
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 AI 핵심 기술 집중 클래스의 자연어처리(NLP) 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
1. 포스트 목적
이전 포스트 NLP- Seq to Seq (4-2) : Beam Search에서 Pytorch에서 제공하는 다양한 함수(메서드)를 사용하다 보니 정리할 필요성이 느껴저 이를 작성하고자 한다.
2. Tensor과 Ndarray
먼저 Pytorch에서 주로 다루는 데이터 자료형인 Tensor과 Numpy에서 주로 다루는 데이터 자료형인 ndarray는 다차원 배열과 배열 생성 시 다양한 데이터 타입 적용이 가능하지만 주요한 차이점이 존재한다.
우선 가장 중요한 차이점은 GPU를 활용한 연산이 가능한가? 이다.
그 외로 중요한 기능들에서 차이점이 있지만 이거는 표로 요약하여 확인하자
요약
| 특징 | tensor (PyTorch) | ndarray (NumPy) |
|---|---|---|
| 주요 라이브러리 | PyTorch | NumPy |
| GPU 지원 | 가능 | 불가능 (CuPy 필요) |
| 자동 미분 | 지원 (requires_grad) | 미지원 |
| 주요 사용 목적 | 딥러닝, 신경망 훈련 및 추론 | 수치 계산, 데이터 분석 |
| 변환 가능 여부 | .numpy()로 변환 가능 | torch.from_numpy()로 변환 가능 |
이제 딥러닝 공부를 하면서 사용한 주요 Pytorch - Tensor 함수에 대해 설명을 진행하겠다.
torch.rand()
임의의 매트릭스데이터를 만들어내는 메서드 인데
주로 내가 어떤 딥러닝 모델이나 클래스를 설계했으면
이 모델이 실제로 코드상 문제가 없는지 테스트 하는 용도로 많이 사용된다.
import torch
import torchvision.models as models
# 임의의 테스트 하고자 하는 모델을 만들기
# 지금은 편의상 다른데서 모델을 불러옴
model = models.vgg16()
# 설계한 모델이 잘 동작하는지 확인하기 위해
# 임의의 입력 텐서를 하나 만든다
# 입력하는 텐서 데이터는 [배치 크기, 채널 수, 높이 너비]의 4차원 데이터 형태임
input_tensor = torch.rand(1, 3, 224, 224)
# 임의의 텐서를 모델에 입력해 모델이 출력을 내는지 테스트
output = model(input_tensor)
# 모델 출력 결과가 원하는 차원 형태를 띄는지 사후검증
print("입력한 텐서 차원구조:", input_tensor.shape)
print("모델 출력 차원 구조:", output.shape)
이렇게 내가 설계한 모델이
1) 입력은 받을 수 있게 되어 있는지 (코드에러가 없는지?)
2) 출력텐서가 내가 예상한 데이터 구조인지 (논리에러가 없는지?)
이 두가지를 따질 때 주로 사용하는 함수이다.
torch.randint()
이 함수도 위와 비슷하게 설계한 차원에 맞춘 임의의 입력 데이터를 만들지만 생성하는 데이터가 '정수형 데이터 타입'인 것이 큰 차이가 있다.
이 함수는 주로 내가 설계한 모델이 NLP를 수행하는 언어모델이 잘 설계가 되었는지 테스트할 때 사용한다.
import torch
import torch.nn as nn
# 1. 간단한 자연어 모델 정의 (RNN 기반)
class SimpleRNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim):
super(SimpleRNN, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim) # 임베딩 층
self.rnn = nn.RNN(embedding_dim, hidden_dim, batch_first=True) # RNN 층
self.fc = nn.Linear(hidden_dim, output_dim) # 출력층
def forward(self, x):
embedded = self.embedding(x) # [배치 크기, 시퀀스 길이, 임베딩 차원]
output, hidden = self.rnn(embedded) # RNN 출력
out = self.fc(hidden.squeeze(0)) # [배치 크기, 출력 차원]
return out
# 2. 모델 초기화
vocab_size = 728 # 단어 집합 크기 (가상의 어휘 크기)
embedding_dim = 50 # 임베딩 차원
hidden_dim = 128 # RNN의 은닉 상태 크기
output_dim = 5 # 출력 클래스 개수
model = SimpleRNN(vocab_size, embedding_dim, hidden_dim, output_dim)
# 3. 임의의 정수형 입력 데이터 생성
# 입력 데이터는 [배치 크기, 시퀀스 길이] 형태의 정수형 데이터
Bs = 4 # 배치 사이즈
Seq_len = 10 # 입력데이터의 시퀀스 길이
input_tensor = torch.randint(low=0, high=vocab_size,
size = (Bs, Seq_len))
# 4. 모델 테스트
output = model(input_tensor)
# 5. 결과 출력
print(f"모델 테스트 용 입력 데이터 차원: {input_tensor.shape}")
print(f"언어 모델 테스트 결과 :{output.shape}")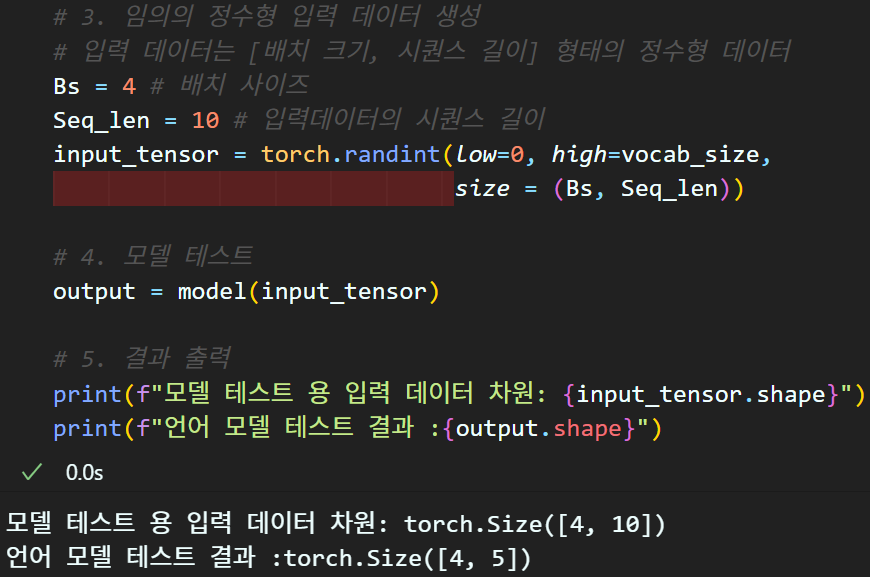
이렇게 모델테스트를 수행할 때 가장많이 사용되는 함수의 사용 예 라 보면 된다.
device
Pytorch의 Tensor데이터는 GPU CPU 으로 연산 위치가 시시각각 변하는 경우가 많기에
선언한 Tensor 변수가 어느 위치에 있어야 하는지? 를 잘 알아야 한다.
그래서 가장 많이 사용하는 구문 먼저 소개하고자 한다
# 현재 코드 개발환경에서 GPU사용이 가능한지 체크
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')이 코드는 개발 시작부나 모델 설계 후 객체화를 하기 전에 왠만하면 꼭 집어넣는것을 권장한다.
