
1. LLaMA Cpp

https://github.com/ggerganov/llama.cpp
C/C++ 기반의 경량화된 LLM을 실행(추론) 하는 기능을 제공하는 엔진으로 주요 수행가능한 항목은 아래와 같다.
1) LLM의 Local PC 구동 지원 : llama이나 gemma 같이 로컬PC에 설치가 가능한 LLM이 있는데 해당 모델의 구동을 지원한다.
이때 단순히 구동만 지원하는 수준이 아니라 CPU기반으로도 구동을 가능케 하여 GPU가 없는 환경에서도 추론기능이 수행되게끔 지원한다.
2) 호환성 높은 모델 파일구조 지원 : LLama.cpp는
GGUF(Georgi Gerganov Unified Format)이라는 전용 파일포멧을 지원하는데
파일포멧에 Georgi Gerganov 본인의 이름을 넣은 것도 꽤 대단하지만

파일 구조도 모델의 가중치 및 메타데이터를 효율적으로 압축하고 확장성 높게 설계되어 있다.
이를 간단하게 요약하자면 *.gguf파일 확장자로 저장된 모델은 HuggingFace나 Ollama, Langchain 등의 여러 딥러닝 프레임워크에서 호환을 지원하니
약간 딥러닝 모델 배포할 때 *.onnx확장자로 배포하는 것과 동일하게 받아들여도 된다.
