
개요
https://velog.io/@tbvjvsladla/series/%EC%98%A8%EB%94%94%EB%B0%94%EC%9D%B4%EC%8A%A4LLM
필자가 온디바이스 기반의 RAG시스템을 개발하면서 정리가 되지 않았던 내용을 다시 복기 후 좀 더 전달력있게 재 포스팅을 하고자 본 시리즈를 작성합니다.
1. 임베딩 모델이란?
RAG 프레임워크를 기초로 하여 AI Agent을 설계하다 보면 LLM, Retriver에서 주요하게 사용되는 임베딩 모델이
1) 어떤 정보와 기능을 담당하는지?
2) 임베딩 모델의 생성 및 배포 단계는 어떻게 되는지?
가 좀 혼동되는 경우가 있다.
이를 정리하면 아래의 그림으로 표현할 수 있는데 각 항목별로 설명을 진행하겠다.
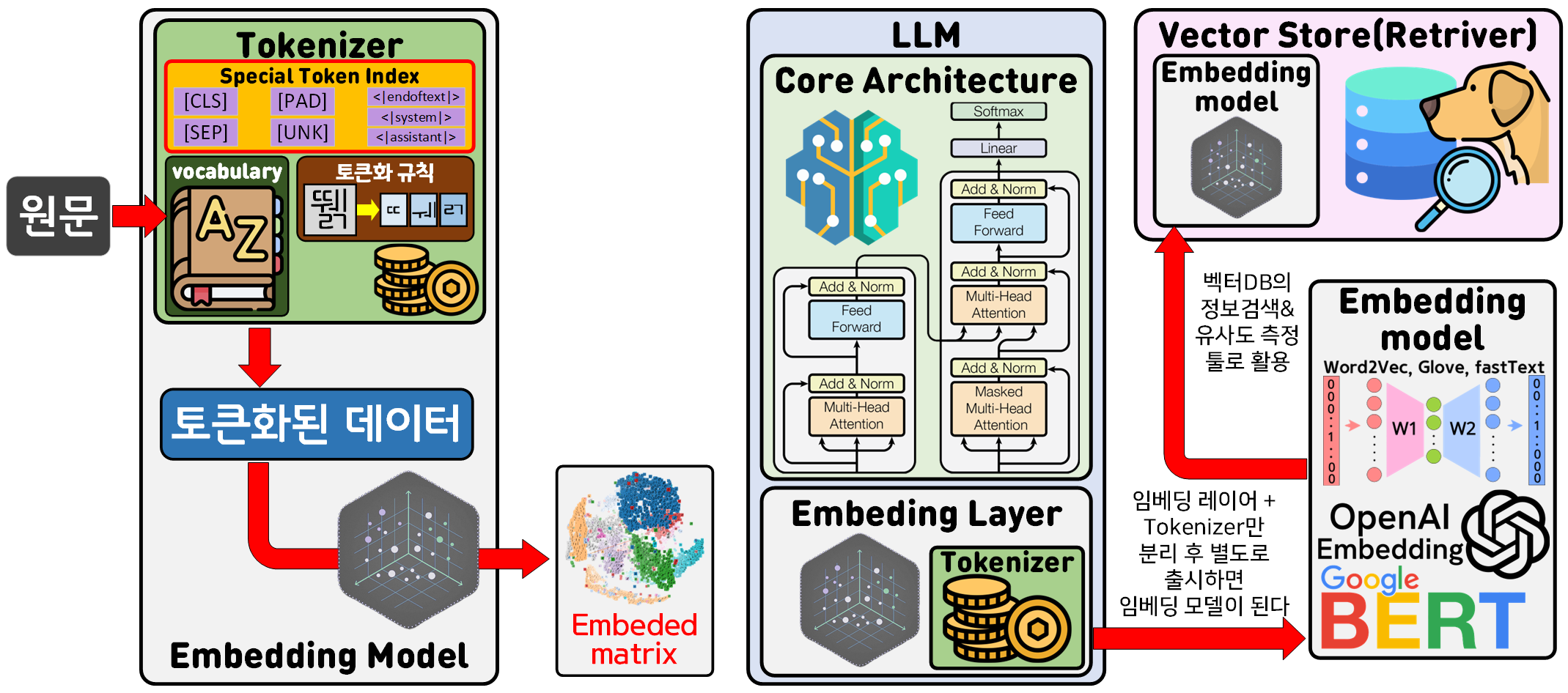
1) 배포되는 임베딩 모델의 구조 및 기능
처음 NLP를 배울때는 Embedding Model은 NLP를 수행하는 Model의 맨 앞단 Stem Layer에 붙던 것을 Model이 학습이 완료된 뒤에 앞단 레이어만 똑 떼어내서 사용하면 그게 Embedding Model이다
이렇게 배웠는데
현재 허깅페이스에서 배포되는 Embedding Model는 사전학습된 Stem Layer만 포함한 것이 아니고 Tockenizer도 함께 포함하여 배포되고 있다.
이 Tockenizer는 엄밀하게 말한다면 텍스트 전처리 방법론에 관한 기능을 수행하는 것이기에 Model과는 연관성이 없는 부분이나, NLP를 공부해본 사람이라면 모두가 알 수 있듯이 전처리 부분을 따로 분리하기가 좀 어려운 점이 있다.
