이번 모아모아 팀 프로젝트에서 다음과 같은 요구사항을 받게 되었다.
- "스터디 제목 뿐 아니라 태그를 통해서 필터링을 할 수 있어야 해요."
- "태그는 각각 카테고리를 가지고 있어요. 예를 들어 1기, 2기 와 같은 기수 카테고리, 그리고 BE,FE 와 같은 카테고리가 존재해요."
- "같은 카테고리의 태그끼리는 OR 조건으로 필터링 해주세요."
- "다만 서로 다른 카테고리의 태그 끼리는 AND 조건으로 필터링해야 해요!"
- "여전히 스터디 제목만으로 검색할 수도 있고, 필터링을 함께 혹은 스터디 제목으로 검색 없이 필터링만 할 수도 있어야 해요."
처음부터 이렇게 요구사항이 복잡했던 것은 아니다. 처음에는 태그에 카테고리별 분류 없이 단순히 모든 태그를 AND 조건으로 쿼리를 날려주면 됐었다. 하지만 FE 태그와 BE 태그를 사용자가 선택하였을 때, 사용자는 FE와 BE 모두를 예상하지만 우리의 생각대로라면 FE와 BE를 모두 만족하는 스터디 목록만(예를 들어, 운동 스터디(?)같이 프론트, 백엔드 구분이 없는 경우) 조회될 것이다.
따라서 우리는 앞서 보인 것과 같은 요구사항을 도출하게 되었고, 이를 구현하기 위한 여정을 기록하려고 한다.
다대다 매핑 어떻게 할거야?
가장 처음(모든 태그가 AND 조건이었을 때, 태그들을 구별하기 위해 Category 라는 도메인이 도출되지 않았을 때)에는 나와 베루스가 페어를 이루어 작업을 시작하였다.
우린 가장 먼저 DB 테입르의 다대다 매핑을 JPA 엔티티로 어떻게 매핑할지에서 부터 의견이 갈렸다.
DB 테이블과 JPA엔티티를 어떤식으로 매핑할 것인가?
베루스는 식별자(id)를 이용한 매핑 방법을 주장하였고, 나는 객체(Entity)를 이용해 매핑 방법을 주장하였다. 베루스의 경우에는 두 가지 방법 모두에 대한 경험이 있었지만, 나는 그러지 못했다. 따라서 베루스의 의견을 들어보기로 하였다. 베루스의 주장은 다음과 같다.
- 객체 그래프를 그릴 수 없어 조회를 join문을 사용해야한다. 따라서 조회를 위한 다른 클래스 DAO나 다른 클래스를 만들어야 한다.
- 하지만 JPA 엔티티는
명령에 관한 책임만 가지고,조회를 위한 클래스를 따로 구분하기 때문에 책임이 분리된다. - Study와 Tag의 경우 명령을 수행할 때 각자의 객체가 필요한게 아니고 식별자로도 충분하다.
- 또한 Study와 StudyTag를 같은 생명주기로 묶을 수 있다. 그러면 자연스럽게 Study자체가 StudyTag의 주인이 될 수 있어 패키지 분리도 수월하다.
이와 관련하여 조금 더 찾아볼 수 있는 내용을 첨부하도록 하겠다.
다시 돌아와서 나도 베루스의 의견에 동의하지 않지는 않았다. 실제로 중간에 연관관계를 위한 엔티티(StudyTag)를 두면서 현재 우리의 패키지 구조(도메인 별로 구분)에서 StudyTag 라는 녀석을 어디에 둘지 막막한 경험을 하였다. 또 StudyTag 가 무거워지는 것도 마음에 들지 않았다. Study면 study, Tag면 tag의 책임을 가지는 도메인 객체가 있으면 되지... StudyTag는 뭐야!
그럼에도 불구하고, 우선 내가 다대다 연관관계를 OneToMany, ManyToOne 으로 풀어서 중간에 StudyTag 를 두어 문제를 해결하고 싶은 이유는 다음과 같았다.
- 현재
베루스이외의 모든 팀원이식별자(id)를 이용한 매핑방법을 잘 모른다. 만약 우리가 Study와 Tag 다대다 관계에 있어서 해당 방법을 사용하면, 또 다른 다대다 관계인 Study와 Member에서도 일관성 있게 해당 방법을 사용해야 할 것으로 보이는데, 우리가 잘 할 수 있을까? - 현재 우리는
Study->Tag를 조회할 수 있어야 하고,Tag->Study도 조회가 가능해야 하는데, 객체 그래프를 그릴 수 없다는 것은 너무 치명적인 단점이지 않을까? (이는Study와Member사이에서도 문제가 될 것으로 생각된다.) - 명령과 조회의 책임을 분리하기 위해서 엔티티와 DAO와 같은 클래스를 두는게 어떤 장점이 있어?? (아직 명확한 예시나 답을 구하지 못한 상태이다.)
- 우리는 현재 동적 쿼리를 작성해야 할 것으로 생각된다. (제목만 있는 경우, 태그만을 이용해 필터링 하는 경우, 두 가지를 모두 사용하는 경우) 그런데
식별자(id)를 이용한 매핑방법을 사용했을 때에도 동적 쿼리를 작성하는데에 있어서 얻는 이점이 있을까? 예를 들어Querydsl을 사용할 수 있을까? 만약 불가능 하다면 SQL문을 직접 작성해야하는데 이게 과연 이점이 될 수 있을까?