3) 다양한 양자화 지원 : 모델의 크기를 줄이기 위한 방법론으로는 Quantization, Knowledge Distillation, Model Pruning, Embedding Compression등의 다양한 방법이 있지만
필자가 보기에는 가장 간단하게 모델 크기를 줄이는 방식은 Quantization인 것 같다.
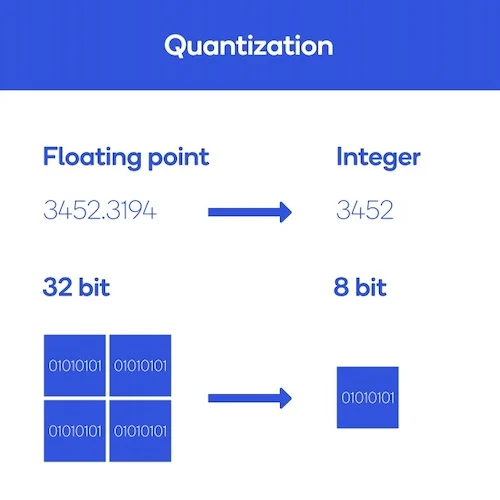
모델의 weight parameter이 정의되어 있는 데이터 타입을 높은 정밀도를 갖는 float32에서 낮은 정밀도의 int8 등으로 줄이는 것인데 llama.cpp는 이 Quantization을 버전별로 다양하게, 그리고 손쉽게 적용하는 것이 가능하다.
이 외에도 여러 장점이 있지만 이정도만 설명을 하고
이제 사용방법에 대해 기술하겠다.
llama.cpp 자체의 빌드 및 실행에 관해서는 Windows에서도 구동이 가능하지만
음.. 사용예제가 ubuntu 환경이 많아서
필자는 wsl-ubuntu환경에서 구동을 진행하려 한다.
2. WSL-ubuntu 사전설정
먼저 llama.cpp의 구동 및 임의의 변환한 *.gguf파일이 잘 동작하는지 확인하기 위해
