우아한테크코스 레벨3, 우리팀(모아모아)의 2차 데모 기간동안 느낀 점 등을 기록하려고 한다.
(2차 데모 기간, 7월 11일 ~ 7월 22일)
진행한 사항
스프린트2 기간 동안 정말 많은 사항들을 진행하였다.
(주말을 제외하면 경우 10일 이라는 시간이었음에도 우리 팀 모두 열심히 많은 사항들을 함께 진행해준 것 같아 고마운 마음이다.)
우리팀은 매일매일 데일리 미팅 을 진행하고, 해당 미팅에서 각자의 진행사항과 오늘 진행할 사항등을 공유하고 이를 기록하고 있다.
보다 자세한 내용은 아래 링크에서 확인할 수 있을 것 같다!
MOAMOA Daily Sprint2
크게 Github Actions와 파이썬 소켓 프로그램 을 이용한 CI/CD 진행과 로그인 기능 구현, 태그를 통해 필터링해서 검색하기, DB 테이블 설계, 엔티티 매핑에 대한 회의, 스토리 포인트 등등을 진행하였다.
EC2 배포와 CI/CD
우리는 이번 스프린트2 동안 dev 서버, prod 서버, dev용 db 서버 그리고 frontend 용 서버를 하나 만들어 총 4개의 인스턴스를 생성하였다.

그리고 이러한 과정에서 가장 인상깊은 것은 Jenkins를 사용하지 않고, Github Actions와 파이썬 소켓 프로그램을 이용하여 CI/CD 환경을 구축한 것이다.
(기존의 CI환경은 우리가 develop 브랜치로 PR을 날리거나 병합될 때(push될 때), main으로 병합될 때 테스트를 수행하도록 Github Actions를 통해서 구축되어 있는 상태이다.)
name: backend
on:
push:
branches:
- main
pull_request:
branches:
- main
- develop
defaults:
run:
working-directory: backend
jobs:
build:
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v3
- name: Set up JDK
uses: actions/setup-java@v3
with:
java-version: '11'
distribution: 'temurin'
- name: Build
run: ./gradlew build --exclude-task test
- name: Test
env:
client-id: ${{ secrets.CLIENT_ID }}
client-secret: ${{ secrets.CLIENT_SECRET }}
jwt-secret-key: ${{ secrets.JWT_SECRET_KEY }}
jwt-expire-length: ${{ secrets.JWT_EXPIRE_LENGTH }}
run: ./gradlew test -Doauth2.github.client-id=${{ env.client-id }} -Doauth2.github.client-secret=${{ env.client-secret }} -Dsecurity.jwt.token.secret-key=${{ env.jwt-secret-key }} -Dsecurity.jwt.token.expire-length=${{ env.jwt-expire-length }}우리팀의 생각은 이러했다. 기존 스프린트1에 비해서 스프린트2에 구현할 기능이 많았다.
우리는 스프린트1 동안 기본적인 Read(읽기, 조회) 기능을 구현하였다. 스터디 전체 조회 및 페이징, 검색 기능 정도를 스프린트1 동안 구현하였고, 여기서 우리가 스프린트2 데모 데이 때 우리 서비스의 가치를 제공하려면 이전에 비해 꽤나 많은 기능을 제공해야한다고 생각하였다.
또한 우리팀원들 중 아무도 Jenkins에 대한 경험이 없었다. 물론 본인의 경우 작년 단국대학교 경소톤 대회에 출전할 당시 만들었던 위아원 서비스에서 Jenkins를 이용한 CI/CD 환경을 구축하였었지만, 블로그 글들을 보며 따라했던 것이었고 1년이란 시간이 지나 머릿속에 남아있는 것이 없었다. 또한 우리의 ec2 인스턴스의 경우 t4g.micro 로 그렇게 좋은 성능의 인스턴스는 아니었고, 다른 팀들의 이야기를 들어보니 workspace와 빌드에 관한 캐싱작업이 발생하여 메모리 이슈가 있는 것 같았다.
결론적으로 Jenkins를 도입하기 위해 이에 대해서 공부하고 이를 실제로 적용하고 이슈를 해결하기에는 비용이 너무 많이 든다고 판단하였다.
그러던 중에 베루스가 아이디어를 내었다. develop 브랜치로 push 될 때, 우리 인스턴스로 curl 요청을 보내어 배포를 하는 방법이다.
