
0. 실습개요
PDF 문서 기반 QA RAG를 설계하면서 필자가 이해가 안되는 정보를 정리하고, 응용한 내용을 기술하고자 한다.
1. document_loaders
https://python.langchain.com/docs/integrations/document_loaders/
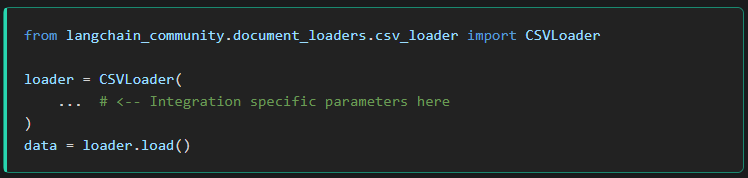
먼저 RAG의 핵심이라 볼 수 있는 데이터베이스의 정보 취득은
Document loaders 컴포넌트를 통해 수행되며, 크게
Web, PDF 두 형태로 데이터 취득에 대해 방법이 기술되어 있고,
특별한 데이터베이스 저장소 : Cloud Providers
소셜 플랫폼(Twitter, Radit)
메세지 서비스 플랫폼(Telegran, WhatsApp, Discord)
생산성 플랫폼(Notion, Slack, Trello, Github)
이 4가지 항목에 대해서는 별도의 API를 통해서 데이터 수집이 가능하게끔 기능을 지원하고 있다.
근데 말이 어려울 뿐이지 예제로는 아래와 같다.
우선 깃허브 로더 API를 기준으로 설명할 때
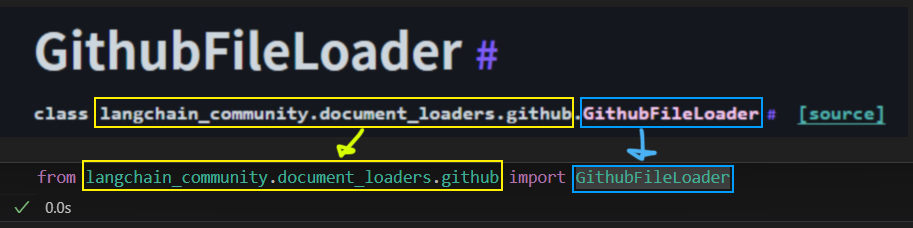
먼저 라이브러리 import 규칙은 해당 사이트에서 설명하는 클래스의 가장 마지막 연보라색을 제외한 부분까지
from 절로 몰아 넣고 연보라색 항목만 import항목으로 빼버리면 된다.
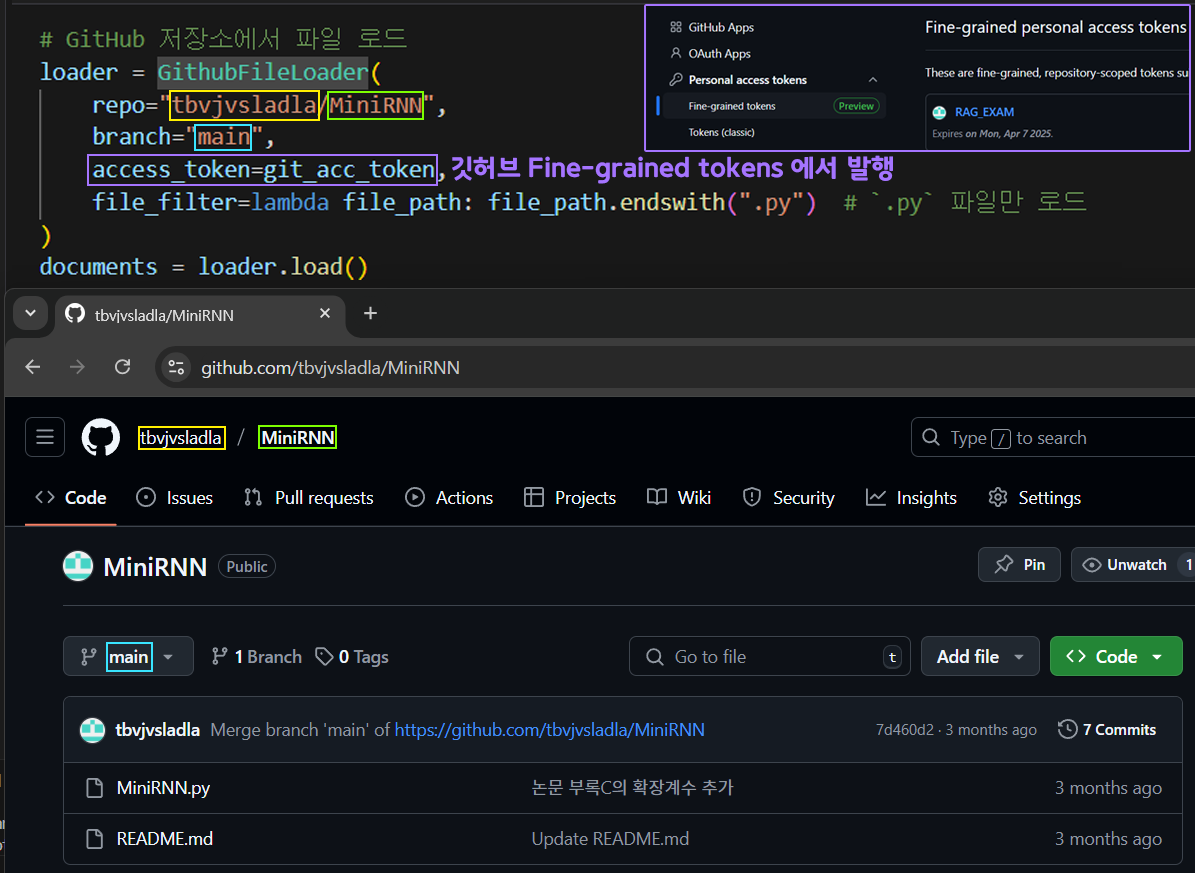
다음으로 loader의 설계는 위 사진처럼
repo, branch, access_token, file_filter순으로 총 4개의 인자값을 채워서
GithubFileLoader클래스를 인스턴스화 하면 된다.
