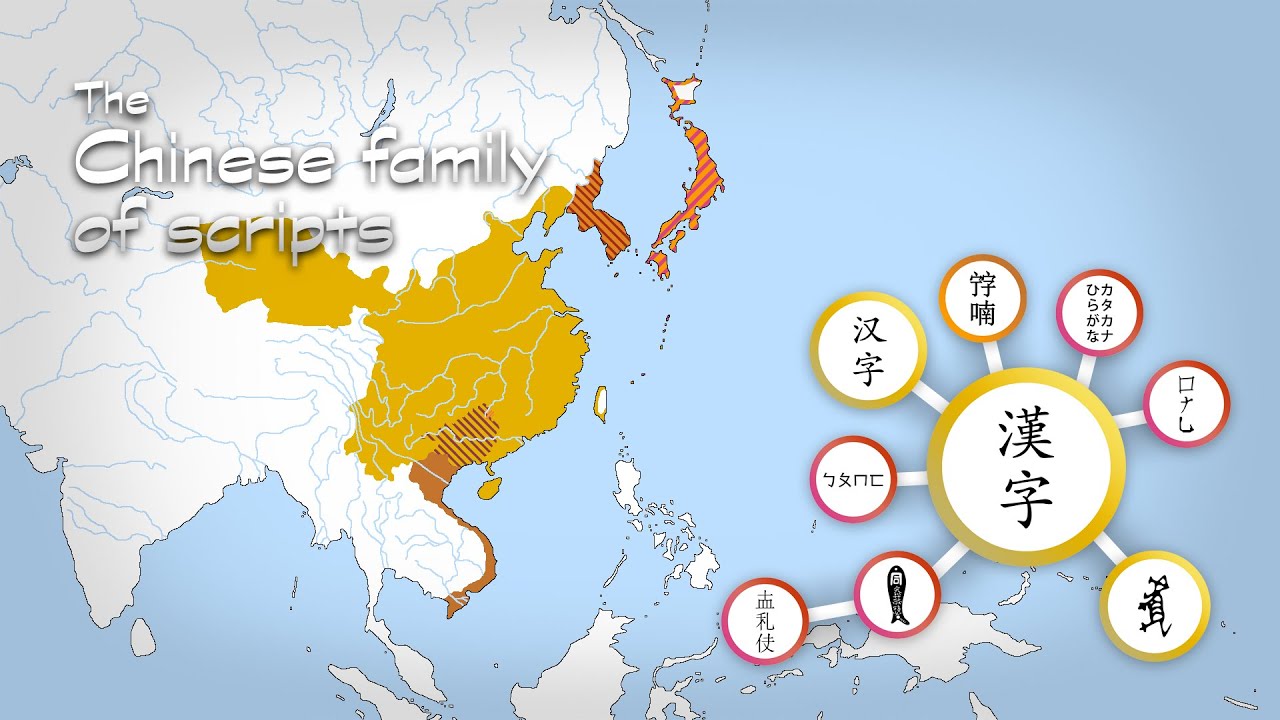
따라서 한국에서 태어나고 언어를 익혀서 사용에 어려움이 없는 것이지 외국인 기준으로도 가장 익히기 어려운 언어는 동아시아 3국의 언어가 꼽히고 있다.
물론 사람도 익히기 어려운 언어이니, 자연어 처리과정도 그리 녹록한 편은 아니다.
아무튼 이런 배경이 있는 탓인지 KoNLPy라이브러리는 그 설치과정도 그렇게 순탄한 편은 아니다.