즉, 우리의 develop 서버의 인스턴스에서는 소켓을 열어놓고 기다리는 프로그램이 동작하고 있고, 정해진 HTTP Method (GET) 와 정해진 경로로 요청이 오면 정해진 프로그램 (./deploy.sh 과 같은 배포 쉘 프로그램)이 동작하도록 하는 것이다.

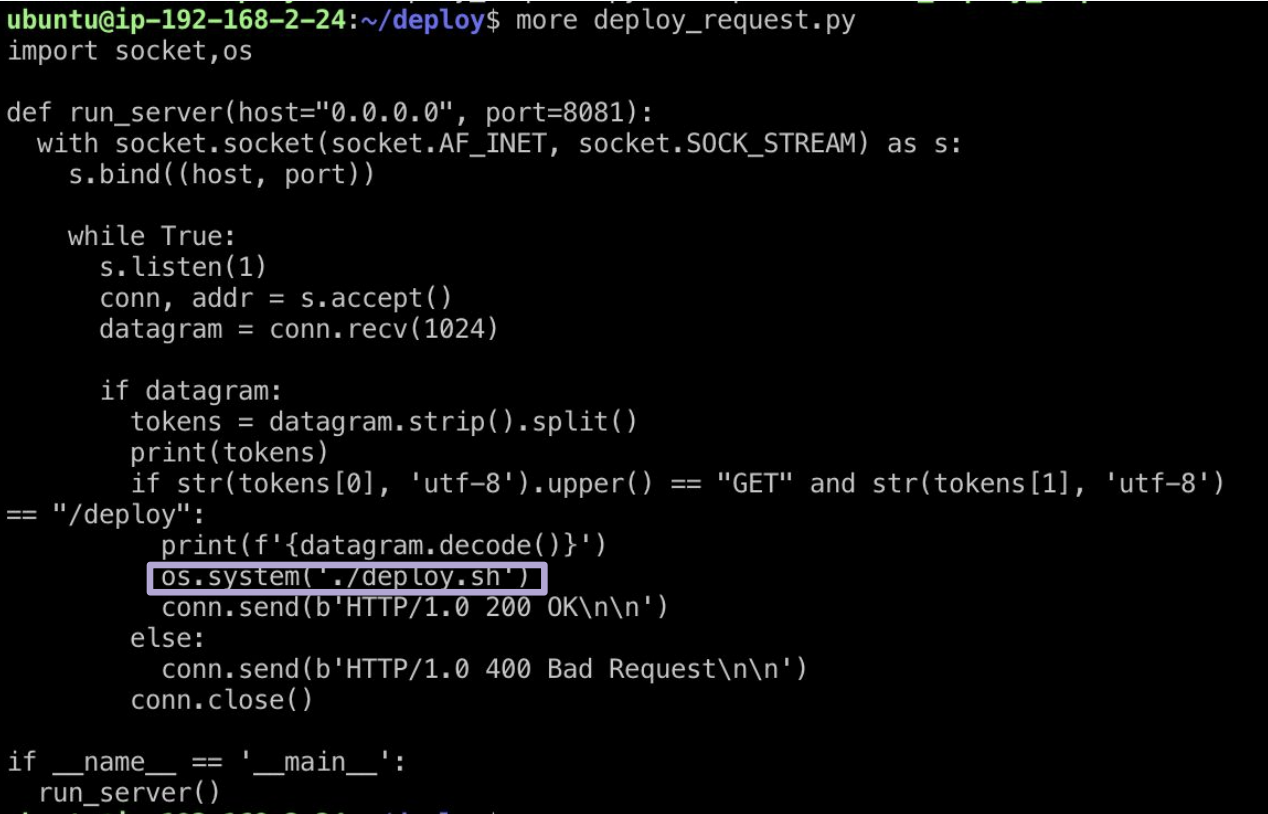
물론 보안적인 측면에 문제가 많긴하다. 코드에도 나와있다시피 우리가 정한 URL 인 /deploy 그리고 우리 서버의 IP 주소를 아는 사람은 모두 해당 요청을 보낼 수 있고, 의도적으로 많은 요청을 보내서 서버를 다운시킬 수도 있다.