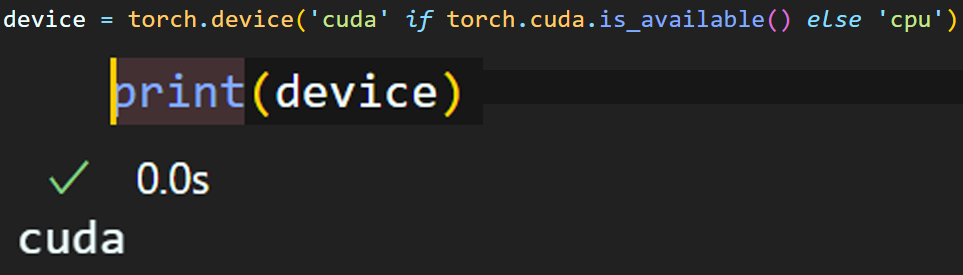
이렇게 cuda, GPU사용이 가능한지 먼저 체크를 하고
본격적으로 Tensor 변수의 연산 위치를 자유로이 제어를 진행하는 것이다.
위 구문으로 GPU사용이 가능해졌음을 확인했으니 아래의 구문등을 실습하자
.to(device) : GPU 사용이 가능해졋음을 알았으니 선언한 Tensor을 GPU로 이동
exam = torch.randn(3, 3)
exam = exam.to(device) # 텐서를 GPU로 이동
print(exam.device) # 선언한 Tensor가 GPU로 이동했는지 확인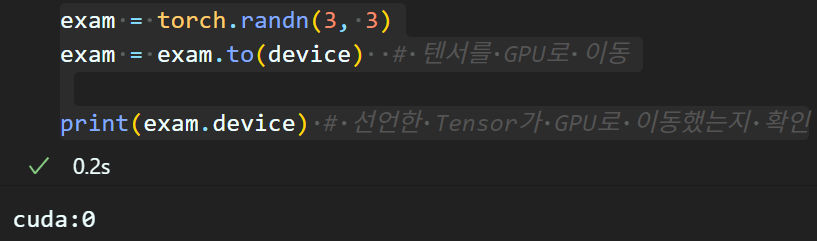
여기서 한발짝 더 나아가면 Tensor을 어느 어느 프로세서로 연산을 수행하라는지 지정하는 것도 응용 할 수 있을 것이다.
exam = exam.to('cpu') # 텐서를 CPU로 강제 이동
print(exam.device) # 선언한 Tensor가 이동했는지 확인
exam = exam.to('cuda') # 텐서를 CUDA로 강제 이동
print(exam.device) # 선언한 Tensor가 이동했는지 확인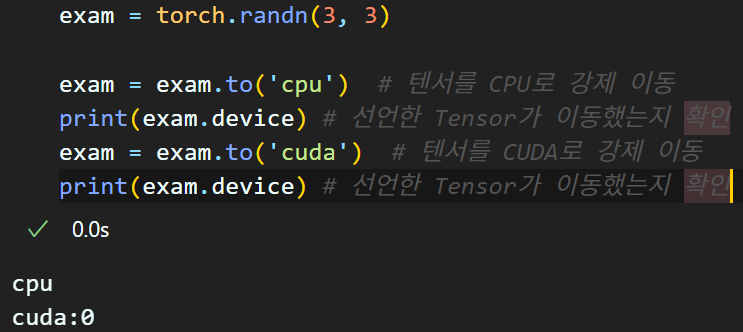
여기까지가 기초중의 기초이고
이제 필자가 그동안 포스트를 쓰면서 겪은 각 Tensor에 대하여 설명하겠다.
torch.full()
Tensor 데이터를 생성할 때 매트릭스 차원내의 각 원소를 특정 value로 채우고자 할 때 사용하는 함수이다
torch.zeros() 보다 좀 더 넓은 기능을 수행하는 함수라 보면 된다.
BS = 4
input_token = torch.full(size=(BS, 4), fill_value=5)
print(input_token)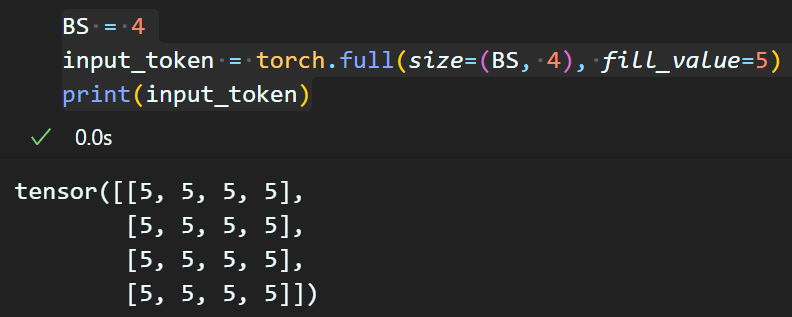
torch.zeros()
이 함수는 바로 위에서 torch.full()에서 설명했는데 왜 이어서 설명하냐면, 이렇게 선언안 녀석은 데이터타입을 boolean으로 지정해서 사용하는 경우가 종종 있기 때문이다.
자매품으로 torch.ones()도 동일하게 Flag 변수 선언에 유용하다
flag = torch.zeros(size=(BS, 1), dtype=torch.bool)
print(flag)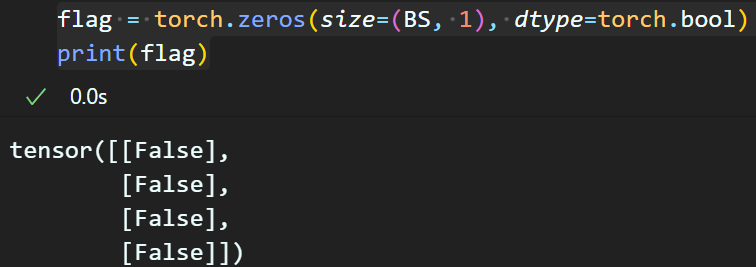
torch.squeeze()와torch.unsqueeze()
위 함수는 선언한 Tensor의 차원 개수
그러니까 2차원에서 3차원 반대로 3차원에서 2차원으로
축소나 확장을 수행할 때 사용하는 메서드이다.
이때 중요한건 차원크기가 무조건 1로 늘어나거나
1 인 것만 줄일 수 있다는 것이다.
exam = torch.rand(3,1,4,1)
print(f"exam텐서의 차원 : {exam.shape}")
#3, 1, 4, 1차원의 idx는 0, 1, 2, 3이다.