KoNLPy라이브러리 설치 - JDK 설치
https://www.oracle.com/kr/java/technologies/downloads/
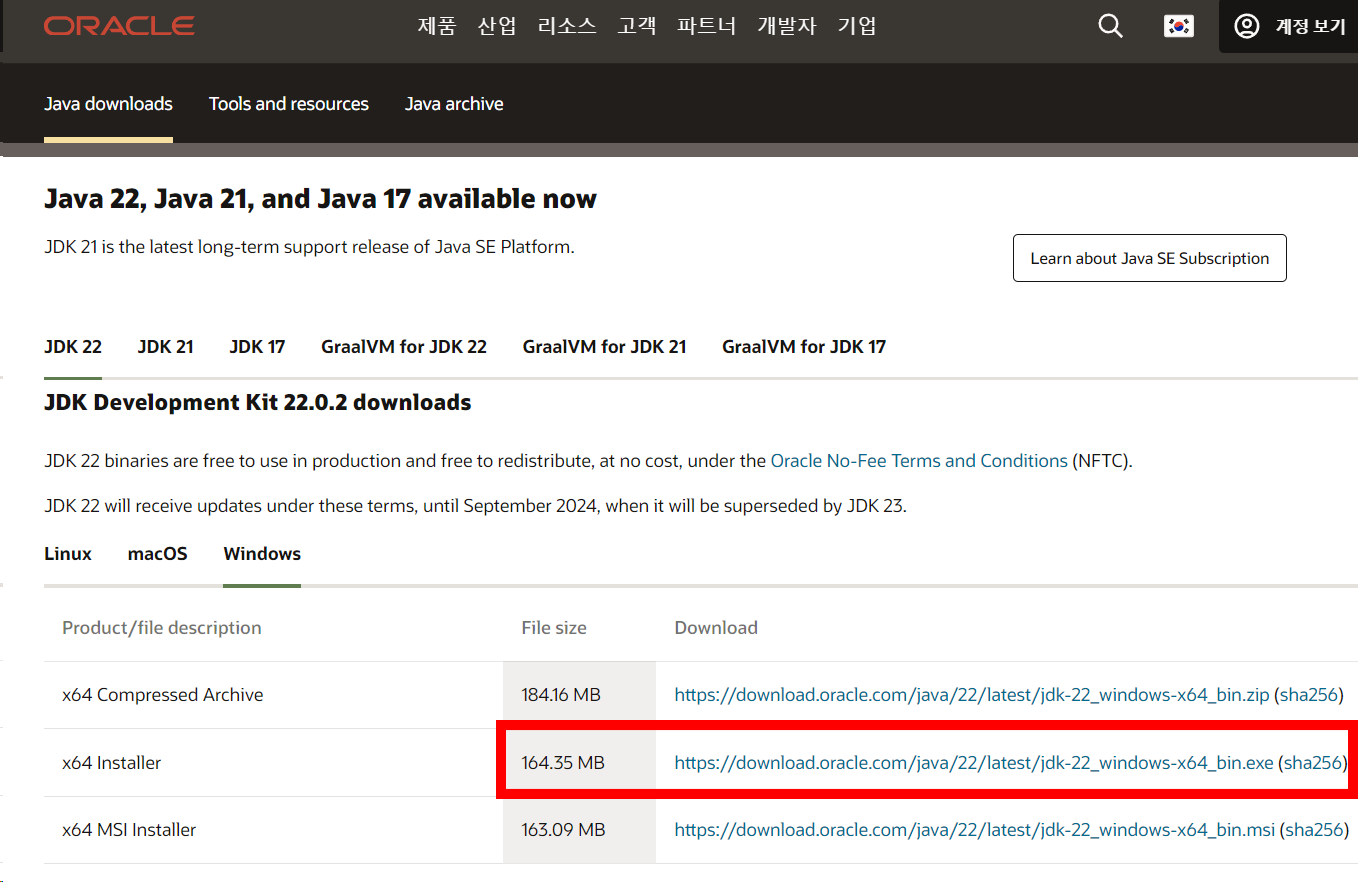
OS 플랫폼 별로 JDK 버전을 다운받아서 설치하면 되는데
필자는 win11-64bit이니 위 붉은색 박스로 표시한 항목을 다운로드 받는다.