이는 CV쪽 전처리 과정과 비교하면 좀 명확하게 이해할 수 있는데
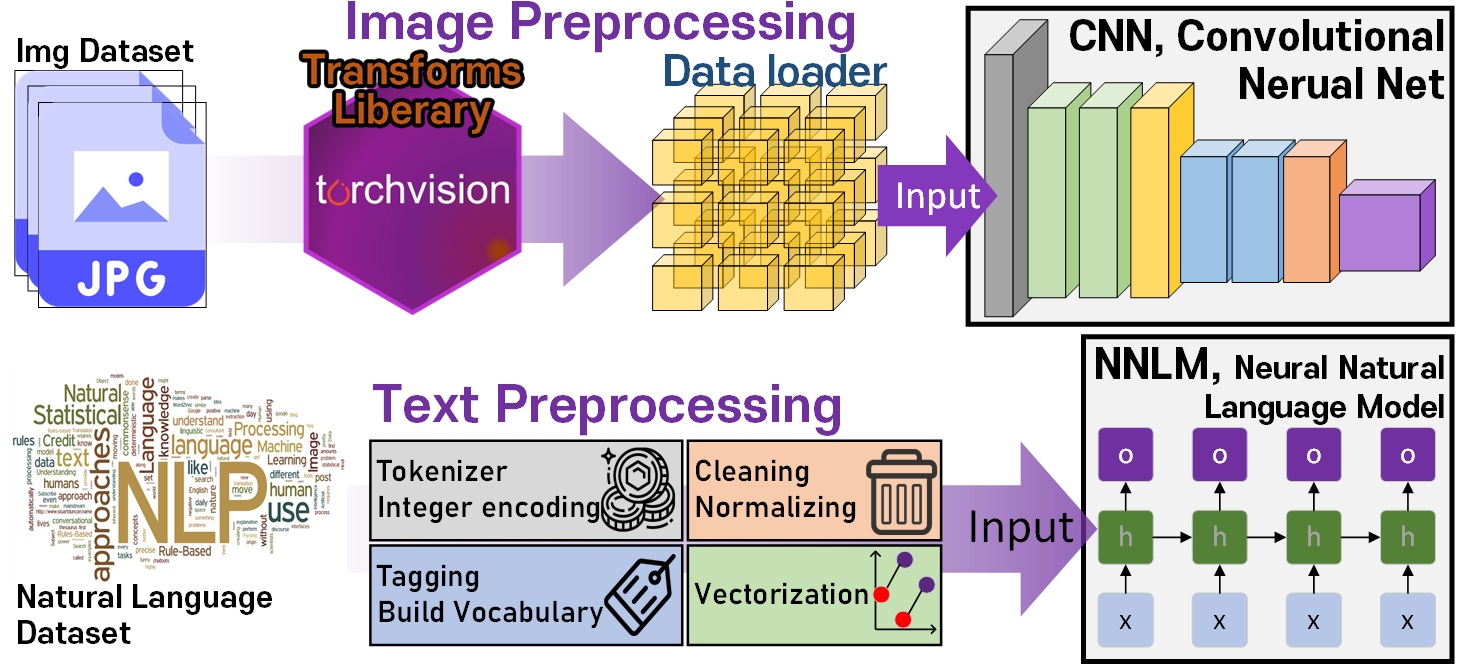
CV에서 다루는 데이터인 이미지 데이터는 대체로 jpg, png등의 이미지 데이터 포맷으로 정해진 정보를 받으며, 이들은 데이터 규칙이 명확하기에 첨부한 이미지처럼 Tensor 데이터 포맷으로 변환하는 컨버팅 과정이 통일되어있다.
그러니까 torchvision에서 제공하는 Transforms 라이브러리만 쓰면 어떤 이미지 데이터 간에 모두 모델에 입력 가능한 Tensor data로 포멧변환이 가능하지만
NLP는 입력되는 자연어 데이터셋(Natural Language Dataset)이 언어마다 어떻게 규격화를 하고 Tensor data포멧으로 변환해야 하는지 과정이 다 다르고 커스터마이징의 자유도가 높은 편이다.
그러다 보니 어떻게 전처리를 하는지에 대한 규칙을 사전에 정의해야 하며, Embedding Model에는 이 Tensor data변환 규칙이 내장되어 있다.
이렇게 보면 될 것 같다.
이정도 개념설명을 했으니 실전으로 허깅페이스에서 배포되는 Embedding Model을 다운로드 받고 그 구조를 확인해 보자
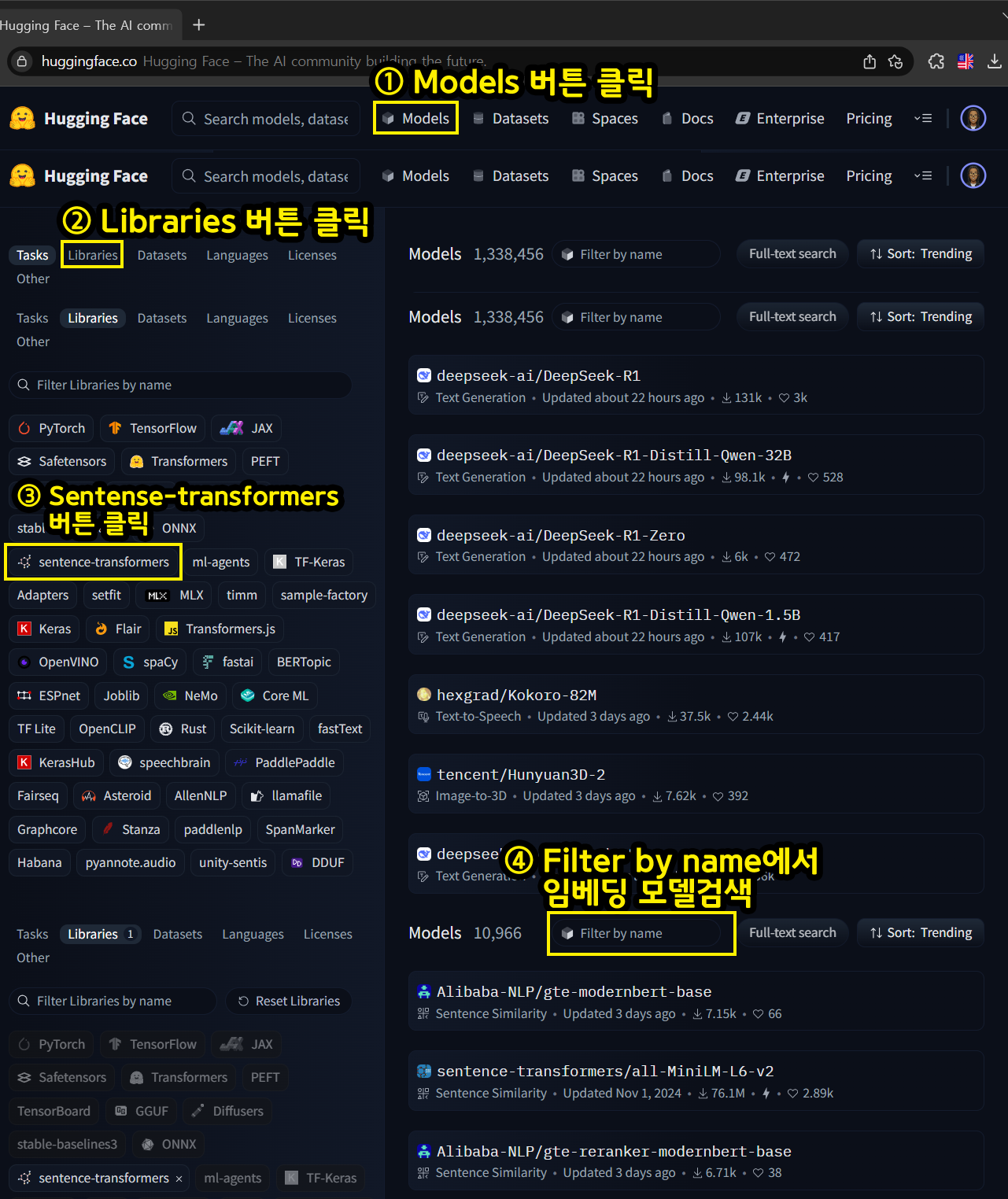
우선 허깅페이스에서 Embedding Model를 다운로드 받는 방법은 위 사진처럼
Models -> Libraries -> Sentense-transformes 까지 차례로 버튼을 클릭한 뒤 'Filter by name'에서 다운로드 받고자 하는 임베딩 모델을 검색하면 된다.
여기서 임의의 모델을 다운로드 받은 뒤, tockenizer 정보를 확인하면 아래와 같다.