exam = exam.squeeze(dim=1)
print(f"exam텐서의 차원 : {exam.shape}")
# idx는 리스트 인덱싱처럼 뒤에서도 순번을 매길 수 있다.
exam = exam.squeeze(dim=-1)
print(f"exam텐서의 차원 : {exam.shape}")
# 차원을 늘리는것은 인자값에 해당하는 순번에 `1`로 빈 차원이 끼어든다.
exam = exam.unsqueeze(dim=0)
print(f"exam텐서의 차원 : {exam.shape}")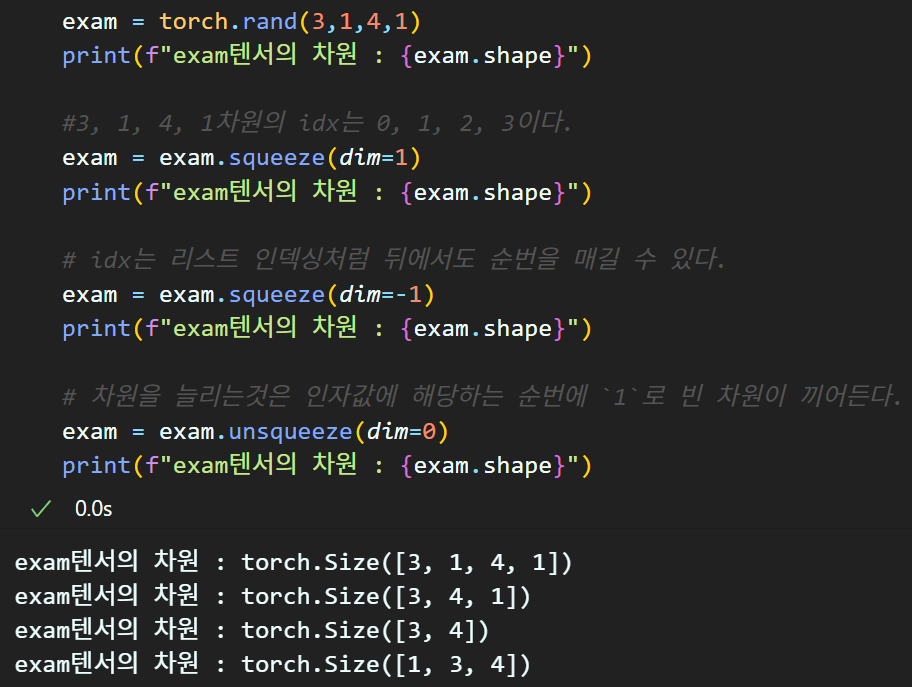
squeeze()메서드는 아무 의미가 없는 1짜리 차원을 없애버린다는 측면에서는 효율성으로 놓고 보면 이해가 가는 메서드 이지만
unsqueeze() 메서드는 왜 빈칸 차원을 추가하냐? 라는 의문이 들 수 있는데
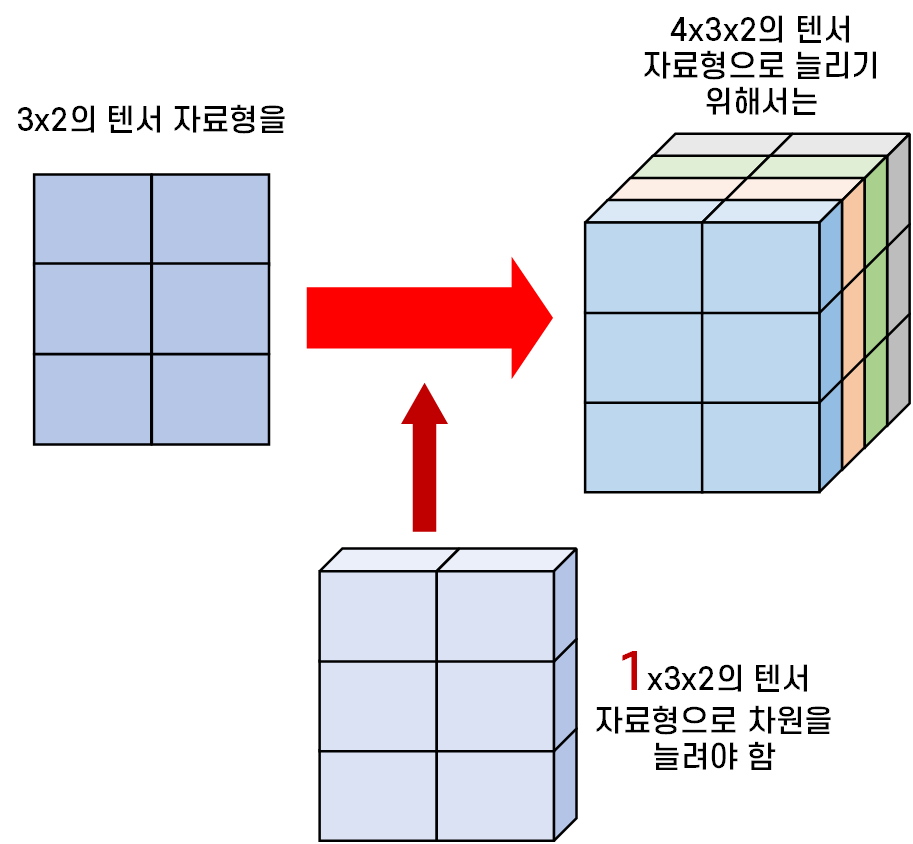
Tensor자료형의 '확장'은 무조건 차원 확장 후 차원값 확장 으로 진행되기 때문이다.
torch.repeat(),torch.expand()
위에서 차원 확장&축소와 관련된 메서드 squeeze() & unsqueeze()를 설명했으니 이제 확장된 차원크기를 조정하는 메서드를 알아보자
# 알아보기 슆게 임의 데이터 하나를 난수(정수 데이터타입)
origin_data = torch.randint(0, 4, (3,2))
# 차원 확장 [3, 2] -> [1, 3, 2]
temp_data = origin_data.unsqueeze(0)# 확장된 차원을 반복하여 늘림 [1, 3, 2] -> [4, 3, 2]