1) CUDA Toolkit
2) Pytorch - WSL - Ubuntu
를 먼저 설치한다
CUDA Toolkit
https://developer.nvidia.com/cuda-toolkit-archive
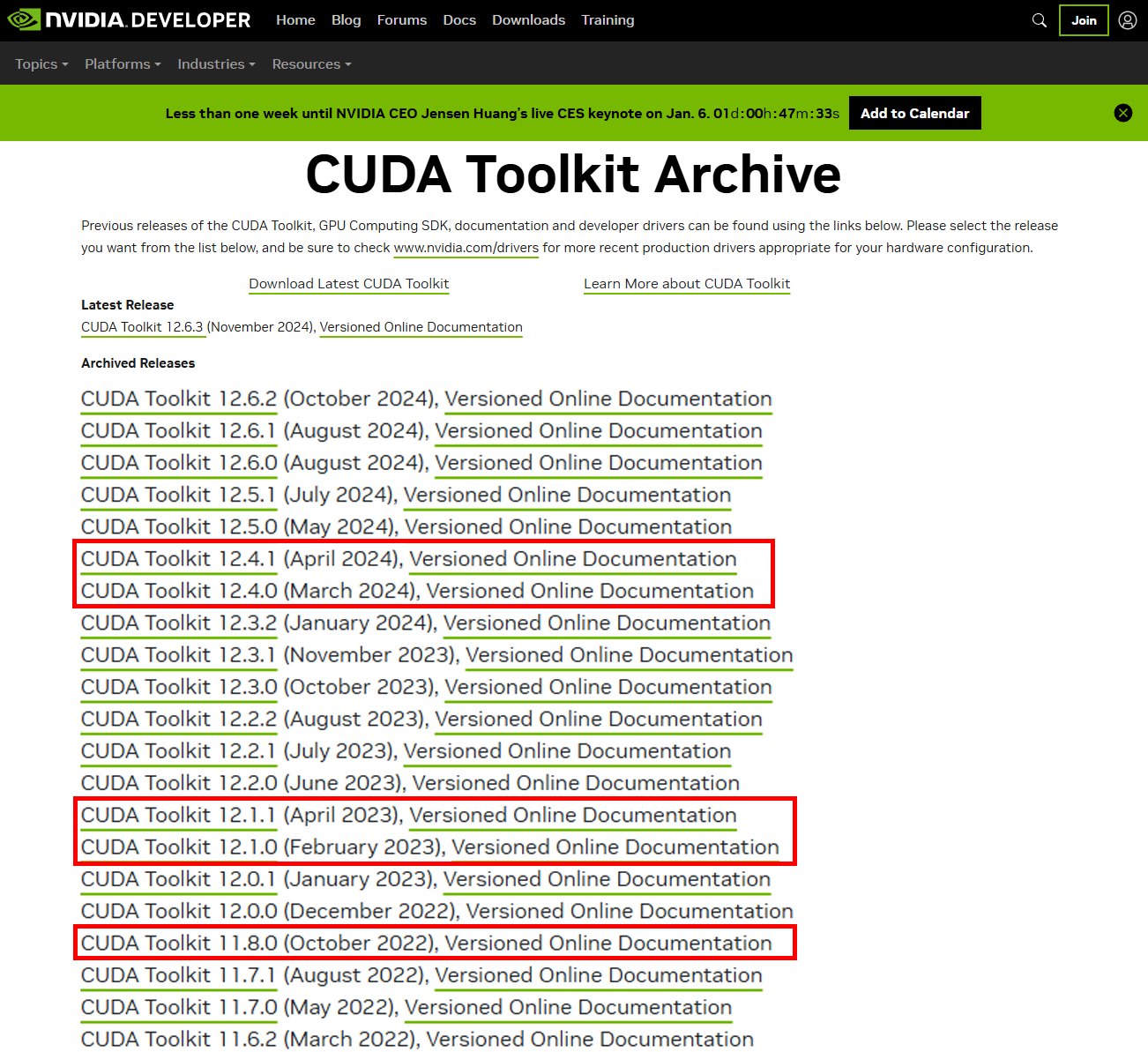
해당 페이지에 접속하면 CUDA Toolkit 버전이 여러개 있는데
붉은색 박스로 표시한
11.8, 12.1, 12.4 버전의 CUDA Toolkit 설치를 권장한다
이유는 뒤에서 기술하도록 하고
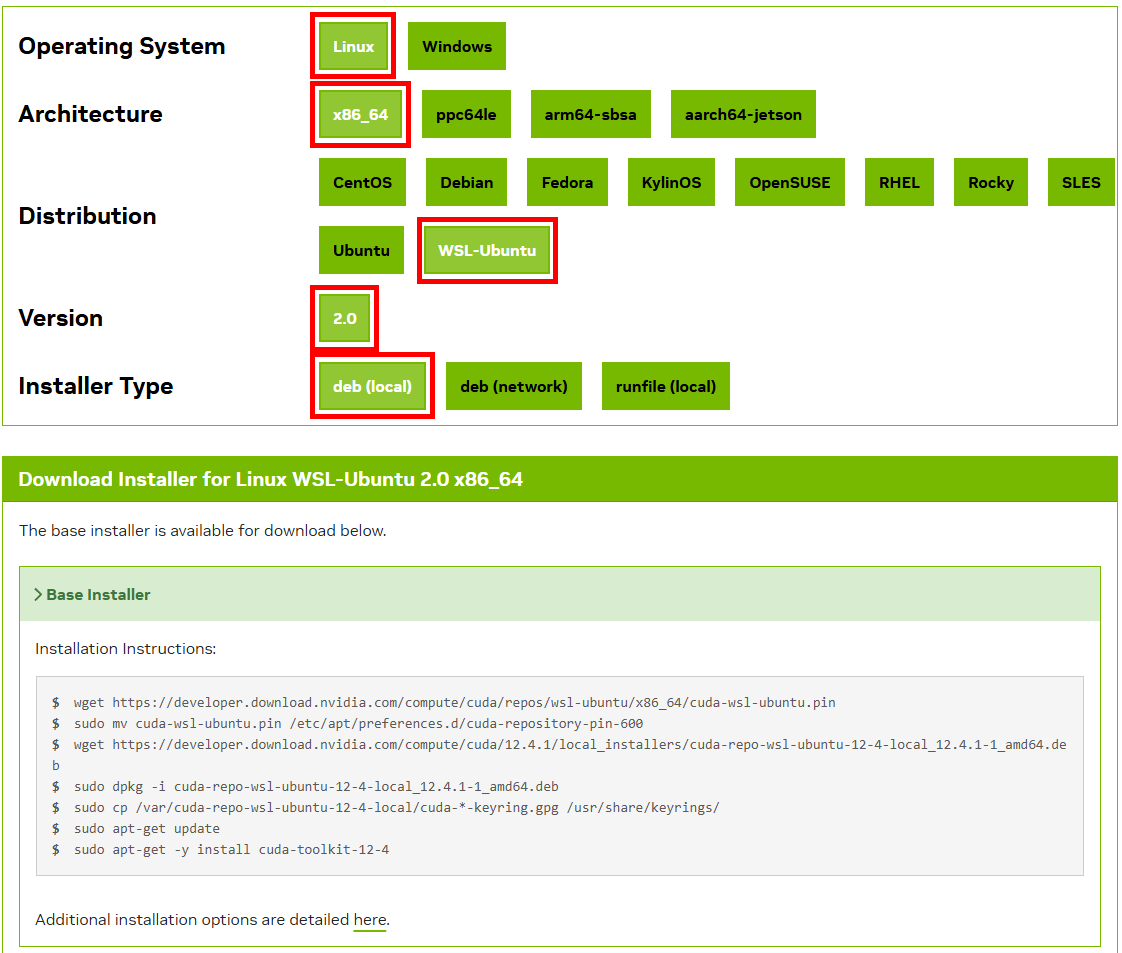
아무튼 버전 하나 선택을 하고 Linux -> x86_64 -> WSL-Ubuntu -> 2.0 -> deb(local)을 선택하면
아래의 설치 명령어가 활성화 된다.
wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-wsl-ubuntu.pin
sudo mv cuda-wsl-ubuntu.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/12.4.1/local_installers/cuda-repo-wsl-ubuntu-12-4-local_12.4.1-1_amd64.deb