따라서 우리는 해당 프로그램을 통해서 계속해서 지속적 배포 환경을 구축하겠다라고 하면 Authorization 헤더를 활용해볼 수 있을 것이고 간단하게는 우리가 정한 URL인 /deploy 를 우리만 알 수 있는 어려운 값으로 변경할 수도 있을 것 같다.
해당 지속적 배포 프로세스는 분명 Jenkins에 비해서 안정적이지 않다. 하지만 이렇게 직접 Github Actions와 소켓 프로그램을 작성해봄으로써 직접 CI/CD 환경을 구축하는 경험도 학습 측면에서 많은 도움이 되었다고 생각하고, 실제 서비스를 하게 될지는 아직 모르겠지만 필요에 의해서 Jenkins로도 충분히 업그레이드 할 수 있는 좋은 경험이었다고 생각한다.
태그를 통해 필터링해서 검색하기
이번 스프린트 동안 내가 맡은 업무는 다음과 같다.
- MySQL 위한 EC2 인스턴스 생성 및 세팅
- 스터디 상세 정보 조회
- 태그로 스터디 필터링해서 검색
- 태그 목록 조회 및 검색
- 스터디 후기 조회
그 중 가장 기억에 남는 것은 혼자 맡아서 진행하였던 태그로 스터디 필터링해서 검색 하기 부분이다.
해당 기능에 대한 요구사항은 다음과 같다.
- "스터디 제목 뿐 아니라 태그를 통해서 필터링을 할 수 있어야 해요."
- "태그는 각각 카테고리를 가지고 있어요. 예를 들어 1기, 2기 와 같은 기수 카테고리, 그리고 BE,FE 와 같은 카테고리가 존재해요."
- "같은 카테고리의 태그끼리는 OR 조건으로 필터링 해주세요."
- "다만 서로 다른 카테고리의 태그 끼리는 AND 조건으로 필터링해야 해요!"
- "여전히 스터디 제목만으로 검색할 수도 있고, 필터링을 함께 혹은 스터디 제목으로 검색 없이 필터링만 할 수도 있어야 해요."
사용자는 태그를 선택할 수도 있고 안할 수도 있다. 즉, 제목만으로 검색하여 원하는 스터디를 찾을 수도 있다. 반면 검색은 없이 태그만을 통해서 필터링해서 원하는 스터디를 찾을 수도 있다.
여기서 더 나아가서 같은 카테고리의 태그만을 사용할 수도 있고, 서로 다른 카테고리의 태그를 활용할 수도 있다.
즉, 사용자의 상황에 따라 동적으로 쿼리를 날려 데이터를 조회해와야 하는 상황인 것이다. 따라서 나는 해당 문제를 이전에 공부하고 위아원 서비스를 만들면서 사용해본 경험이 있는 Querydsl을 적용하여 문제를 해결하였다.
이에 대한 자세한 내용은 동적 쿼리 작성하기라는 다른 포스팅에 기록해두었으므로 여기서는 생략하려고 한다.
엔티티 매핑
앞서 언급한 태그를 통해 필터링해서 검색하기 기능을 구현하면서 엔티티를 어떻게 매핑할 것인가에 대해서 굉장히 많은 고민의 과정을 거쳤다.
DB 테이블과 JPA엔티티를 어떤식으로 매핑할 것인가?