exp_res_data = temp_data.expand(4, 3, 2)
# 차원 사이즈가 어떻게 늘어났는지 확인
print(exp_res_data.shape)
# 원소가 어떻게 늘어났는지 확인하기
print(exp_res_data)# 확장된 차원을 repeat메서드로 늘림
rep_res_data = temp_data.repeat(4, 1, 1)
# 차원 사이즈가 어떻게 늘어났는지 확인
print(rep_res_data.shape)
# 원소가 어떻게 늘어났는지 확인하기
print(rep_res_data)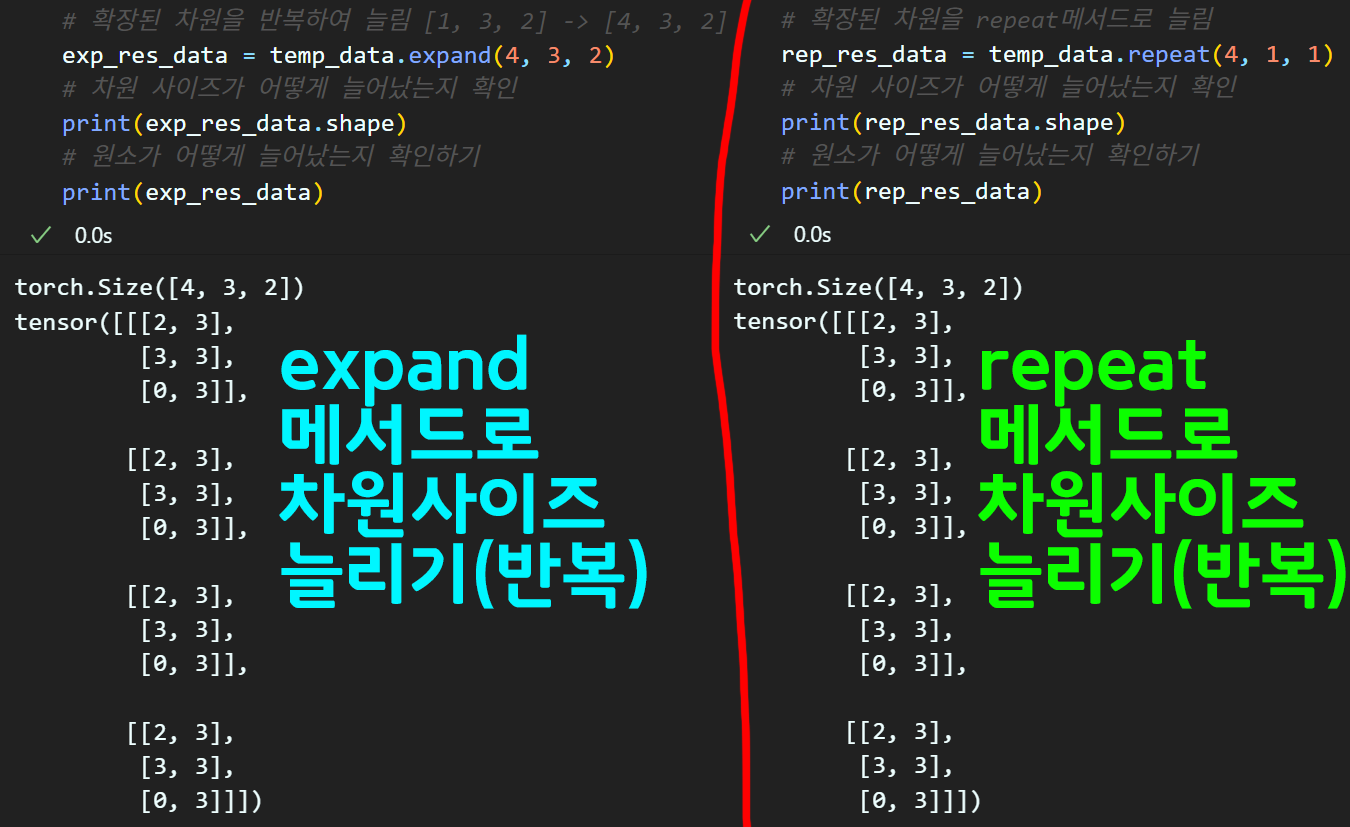
사이즈가 늘어난 과정을 보면 repeat와 expand가 둘다 동일하게 늘어나는것을 확인할 수 있다.
그럼 두 메서드의 차이점은 어떤게 있을까?
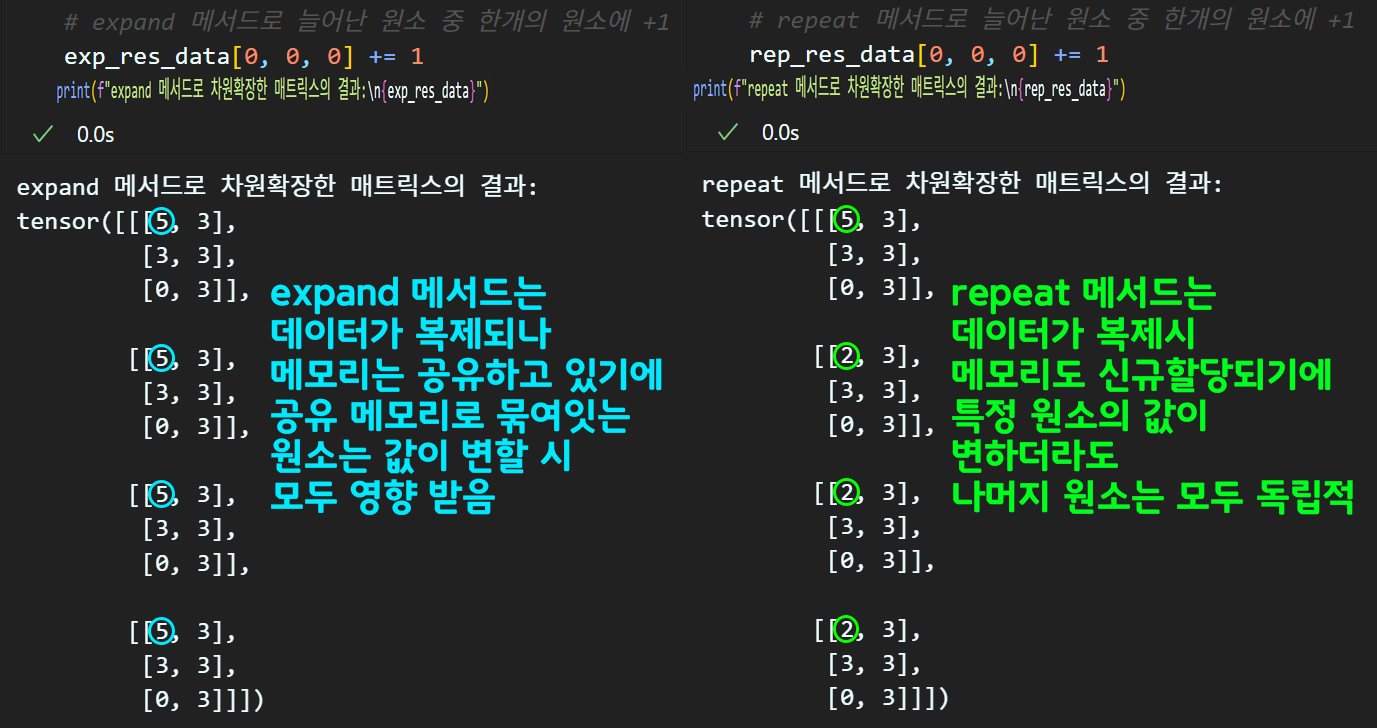
위 사진을 보면 알 수 있듯이 expand는 차원 사이즈가 늘어나도 메모리는 공유되고 있기에
하나의 원소값을 변조하면 공유 메모리로 묶여있는 다른 원소도 같이 영향받는다.
따라서 expand로 차원을 늘리는 경우는 브로드 캐스팅 방식으로 읽기전용 데이터를 만들 때 최적화 측면에서 사용하는 메서드라 보면 된다.
반대로 repeat메서드는 차원사이즈가 늘어나면 복제된 데이터는 완전히 독립적으로 운용되어 원소 변조가 발생하는 쓰기데이터일 때 위 메서드를 사용한다.
torch.view(),torch.reshape()
위 두개의 메서드는 텐서의 차원을 변경할 때 주로 사용하는 메서드 이지만 규칙이 존재한다.
이는 그림으로 표현하겠다.