sudo dpkg -i cuda-repo-wsl-ubuntu-12-4-local_12.4.1-1_amd64.deb
sudo cp /var/cuda-repo-wsl-ubuntu-12-4-local/cuda-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cuda-toolkit-12-4위 명령어를 차례대로 WSL-ubuntu에서 실행해서 설치를 진행하면 된다.
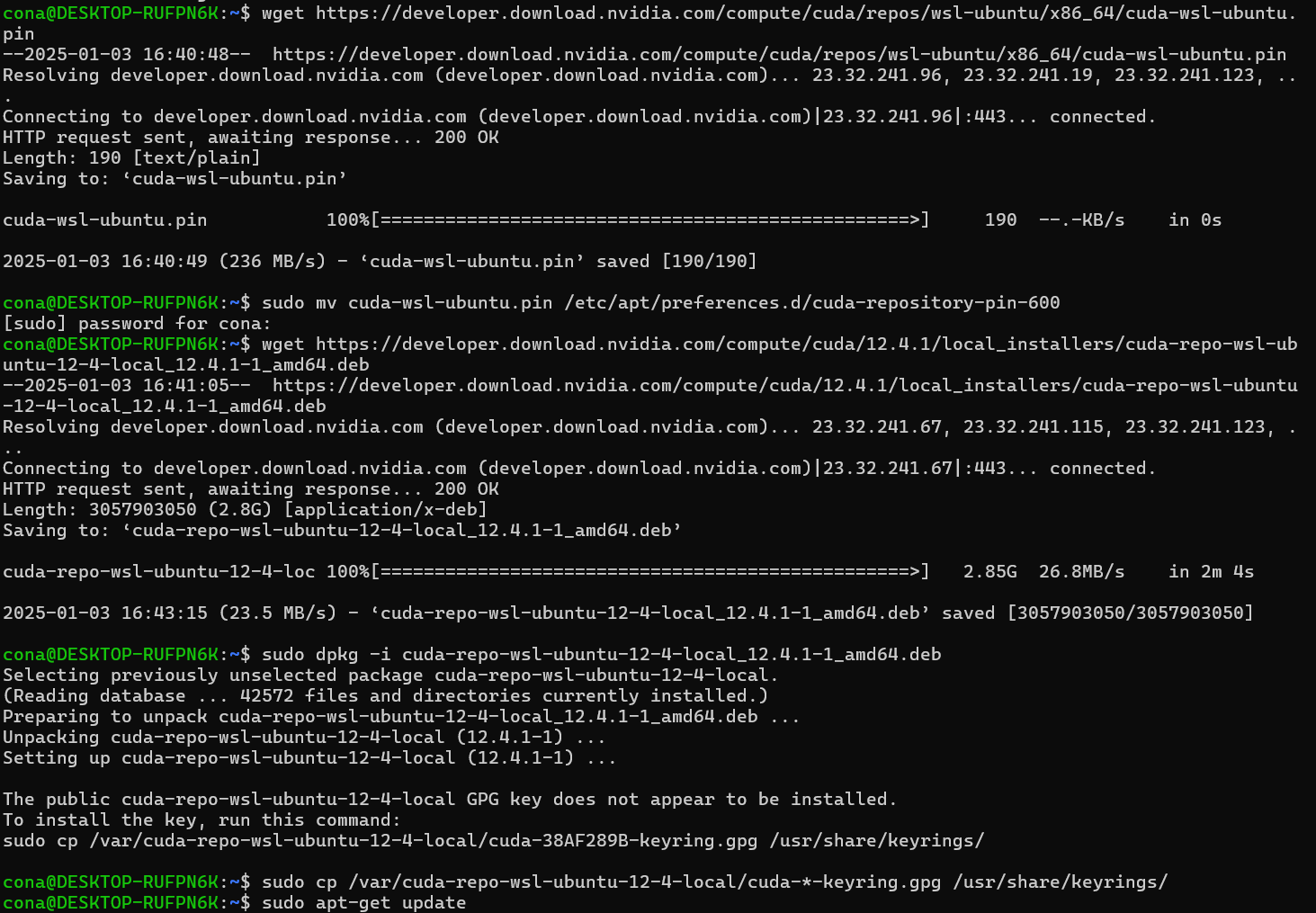
아무튼 설치를 다 하고 나면 nvcc -v, nvidia-smi등으로 정보를 확인하고 싶은데.. 음 이게
nvcc-v로 정보를 확인하려면
sudo apt install nvidia-cuda-toolkit이 명령어를 수행해야 하는데 이걸 수행하면 최신버전 cuda-toolkit이 설치되 버리고
nvidia-smi로는 정보가 자세하게 출력되지 않는다.
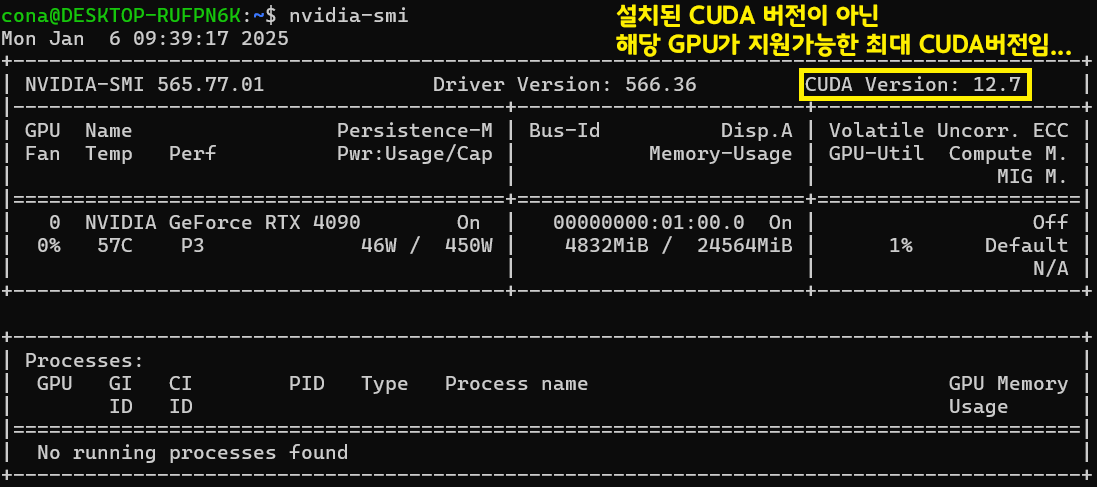
이 문제를 해결하려면 .bashrc부분을 아래와 같이 수정해야 한다.