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-mpnet-base-v2")
print(tokenizer)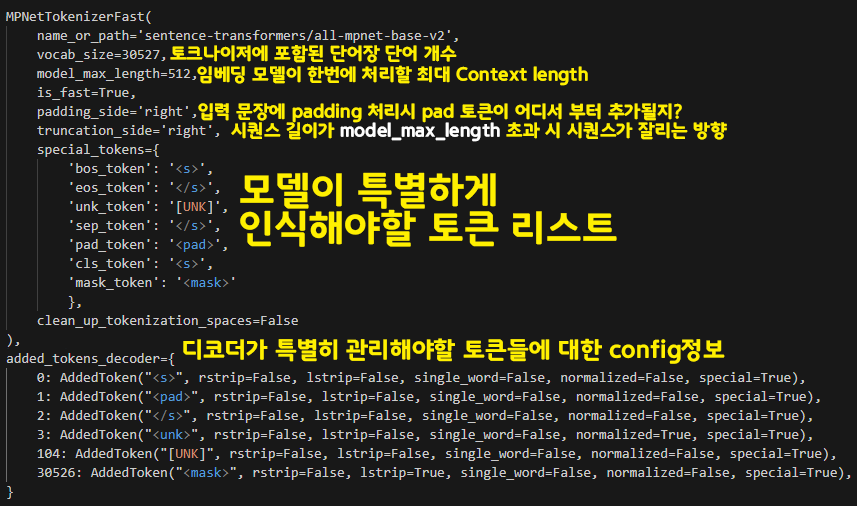
내용을 살펴본다면
단어장항목, 전처리시 Pad토큰은 어디에 붙는지?, 토크나이저가 특별하게 기억하고 있어야할 Special token정보, 디코더가 단어 생성할 때 특별하게 알고 있어야할 토큰 정보등이 출력되고
model_max_length는 Embedding Model이 1개의 batch에 대해 동시에 최대로 처리 가능한 seq_len정보가 된다.
음.. 그러니까 임베딩 모델의 config정보 요약이라 볼 수 있다.
이 config정보를 가지고 임베딩 모델에 원문을 입력하여 인코딩을 수행하면 Embedded Matrix를 출력하게 된다.
2) 임베딩 모델의 생성 및 배포 단계
위 Embedding model는 어떻게 만들어 지는가에 대한 내용은
LLM을 설계하고 학습 할 때 맨 앞에 있는 stem layer이 무조건 Embedding layer이니 이 부분만 학습이 완료된 후 별도로 분리하여 출시하면 된다.
물론 임베딩 모델을 좀 특화시키거나 변형시키고자 한다면
Tokenizer의 config정보를 조정하거나
모델 전체를 fine turning한 후 동일하게 Embedding layer를 떼어내서 다시 허깅페이스와 같은 LLM Deploy & Manage Platform에 등록하여 배포를 진행하면 된다.
이렇게 배포되는 Embedding model는 몇가지 계보같은게 있는데
MPnet, Bert는 초기형 Transforemr LLM에서 떼어낸 Embedding model이라 보면 되고
Word2Vec, Glove, fastText는 살짝 고전에 속하는 Embedding model
요즘은 llama계열의 LLM이 배포되다 보니 llama계열의 Embedding model을 다른 LLM들도 LLama embedding model을 주로 쓰는게 추세인 듯 하다.
그리고 RAG(Retrival Augmented Generation) 시스템을 구축할 때 Retriver에서도 Embedding model을 필요로 한다.
RetriverEmbedding model은
1) Curated raw data를 모두 embedded matrix로 변환하는 과정을 수행
2) 사용자가 Query(질문)을 입력하면 RAG 과정 중에서 데이터 검색을 위한 keyword가 만들어 질 때 이 keyword를 embedded matrix로 변환하는 과정을 수행
위 두가지 과정을 수행해서
Vector Store는 효율적으로 여러 포맷의 데이터를 압축하고,
빠르고 쉽게 Query(질문)에 좋은 답변을 내기 위한 주변정보 : Context를 색인한다.
2.임베딩 모델과 RAG
이제 본격적으로 포스팅하고자 하는 RAG(Retrival Augmented Generation) 시스템을 구축할 때 주의해야할 Embedding model의 사용방법이다.
실습 예제는 https://wikidocs.net/265456 에 업로드 되어 있는

PDF문서기반 QA RAG 실습코드를 바탕으로 포스트를 진행하고자 한다.
2.1 포스트 내용을 그대로 따라하기
첫번째로 실습할 내용은 포스트 내용을 거의 그대로 따라하는 코드이다
# openai의 LLM 및 임베딩 모델을 사용하기 -> API키가 필요하니 이 부분을 로드하는 부분
import os
from dotenv import load_dotenv
load_dotenv()
openai_api_key = os.getenv("OPENAI_API_KEY")# 1번 단계 : 문서 로딩 후 청킹(split)하는 부분 -> Augmented 준비단계
from langchain_community.document_loaders import PyMuPDFLoader
pdf_dir = "data"
# 모든 PDF 파일 로드
docu = []
for pdf_file in os.listdir(pdf_dir):
if pdf_file.endswith(".pdf"): # .pdf 파일만 처리
loader = PyMuPDFLoader(os.path.join(pdf_dir, pdf_file))
# loader은 PDF를 1장 단위로 문서화 시킴
docu.extend(loader.load())
print(f"총 {len(docu)}개의 문서를 로드했습니다.")from langchain_text_splitters.character import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 각 청크의 최대 문자(character) 수
chunk_overlap=50 # 청크 간에 앞 뒤로 중복할 최대 문자 수
) # 청크에 오버랩이 있어야 문맥이 공유되서 모델이 더 정확한 답을 생성함
split_documents = text_splitter.split_documents(docu)
print(len(split_documents))# 2번 단계 : openai 임베딩 모델 불러오기