이 중에서도 가장 큰 문제라고 생각했던 부분은 다른 팀원들 모두가 이 방법을 어떻게 사용해야할지, 왜 사용해야하는지 잘 모르고, 납득이 되어야한다는 것이었다. 결국 이 프로젝트는 혼자하는 것이 아니고 4명의 백엔드 크루들 모두가 함께 만들어 나가는 것이기 때문에 관련 코드를 리팩토링하거나 수정해야할 때에면 모두가 그 코드를 잘 이해하고 있어야 했다. 또 아무리 좋은 기술이라고 할지라도 그것을 도입할 때에는 모두의 동의가 필요하다고 생각했다.
따라서 우리는 4명의 백엔드 크루를 모두 모아 놓고, 어떤 방법이 좋을지에 대해서 의견을 나누고 결정하는 시간을 가졌다.
회의에서는 앞서 링크를 걸어두었던 Discussion 의 내용을 베루스가 이야기 해주었다.
그리고 각자의 의견을 나누는 과정을 시작하였다.
그런데 문득 위의 사진을 보던 나는 이상하다는 생각이 들었다.
우리가 이번 프로젝트에서 JPA 를 사용하는 이유가 뭘까? ORM을 위해서라고 생각하는데 모든 팀원이 동의하였다. 그런데 다대다 매핑을 1:다, 다:1로 풀어서 해결하기 위한 테이블의 구조를 그래도 객체 관계로 가져와 생기는 StudyTag 라는 객체가 적절할까? 우리가 만약 DB와 관련없이 해당 비즈니스를 해결하려고 했을 때 (ex. DB저장이 아닌 List에 저장)에도 우리는 StudyTag 라는 객체를 만들었을까? 그런데 만약 베루스가 말한 방법대로 한다면 이러한 객체가 만들어지지 않게 된다.
이런 이야기를 하고 보니, 나를 포함한 모두가 중간에 생기는 연관관계 엔티티에 대해서 부정적인 것은 확실했다. 또한 모두가 식별자(id)를 이용한 매핑 방법을 경험해보는 것도 좋은 경험이 될 수 있을 것이라고 생각하며 만약 해당 방법을 사용해보다가 단점을 느끼게 되면 그 때 다시 이야기를 해보자라는 것으로 의견이 모아졌다. (말을 100번 듣는 것보다는 한 번 찐하게 경험해보는 게 낫다는 의견이었다.)
결국 우리는 식별자를 이용해서 매핑하는 방법을 선택하게 되었다.
요구사항의 변경
앞서 언급한 것과 같이 모두 AND조건으로 필터링하는 것에서 OR 조건으로 처리하는 것으로 요구사항이 변경되게 되었다.
나도 앞서 언급한 것과 같은 이유로 동의하였고, 나머지 팀원 모두 기존의 방법은 사용자 입장에서 너무 어색할 것 같다고 동의하여 해당 제안을 받아들이기로 하였다.
하지만 문제는 해당 제안의 날짜이다. 우리는 1주마다 하나의 스프린트 기간으로 가져가고 있다. 하지만 이러한 제안에 대해서 이야기 나눈 시간은 금요일이었다. 즉, 주말을 제외하면 스프린트 마지막 날이었다.
그리고 이를 위해서는 Category 라는 새로운 도메인이 추가되어야 하고, Category와 Tag의 연관관계를 설정해주는 작업도 필요하고 이 말은 즉 DB 테이블의 변경이 필요하게 된다.
심지어 나와 베루스는 이전에 언급한 것과 같이 식별자(id)를 이용한 매핑 방법으로 구현을 어느정도 진행한 상태였었다. 우리는 결단이 필요했다. 결국 베루스와 나는 각각 찢어져서 구현을 진행하기로 하였다. 이미 어느 정도 함께 진행을 하면서 서로 이야기를 많이 하였고, 의견도 많이 나누었다. (이 과정에서 Jooq라고 하는 라이브러리도 이야기가 나왔었다. (내가 SQL을 직접 짜는 것은 너무 별로라고 생각했었기 때문이다..ㅋㅋ..)) 따라서 이제는 둘이 찢어져서 작업을 해도 괜찮겠다고 의견을 제시해주었고, 나도 동의했다.
베루스는 새롭게 추가된 Category 를 포함하여 카테고리별 필터 조회 및 검색 을 구현하기로 하였고, 나는 태그로 스터디 필터링해서 검색 하는 부분을 구현하기로 하였다.
그러다보니 아직 나에게는 생소한 식별자를 이용한 매핑 방법이 아닌 중간에 엔티티를 두고 일대다, 다대일로 풀어 매핑을 하는 것으로 결정하였다.
그리고 마지막으로 기존의 Tag -> Filter 로 네이밍을 변경하였다. 왜냐하면 Category 에 generation(기수), area(BE, FE와 같은 영역), tag(ex. Java, HTTP, React 등 스터디 태그) 가 포함되어야 했기 때문이다.
Querydsl 사용하기
태그로 스터디 필터링해서 검색 하는 부분을 혼자서 맡기로 하였다.
팀 프로젝트를 진행하면서 처음으로 혼자 코딩을 하는 시간을 가지게 된 것이다. 최근 약 한달간 혼자서 코딩하는 시간이 없다보니 오히려 어색하다는 느낌을 받기도 하였다.
가장 먼저 QueryDSL을 적용하기 위해 설정하는 작업이 필요했다. 하지만 나는 Groovy 문법이 익숙하지도 않고, 지금은 이것을 하나하나 이해하면서 공부를 해 적용하기 보다는 빠르게 도입하여 필요한 기능을 구현하는게 우선순위가 더 높았다. 향후에 공부가 필요하게 될 때 공부하는게 적절했다.