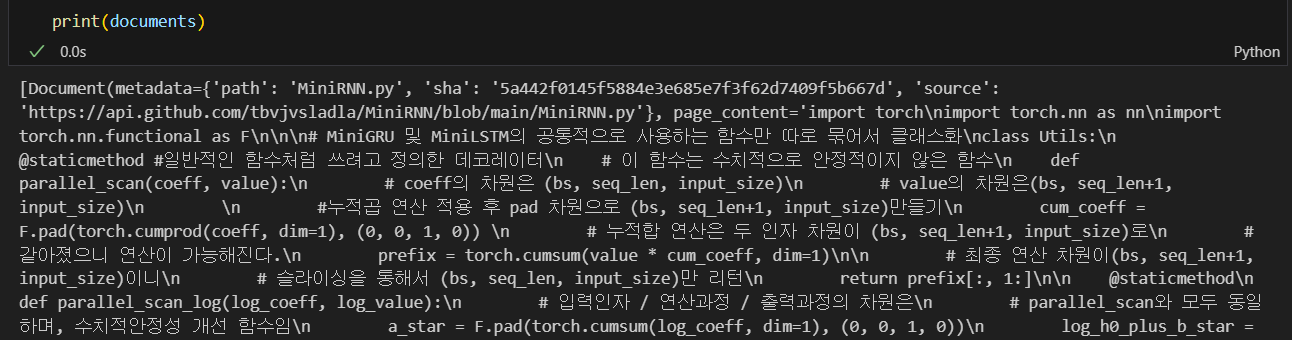
아무튼 Document_loader에서 외부 API기능이 연계되어 자료를 수집하는 것은 위 사진처럼 문제없이 된다
물론 처음 시작할 때 Access token이나 코드에러등은 ChatGPT를 적극 활용하자
1.1 PDF Loader
https://python.langchain.com/docs/integrations/document_loaders/
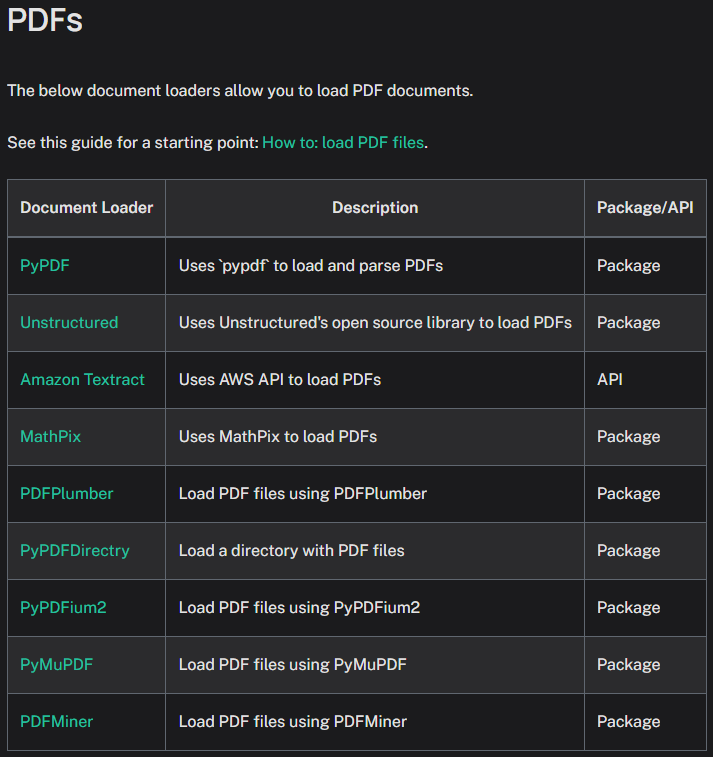
PDF 자료 수집기라 하면 loader이 한종류만 있을 줄 알았는데 여러 종류의 PDF loader을 지원하고 있으며,
다 찾아보면 파이썬 오픈소스 라이브러리에 연동되는 PDF 뷰어 라이브러리를 Langchain에 연동한 것이라 보면 된다.