# 여기서 실습을 위헤 임베딩 모델은 2종류(small, large)를 불러옴
from langchain_openai.embeddings.base import OpenAIEmbeddings
# 임베딩 모델 객체화 - small 모델
# openai처럼 클라우드 모델은 api_key가 필요함
OAis_embeddings = OpenAIEmbeddings(
model="text-embedding-3-small",
api_key=openai_api_key
)
# 임베딩 모델 객체화 - large 모델
# openai처럼 클라우드 모델은 api_key가 필요함
OAil_embeddings = OpenAIEmbeddings(
model="text-embedding-3-large",
api_key=openai_api_key
)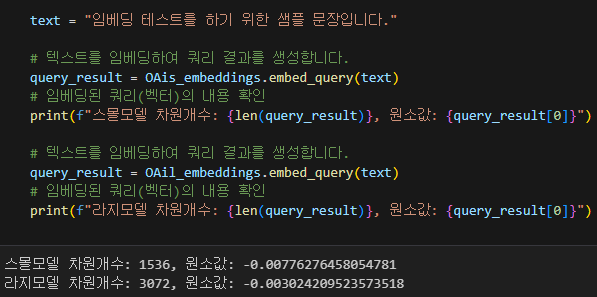
openai의 임베딩 모델 버전별 간단 성능 확인
# 3번 단계 : 버전별 임베딩 모델로 2종의 Retriver을 생성
# Vector Store는 Langchain의 기본 VS를 사용
from langchain_core.vectorstores import InMemoryVectorStore
# LangChain에서 제공하는 기본 Vector Store를 활용
Ins_vector_store = InMemoryVectorStore(
embedding=OAis_embeddings
)
# 객체화한 벡터스토어에 청킹처리된 도큐먼트를 모두 입력
Ins_vector_store.add_documents(split_documents)
Ins_retriever = Ins_vector_store.as_retriever()
Inl_vector_store = InMemoryVectorStore(
embedding=OAil_embeddings
)
# 객체화한 벡터스토어에 청킹처리된 도큐먼트를 모두 입력
Inl_vector_store.add_documents(split_documents)
Inl_retriever = Inl_vector_store.as_retriever()# 4번 단계 : 프롬포트, LLM(Openai)의 정의 및 선언
# 프롬포트는 사전에 정의한 template를 불러오는 방식으로 선언
from langchain_core.prompts import load_prompt
from langchain_core.output_parsers.string import StrOutputParser
# 프롬포트와 아웃풋 파서 객체화
template = "template/kor_PDFRAG_answer.yaml"
prompt = load_prompt(template, encoding="UTF-8")
output_parser = StrOutputParser()from langchain_openai import ChatOpenAI
# LLM모델 객체화
llm = ChatOpenAI(
model_name="gpt-4o",
api_key=openai_api_key,
temperature=0
)# 5번 단계 : Retriver 버전별로 두 종류의 Agent(chain)을 선언
from langchain_core.runnables import RunnablePassthrough
# Langchain의 코드 개발규칙에 따라 객체화한 4개 모듈을 Chain으로 묶음
# -> Agent생성
Agent_small = (
{"context": Ins_retriever, "question": RunnablePassthrough()}
| prompt
| llm
| output_parser
)
Agent_large = (
{"context": Inl_retriever, "question": RunnablePassthrough()}
| prompt
| llm
| output_parser
)query = "AI 에이전트에 대해 설명해줘"
response = Agent_small.invoke(query)
print(f"리트리버:스몰모델\n {response}")
print()
response = Agent_large.invoke(query)
print(f"리트리버:라지모델\n {response}")
위 실습의 내용을 요약한다면 아래의 그림으로 표현할 수 있다.
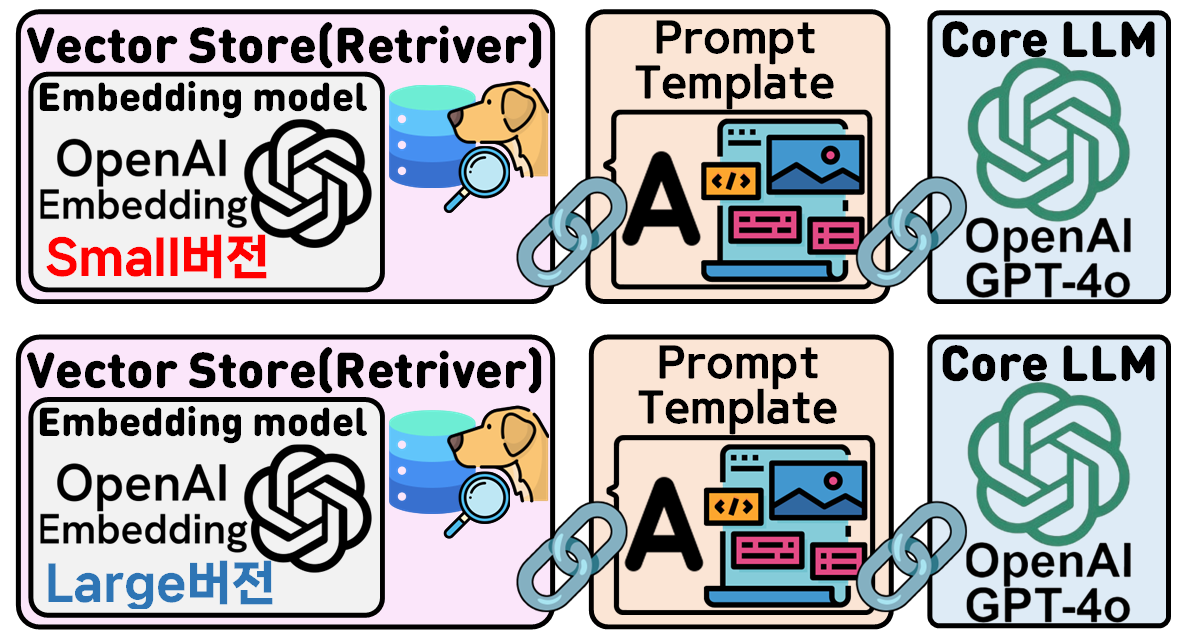
사진처럼 2개 버전의 Agent를 설계하고 차이점이라면
임베딩 모델을 같은 Openai에서 만든 임베딩 모델을 사용하나
그 파생 모델이 살짝 다른걸 쓰는 실습이다.
Small버전의 임베딩 모델은 차원 개수가 1536이고
Large버전의 임베딩 모델은 차원 개수가 3072인 차이인데
여기서 발생한 차이점이 최종적으로 RAG성능에 어떤 영향을 끼치는가?
이걸 확인하는 실습이라 보면 된다.
물론 결과물을 확인하면 알 수 있듯이 Large버전 임베딩 모델은 생성하는 Context가 좀 더 풍부한 Feature를 담고 있으니 RAG의 답변이 살짝 더 많은 정보를 담고 있음을 확인할 수 있다.
결론만 본다면 Retriver에 사용되는 Embedding model는 전체 RAG 시스템에는 그렇게 큰 영향을 끼치는 것은 아닌것으로 볼 수 있다.