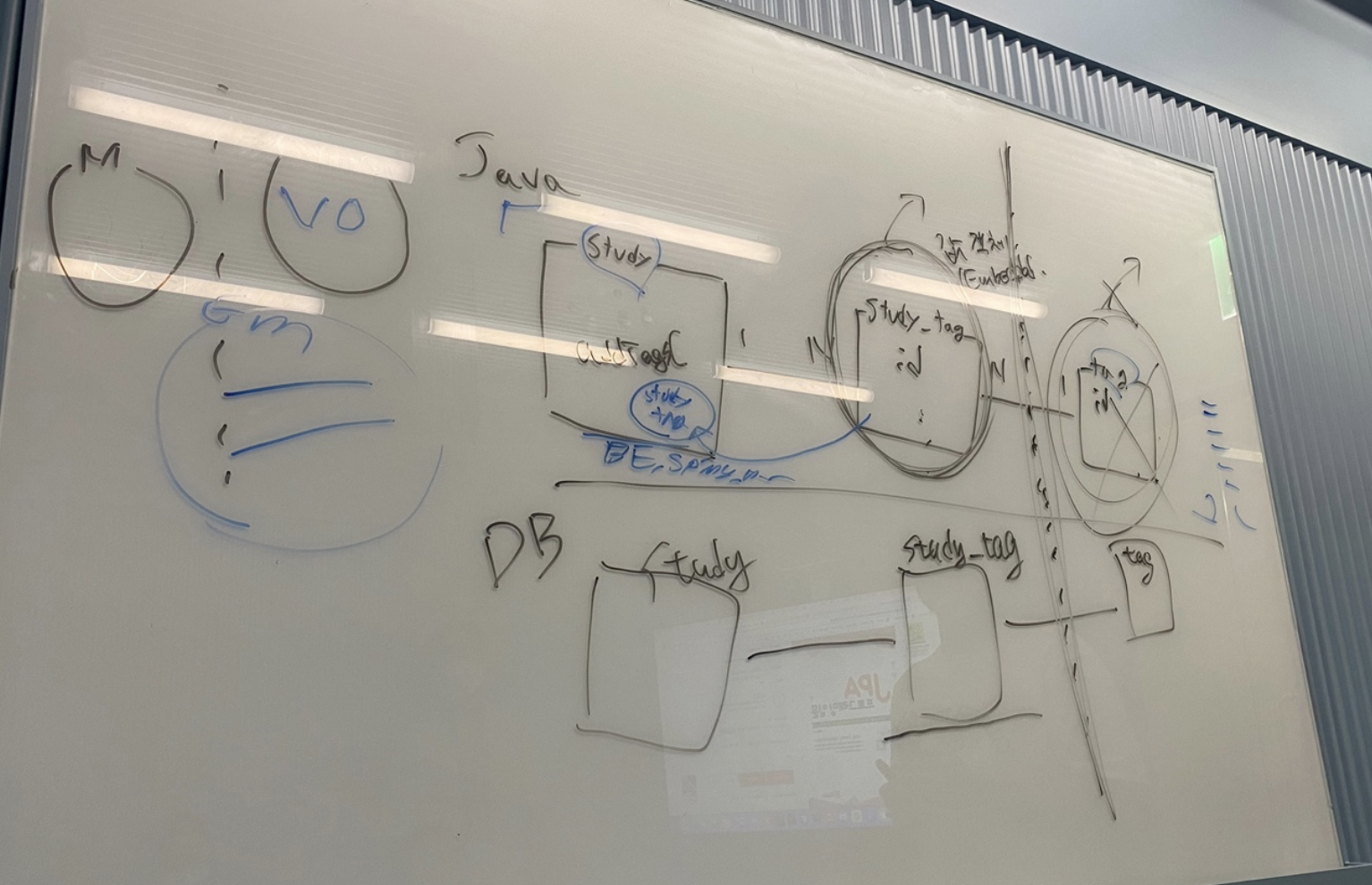
처음에는 다대다 매핑 (ex. study, study_tag, tag) 에 대해서 많은 의견을 나누었다. study_tag 라는 테이블을 엔티티로 매핑할 것이냐 아님 study쪽에 tag의 식별자를 가지는 식으로 테이블과의 매핑을 해결할 것인냐 하는 것이었다.
보다 자세한 내용은 동적 쿼리 작성하기 글에도 포함되는 것 같아 생략하고 결론만을 이야기하면 우선 내가 작업을 해야 하는데 식별자를 이용한 매핑 방법에 대한 경험은 없는 상태였기 때문에 엔티티로 매핑을 하여 Querydsl을 사용해 작업을 하였고, 향후에 식별자를 이용하는 방법으로 리팩토링 하기로 하였다. 그리고 그 이유는 아래 사진과 같이 ORM (Object와 Relation(DB table)의 매핑), 즉 객체는 객체대로, 테이블은 테이블대로 설계하기 위함인데, DB에 종속적인 StudyTag 라는 객체가 존재하는 것이 제대로된 ORM인가? 에 대한 의문으로 부터 시작해서 여러가지 이유로 식별자를 이용하기로 결정하였다.
스터디 상세 정보 조회
스터디 상세 조회는 그린론과 함께 진행하였다.