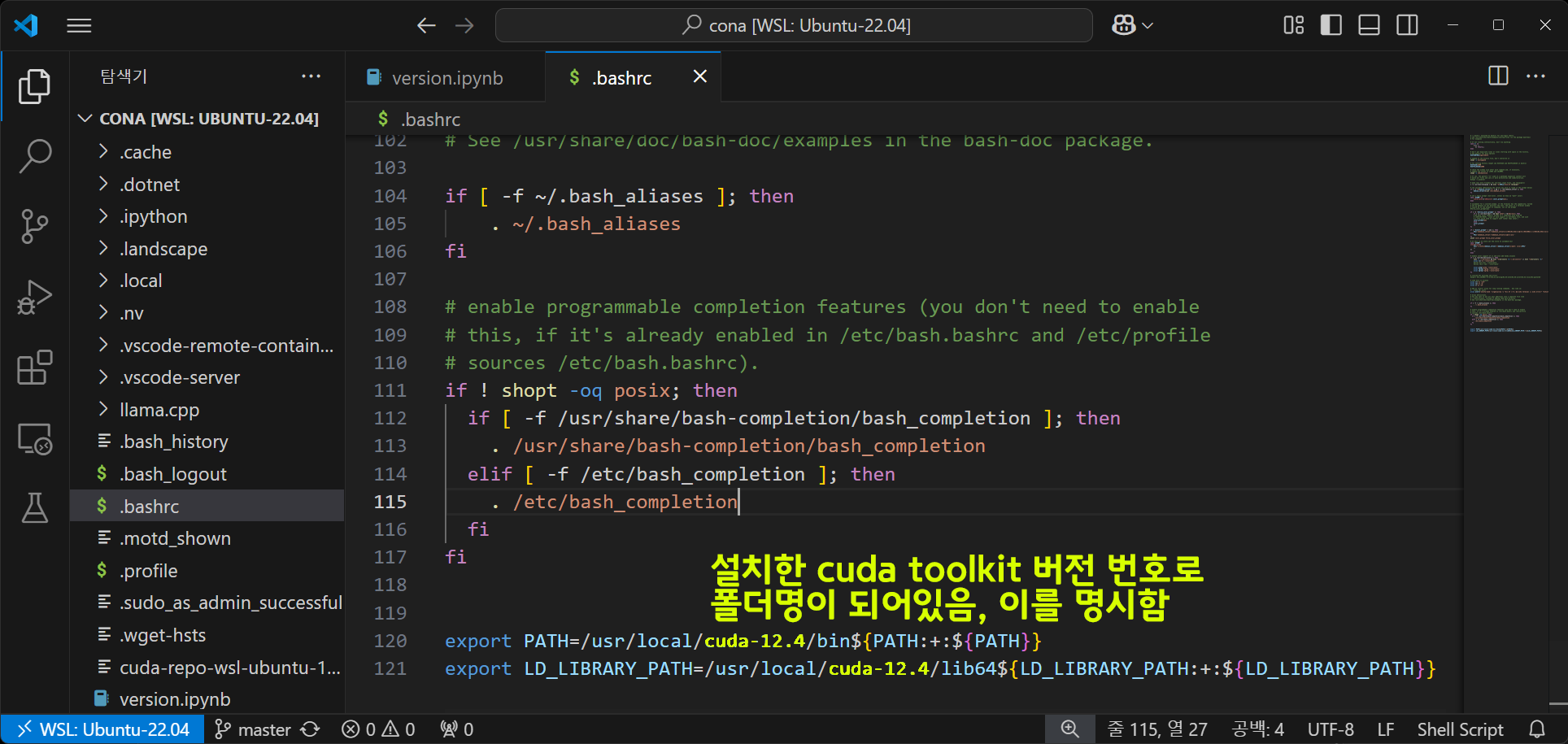
.bashrc에 기입을 수행해야 하는 부분
# cuda-12.4 -> 이 부분에 설치한 cuda toolkit버전입력
export PATH=/usr/local/cuda-12.4/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-12.4/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}수정을 완료한 뒤에는
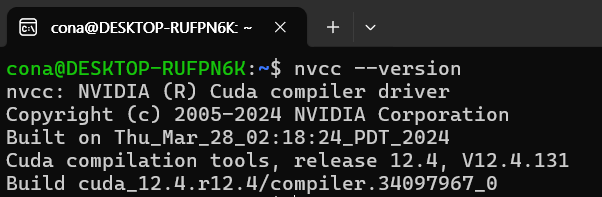
source ~/.bashrc이후에 nvcc --version 명령을 수행하면 제대로 설치된 nvcc가 뜬다
Pytorch - WSL - Ubuntu
https://pytorch.org/get-started/locally/

사실 pytorch의 경우 wsl-ubuntu나 그냥 ubuntu를 구분하지 않고, cuda버전이 12.4는 명령어 코드가 짧지만
12.1이나 그 이전버전의 cuda는 별도의 다운로드 링크가 명시된다.