| Document Loader | 장점 | 단점 |
|---|---|---|
| PyPDF | - 경량화된 패키지로 빠른 성능 - PDF 텍스트 추출에 적합 - 간단한 사용법 | - 복잡한 PDF 레이아웃 지원 부족 - 이미지 기반 PDF 처리 불가 |
| Unstructured | - 문서 레이아웃 및 구조를 분석 - 다양한 형식의 문서 지원 - 확장성 높음 | - 이미지 기반 PDF에는 별도의 설정 필요 - 초기 설정이 복잡할 수 있음 |
| Amazon Textract | - OCR(광학 문자 인식) 지원 - 이미지 기반 PDF 처리에 강력 - AWS 인프라 활용 | - AWS 사용 비용 발생 - 설치 및 설정 복잡 - 인터넷 연결 필수 |
| MathPix | - 수학 방정식 및 수식이 포함된 PDF 처리에 특화 - 높은 정확도 | - 유료 플랜 필요 - 일반 텍스트 PDF 처리에는 비효율적 |
| PDFPlumber | - 텍스트 추출 정확도 높음 - PDF 특정 영역 텍스트 추출 지원 - 직관적인 API | - 복잡한 레이아웃 처리 성능 제한 - 스캔 PDF는 OCR 필요 |
| PyPDFDirectry | - 디렉토리 단위로 PDF를 한번에 처리 가능 - 배치 작업에 적합 | - 개별 파일에 대한 세부 설정은 어려움 |
| PyPDFium2 | - Google PDFium 엔진 사용 - 복잡한 PDF 렌더링 지원 - 성능 우수 | - 상대적으로 높은 학습 곡선 - 이미지 기반 텍스트 추출 기능 부족 |
| PyMuPDF | - 빠른 텍스트 및 이미지 추출 - PDF 페이지 렌더링 강력 - 다양한 기능 제공 | - 스캔 PDF OCR 기능 없음 - 복잡한 구조의 문서 지원 제한 |
| PDFMiner | - PDF 텍스트 레이아웃 보존 - 고급 사용자를 위한 세부 옵션 지원 | - 느린 처리 속도 - 설정 및 사용법 복잡 |
이중 필자는 PyMuPDF를 바타으로 실습을 수행하고자 한다.
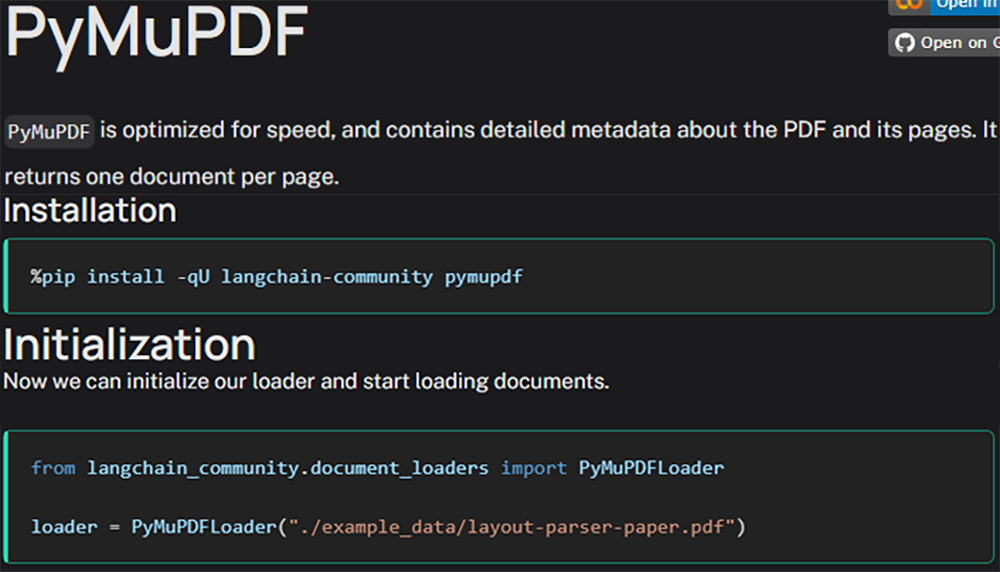
먼저 해당 라이브러리가 설치 안되있다면
pip install -qU langchain-community pymupdf를 수행하면 된다. langchain-community에 해당하는 라이브러리는 워낙 항목이 방대하게 많기에
유저들이 필요한 항목들이 발생하면 이를 선택하여 설치하는 것을 권장한다
이때 앞에 붙어있는 옵션 -qU는
-q : quiet로 설치중에 발생하는 메세지를 최소화 하라는 뜻이다.