QueryDSL을 적용하기 위해 Tecoble 글 과 이전에 인프런의 QueryDSL 김영한님 강의 자료를 참고하였다.
최종적으로 우리 모아모아팀의 build.gradle은 다음과 같다.
buildscript {
ext {
queryDslVersion = "5.0.0"
}
}
plugins {
id 'org.springframework.boot' version '2.6.9'
id 'io.spring.dependency-management' version '1.0.11.RELEASE'
id 'java'
id "com.ewerk.gradle.plugins.querydsl" version "1.0.10"
}
group = 'com.woowacourse'
version = '0.0.1-SNAPSHOT'
sourceCompatibility = '11'
configurations {
compileOnly {
extendsFrom annotationProcessor
}
}
repositories {
mavenCentral()
}
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
implementation 'org.springframework.boot:spring-boot-starter-web'
implementation 'org.springframework.boot:spring-boot-starter-validation'
compileOnly 'org.projectlombok:lombok'
annotationProcessor 'org.projectlombok:lombok'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testImplementation 'io.rest-assured:rest-assured'
runtimeOnly 'com.h2database:h2'
// querydsl
implementation "com.querydsl:querydsl-jpa:${queryDslVersion}"
implementation "com.querydsl:querydsl-apt:${queryDslVersion}"
}
tasks.named('test') {
useJUnitPlatform()
}
// querydsl
def querydslDir = "$buildDir/generated/querydsl"
querydsl {
jpa = true
querydslSourcesDir = querydslDir
}
sourceSets {
main.java.srcDir querydslDir
}
compileQuerydsl {
options.annotationProcessorPath = configurations.querydsl
}
configurations {
compileOnly {
extendsFrom annotationProcessor
}
querydsl.extendsFrom compileClasspath
}사실 어떤 내용인지 잘모르지만, 본인이 이해한대로 해석해보면 querydsl 5.0.0 버전의 의존성을 주입받고, querydsl 빌드 이후 생성된 파일을 저장할 source 디렉토리의 위치를 지정해준 정도 인 것으로 생각된다.
querydsl 빌드 이후 생성된 파일 이라는 말이 어색할 수 있는데, 앞서 Tecoble 글을 참고하여도 알 수 있다시피, querydsl은 @Entity 어노테이션이 붙은 클래스들을 탐색하고 JPAAnnotationProcessor 를 사용해 Q클래스 라는 것을 생성한다. 그리고 우리는 이 Q클래스 라는 것을 통해서 쿼리문을 작성하게 된다.
쉽지 않은 여정
Entity 매핑하기
@Entity
@Getter
@AllArgsConstructor
@NoArgsConstructor(access = PROTECTED)
public class Study {
@Id
@GeneratedValue(strategy = IDENTITY)
private Long id;
private String title;
private String excerpt;
private String thumbnail;
private String status;
@OneToMany(mappedBy = "study")
private List<StudyFilter> studyFilters = new ArrayList<>();
...
}@Entity
@Getter
@AllArgsConstructor
@NoArgsConstructor(access = PROTECTED)
public class StudyFilter {
@Id
@GeneratedValue(strategy = IDENTITY)
private Long id;
@ManyToOne
@JoinColumn(name = "study_id")
private Study study;
@ManyToOne
@JoinColumn(name = "filter_id")
private Filter filter;
}@AllArgsConstructor
@Getter
@Entity
@NoArgsConstructor(access = PROTECTED)
public class Filter {
@Id
@GeneratedValue(strategy = IDENTITY)
private Long id;
private String name;
@ManyToOne(fetch = LAZY)
@JoinColumn(name = "category_id")
private Category category;
@OneToMany(mappedBy = "filter")
private List<StudyFilter> studyFilters = new ArrayList<>();
...
}@Entity
@Getter
@AllArgsConstructor
@NoArgsConstructor(access = PROTECTED)
public class Category {
@Id
private Long id;
private String name;
@OneToMany
@JoinColumn(name = "filter_id")
private List<Filter> filters = new ArrayList<>();
...
}최종적으로는 위와같은 Entity 클래스들이 탄생했다! 하지만 그 과정에서 많은 실수가 있었다. (실수라기 보단 내가 몰랐기 때문이라고 생각한다.)
가장 먼저 Èrror creating bean with name 'entityManagerFactory' 에러를 만나게 되었다.
그리고 이를 해결하기 위해 참고한 블로그 글 을 먼저 첨부하겠다.
CREATE TABLE study_filter
(
id BIGINT PRIMARY KEY AUTO_INCREMENT,
study_id BIGINT,
filter_id BIGINT,
FOREIGN KEY (study_id) REFERENCES study (id),
FOREIGN KEY (filter_id) REFERENCES filter (id)
);우리는 study_filter 테이블을 위와 같이 설계하였다. Study의 id와 Filter의 id를 조합한 복합키를 PK로 사용하는 것이 아니라 Auto Increment 의 별도 키를 가지는 것을 확인할 수 있다.
그런데 StudyFilter Entity 클래스에서 @GeneratedValue 부분을 빼먹어서 발생하는 에러였다.
예를 들어 category 테이블을 보면 아래와 같이 자동증감 컬럼 을 PK로 사용하지 않는다.