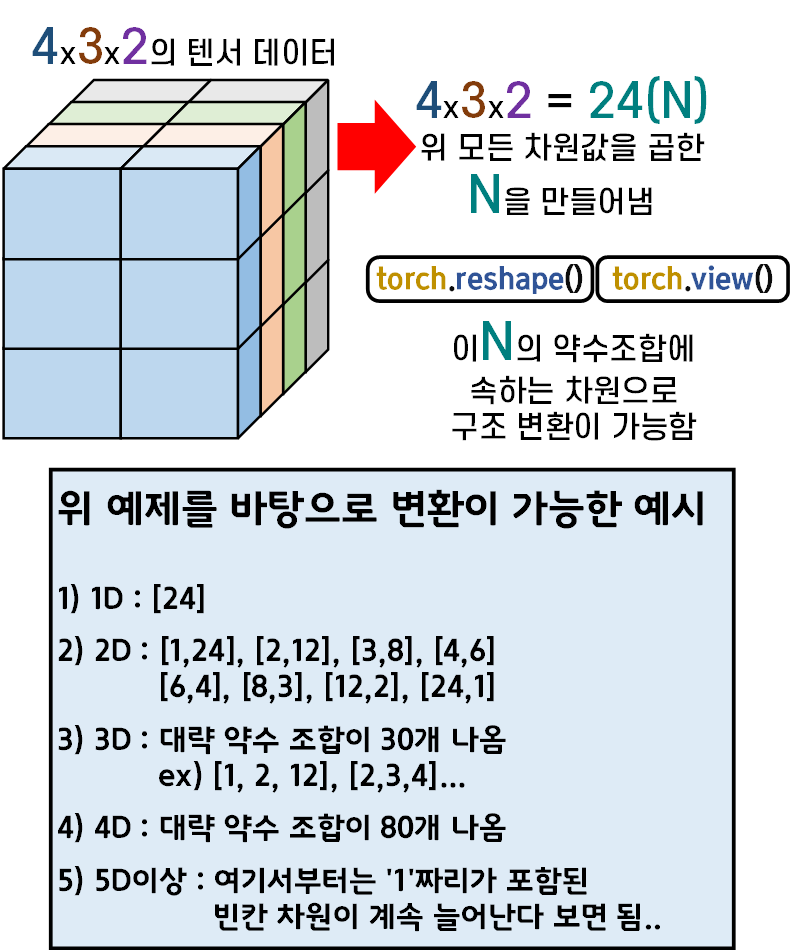
# 실습을 위한 데이터 생성
origin_data = torch.rand(4,3,2)# view 메서드로 차원 구조 변환
view_data = origin_data.view(1,3,8)
# reshape 메서드로 차원 구조 변환
reshap_data = origin_data.reshape(1,3,8)
print(f'view 메서드로 차원변환 결과 : {view_data.shape}')
print(f'reshape 메서드로 차원변환 결과 : {reshap_data.shape}')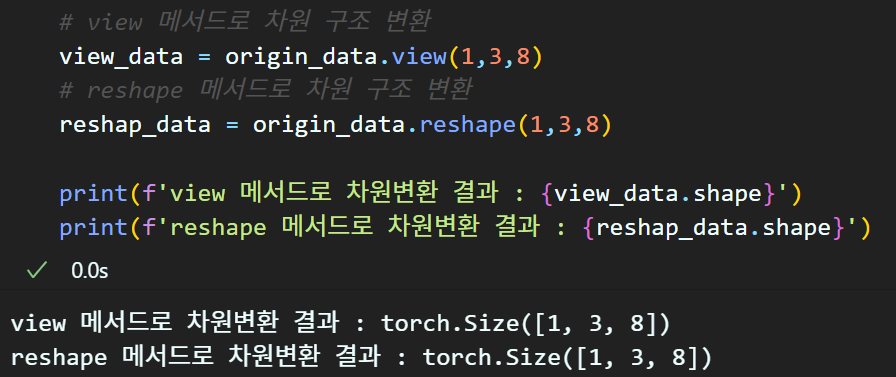
그럼 두 메서드는 같은 기능을 하는거 같은데 왜 다르게 쓸까?
여기서부터는 컴퓨터 구조와 관련된 지식이 필요한데
메모리의 연속성이 보장된 차원 구조 변환 : view
연속성 패싱하고 일단 차원 구조 변환 : reshape
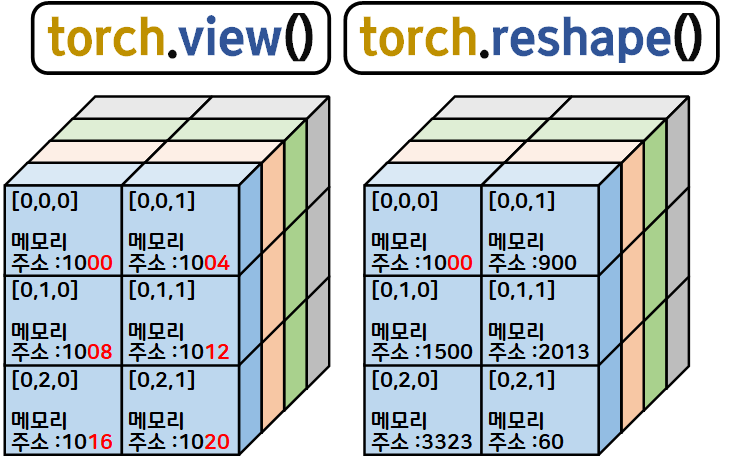
예시를 들어보면 view, reshape차이는 위 사진처럼 볼 수 있다.
이 메모리 연속성이 왜 중요하냐면
GPU연산할 때 메모리 참조가 편리하다 GPU연산 속도가 빠르다
일단 이렇게 이해하면 될 듯하다.
그래서 위 두 메서드의 사용에 대한 이야기를 하자면
1) 구조 변환이 필요한 Tensor데이터는 일단 view 메서드로 변환한다.
2) 변환 후 에러(Runetime에러가 뜸)가 발생하면 reshape를 써본다 이러면 대체로 문제가 해결됨
코드 최적화 측면에서 되도록이면 view을 사용하고
에러가 발생할 때만 reshape을 사용하는걸 권장한다.
torch.transpose(),torch.permute()
두 메서드 모두 Tensor데이터가 다차원(2차원 이상)으로 되어 있을 시 차원의 축 순서를 변환하는 메서드이지만 조금 차이가 있다.
우선torch.transpose()는 전치행렬을 만드는 과정이랑 같은데 기능이 좀 더 확장된 항목이다.
# 알아보기 슆게 임의 데이터 하나를 난수(정수 데이터타입)
exam_data = torch.randint(0, 9, (3,2))
print(exam_data)T_matrix = exam_data.transpose(0, 1)
print(f"전치행렬 T_matrix 차원 : {T_matrix.shape}")
print(f"T_matrix:\n {T_matrix}")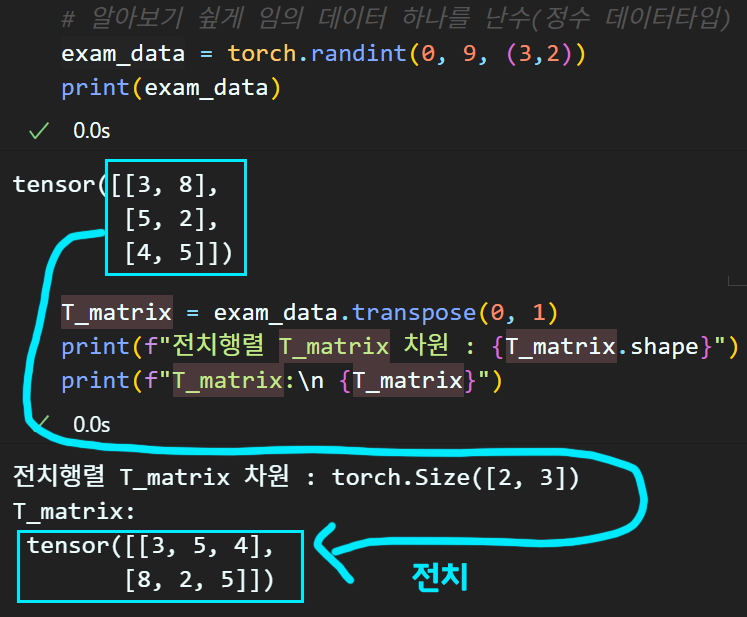
여기까지 설명하면 torch.transpose()는 전치행렬만의 기능을 하는것으로 보이나 이 차원 내 축 순서 바꿈을 3차원 이상 환경에서도 진행할 수 있다.