-U : upgrade로 이미 설치된 패키지가 있으면 최신 버전으로 업그레이드 하라는 뜻이다.
아무튼 설치를 진행한 후
임의의 문서로 실습을 진행해보자
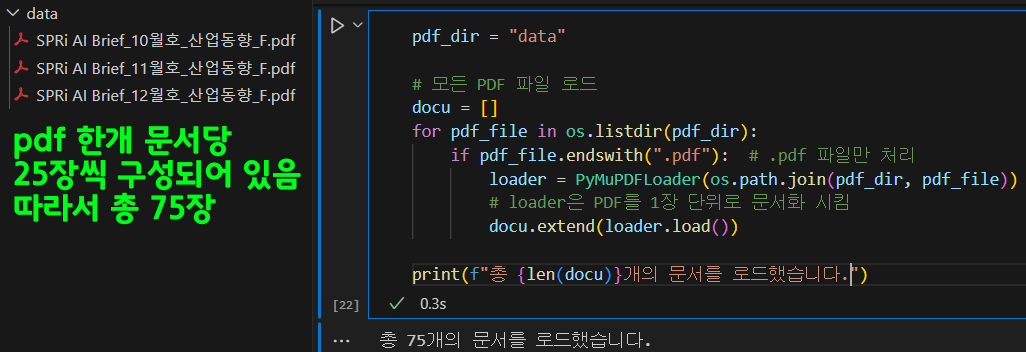
pdf_dir = "data"
# 모든 PDF 파일 로드
docu = []
for pdf_file in os.listdir(pdf_dir):
if pdf_file.endswith(".pdf"): # .pdf 파일만 처리
loader = PyMuPDFLoader(os.path.join(pdf_dir, pdf_file))
# loader은 PDF를 1장 단위로 문서화 시킴
docu.extend(loader.load())
print(f"총 {len(docu)}개의 문서를 로드했습니다.")1.2 Splitter
다음으로는 Splitter에 대한 설정으로 3개의 PDF를 각 장 단위로 75개의 문서로 분할했지만,
어떤 문서는 텍스트량이 많고, 어떤 문서는 테스트량이 적을것이다.
텍스트 량이 적은건 크게 문제가 안되는데
텍스트량이 많아서 RAG을 구성하는데 사용하는 LLM의 입력 토큰 제한 개수를 넘어가는 경우
정보가 유실될 가능성이 있다. 따라서 LLM의 최대 입력 토큰 개수(Max context length)미만으로 입력되게끔
문서를 분할하는 chunking 작업을 진행해야 한다.
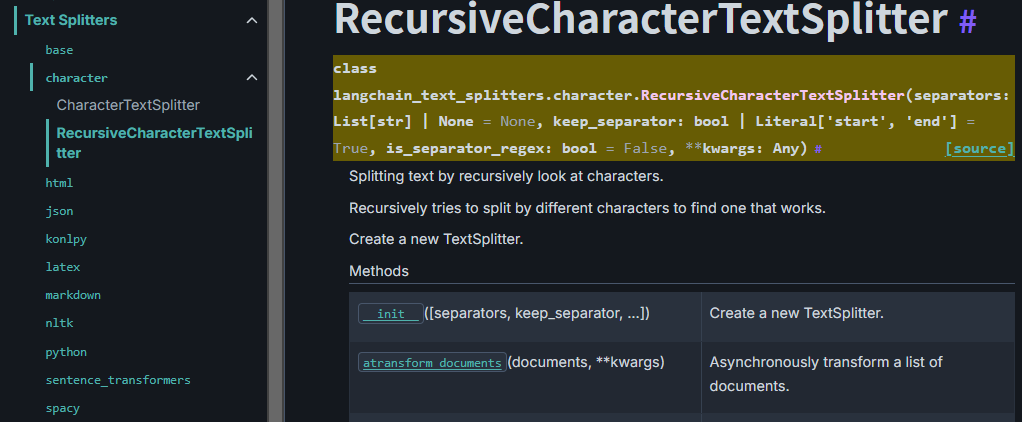
이 Splitter은 지금 단계에서는 Text Splitter만 있는 듯 하며, Text Splitter로 종류별로 굉장히 다양한 메서드가 제공되지만, PDF의 문서를 정보손실 없이 잘 분할하는 메서드는
RecursiveCharacterTextSplitter인 듯 하다.