CREATE TABLE category
(
id BIGINT PRIMARY KEY,
name VARCHAR(255) NOT NULL
);따라서 Category Entity 클래스에서도 @Id 를 통해 엔티티의 식별자 필드만 지정해주면 되지만, StudyFilter 에서는 DDL이 위와 같으므로 GeneratedValue 가 필요하였다. 즉, schema.sql 에 작성해놓은 DDL와 엔티티가 일치하지 않아 발생하는 에러였다. 그러면서 테이블과 엔티티의 매핑이 정상적인지를 확인하는 spring.jpa.hibernate.ddl-auto = validate 를 application 설정 파일에 추가하는 것은 어떨지 하는 생각도 들어 조만간 제안해보려고 한다.
@Repository
다음으로 만난 예외는 Unsatisfied dependency expressed through field 라는 예외였다. 이전에 Spring Data JPA 를 사용하여 개발할 때에는 인터페이스만 작성하면 실행 시점에 알아서 구현 객체를 동적으로 생성해서 주입해주므로 @Repository 와 같은 어노테이션이 불필요했다. 하지만 querydsl 을 작성하면서 직접 쿼리문 작성이 필요했고, 이에 따른 빈 등록을 해주어야했다. 또한 테스트 코드에서는 @DataJpaTest 즉 JPA 관련 테스트 설정만 로드해서 사용하는 어노테이션을 사용하므로 내가 직접 만든 @Repository 를 붙여 만든 다음의 코드는 테스트 코드에서 인식할 수 없었다.
@RequiredArgsConstructor
public class StudyFilterRepository {
private final JPAQueryFactory queryFactory;
@Override
public StudySlice searchBy(StudySearchCondition condition, Pageable pageable) {
final List<Study> studies = queryFactory
.select(study)
.from(studyFilter)
.where(studyTitleEq(condition.getTitle()),
studyFilter.study.in(findFilteredStudy(condition.getFilters())))
.join(studyFilter.study, study)
.join(studyFilter.filter, filter)
.distinct()
.offset(pageable.getOffset()).limit(pageable.getPageSize() + 1)
.fetch();
boolean hasNext = studies.size() > pageable.getPageSize();
removeLastOne(studies, hasNext);
return new StudySlice(studies, hasNext);
}
...
}이를 해결하기 위해 JpaRepository<StudyFilter, Long> 인터페이스와의 연관이 필요해지게 되었고, 다음과 같이 해결하였다.
public interface StudyFilterRepository extends JpaRepository<StudyFilter, Long>, CustomStudyFilterRepository {
StudySlice searchBy(StudySearchCondition condition, Pageable pageable);
}public interface CustomStudyFilterRepository {
StudySlice searchBy(StudySearchCondition condition, Pageable pageable);
}@RequiredArgsConstructor
public class CustomStudyFilterRepositoryImpl implements CustomStudyFilterRepository {
private final JPAQueryFactory queryFactory;
@Override
public StudySlice searchBy(StudySearchCondition condition, Pageable pageable) {
final List<Study> studies = queryFactory
.select(study)
.from(studyFilter)
.where(studyTitleEq(condition.getTitle()),
studyFilter.study.in(findFilteredStudy(condition.getFilters())))
.join(studyFilter.study, study)
.join(studyFilter.filter, filter)
.distinct()
.offset(pageable.getOffset()).limit(pageable.getPageSize() + 1)
.fetch();
boolean hasNext = studies.size() > pageable.getPageSize();
removeLastOne(studies, hasNext);
return new StudySlice(studies, hasNext);
}
...
}물론 이와 같은 방법 이외에도 @DataJpaTest(includeFilters = @Filter(type=ANNOTATION, classes = Repository.class)) 와 같이 Repository 어노테이션이 붙은 클래스를 포함하겠다라고 지정해주는 방법으로도 해결이 가능하다. 하지만 위와 같이 해결한 이유는 향후에 Spring Data JPA 에서 제공하는 기능들을 함께 활용할 수 있을 것으로 예상되었기 때문이다.
querydsl 작성하기
이제 본격적으로 QueryDSL 을 작성할 준비가 되었다. 본인은 이전에 김영한님의 인프런 QueryDSL 강의와 더불어 우아한 형제들의 Querydsl 사용법 이라는 글을 참고하여 작성하였음을 알린다.
가장 먼저 다음과 같이 JPAQueryFactory 를 빈으로 등록해주었다. (별도의 Config 클래스로 분리해도 괜찮을 것 같다.) JPAQueryFactory 가 필요한 곳에서 new JPAQueryFactory(em); 으로 매번 생성하는 것보다는 빈으로 등록해두는 편이 훨씬 편할 것으로 생각해서 이렇게 빈으로 등록해두었다.
@SpringBootApplication
public class MoamoaApplication {
public static void main(final String[] args) {
SpringApplication.run(MoamoaApplication.class, args);
}
@Bean
public JPAQueryFactory jpaQueryFactory(EntityManager entityManager) {
return new JPAQueryFactory(entityManager);
}
}이제 남은 것은 우리 조건에 맞게 쿼리를 날리도록 동적 쿼리를 작성하는 일이었다.
우선 제목 검색에 해당하는 조건을 return hasText(title) ? studyFilter.study.title.containsIgnoreCase(title) : null; 와 같이 풀고 하나의 메소드로 두었다. 우리는 현재 사용자가 입력한 문자열을 대소문자 구분없이 (공백을 제거하고) 포함하는 Study 목록을 불러오고 있기 때문이다.