그러면 torch.permute()는 무엇이냐? 이건 차원 순서로 야바위 하는 것이다.

짤을 보면 알겠지만 두개 차원의 위치를 이동하는 torch.transpose()보다 torch.permute()는 더 상위호환의 기능을 하는 것을 알 수 있다.
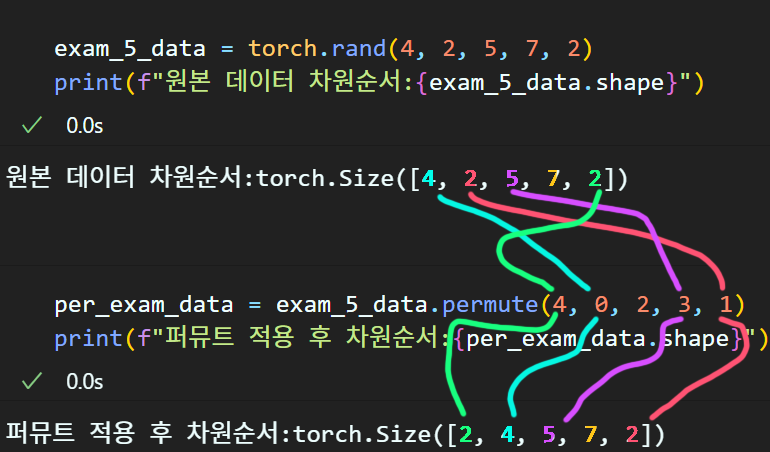
위 사진을 보면 대략 차원 축 순서를 아주 유연하게 섞는게 가능함을 알 수 있을 것이다
torch.topk()
이제 여기서부터 슬슬 난이도가 높아지는 메서드를 설명할텐데
입력되는 데이터의 축(axis)을 기반으로 상위 k개의 값과 해당 값(val)이 어느 위치에 있는지에 대한 idx 두가지를 반환하는 메서드이다.
일단 쉽게 1차원 데이터먼저 동작을 어떻게 하는지 확인해보자
x_data = torch.randint(low=0, high=10, size=(6,))
print(x_data)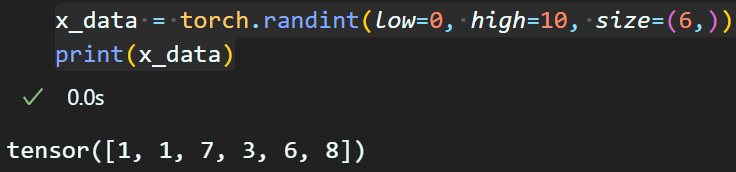
위 사진처럼 1차원 데이터를 임의의 난수(정수형데이터)로 선언을 한 뒤 아래의 코드로 상위 K의 정보를 추출해보자
K = 3
val, idx = torch.topk(x_data, K)
print(f"상위 {K}개의 값 : {val}")
print(f"상위 {K}개의 주소값 : {idx}")
여기까지는 이해하는데 어려움이 없을 것이다.
이제 2차원 이상의 데이터에 대한 내용이다.
x_data = torch.randint(low=0, high=10, size=(6,4))
print(x_data)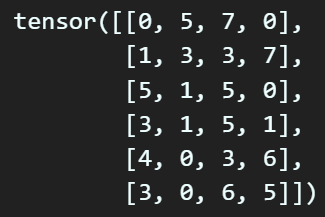
여기서 torch.topk()옵션을 위 데이터 기준으로 2차원
(axis=0, axis=1)으로 상위 K개의 데이터를 추출한다.
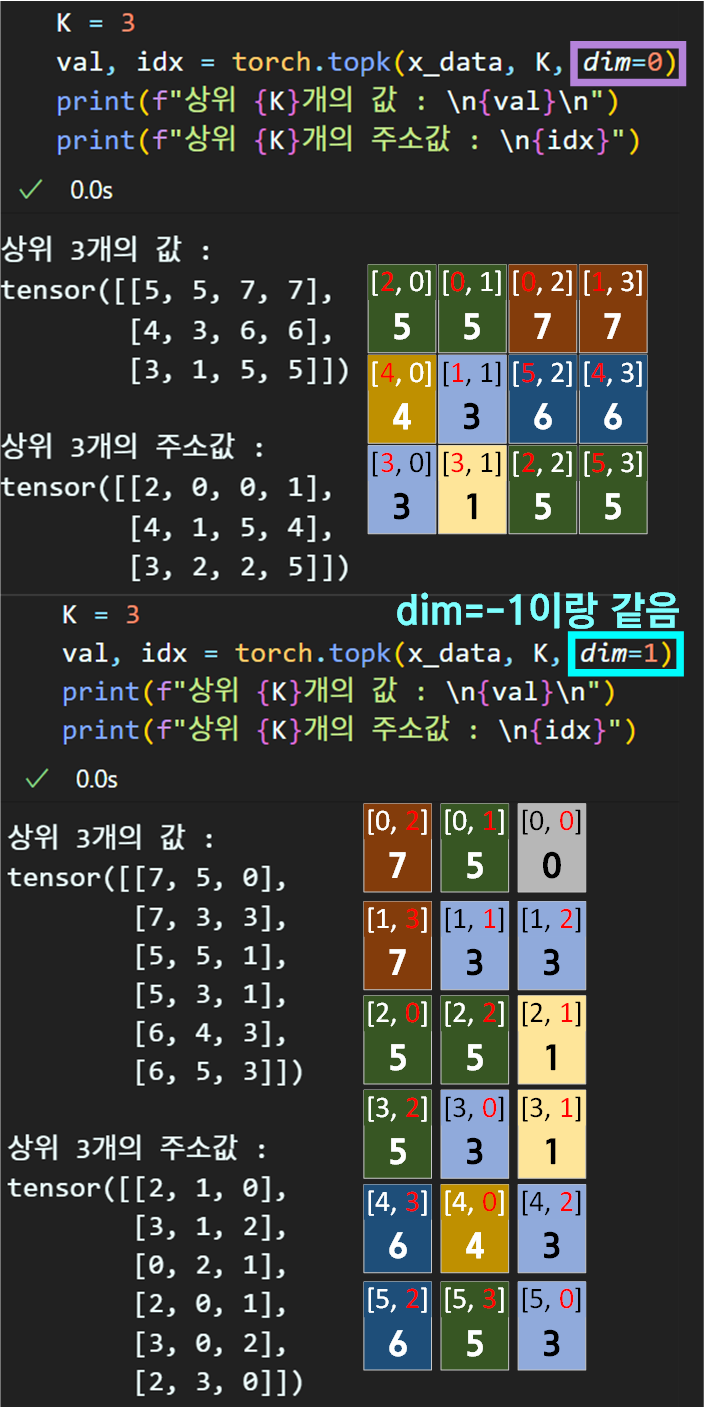
대략 각 축별로 어떻게 상위 몇개? 의 데이터를 추출하는지 감이 왔으리라 생각한다.
torch.gather()
이 메서드는 텐서 데이터의 특정 값들을 idx기반으로 추출할 때 유용한 메서드이지만
사용법이 상당히 이해가 안가는 메서드이기도 하다.