그 다음 시스템 변수에 신규항목
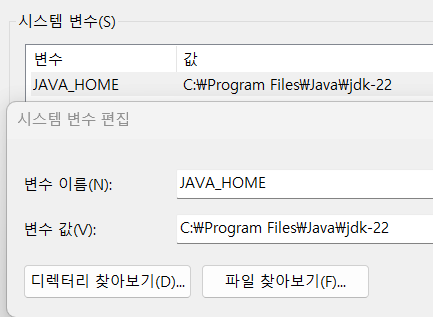
변수 이름 : JAVA_HOME
변수 값 : C:\Program Files\Java\jdk-[설치버전]
을 생성하고
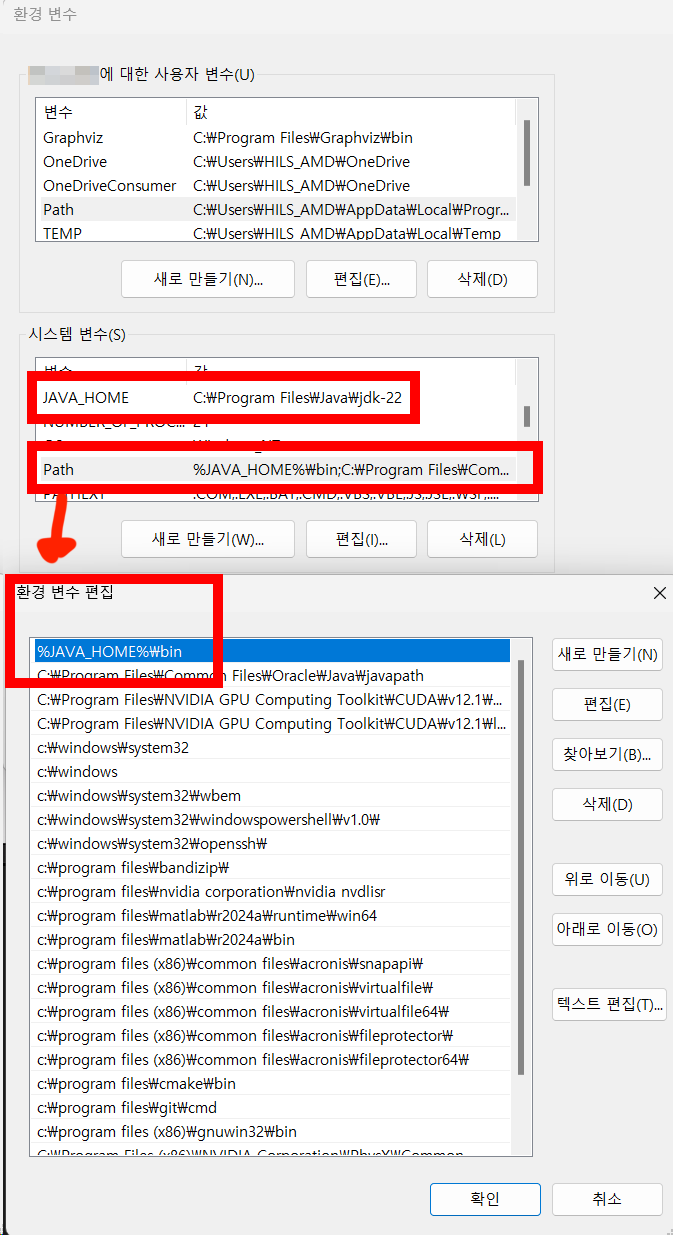
그 다음에 위 사진처럼 시스템 변수의 Path를 찾아서 -> 편집
환경 변수 편집에
%JAVA_HOME%bin을 추가하면 된다.
이거는 사용자 변수 탭에서 추가시켜도 되고
시스템 변수 탭에서 추가시켜도 된다.
(시스템 변수에도 Path가 있고 사용자 변수에도 Path가 있다 둘다 큰 차이는 없지만 만약 로컬 계정이 2개 이상 엉켜서 쓰이는 경우에는 시스템 변수에 넣어야 한다)
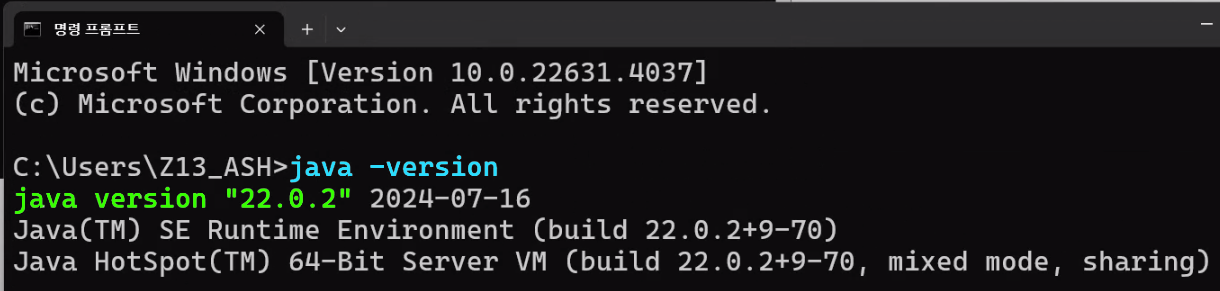
설치 + 시스템 변수 등록 후에는 위 사진처럼 JDK가 활성화 되었는지 확인하자
> java -version
해당 명령어를 실행하면 version "~~~"이 출력2)
KoNLPy라이브러리 설치 - JPyp1및 konlpy 설치

이거는 구 버전의 경우 설치 방법이 좀 어지럽게 되어있던데
지금은 pip에 완전히 다 설치과정이 편입되어서 문제없게 사용이 가능하다
!pip install JPype1
!pip install konlpy어렵게 설치하지말고 다 pip로 쓰자
24년도 들어와서 파이썬으로 뭐 설치할거는 아나콘다나 깃허브 들어가서 뭐 어쩌구 저쩌구 하는 경우가 있던것들
전부 pip로 대동단결 된지 오래됫다.