2.2 Retriver의 임베딩 모델을 다른계열로
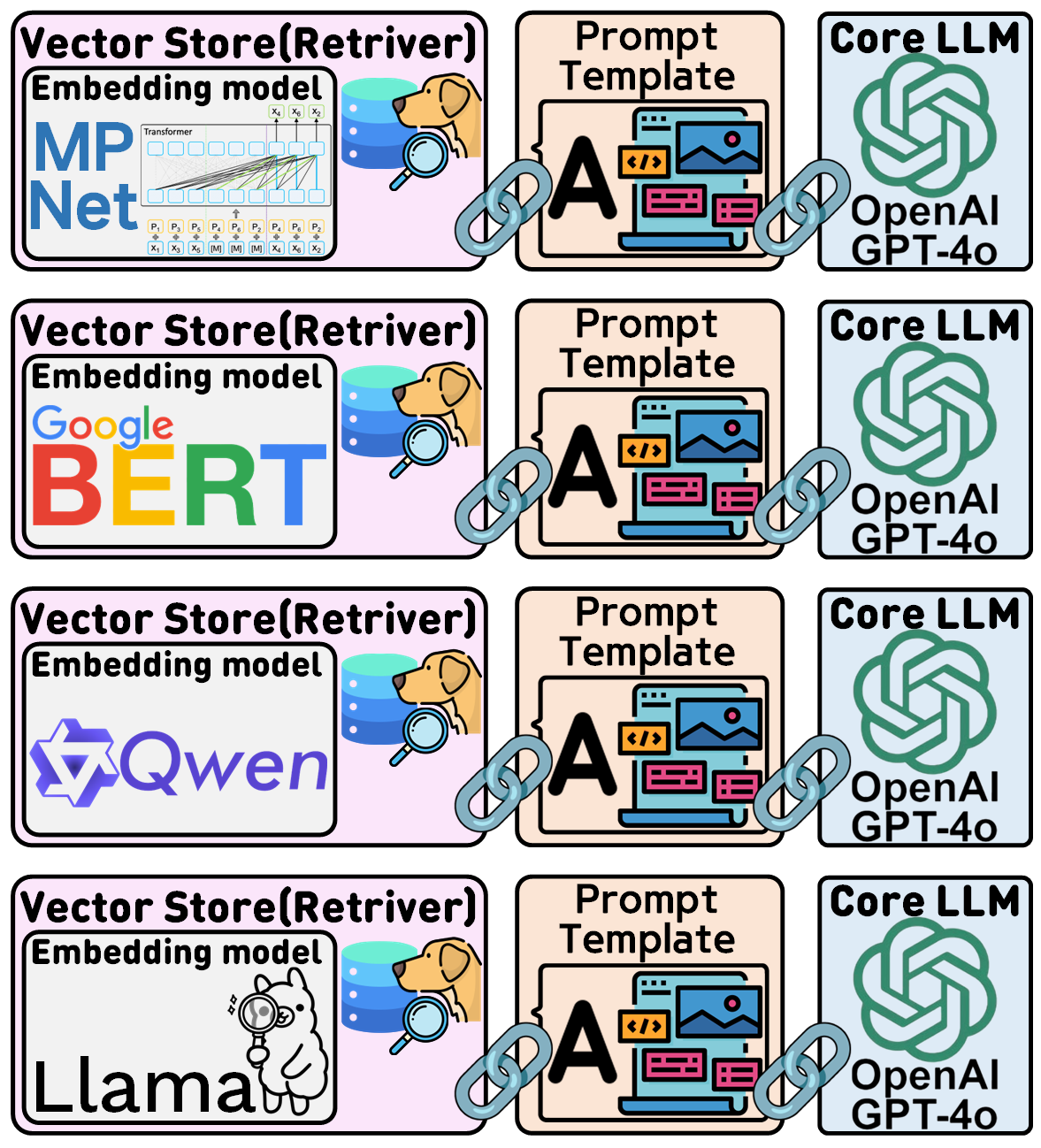
다음으로 해볼 실험은 위 사진처럼 Retriver에서 임베딩 모델을 OpenAI의 임베딩 모델이 아닌 다른 계열의 모델을 사용해보는 것이다.
MPNet, Bert, Qwen, Llama계열에서 배포하는 각각의 임베딩 모델을 선정한 후 이를 사용해 보도록 하겠다.
각 모델은
sentence-transformers/all-mpnet-base-v2
sentence-transformers/xlm-r-100langs-bert-base-nli-stsb-mean-tokens
Alibaba-NLP/gte-Qwen2-1.5B-instruct
<jonaschris2103/tiny_llama_embedder
총 4종의 임베딩 모델을 선정했다.
각 모델의 정보를 확인한다면 아래와 같다.
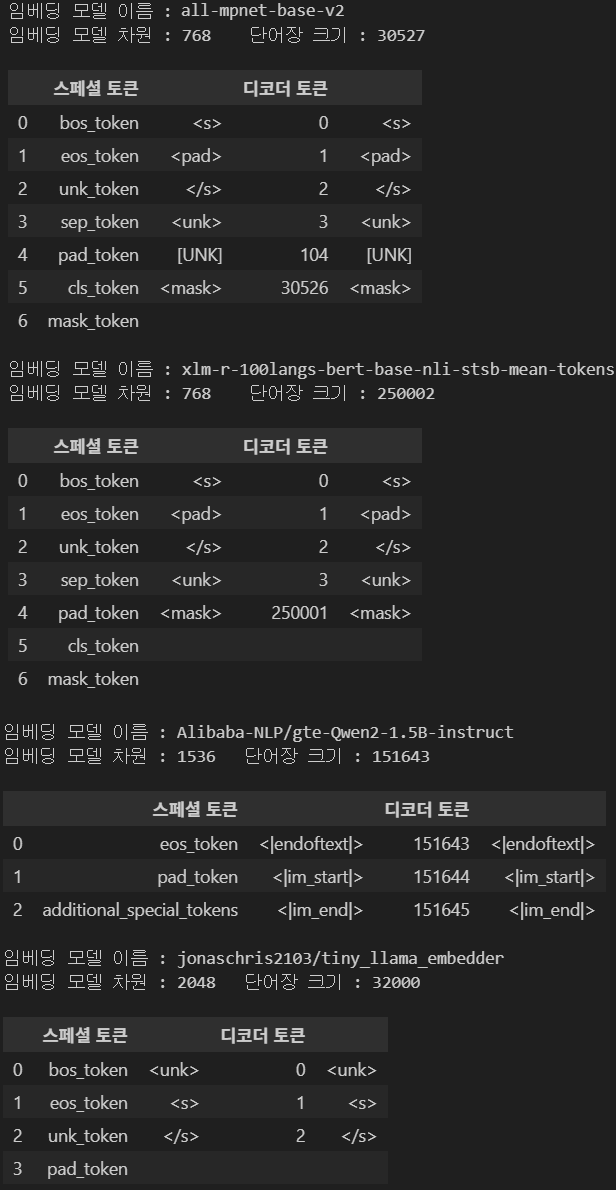
위 임베딩 모델의 정보를 확인했으니
각각의 Embedding model를 Retriver에 포함 ->
버전별 Retriver가 포함된 Agent를 설계한 뒤 답변을 받아보면 아래의 그림처럼 정보를 얻을 수 있다.

출력 정보를 본다면 OpenAI에서 제공하는 LLM : gpt-4o를 사용했을 때에는 Embedding model이 Bert나 MPNet 계열일 시에는 제대로 동작을 하지 않지만,
Qwen, Llama계열의 임베딩 모델은 호환이 되는 것을 확인할 수 있다.
2.3 LLM도 바꿔보기
첨부한 이미지처럼 LLM을 gpt-4o만 사용하지 말고 Local PC에서도 설치가 가능한 LLM : Llama 3.1:8B, Phi-4:14B, deepseek-R1:8B으로도 동일한 작업을 진행해 보기로 한다.