1차원부터 차근차근 이해해 나가도록 하자
먼저 해당 함수의 인자값을 이해해야 한다.

인자값에 대한 설명은 위 사진을 참조하여 아래의 코드를 동작시키면 대충 갑 추출이 어떻게 진행될 지 이해가 될 것이다.
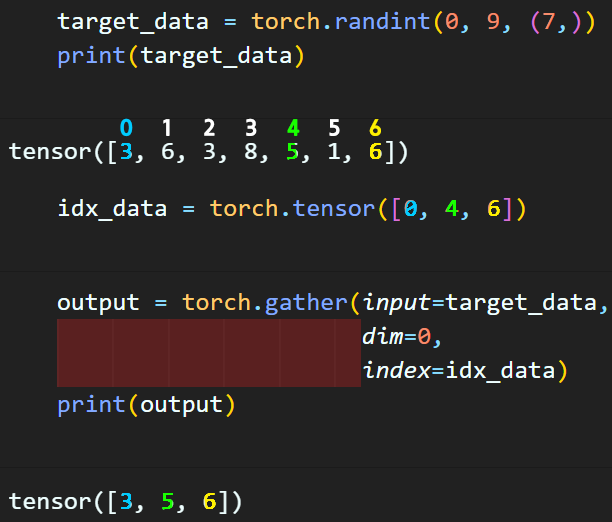
여기서 중요한게 있다. 인덱스는 원본 텐서보다 차원 가지수가 크지만 않으면 사이즈에 무관하게 중복 추출이 가능하다는 것이다.
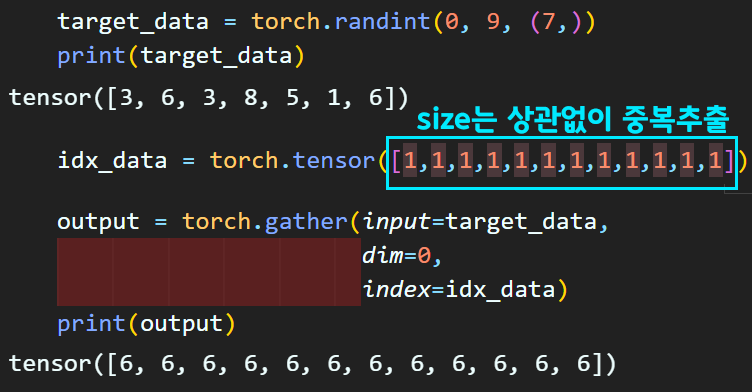
이 중복 추출이 가능하다 라는걸 꼭 기억해야 한다.
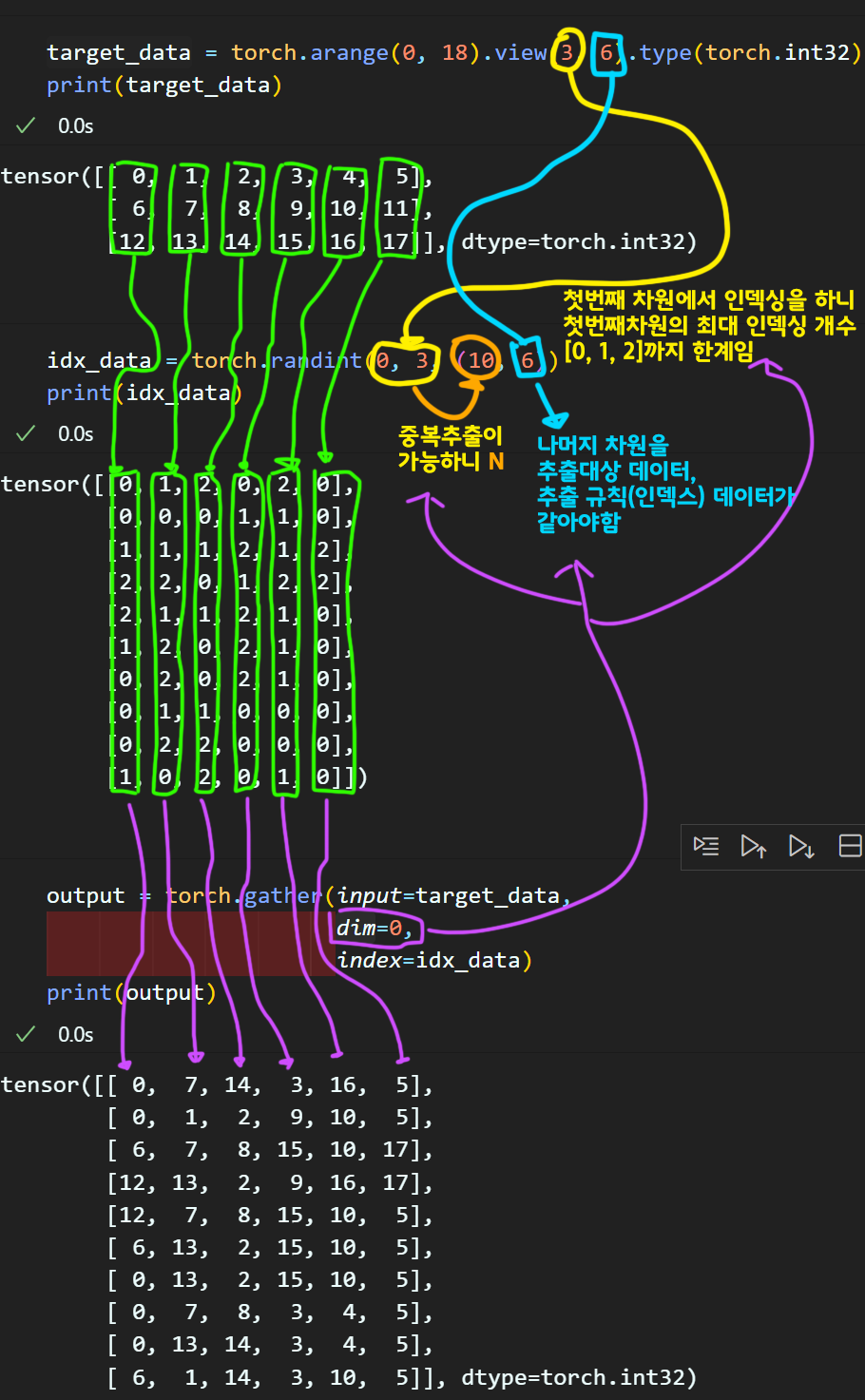
dim=0 : 1번 차원의 경우
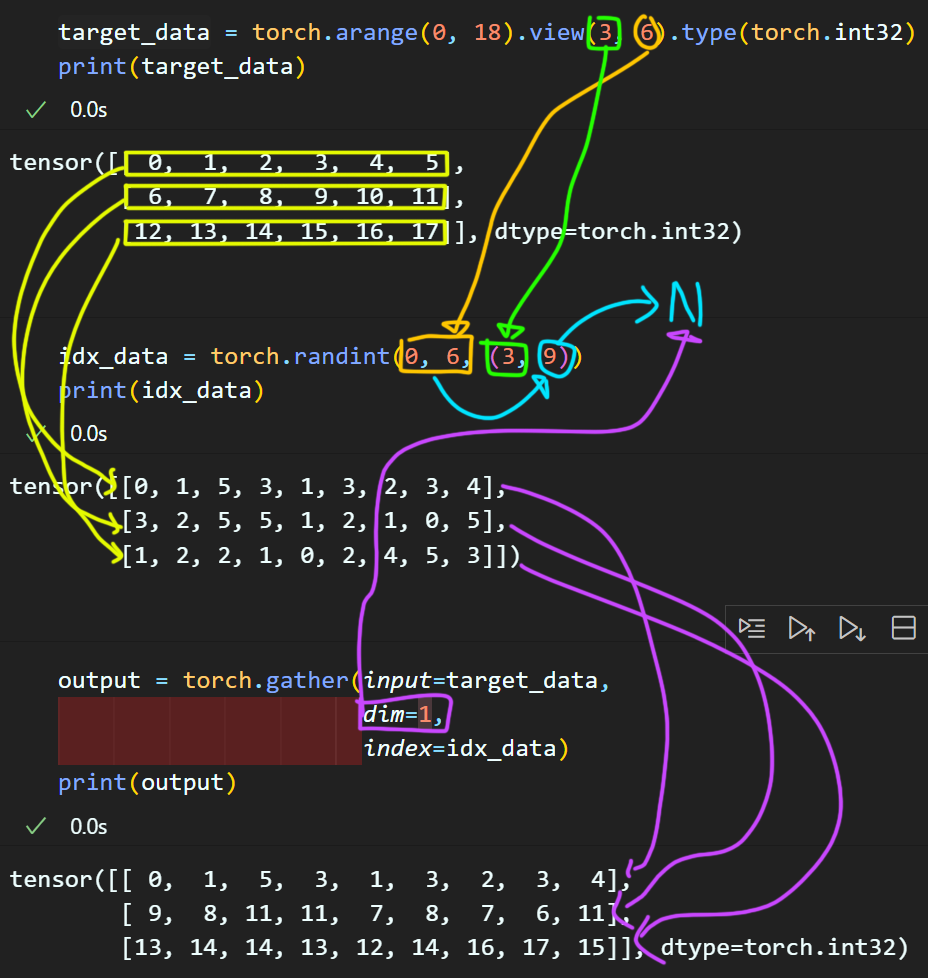
위 규칙을 이해했으니 dim=1인 경우도 올바르게 torch.gather()를 적용할 수 있을 것이다.
이렇게 다차원 텐서 데이터에서 특정 값의 idx를 매트릭스 단위로 다양한 조건으로 데이터추적을 수행하고자 할 때 torch.gather()를 사용한다 볼 수 있다.
torch.where()
이 메서드는 흔히 삼항연산자
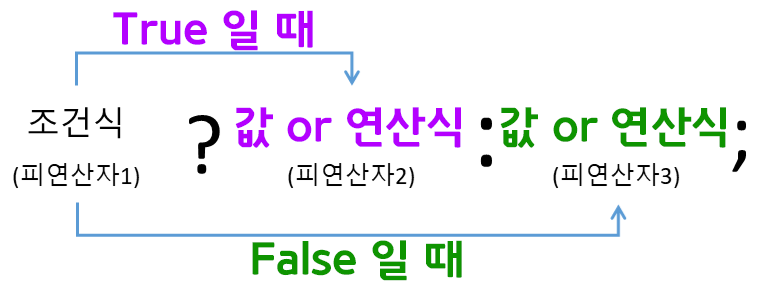