KoNLPy라이브러리는 서브 패키지로 총 5개의 tag Packgae를 제공하고 있는데 각각
Hannanum(한나눔),
Kkma(꼬꼬마),
Komoran(꼬모란),
OKT,
Mecab 이다.
이 중 Mecab은 리눅스 환경에서는 KoNLPy라이브러리르 통해서 정상 구동이 가능하나, 유독 윈도우 환경에서는 KoNLPy를 통해서 사용하는것이 거의 불가능하게 되어있다.

이 어려운 과정을 뚫고 어떻게든 KoNLPy라이브러리의 Mecab클래스를 활성화 하려고 노력해봤으나, 거의 다 허사였고,
별도로 분리된 전용 라이브러리를 설치해서 사용하는게 가장 속편하다.

!pip install python-mecab-ko3.4 KoNLPy 실습
Word Tokenizer 실습
from konlpy.tag import Hannanum, Kkma, Komoran, Okt
from mecab import MeCab
#각 tag 클래스 라이브러리의 인스턴스화
hannanum = Hannanum()
kkma = Kkma()
komoran = Komoran()
okt = Okt()
mecab = MeCab()# 예제 한글 NLD 데이터 생성
sentence = "건강식 다 필요없어요. 무작정 굶지 마시고, '이렇게'공복을 유지해 보세요."한글 word tokenizer은 정확히는 형태소 분석기 이기에 토크나이저 말고도 다른 기능을 제공한다. 이 기능을 전부 체크해 보도록 하겠다.

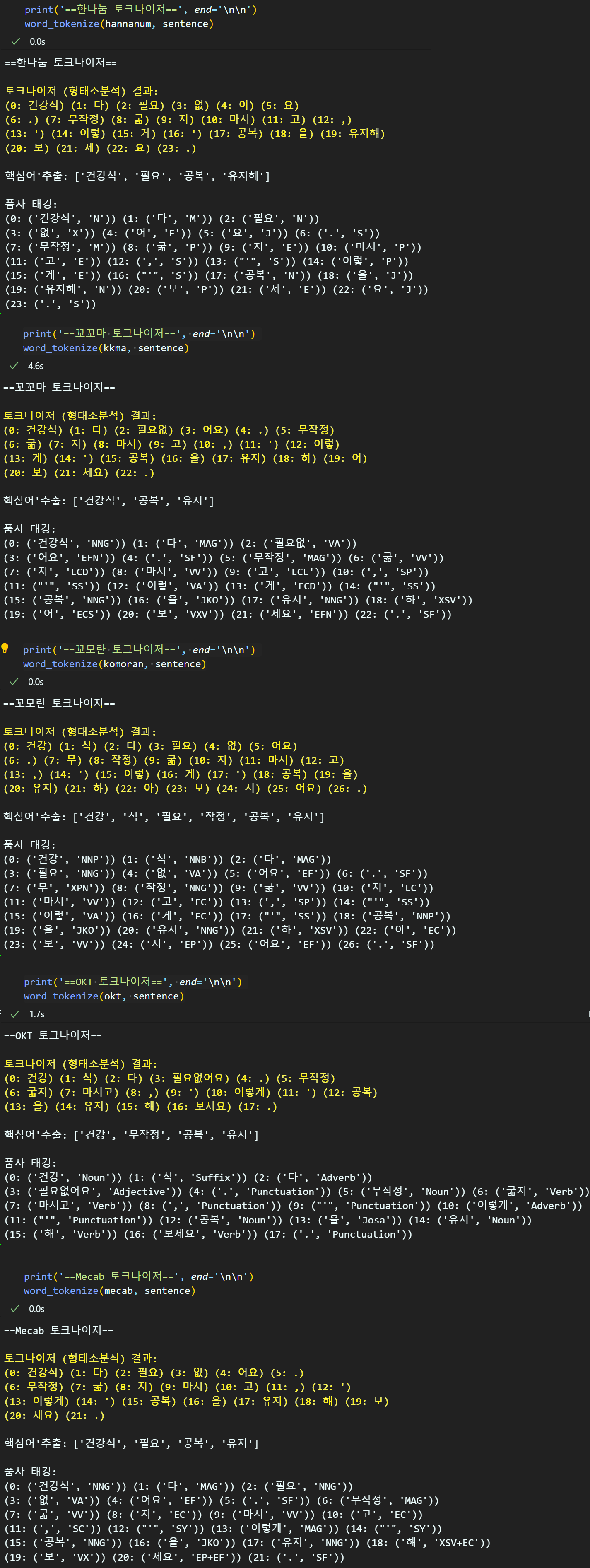
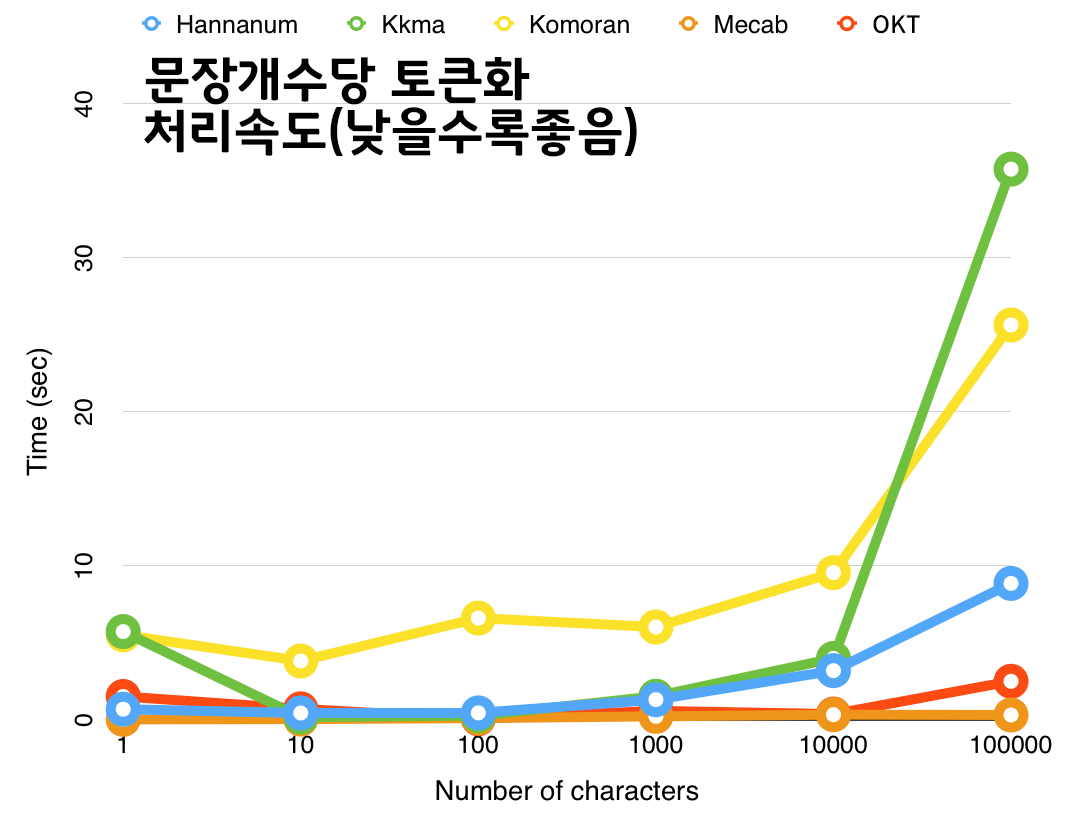
각각의 토크나이저 실행성능, 분절 정확도 등을 비교한 연구 결과가 여럿 존재하고 그 결과를 비교하면 대략 OKT와 Mecab 두가지를 주로 사용한다.