메서드의 사용예제는 아래의 코드와 같다.
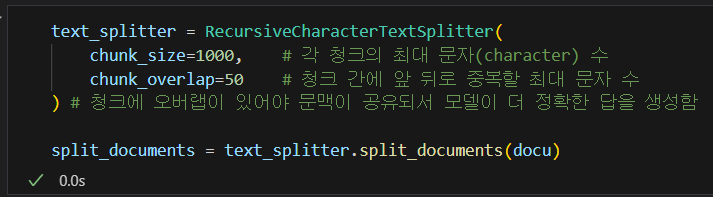
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 각 청크의 최대 문자(character) 수
chunk_overlap=50 # 청크 간에 앞 뒤로 중복할 최대 문자 수
) # 청크에 오버랩이 있어야 문맥이 공유되서 모델이 더 정확한 답을 생성함
split_documents = text_splitter.split_documents(docu)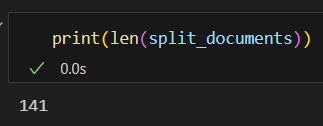
위 사진처러 문서를 split하여 더 작은 단위(chunk)로 분할하면 그 개수가 좀 더 늘어나는 것을 확인할 수 있다.
1.3 Embedding
다음으로 텍스트 데이터를 벡터 표현으로 변환하는 모델인 Embedding 메서드에 대해 알아야 한다.
LangChain 라이브러리에서는 다양한 백엔드 모델(OpenAI, Hugging Face, ollama)등으로부터 텍스트 임베딩 생성이 가능하다.
이때 여러 AI서비스 플랫폼으로부터 임베딩 모델을 연동해서 사용하는 것을 LangChain은 하나의 통일된 인터페이스로 사용하도록 되어 있는데
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(
model="text-embedding-3-large",
# With the `text-embedding-3` class
# of models, you can specify the size
# of the embeddings you want returned.
# dimensions=1024
)위 사진처럼 AI서비스 플랫폼으로부터 특정 임베딩 모델을 선택했다면 LangChain에서 통일된 규격으로 객체화를 하게끔 코드 규칙이 정의되어 있다.
(이거는 어느 임베딩 모델이나 LangChain과 연동되면 동일하게 위 코드처럼 사용된다)
이렇게 연동된 embedding 모델은 AI 서비스플랫폼이 워낙 다양하기에 여러개가 있지만 나열을 해보자면
1) Huggingface
https://python.langchain.com/api_reference/huggingface/index.html
2) ollama
https://python.langchain.com/api_reference/ollama/index.html
3) openai
https://python.langchain.com/api_reference/openai/index.html
4) pinecone
https://python.langchain.com/api_reference/pinecone/index.html
더 많은 임베딩 모델을 선택할 수 있지만 각 서비스 플랫폼 별로 요약하면 아래와 같다.
| 항목 | Hugging Face | Ollama | OpenAI | Pinecone |
|---|---|---|---|---|
| 운영 환경 | 로컬에서 실행 가능. 클라우드 옵션도 지원. | 로컬에서 실행 가능. Ollama 서버를 필요로 함. | 클라우드 기반, OpenAI API 호출 필요. | 클라우드 기반. 벡터 저장 및 검색 기능에 특화. |
| 모델 품질 | 모델에 따라 다름(sentence-transformers 등 다양한 품질 제공). | Ollama 모델 품질은 사용 사례에 특화. | OpenAI의 최첨단 임베딩 모델 제공(예: text-embedding-ada-002). | 자체 임베딩 모델은 제공하지 않음. OpenAI, Hugging Face 등 외부 모델과 연동 필요. |
| 속도 | 로컬 실행 시 빠름(하드웨어 스펙에 의존). | 로컬에서 빠르게 실행 가능. | API 호출 속도는 네트워크 연결에 의존. | 매우 빠른 검색 속도(벡터 스토어 최적화). |