구현에서는 큰 어려움이 없었다. DB를 조회해서 필요한 데이터를 조합한 후에 API 명세에 맞추어서 반환만 해주면 되는 문제였다.
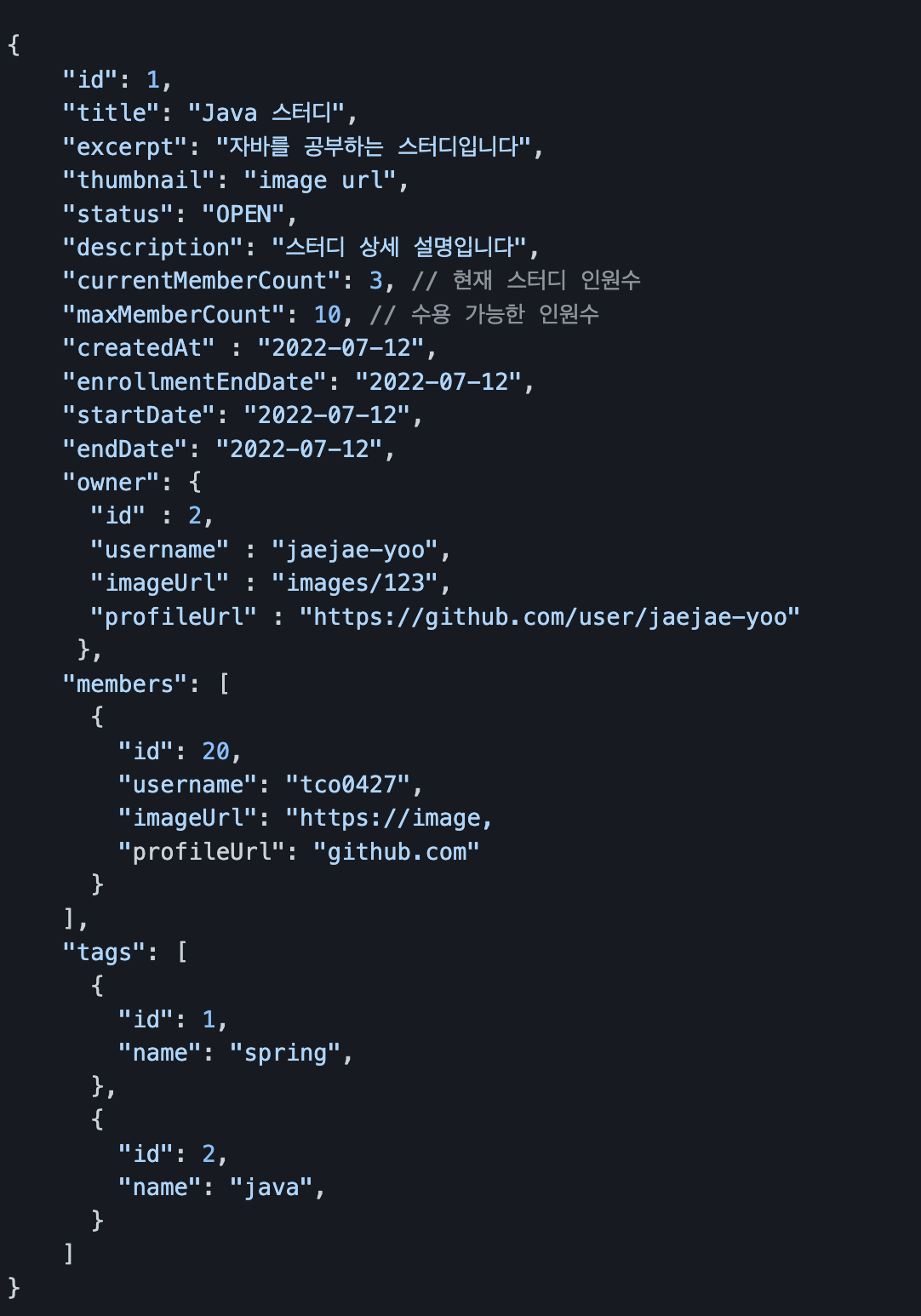
하지만 문제는 앞서 언급한 것과 같이 엔티티 매핑 에서 발생하였다. API 명세를 보아도 알 수 있다시피 우리는 현재 study, member, tag 이렇게 3가지 테이블을 조회하여야 한다. (연관관계 테이블 (ex. study_tag 는 생략))
심지어 study와 owner 관계에서 study, member 테이블은 1대1 매핑이지만 members(스터디원들) 과는 study가 다대다 매핑이다.