pip3 install torch torchvision torchaudio
# CUDA버전이 12.4 이전버전의 경우
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121wsl-ubuntu에 pip3 설치과정을 진행하려면 먼저
sudo apt install python3-pip를 진행해주자
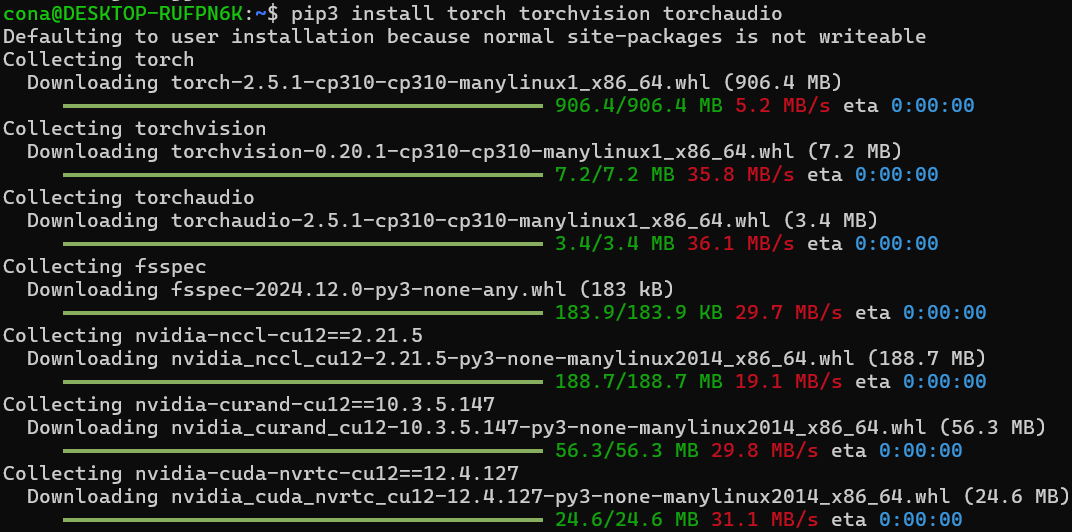
아무튼 이것저것 다 설치를 완료했으면 vscode 로 현재까지 설치가 잘 되엇는지 모두 확인해보도록 하겠다.
3. llama.cpp설치
먼저 작업공간 폴더를 하나 지정하고 git clone를 수행한다.
git clone https://github.com/ggerganov/llama.cpp.git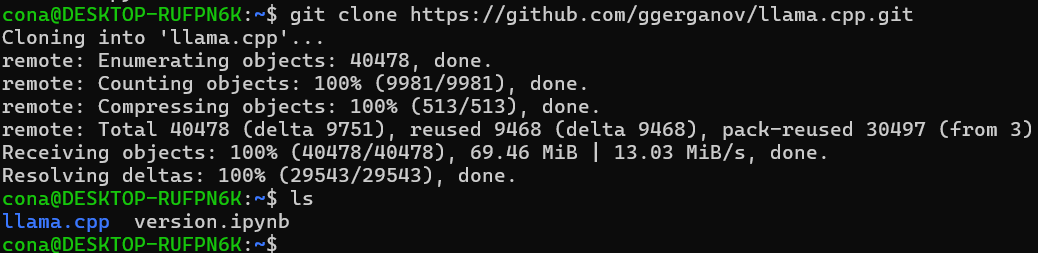
git clone를 수행을 완료하면 llama.cpp폴더가 생성된다.
이제 해당폴더를 빌드해야 하는데 빌드에 필요한 메뉴얼은 아래와 같다.
https://github.com/ggerganov/llama.cpp/blob/master/docs/build.md
여기에 나와잇는 대로 설치를 진행하면 되는데
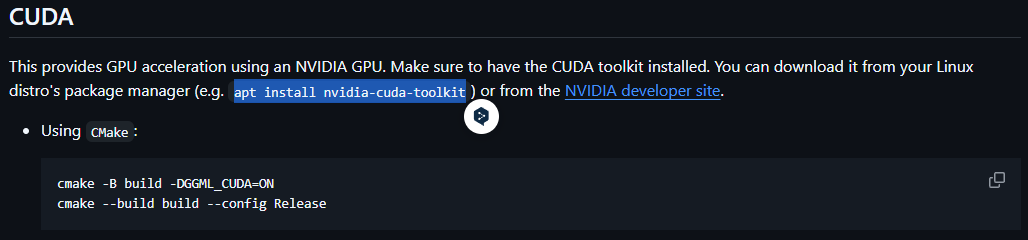
여기서 CUDA 항목에 나와있는 CMake 빌드 방식을 선택해야 한다.
cmake -B build -DGGML_CUDA=ON
cmake --build build --config Release
빌드에 꽤 많은 시간이 소요되니 여유를 갖고 수행하자.
아무튼 make를 완료했다면 아래의 명령을 수행하여
llama.cpp를 구동하는데 필요한 기타 의존성 패키지를 모두 설치하자.
cd requirements/
pip install -r requirements-all.txt
requriements폴더 내에 이것저것 종류별로 의존성 패키지 설치하는게 다 나눠져 있는데
그냥 속편하게 requirements-all.txt으로 전부 설치하면 된다.