다음으로는 카테고리 별 태그로 필터링하는 작업이었다. 처음 접근은 카테고리 별로 필터를 묶고, booleanBuilder.or(studyFilter.filter.eq(filter)) 와 같이 각 카테고리에서 필터를 or 조건으로 추가하고, 이를 다시 booleanBuilder.and() 로 묶어주는 방법을 생각했다. 즉, 다음과 비슷한 로직이다.
for (Category category : categories) {
final List<Filter> categorizedFilters = makeCategorizedFilters(filters, category);
booleanBuilder.and(categorizedFilterEq(categorizedFilters));
}
private BooleanBuilder categorizedFilterEq(final List<Filter> filters) {
final BooleanBuilder booleanBuilder = new BooleanBuilder();
for (Filter filter : filters) {
booleanBuilder.or(studyFilter.filter.eq(filter));
}
return booleanBuilder;
}하지만 원하는대로 동작하지 않았다. study_filter 테이블에서 filter의 id가 and 조건으로 묶이는 것을 확인 할 수 있었다. 하지만 우리가 알다시피 study_filter 에서 filter id가 2이면서 동시에 1인 row 는 존재할 수 없다. 즉 올바르진 못한 쿼리문이 나가고 있었고, 당연히 결과는 나오지 않았다.
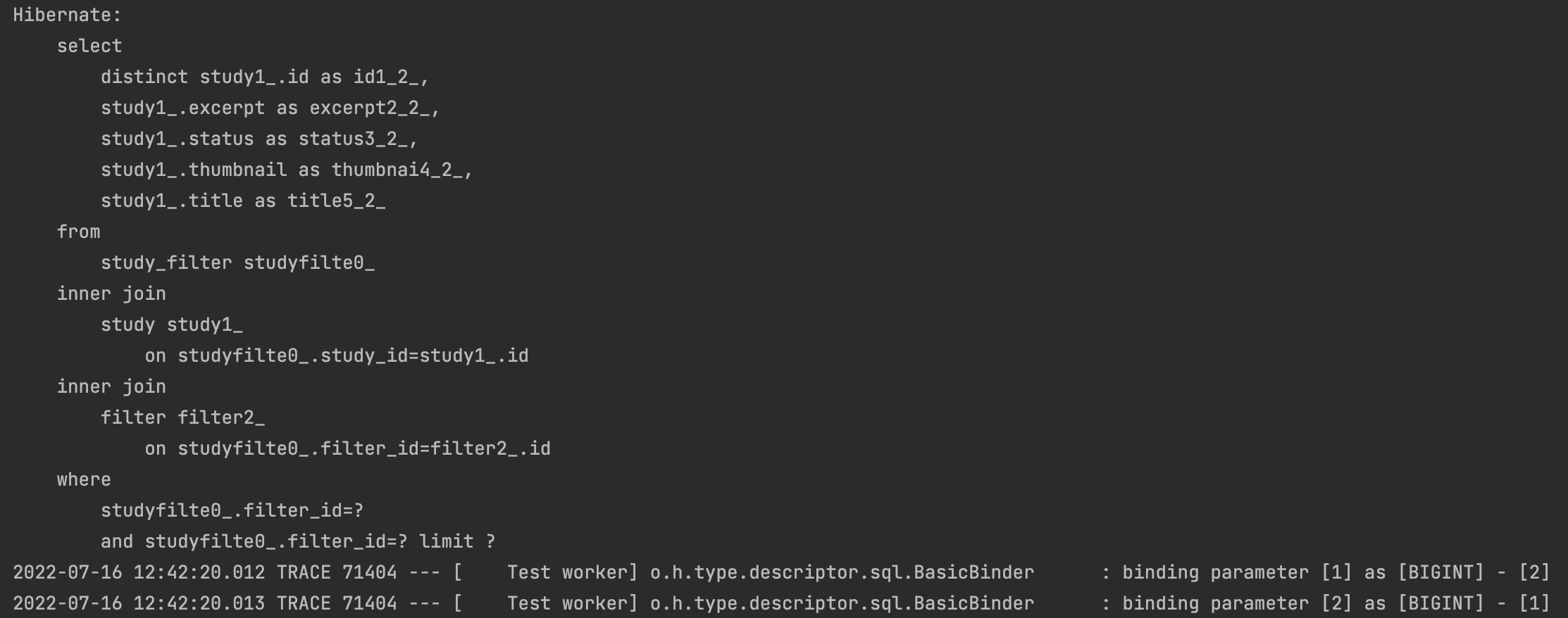
이후에도 계속해서 수정을 진행해보았는데, 아래 그림과 같이 내가 원하는 대로 or 처리르 먼저 진행하고 and 묶는 쿼리를 작성할 수 있었다. 하지만 3, 4, 3, 4 와 같이 반복된 id 값을 사용하고 있는 문제 이외에도 이전과 동일하게 filter의 id 가 3 이면서 동시에 4인 row 가 study_filter 테이블에 존재할 수 없다는 문제점이 존재했다.