그린론과 이야기하며 점점 식별자 매핑에 관해서 의문이 들었다.
DB 테이블과 JPA 엔티티 방식에 대한 고민
우선 그린론과 함께 각자 식별자를 이용한 매핑방법에 동의한 각자만의 이유를 이야기해보았다. 공통적으로 연관관계를 끊어낼 수 있다는 점과 객체와 DB 패러다임의 불일치를 해결하는 더 좋은 방법이라고 생각하여서 동의하였다는 것으로 정리할 수 있었다.
그럼 어떤 의문점이 생긴걸까?
- 우선 memberId 와 같이
id라는 것도 DB에 종속적인 것 아닐까? - 연관관계를 위해서
Long memberId를 필드로 가지는 것이 객체지향적인 것일까? Member 객체를 직접 가지고 있는 것이 객체지향적인 것이지 않을까? memberId 라는 변수명을 통해서만 우리가 현재 그 의미를 파악하고 있는데, 만약 변수명이 바뀌면 어떻게 될까? 완전히 다른 의미가 되지 않을까? - memberId로 관계를 끊어낼 수 있다고 했는데, 왜 그래야 하지?
- study 와 tag 관계를 볼 때 study 가 tag 를 가지는 것이 자연스러운데, study 안에서 member를 관리하는게 적절할까? member와 study는 대등한 관계처럼 느껴지는데, 지금으로 봐서는 member가 종속적인 것 같다.
- 명령과 조회를 왜 분리해야 하는가?
위의 의문에 대한 답을 찾기 위해 해당 아이디어를 제시했던 베루스를 포함하여 백엔드 팀원 모두가 모여 회의를 진행하였고, 내가 내린 위의 의문에 대한 답은 다음과 같다.
-
먼저 memberId 라는
id를 DB에 종속적인 것이 아닌 도메인의 하나의 식별자 라고 생각해볼 수도 있을 것 같다. 예를 들어 Member 라는 도메인의 필드가 굉장히 많아지고, 이것을 모두 비교하는 eq & hc, 그리고 테스트 코드에서 모든 값을 비교하는 로직 대신에 Member 라는 도메인에id라는 유일한 식별자 필드를 하나 두고 이것이 같으면 다른 필드를 보지 않아도 같은 객체, 다르며 다른 객체라고 구분하는 필드라고 생각해보자.(마치 각각의 Object Instance의 주소처럼) 그럼 DB에 종속적인 것 만은 아니라고 볼 수 있다. -