위와 같은 연산을 Tensor Matrix버전으로 수행하는 메서드라 보면 된다.
이때 중요한 점은 torch.where()에 사용가능한 조건식은 Boolean타입의 데이터
그러니까 True / False 데이터만 가능하다
이를 실전예제로 확인해보자
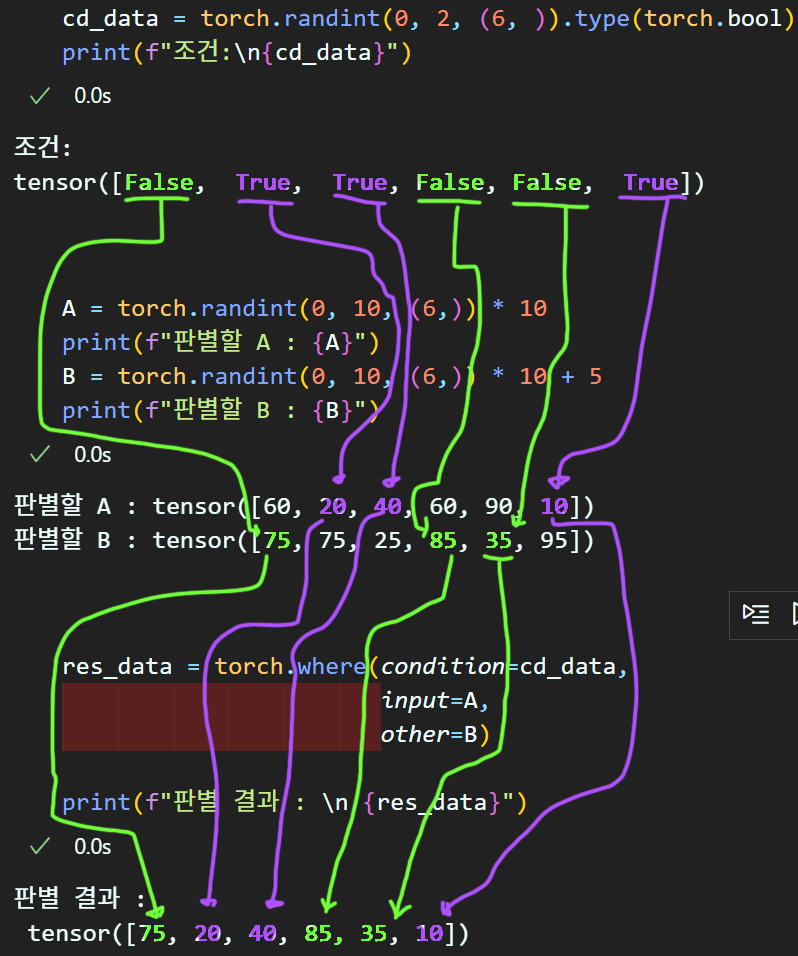
cd_data = torch.randint(0, 2, (6, )).type(torch.bool)
print(f"조건:\n{cd_data}")
A = torch.randint(0, 10, (6,)) * 10
print(f"판별할 A : {A}")
B = torch.randint(0, 10, (6,)) * 10 + 5
print(f"판별할 B : {B}")
res_data = torch.where(condition=cd_data,
input=A,
other=B)
print(f"판별 결과 : \n {res_data}")
우선은 이 정도로 다양한 tensor 메서드의 사용방법에 대해 정리를 진행한다.

안녕하세요. 수강하신 ICT이노베이션 수업 들으려고 고민중인데 혹시 도움이 많이 되셨나요? 도움이 되셨다면 추천할 만한 강좌가 있을까요? 관련 코드도 거기서 따로 제공해주시나요?