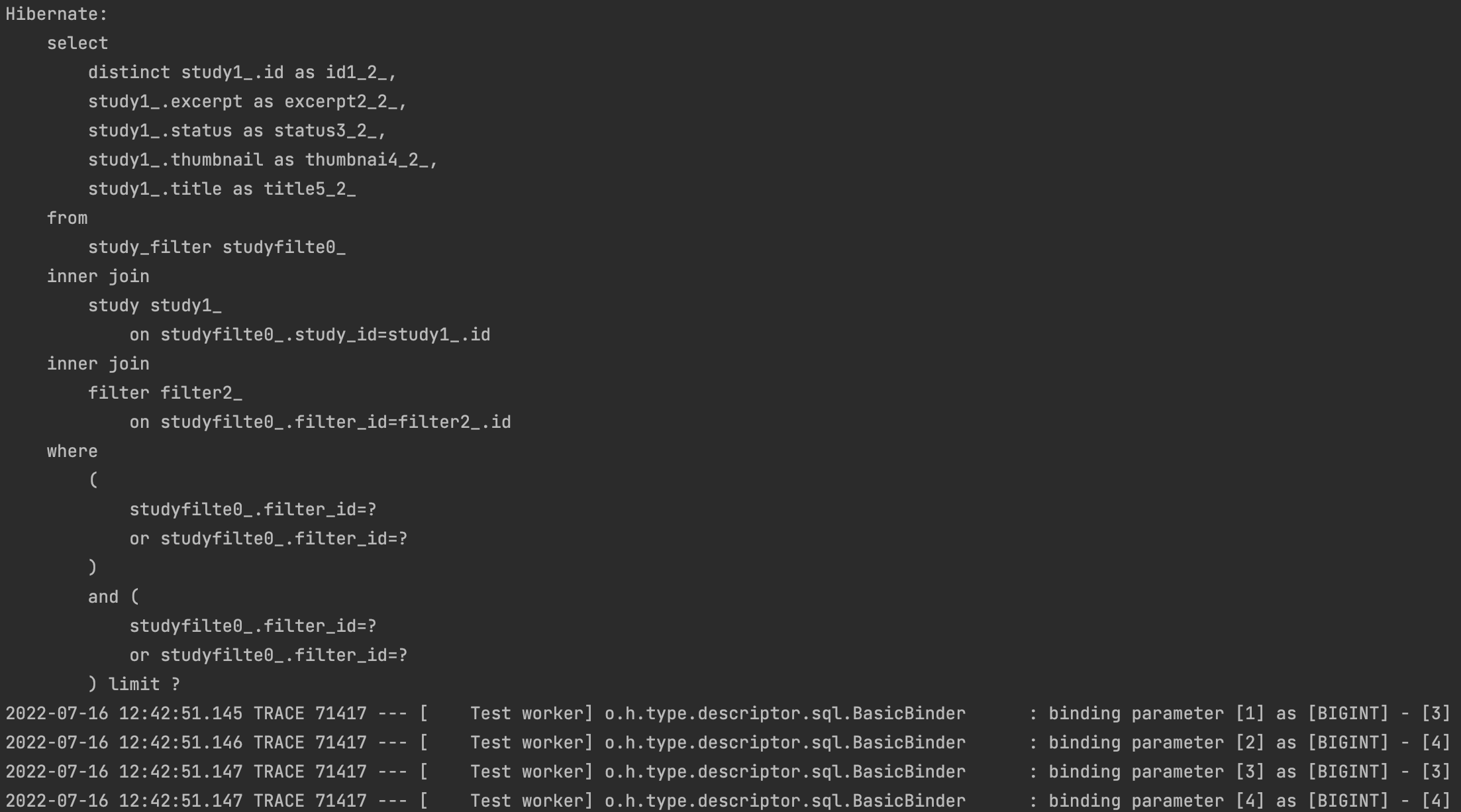
(이외에도 fetchjoin을 사용하지 못하는(?) 문제도 있었는데, 이는 원인을 찾지 못하였다...ㅠ.ㅠ 관련된 에러 키워드는 query specified join fetching, but the owner of the fetched 였던 것으로 기억한다..)
(또 No row with the given identifier exists 와 같은 오류를 만나기도 하였는데, 원인은 join 결과 row가 존재하지 않아서 발생하는 문제이다. 이는 본인이 Filter 와 Category 가 일대다 관계임에도 불구하고, OneToOne 매핑을 하고 있었기 때문에 발생한 오류였다.)
이후에 어떻게 내가 원하는 쿼리를 작성할 수 있을까? 계속 고민해보았다. 결론은 다음과 같다.
- 우선 Category 별로 필터를 분리한다.
- 분리된 Category를 돌면서(iter) 각 카테고리 별로
or조건으로 동일한 studyFilter와 일치하는 filter에 해당하는 Study를 찾고 이를List에 저장해둔다.
- 분리된 Category를 돌면서(iter) 각 카테고리 별로
- 그리고 일치하지 않는 원소가 있으면 삭제해 나간다.
(ex: 첫번재 카테고리의 Filter List가 (1, 2, 3) 이고, 두번째 카테고리의 Filter List가 (1, 2) 이면 포함되지 않는 "3" 은 제거된다.)
- 그리고 일치하지 않는 원소가 있으면 삭제해 나간다.
위와 같은 흐름으로 쿼리문을 작성하였다.