이 부분에 대해서는 다음 코드와 같이 하나의 클래스로 감싸줌으로써 Type 이 생기고 이전에 변수명을 통해서만 그 의미를 파악하던 것에 비해 조금 더 확실해질 수 있을 것 같다. 현재는 study와 member 사이에서 participant(스터디 참여자)라는 의미로 member와 연관을 맺고 그 내부에 값으로
Long memberId를 갖는 것인데, 만약 review 와 member가 연관을 맺는다면 같은 Long타입의 memberId 라는 변수의 값으로 매핑을 하겠지만,Writer라는 클래스로 분류함으로써 보다 객체지향적으로 사고할 수 있게 된다.public class Participant { @Column(name = "member_id", nullable = false) private Long memberId; } -
다음으로 study 와 member 의 종속성(?) 인데, 우리의 주요 비즈니스는
스터디이고 그렇게 생각을 해보면 study안에 member가 종속적이라고 해도 크게 문제될 것이 없다는 생각이 든다. 그리고 또한 위에서와 같이Participant라고 한다면 Study에 종속적인 것이 맞고, 만약 Member안에 Study가 종속적으로 필요하다면 적절한 네이밍의 클래스로 한 번 감쌈으로써 그 의미를 확실시 해줄 수 있게 될 것이다. 자연스럽다. -
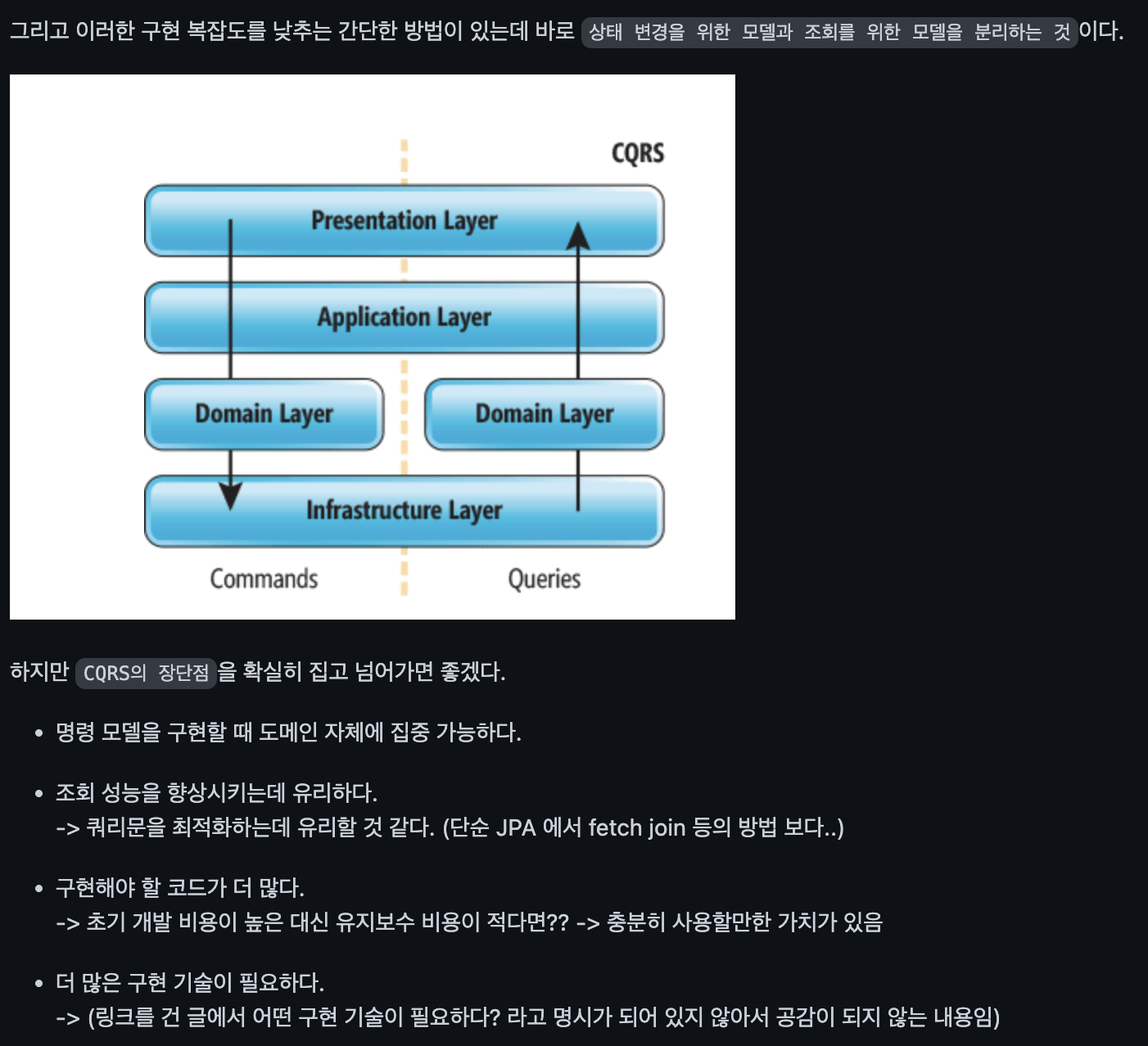
명령과 조회를 왜 분리해야하는지에 대해서는 아직 답을 찾지 못하였다. 하지만 본인이 Discussion에 올린 것 처럼 DDD와 CQRS 의 관계를 통해서 어느 정도 답을 구할 수 있을 것 같다.
스토리 포인트
이번 스프린트2 기간 동안 새롭게 도입한 사항 중 가장 마음에 들고, 팀원들 모두 만족하고 있는 사항이다.
가장 먼저 우리는 팀원 각자가 생각하는 우리 프로젝트의 기능들을 도출해보았다. 각자 생각하는 기능들에서 차이가 보이기도 했지만, 동일한 기능에 대한 생각도 서로 용어에서 차이가 발생하기도 하였다.