| 비용 | 무료 (로컬 실행), 모델 다운로드 필요. | Ollama 라이선스 정책에 따라 다름(로컬 실행으로 비용 효율적). | 호출당 비용 발생. OpenAI의 가격 정책에 따름. | 클라우드 서비스 비용 발생(Pinecone 요금제에 따라 다름). |
| 사용 편의성 | 모델 다운로드 및 설정 필요. Python 코드로 쉽게 사용 가능. | Ollama 설치 필요. LangChain과 연동 시 간단한 설정 필요. | 간단한 API 호출로 사용 가능. LangChain과 완벽히 통합. | 벡터 스토어로 쉽게 통합 가능. 임베딩 생성은 외부 모델을 활용해야 함. |
| 확장성 | 다양한 모델 지원(BERT, GPT 기반 등). | Ollama 모델만 사용 가능. | OpenAI가 제공하는 모델 범위에 따라 다름. | 대규모 데이터에 대한 확장성 탁월. 검색 및 저장 최적화. |
| 하드웨어 요구 | GPU 또는 고성능 CPU 필요(로컬 실행 시). | 로컬 실행 시 하드웨어 의존. | 클라우드에서 실행되므로 로컬 하드웨어 요구 없음. | 자체 임베딩 모델 없음. 벡터 저장 및 검색에만 초점. |
| 주요 장점 | - 로컬 실행 가능 (비용 절감). - 다양한 오픈소스 모델. | - 로컬에서 실행 (데이터 보안 강화). - 사용 사례 특화. | - 최신 기술 활용. - 높은 품질의 임베딩 제공. - 간편한 설정. | - 대규모 벡터 데이터 저장. - 빠른 검색 속도. - 다양한 임베딩 모델과 통합 가능. |
| 주요 단점 | - 모델 품질이 OpenAI만큼 뛰어나지 않을 수 있음. - 하드웨어 의존. | - Ollama 모델에 제한적. - 커뮤니티 및 지원이 제한적일 수 있음. | - 비용 발생. - 클라우드 연결 필수. | - 자체 임베딩 생성 불가. - 외부 모델과 연동 필요. - 클라우드 기반 비용 발생. |
실습에서는 OpenAIEmbeddings를 사용했으니 이를 활용하여 임베딩 모델을 객체화 하도록 하겠다.
OpenAIEmbeddings에서 제공하는 임베딩 모딜이 종류가 무엇인지 확인하려면 이거는 openai api 페이지에 접속해야 하며
https://platform.openai.com/docs/guides/embeddings/embedding-models

여기서 Pages Per Dollor은 페이지 당 소비 달러
MTEB는 임베딩 모델을 평가하기 위한 벤치마크의 성능결과표이다.
이를 아래와 같이 실습을 진행하자
from langchain_openai.embeddings.base import OpenAIEmbeddings# 임베딩 모델 객체화
# openai처럼 클라우드 모델은 api_key가 필요함
OAi_embeddings = OpenAIEmbeddings(
model="text-embedding-3-small",
api_key=openai_api_key
)text = "임베딩 테스트를 하기 위한 샘플 문장입니다."
# 텍스트를 임베딩하여 쿼리 결과를 생성합니다.
query_result = OAi_embeddings.embed_query(text)
# 임베딩된 쿼리(벡터)의 내용 확인
print(f"차원개수: {len(query_result)}, 원소값: {query_result[0]}")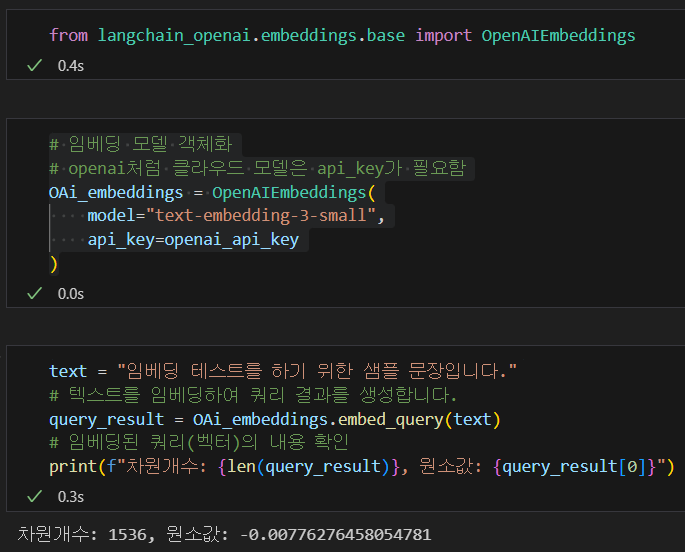
동일한 실습을 hugging face로 수행한다면 로컬 PC에 임베딩모델을 설치하며, 별도의 API_KEY가 필요없으니 비용은 발생하지 않는다.
from langchain_huggingface.embeddings.huggingface import HuggingFaceEmbeddings# 허깅페이스 임베딩 모델 객체화
HF_embedings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-L6-v2",
model_kwargs={'device': 'cpu'},
encode_kwargs={'normalize_embeddings': False}
)text = "임베딩 테스트를 하기 위한 샘플 문장입니다."