전체코드
public class CustomStudyTagRepositoryImpl implements CustomStudyTagRepository {
private final JPAQueryFactory queryFactory;
public CustomStudyTagRepositoryImpl(final EntityManager entityManager) {
this.queryFactory = new JPAQueryFactory(entityManager);
}
@Override
public StudySlice searchBy(StudySearchCondition condition, Pageable pageable) {
final List<Study> studies = queryFactory
.select(study)
.from(studyTag)
.where(studyTitleEq(condition.getTitle()),
studyTag.study.in(findFilteredStudy(condition.getTags())))
.join(studyTag.study, study)
.join(studyTag.tag, tag)
.distinct()
.offset(pageable.getOffset()).limit(pageable.getPageSize() + 1)
.fetch();
boolean hasNext = studies.size() > pageable.getPageSize();
removeLastOne(studies, hasNext);
return new StudySlice(studies, hasNext);
}
private Predicate studyTitleEq(final String title) {
return hasText(title) ? studyTag.study.title.containsIgnoreCase(title) : null;
}
private List<Study> findFilteredStudy(final List<Tag> tags) {
final List<Category> categories = findCategories(tags);
final List<Study> result = new ArrayList<>();
for (Category category : categories) {
final List<Tag> categorizedTags = makeCategorizedTags(tags, category);
final List<Study> studies = findStudyWithTag(categorizedTags);
if (result.isEmpty()) {
result.addAll(studies);
}
result.removeIf(finalStudy -> !studies.contains(finalStudy));
}
return result;
}
private List<Category> findCategories(final List<Tag> tags) {
return tags.stream()
.map(Tag::getCategory)
.collect(toList());
}
private List<Study> findStudyWithTag(final List<Tag> tags) {
return queryFactory.select(study)
.from(studyTag)
.where(categorizedTagEq(tags))
.join(studyTag.study, study)
.fetch();
}
private List<Tag> makeCategorizedTags(final List<Tag> tags, final Category category) {
List<Tag> categorizedTags = new ArrayList<>();
for (Tag tag : tags) {
addTag(category, categorizedTags, tag);
}
return categorizedTags;
}
private void addTag(final Category category, final List<Tag> categorizedTags, final Tag tag) {
if (category.getId().equals(tag.getCategory().getId())) {
categorizedTags.add(tag);
}
}
private BooleanBuilder categorizedTagEq(final List<Tag> tags) {
final BooleanBuilder booleanBuilder = new BooleanBuilder();
for (Tag tag : tags) {
booleanBuilder.or(studyTag.tag.eq(tag));
}
return booleanBuilder;
}
private void removeLastOne(final List<Study> studies, final boolean hasNext) {
if (hasNext) {
studies.remove(studies.size() - 1);
}
}
}어려웠던 점
OR 처리
이번에 querydsl로 쿼리를 짜면서 가장 어려웠던 점 중 하나가 바로 OR 처리였다. 모든 조건을 AND 처리 해야하는 것이 아니라 같은 카테고리 내의 태그들은 서로 OR 조건으로 처리를 해주어야했다.