4. GGUF 모델 변환하기
make까지 완료했다면 본격적으로 huggingface 모델을 다운로드 받은 뒤 이를 llama.cpp 에서 정의하는 규격인 *.GGUF로 변환하는 실습을 진행하자
사전 준비작업
huggingface에서 관리하는 대형 파일을 다운로드 받으려면 먼저 Git LFS를 설치해야 한다.
sudo apt update
sudo apt install git-lfsgit lfs install다음으로 허깅페이스 CLI를 활용하여 모델을 다운로드할 예정이니 아래의 CLI설치 및 로그인을 진행하자
pip install huggingface_hub
huggingface-cli login
참고로 cli로그인을 하려면 access token이 필요한데
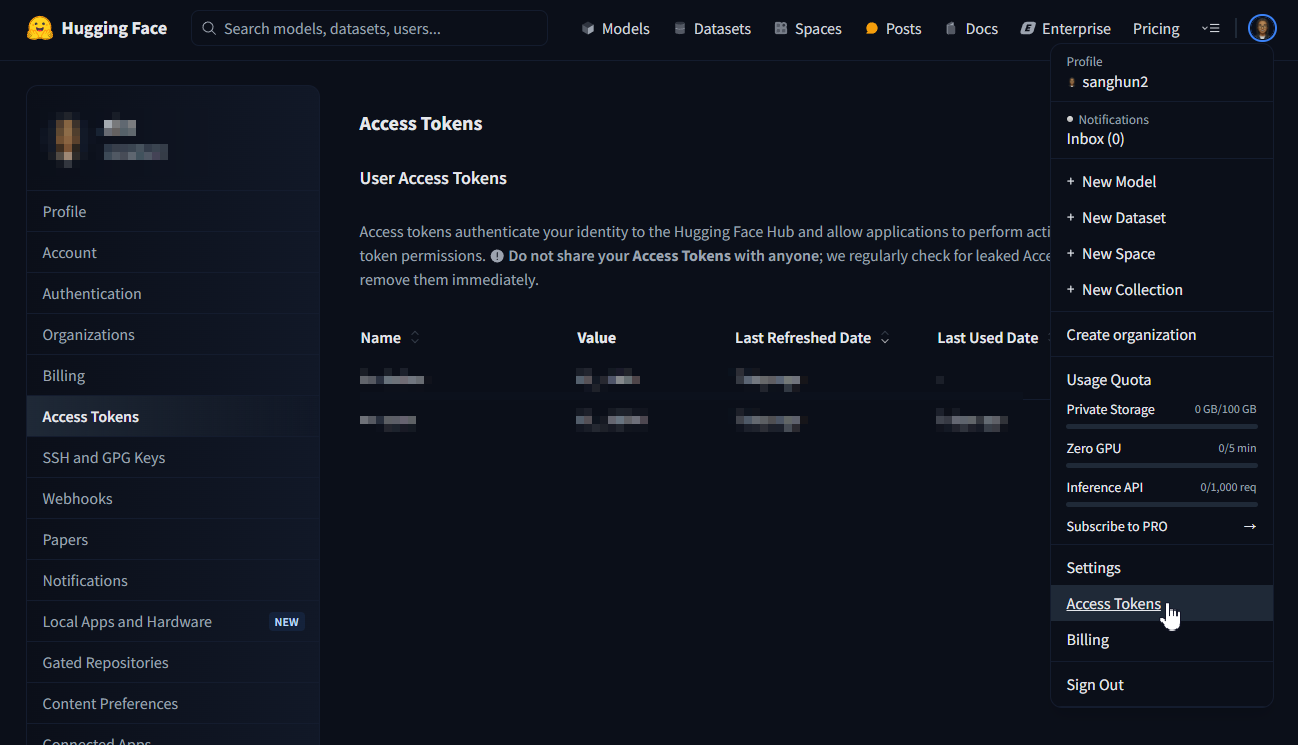
이거는 허깅페이스의 Access Token에서 쉽게 발부받을 수 있다.
허깅페이스 모델 다운받기
*.GGUF변환 실습용 예제 모델은 llama-3.2-Korean-Bllossom-3B를 사용한다.
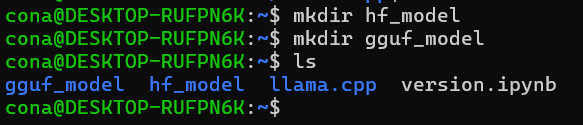
폴더는 허깅페이스 모델을 담기 위한 hf_model, 그리고 gguf로 변환한 모델을 담기 위한 gguf_model 폴더 2개를 생성했다.