3.5. 한글 문장 토크나이저(kss, kiwi)
마지막으로 한글 문장 토크나이저(Sentense toenizer)은 KoNLPy 라이브러리에서는 그 기능을 지원하지 않고, 다른 토크나이저 라이브러리인 kss, kiwi를 통해 문장 토크나이징을 수행할 수 있다.
https://github.com/hyunwoongko/kss
https://bab2min.github.io/kiwipiepy/v0.18.0/kr/


참고로 kiwi는 Sentense toenizer 말고도 형태소 분석이나 띄어쓰기 교정 등 다양한 기능을 제공하지만
대체로 Sentense toenizer를 실습한다면 kss, kiwi를 주로 쓴다.. 이렇게 보면 된다.
import kss
from kiwipiepy import Kiwi
kiwi = Kiwi() #kiwi는 클래스 형태로 라이브러리가 구성됨# 임의의 한글 문장 데이터
ex_NLD = "서울시는 다음 주부터 새로운 교통 정책을 시행합니다. 이번 정책은 버스 노선을 대폭 개편하는 내용입니다. 시민들의 편의를 높이기 위한 조치라고 밝혔습니다. 노선 변경으로 인해 일부 불편이 예상됩니다. 정확한 노선은 시 홈페이지에서 확인 가능합니다."
# 문장 토크나이징 수행
tokenized_sent_kss = kss.split_sentences(ex_NLD)
tokenized_sent_kiwi = kiwi.split_into_sents(ex_NLD)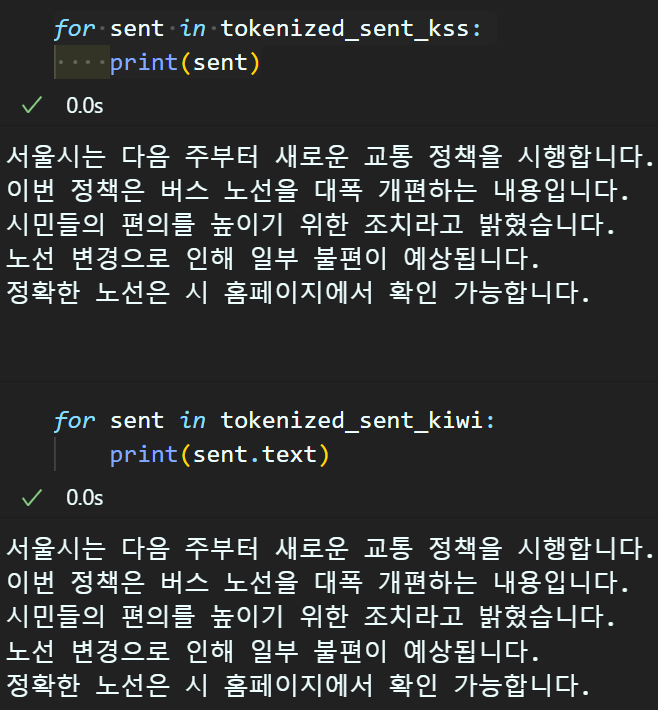
4. 실습 정리
여기까지 토크나이저 - Rule-based Tokenizer에 대한 실습을 수행했다.
실습에 사용한 라이브러리는 정확하게는 Rule-based Tokenizer와 기계학습 기반 혹은 통계적 기법 기반의 토크나이저를 혼용하여 실습을 진행했다.
이를 혼용해서 설명한 이유는
다음 포스트에서는 Pre-trained Tokenizer에 대해 설명을 진행하려는데
이 Pre-trained Tokenizer 다시말하면 딥러닝 기반의 토크나이저은 이번 포스트에서 설명한 규칙기반/기계학습 기반의 토크나이저와는 아래와 같은 주요한 차이점이 존재하기 때문이다.