LLM :
Llama 3.1:8B


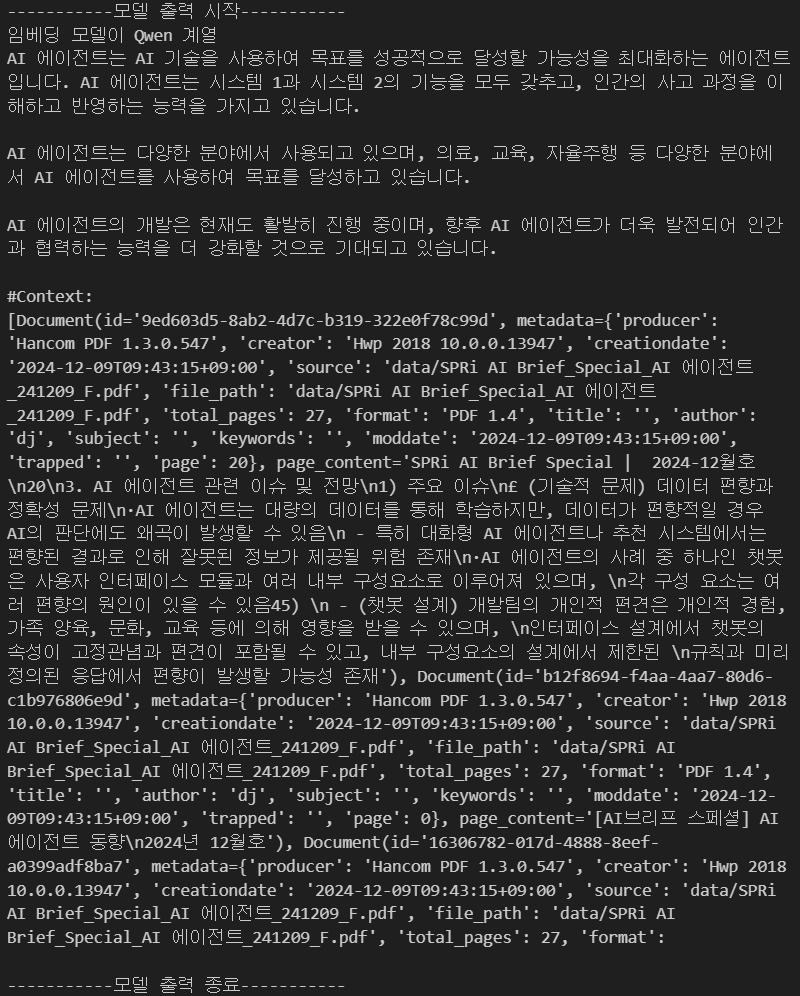
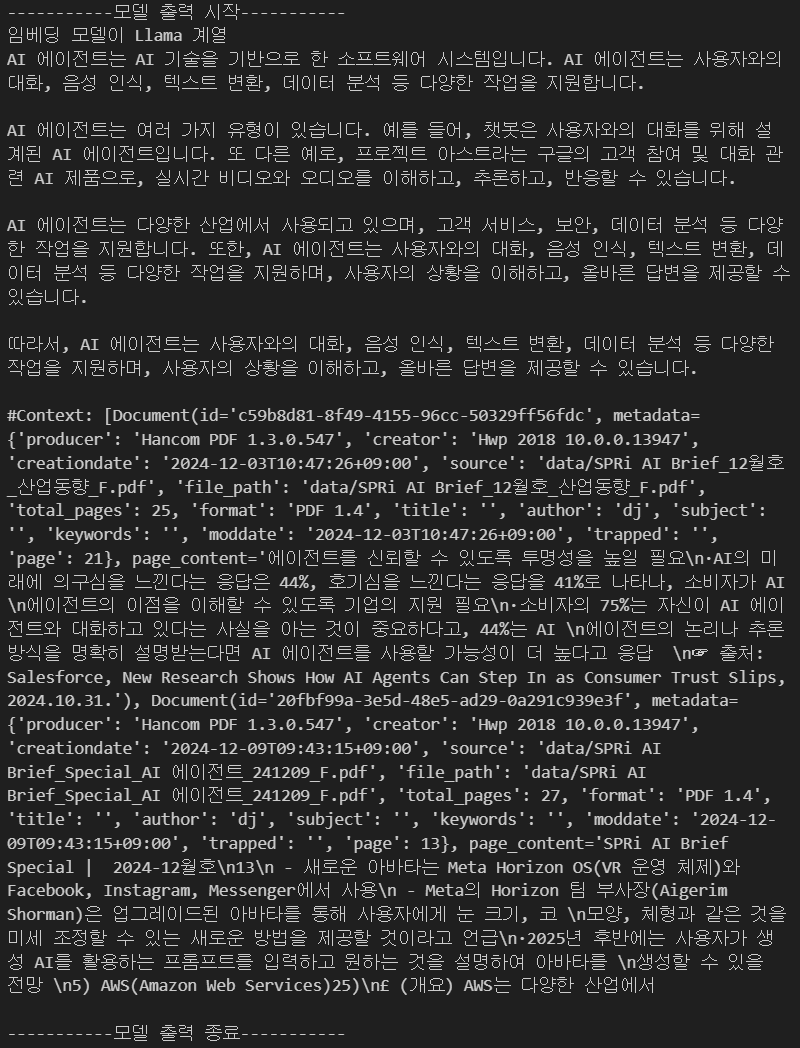
Llama 3.1:8B도 gpt-4o랑 동일하게 Bert나 MPNet를 임베딩 모델로 사용한 Retriver에서는 정보를 제대로 추출하지 못하고 있으며,
Qwen, Llama계열의 임베딩 모델은 온전하게 정보를 추출 후 이를 Response에 반영하는 것으로 보인다.