# 텍스트를 임베딩하여 쿼리 결과를 생성합니다.
query_result = HF_embedings.embed_query(text)
# 임베딩된 쿼리(벡터)의 내용 확인
print(f"차원개수: {len(query_result)}, 원소값: {query_result[0]}")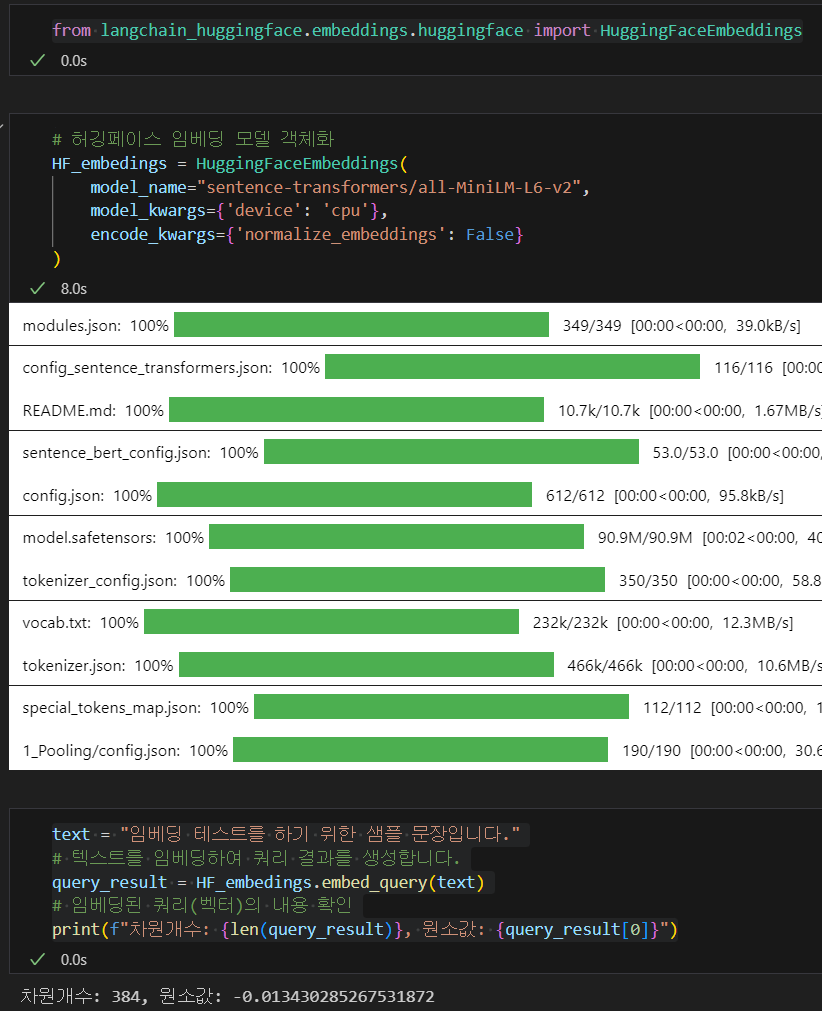
1.4 Vector Store
이제 LangChain의 Vector Store에 대해 알아보자.
Vector Store는 데이터베이스의 한 종류이나, 관리되는 데이터가 벡터, 그러니까 임베드된 매트릭스 데이터를 관리하는 데이터베이스이다.
위 1.3 챕터의 Enbedding에서 문서를 임베드 매트릭스로 변환하니 이를 전용으로 관리하는 데이터베이스를 생성하여
벡터 검색(Vector Search), 유사성 검색(Similarity Search)를 수행
User가 RAG 기반의 Agent에 Query를 남기면
질문과 관련된 문서정보는 모두 임베딩 처리가 되어 있으니 이를 빠르게 검색하여 더 정확한 Response를 제공하는 것이다.
어쨋든 데이터베이스의 한 종류가 Vector Store이니
차이점을 비교하자면 아래와 같다.
| 기준 | 기존 DB (Relational/NoSQL) | Vector Store |
|---|---|---|
| 데이터 형태 | 정형 데이터(테이블, 키-값 등) | 비정형 데이터(텍스트, 이미지 등)를 임베딩 벡터로 저장 |
| 데이터 구조 | 스키마 기반 (Structured Schema) | 벡터화된 다차원 공간 (High-dimensional Vector Space) |
| 검색 방식 | SQL 쿼리, 키 기반 검색, 인덱싱 | 유사성 검색 (Cosine Similarity, Euclidean Distance 등) |
| 검색 대상 | 문자열, 숫자, 키와 값 | 벡터(임베딩된 데이터) |
| 사용 사례 | 금융, 재고 관리 등 전통적 데이터 관리 시스템 | 추천 시스템, 문서 검색, NLP 기반 AI 시스템 |
| 스케일링 | 관계형 DB는 스케일링에 제약이 있음 | 벡터 데이터베이스는 대량의 벡터에 대해 빠른 검색을 지원 |
| 응답 시간 | 수백만 개 이상의 데이터에서 문자열 검색은 상대적으로 느림 | 대규모 데이터에서의 유사성 검색에 최적화 |
| 확장성 | 스키마를 수정하거나 비정형 데이터 처리 시 제약 | 다양한 비정형 데이터를 처리할 수 있는 유연한 구조 |
RAG에서 유독 DB로 Vector Store를 사용하는 이유는 아래의 장점이 있어서이다.