| 특징 | Pre-trained Tokenizer | 기계학습/규칙기반 토크나이저 |
|---|---|---|
| 기반 기술 | 딥러닝 모델 기반 (BERT, GPT, T5 등) | 규칙 기반, HMM, CRF, 통계적 모델 |
| 토큰화 방식 | WordPiece, BPE, SentencePiece 등 | 사전 정의된 규칙, 기계 학습 알고리즘 |
| 데이터 학습 | 대규모 말뭉치로 사전 학습된 모델 사용 | 사전 학습된 모델이나 수동 규칙 사용 |
| 언어 처리 능력 | 다국어 지원, 문맥에 따른 동적 토큰화 가능 | 주로 단일 언어 지원, 정적 토큰화 |
| 문맥 이해 | 문맥을 반영하여 단어의 의미적 차이를 고려 | 문맥을 반영하지 않거나 제한적으로 반영 |
| 적응성 | 특정 도메인에 맞게 미세 조정 가능 | 규칙 기반은 유연성이 떨어짐 |
| 속도 | 비교적 느림 (딥러닝 모델이 크고 복잡함) | 비교적 빠름 (복잡도가 낮음) |
| 사용 용이성 | 사전 학습된 모델을 사용하면 쉬움 | 규칙 기반은 복잡하고 설정이 어려울 수 있음 |
| 주요 라이브러리 | Hugging Face Transformers, SentencePiece | Konlpy, Mecab, NLTK, SpaCy 등 |
| 토크나이저 예시 | BERT, GPT-2, T5, XLM-R | Mecab, Kkma, Hannanum, NLTK, SpaCy |
| 토큰화 결과의 일관성 | 동일한 문장이라도 문맥에 따라 다를 수 있음 | 동일한 입력에 대해 일관된 결과 제공 |
| 확장성 | 커스텀 말뭉치로 재학습 가능 | 새로운 규칙이나 모델 추가 가능 |
| 적합한 작업 | 문맥 이해가 중요한 NLP 작업 (예: 번역, 요약) | 기본적인 형태소 분석, 빠른 토큰화 필요시 |
| 장점 | 문맥 고려, 고도화된 언어 이해 | 빠르고 간단, 특정 언어/작업에 최적화 가능 |
| 단점 | 고사양 하드웨어 요구, 복잡한 설정 | 문맥 이해 부족, 확장성 제한 |
Pre-trained Tokenizer는 모델의 종류 및 학습 방법론 및 설계철학과 같은 BERT, GPT, WordPiece, BPE, SentencePiece 등을 알아야 할 필요가 있지만
이번 포스트의 규칙기반/기계학습 기반의 토크나이저와의 차이점에 대해 집중하려 한다.
이것저것 사용해본 결과 큰 차이점이라면
1) corpus의 적용 용이성 : 토크나이징을 수행하는데 분절 규칙을 해당 데이터셋에 적합하게 조정하도록 custom corpus를 다양하게 적용할 수 있으며, 극단적으로는 train_dataset = corpus으로 아에 합치시켜서 사용하는 것도 문제가 없으며, 오히려 이렇게 사용하는 경우도 꽤 많이 존재한다.
2) 다국어 지원 : Pre-trained Tokenizer는 특정 언어에 대해서만 토크나이징을 수행되게 기능이 제한된 경우가 존재하지만, 기반이 되는 딥러닝 모델이 대체로 대규모 언어모델(Large Language Model, LLM)에 속하는 종류도 있어, 여러 언어데이터로 학습된 모델이 배포되기도 한다.
따라서 규칙기반/기계학습 기반의 토크나이저대비 범용성이 좀 더 높은 장점이 있다.
그러나 딥러닝 모델을 활용해 토크나이징을 수행하기에 결과 일관성이 모호한 측면이 있고, 속도가 느린 단점이 존재한다.
아무튼 Text Preprocessing(텍스트 전처리)과정에서 사용되는 토크나이저를 다 다룬것도 아닌데 꽤 많은 내용을 정리해야 했다.
문제는 Text Preprocessing(텍스트 전처리)를 수행하는데 가장 먼저 진행해야 할 항목이 토크나이징이다 보니 첫 걸음부터 좀 빡센감이 있다.
아무튼 큰 고비를 하나 넘겼다.
다음포스트는 규칙기반/기계학습 기반의 토크나이저를 최대한 활용해서 임의의 데이터셋을 Text Preprocessing(텍스트 전처리)를 수행하고
그 이후에 Pre-trained Tokenizer에 대해 본격적으로 다루도록 하겠다.