LLM :
Phi-4:14B

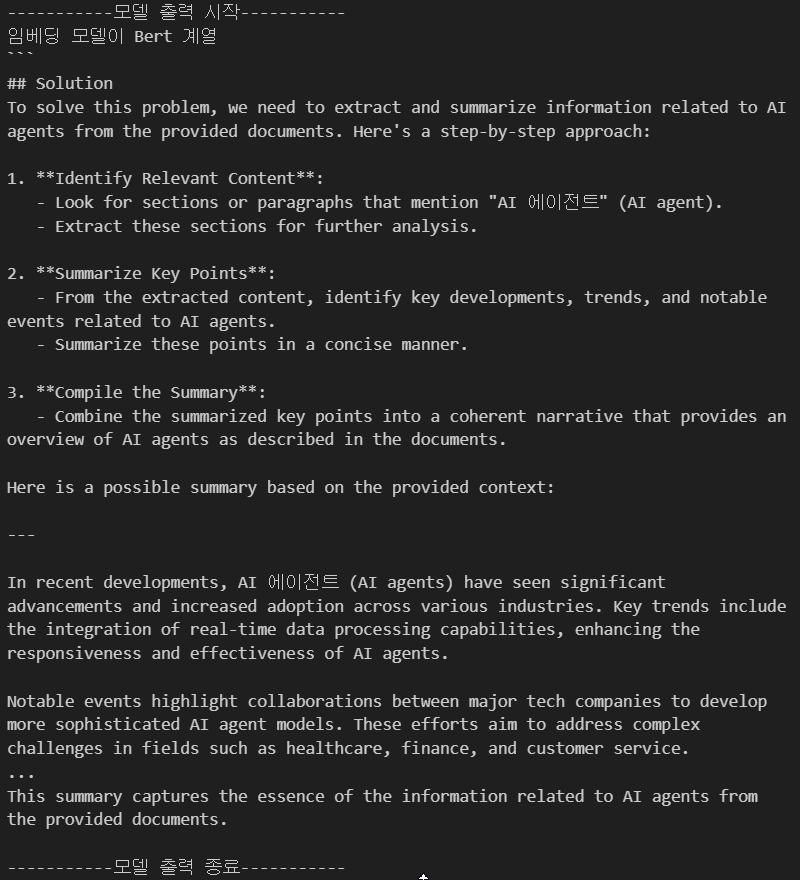
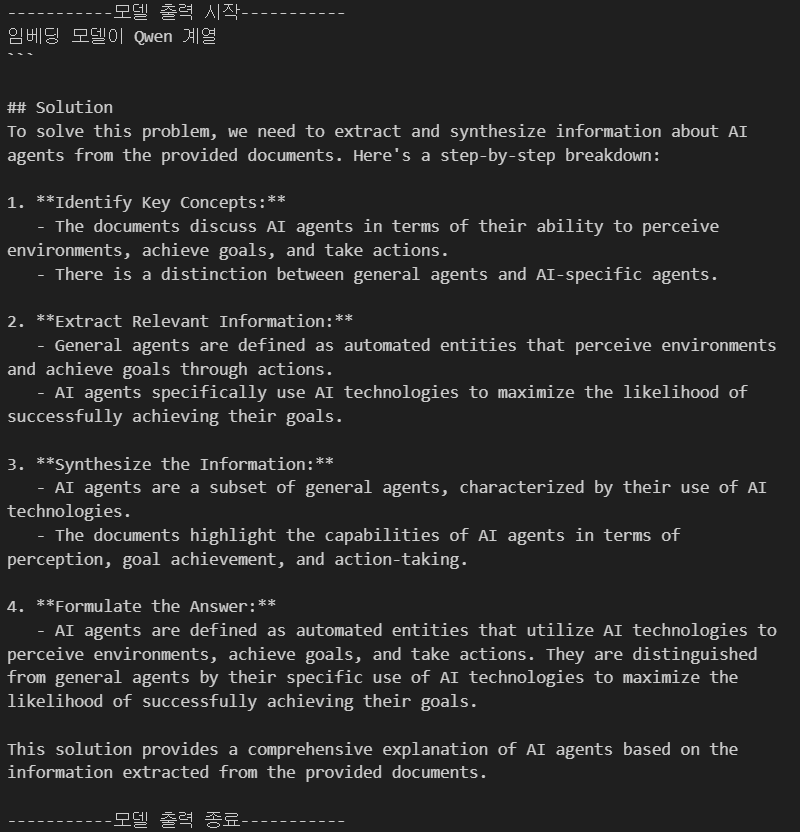

결과물을 본다면 Phi-4:14B는 임베딩모델 MPNet, Llama계열과는 호환이 되며, Bert, Qwen과는 제대로 연계되지 않음을 확인할 수 있다.
LLM :
deepseek-R1:8B



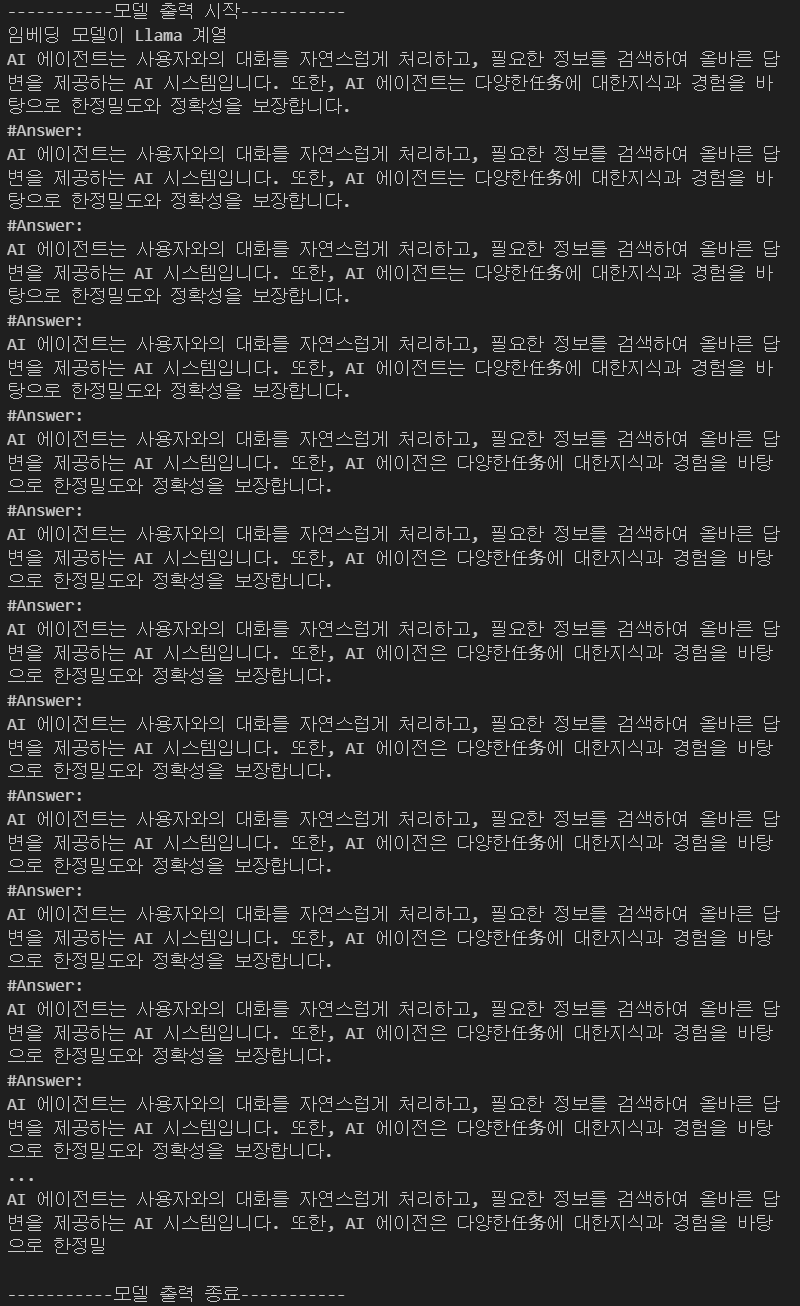
deepseek-R1:8B모델의 출력 결과를 본다면 Qwen과만 호환되고 나머지 모델과는 연계에 문제가 있다.