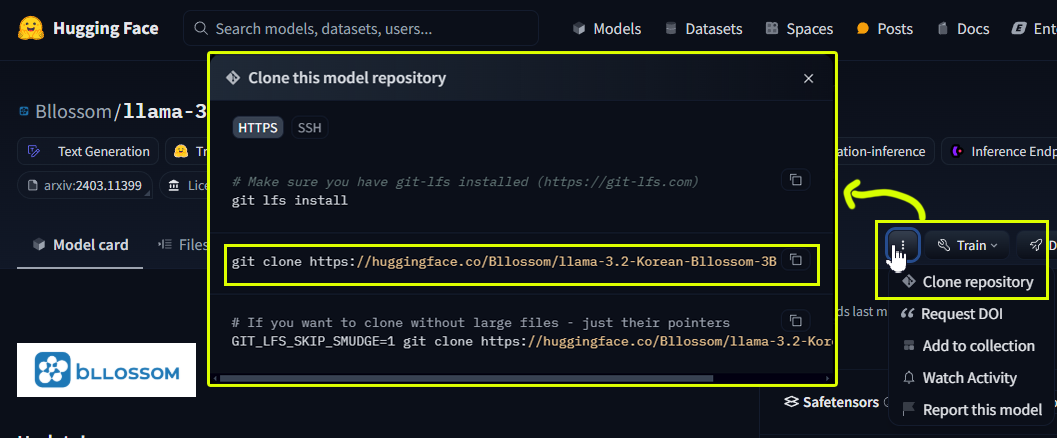
먼저 모델을 다운로드 하기 위한 주소를 위 사진처럼 알아낸 뒤
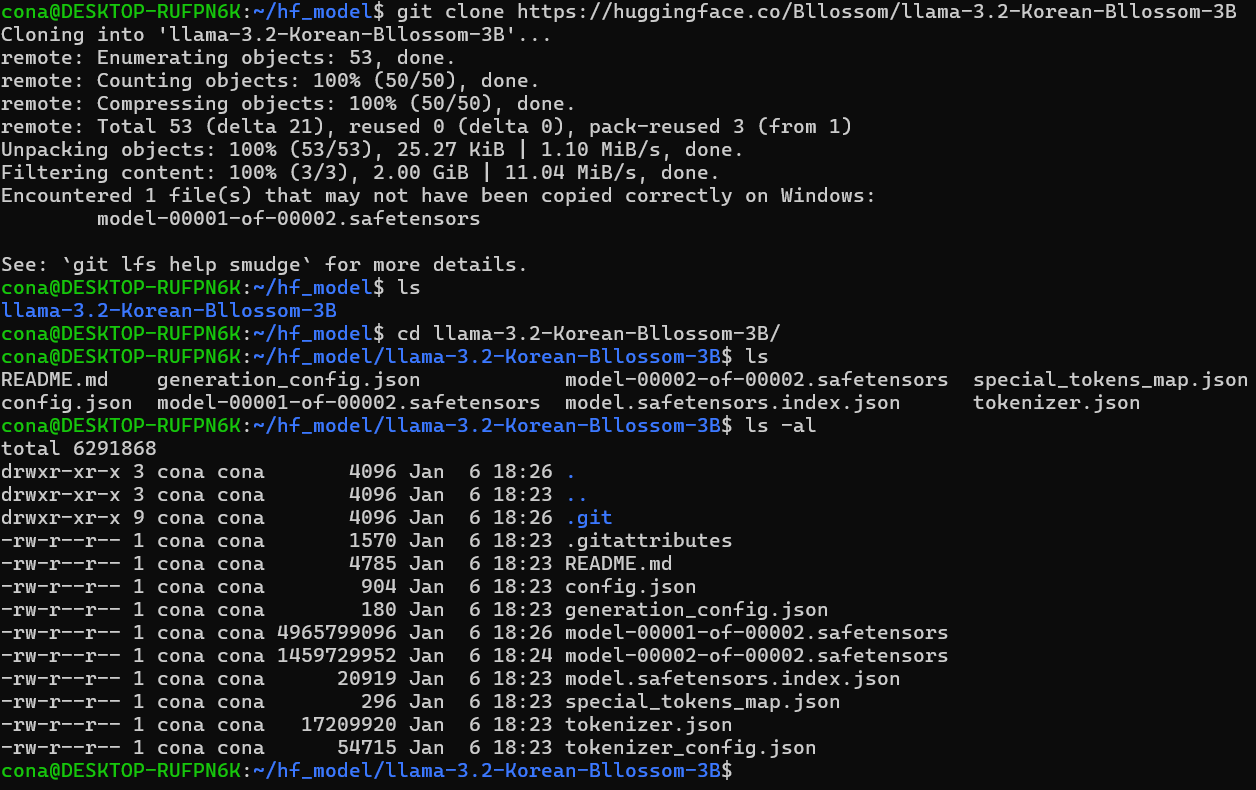
대충 위 사진처럼 모델 파일을 다운로드 받으면 1차는 완료한 것이다.
모델 gguf 로 변환하기

다음으로 빌드가 끝난 llama.cpp 폴더로 돌아간 뒤 노란색 박스 친 convert_hf_to_gguf.py파일을 활용하여 gguf 모델파일을 생성하자

python3 convert_hf_to_gguf.py [허깅페이스모델경로] --outfile [변환한 파일저장경로] --outtype [양자화타입]양자화 타입은 auto로 해도 되는데
llama-3.2-Korean-Bllossom-3B의 Tensor type을 보면 BF16이라 기재되어 있어서 동일타입으로 설정한다.
변환은 의외로 어렵지 않게 수행이 됨을 확인했다.
약간 파일 크기가 커진것 같지만 기분탓으로 여기자.,.