1) 효율적인 정보 검색 : 임베딩 기반 유사성 검색을 통해 관련성 높은 정보를 신속히 검색함
2) 비정형 데이터 활용가능 : 기존 DB로는 처리하기 어려운 비정형 데이터도 임베딩 처리하여 통일된 규격인 임베드 매트릭스를 만들기에 형식이 다양해도 검색에 문제가 없음
3) DB업데이트가 용이함 : 기존 관계형 DB는 스키마 변경 혹은 데이터베이스 재구축이 필요하나, Vector Store는 신규정보를 벡터화 하기에 DB업데이트가 크게 어려운 편이 아니다.
https://python.langchain.com/docs/integrations/vectorstores/
위 링크한 페이지에 접속하면 LangChain에서 제공하는 다양한 Vector Store에 대한 예제코드를 확인하는 것이 가능하며,
LangChain에서도 기본적인 VectorStore가 제공되지만
Chroma, FAISS, PineconeVectorStore등의 다른 벡터스토어도 사용이 가능하다.
우선 InMemoryVectorStore에 대한 사용예제는 아래와 같다.
from langchain_core.vectorstores import InMemoryVectorStore# LangChain에서 제공하는 기본 Vector Store를 활용
In_vector_store = InMemoryVectorStore(
embedding=HF_embedings
)
# 객체화한 벡터스토어에 청킹처리된 도큐먼트를 모두 입력
In_vector_store.add_documents(split_documents)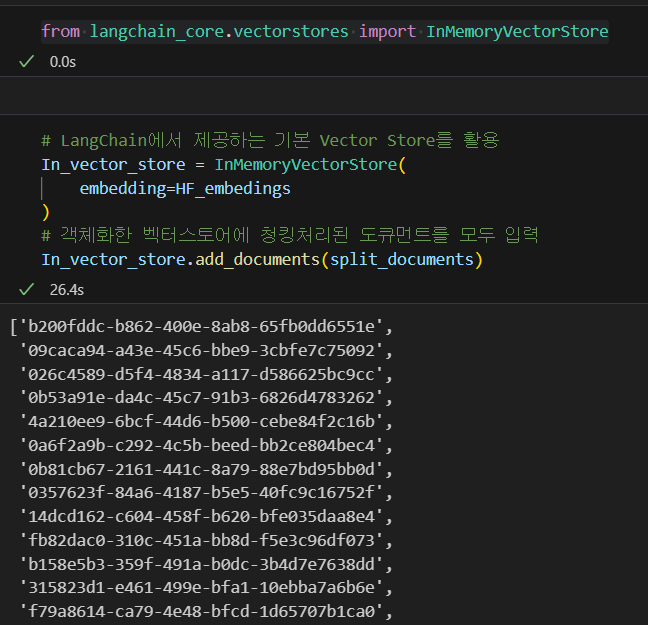
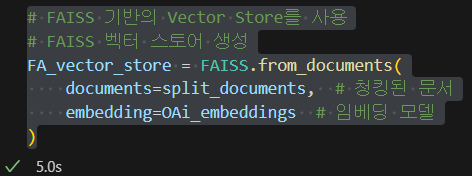
비슷한 코드규칙으로 FAISS는 아래와 같이 사용한다.
from langchain_community.vectorstores import FAISS# FAISS 기반의 Vector Store를 사용
# FAISS 벡터 스토어 생성
FA_vector_store = FAISS.from_documents(
documents=split_documents, # 청킹된 문서
embedding=OAi_embeddings # 임베딩 모델
)
In Memory Vector Store랑은 조금 다르게 객체화가 이뤄졌지만
최소 필요인자값으로
1) 벡터스토어에 등록할 문서리스트
2) 해당 문서를 임베딩하는 모델
이것 2개는 필요하다.
아무튼 벡터스토어를 생성했으면 해당 벡터스토어에 접속하여 검색을 수행하는 검색기(Retriver)을 같이 적용해야한다.
# 생성한 FAISS 벡터스토어를 검색하는 검색기(Retriever)생성
FA_retriever = FA_vector_store.as_retriever()1.5 Prompt Template
이제 LLM에 질문을 입력하기 위한 방법인 Prompte Template에 대해 설명하고자 한다.
RAG로 설계하는 Agent는 쉽게 생각을 하면
1) 질문 대상인 LLM에게 질문을 잘하자
2) 질문 대상인 LLM이 질문에 대한 해답을 특정 규칙에 의거하여 풀이하도록 하자
이렇게 볼 수 있을 것 같다.
이 1), 2)항목을 정의하는것이 필자는 Prompt Template라고 생각한다.