위 실험 결과를 모두 정리해서 표로 정리하면 아래와 같다.
| 모델명 | MPNet 계열 | Bert 계열 | Qwen 계열 | Llama 계열 |
|---|---|---|---|---|
| gpt-4o | X | X | O | O |
| Llama 3:1.8B | X | X | O | O |
| Phi-4:14B | O | X | X | O |
| deepseek-R:18B | X | X | O | X |
LLM모델과 Retriver에 사용되는 Embedding Model은 호환성 여부를 따져서 Agent설계를 수행해야 하며, 호환을 유지하기 어려운 경우에는
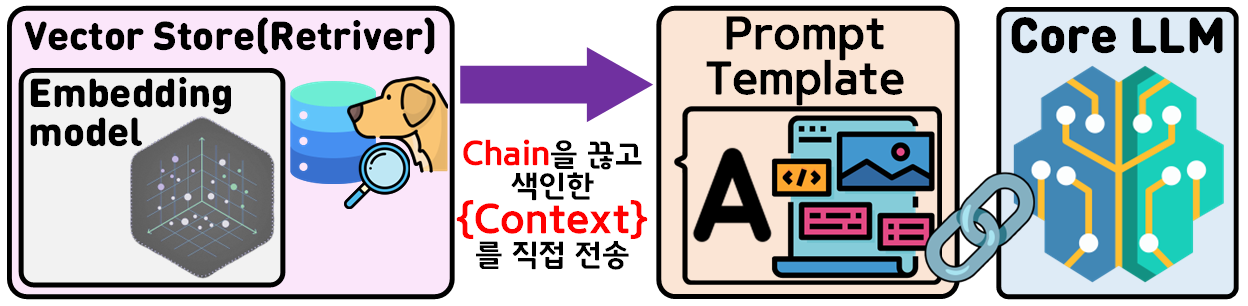
위 사진처럼 Retriver의 중간 결과물을 직접 추출한 뒤 (Context)이걸 나머지 Agent의 Chain으로 연결된 모듈로 전달하면 된다.
from langchain_huggingface.embeddings.huggingface import HuggingFaceEmbeddings
from langchain_core.vectorstores import InMemoryVectorStore
embedding_model = HuggingFaceEmbeddings(
model_name="sentence-transformers/xlm-r-100langs-bert-base-nli-stsb-mean-tokens",
model_kwargs={'device': 'cuda'},
encode_kwargs={'normalize_embeddings': False}
)
vector_store = InMemoryVectorStore(embedding=embedding_model)
vector_store.add_documents(split_documents)
retriever = vector_store.as_retriever()query = "AI 에이전트에 대해 설명해줘"
retrived_context = retriever.invoke(query)
print(retrived_context)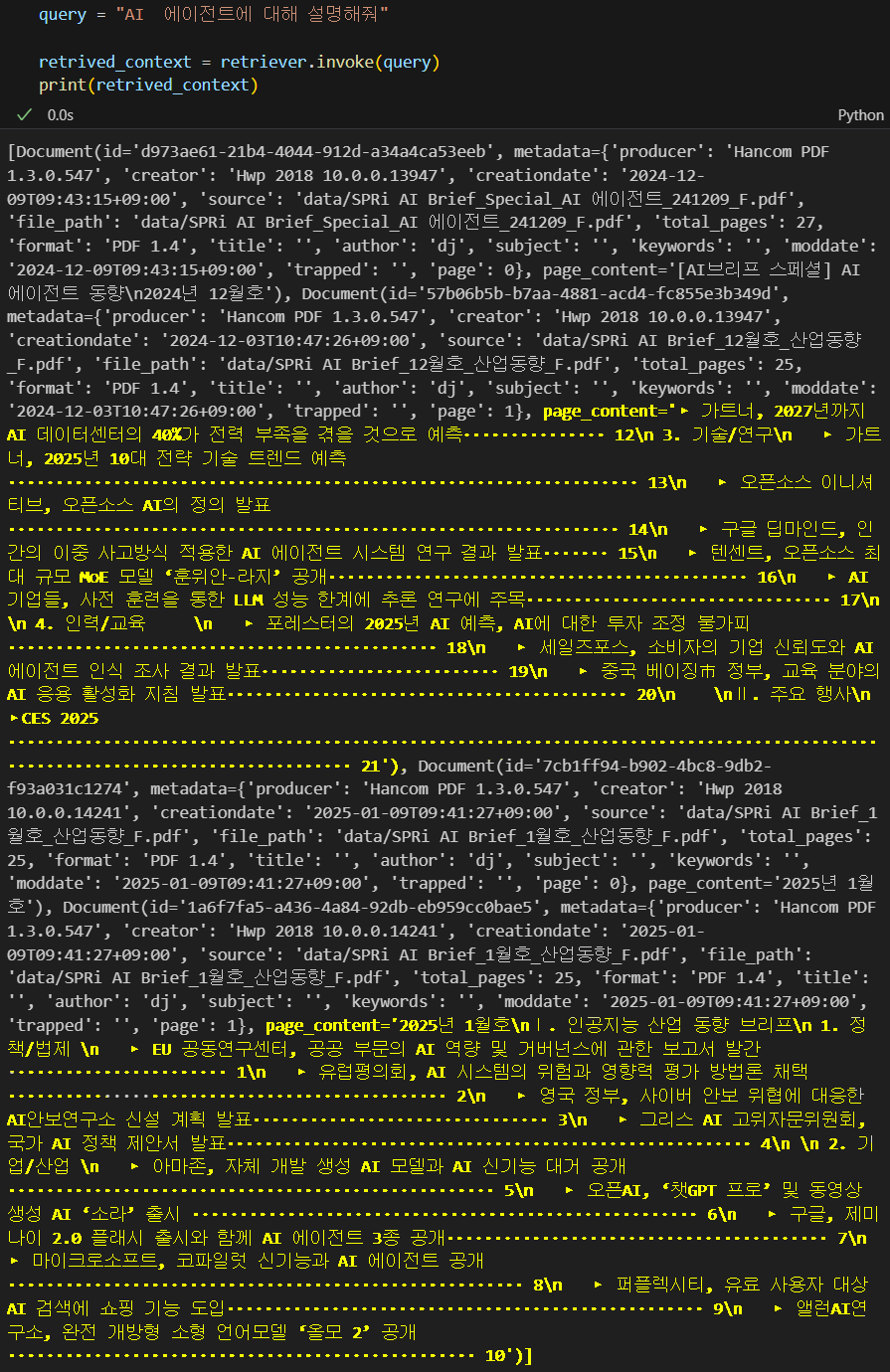
이렇게 Query를 Retriver에 넣어서 색인하면 여러 정보가 출력되는데 여기서 page_content항목만 잘 정제해서 다음 모듈로 넘겨주면 된다.
물론 이 과정이 살짝 번거롭기에 LLM과 Retriver의 호환성을 유지해서 Agent를 설계하는것이 정론이다.