예를 들어 다음과 같은 메소드를 단순히 querydsl의 where 절 속에 나열하게 되면 모두 and 처리가 된다. or를 한다고 해도 or에는 null이 오면 안되는데, 현재는 3가지(generation, area, subject) 모두 온다는 보장이 없었다.
private BooleanExpression sutdyTagEq(final List<Tag> tags) {
...
}따라서 현재는 쿼리를 총 4번 (최종적으로 쿼리 한 번, 카테고리별로 한번씩 총 3번까지 가능) 날리더라도 위와 같은 구조를 가지게 된 것이다. 물론 성능상으로는 그렇게 좋지 못하지만 이 보다 더 나은 방법을 아직까지는 찾지 못하였다.
서브 쿼리 사용하기?
다음으로 구현중에 고려했던 방법은 서브쿼리였다. where 절 내부에서 각각의 카테고리 별로 일치하는 tag들을 검색하고 이를 AND 조건으로 묶어 내는 방법이었다.
하지만 아직 querydsl을 잘 모르기도 하고, where 절 안에 서브쿼리를 어떤식으로 작성해야할지 감이 잡히지 않아서 pass한 방법이다. 향후에 querydsl에 익숙해지고 공부를 할 기회가 생기면 지금의 코드를 개선해보는 것도 방법이 될 수 있겠다. 참고 사이트
기존의 Spring Data JPA와..
나는 내가 만든 querydsl을 포함하는 클래스와 기존의 Spring Data JPA(즉, JpaRepository 를 extends 하는 클래스)와 함께 쓰고 싶었다. 따라서 여러가지 고민을 한 끝에 다음과 같은 구조가 나오게 되었다.
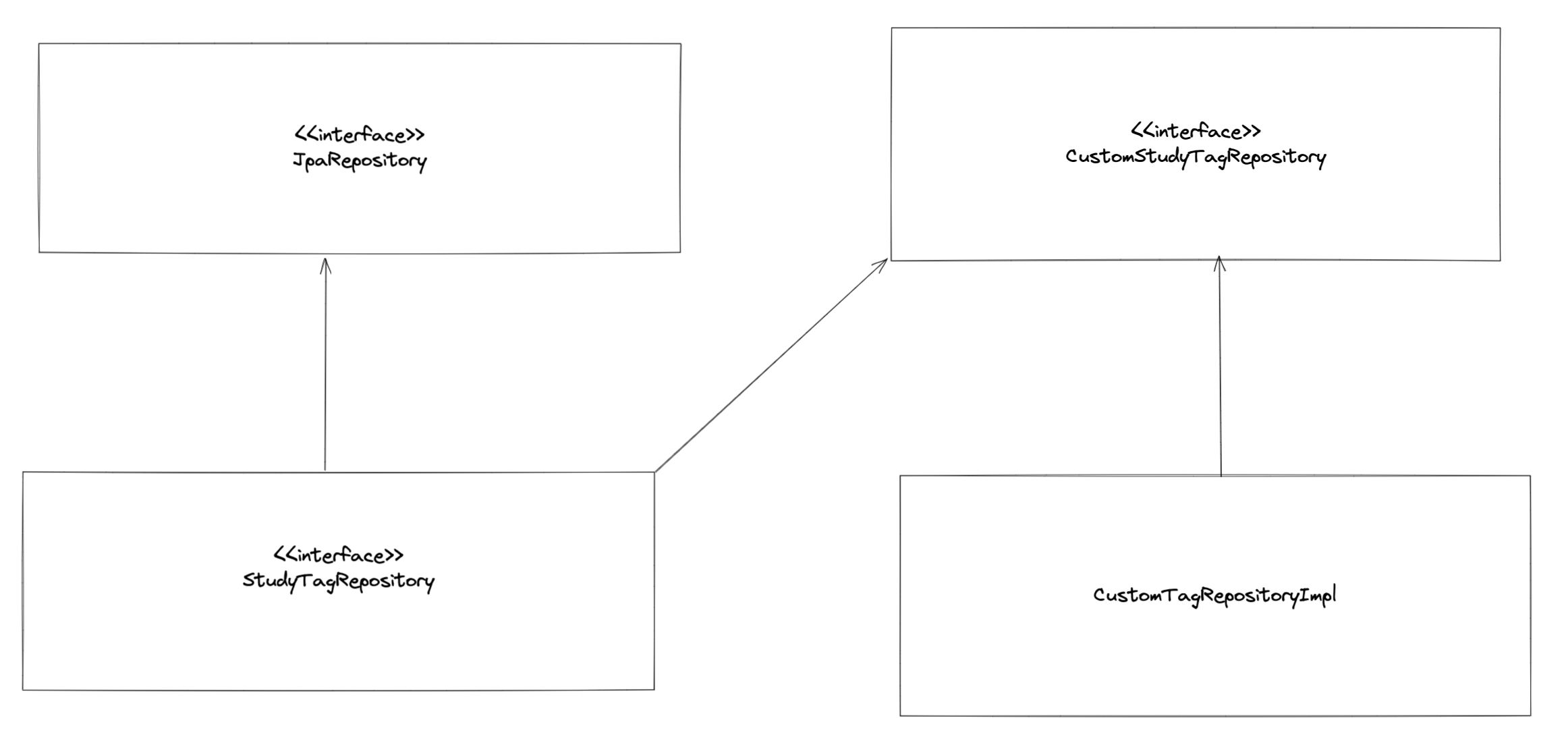
public interface StudyTagRepository extends JpaRepository<StudyTag, Long>, CustomStudyTagRepository {
StudySlice searchBy(StudySearchCondition condition, Pageable pageable);
}public interface CustomStudyTagRepository {
StudySlice searchBy(StudySearchCondition condition, Pageable pageable);
}public class CustomStudyTagRepositoryImpl implements CustomStudyTagRepository {
private final JPAQueryFactory queryFactory;
public CustomStudyTagRepositoryImpl(final EntityManager entityManager) {
this.queryFactory = new JPAQueryFactory(entityManager);
}
...
}그리고 다른 곳에서는 querydsl을 사용하는 것과 Spring Data JPA 를 사용하는 것은 고려할 필요 없이 StudyTagRepository 를 사용하면 된다. 이 과정에서 많은 고민을 하였고, 동일한 Type의 Bean이 여럿일 때의 문제점을 만나볼 수 있었고, @Qualifier, @Primary 의 사용을 고려하기도 하였다.
점점 비대해지는데..??
가장 먼저 팀원들의 코드리뷰 내용은 생략하고 PR 주소로 대체하겠다.
이번에 querydsl을 프로젝트에 도입한 이유는 querydsl 의 타입 안정성(즉, 쿼리를 문자열로 작성하는 것이 아니라 자바 코드로 작성함으로써 컴파일 타임에 에러를 방지할 수 있다.) 과 함께 가독성(쿼리를 직접 작성할 때에 비해서 가독성이 좋다고 생각한다. 특히 테이블이 아닌 객체를 기반으로 쿼리를 작성한다는 점도 한 몫한다고 생각한다. (비교적 테이블의 구조를 고려하지 않아도 됌)) 마지막으로는 보다 나은 동적 쿼리 작성에 있다고 생각한다.
하지만 이번에 querydsl 을 적용하고 보니 위에서 봤다시피 하나의 쿼리(조회)를 날리는데에 100줄이 넘는 코드를 작성해야하는 문제가 있다는 생각이 들었다.
(물론 메소드 분리와 함께 명시적인 메소드명을 사용함으로써 어느 정도 개선이 되었다고 볼 수도 있겠지만, 스스로 생각하기에는 그렇다.)
또한 패키지 구조 변경등에 의해 매번 querydsl을 빌드해주어야하는 것도 문제였다. (빈번한 것은 아니지만)
결국 팀프로젝트는 나 혼자 하는 것이 아니고, 다른 팀원이 현재 내 코드를 리팩토링하고 개선하거나 추가해야 하는 상황이 올 수 있는데 과연 현재 querydsl을 모르는 팀원을 포함하여 모든 팀원이 이를 공부하는데 비용을 투자하고 사용하는 것이 적절한가 하는 생각이 들었다.
또한 프로젝트를 진행하며 여러가지 논의(토론)이 있었다. 그 중에서 이번 스프린트2 동안 백엔드 팀에서 가장 많이 고려한 부분은 DB 테이블과 JPA 엔티티를 어떤식으로 매핑할 것인가? 와 함께 [DB 테이블과 JPA 엔티티 매핑 방식에 대한 고민], 그리고 CQRS(조회와 명령의 분리) 이었다.
우리 팀의 결론은 식별자(id)를 통한 매핑이었고, 이렇게 됨으로써 결론적으로 querydsl을 사용하지 못하게 되었다. (객체가 객체를 참조하고 있는 구조가 아니기 때문에..) 따라서 querydsl을 직접 SQL 문으로 풀어서 문제를 해결하게 되었다.
결국 product 코드에 querydsl 을 제거하게 되었지만, 나름 괜찮은 경험이었고 장점만 있을 것으로 생각했던 것과 달리 생각보다(?) 사소한 단점들을 경험해볼 수 있는 의미있는 시간이었다.