우리는 여기서 용어에 대한 일관성을 부여하고(차이가 나는 용어에 대해서 하나의 용어로 결정하여 팀원 모두가 이해할 수 있도록 하였다.), 공통되는 부분을 제거하여 결론적으로 다음과 같이 우리가 생각하는 프로젝트의 기능을 추려보았다.

여기서 Todo (해야 할 일), In Progress (진행 중인 사항), Done (작업을 마친 일) 로 나누어보았다.

그리고 스터디 전체 조회 를 기준 스토리로 정하고 총 0~8 점으로 사용자 스토리 포인트를 팀원들끼리 제안하고, 차이가 많이 나는 경우에는 조율하는 과정을 거쳤다.
이 때 모든 사용자 스토리에 대해서 포인트를 산출하는 것이 아니라 이번 스프리트에서 어떤 작업을 하면 우리 프로젝트가 사용자에게 가장 큰 가치를 제공할지를 염두해두고 스토리를 골랐으며 해당 스토리에 대해서만 스토리 포인트 산출 작업을 진행하였다.

결론적으로 우리가 이번 스프린트 때 해야할 일에 대한 스토리 포인트를 모두 산출한 이후 팀원 중 누가 어떤 작업을 할지를 결정하였고, 우리가 매일매일 자주 볼 수 있는 것도 해당 포스트잇을 붙였다.
(Github 의 Project 기능을 이용하여 칸반보드를 활용할 수도 있지만, 우리가 자주 볼 수 있는 곳에 붙여서 자주 상기하는 것이 우리가 우리가 사용자 스토리 포인트를 산출한 이유 중 하나이기도 하다.)
사용자 스토리를 추려내는 과정에서는 팀내에서의 용어 정리
를 할 수 있고, 각자가 생각하는 이번 프로젝트의 기능을 정리 하는 과정을 할 수 있어 좋았다.
사용자 스토리 포인트를 산출하는 과정에서는 우리가 해당 Task의 비용이 어느 정도이겠다 추측할 수 있어서 좋았고, 스프린트3에서 이를 기반으로 우리가 이번 스프린트 때 어느 정도의 작업을 할 수 있다 하는 기반이 되어 우리의 문화인 우리가 주체적으로 일정을 컨트롤 해보자를 지켜볼 수 있을 것으로 기대된다.
코드 리뷰
우아한테크코스를 시작하고, 레벨 1,2를 보내며 코드리뷰라는 문화에 익숙해졌다고 생각한다. 이제는 누군가가 나의 코드에 대해서 피드백을 주거나 의견을 주고 받는 과정이 즐겁다.
하지만 이번 팀프로젝트를 하면서 리뷰를 받는 입장에서만 코드리뷰를 경험하였고, 리뷰어로서 어떻게 리뷰를 주어야하는지, 다른 사람이 짠 코드를 어떻게 이해하면 좋을지에 대한 답을 구하지 못했다는 생각이 강하게 들었다.
그린론, 짱구가 구현해준 OAuth 관련 코드의 양이 많았고, 정해진 시간 내에 리뷰를 끝내서 크게 문제가 없으면 Merge를 하고 다음 작업을 이어가야 하는 상황이었다. 내가 리뷰를 해줄 때까지 해당 task를 잡고 기다릴 수 있는 상황이 아니었다.
하지만 내가 짠 코드가 아니니 우선 코드를 하나하나 이해하는데 한계가 있었고, 어떤 내용을 리뷰해주어야 할지 감이 잡히지 않았다.
[BE] issue50: 로그인 기능 구현
위의 PR 은 실제로 로그인 기능 구현에 대한 본인의 첫 리뷰 내용을 포함하고 있다.
처음에는 ./gitignore 파일과 같이 사소한 부분들도 꼼꼼이 보려고 노력했으나 구현양이 많고 리뷰해주기까지의 시간이 많이 있지 않다보니, product 코드보다 test 코드에 대해서는 조금 대충 보았다.
또 EOF 와 같이 문제가 있는 코드 부분에 대해서 피드백을 줄 때에는 머뭇거림이 없었지만, 뭔가 코드 자체에 대해서는 피드백을 줄 때에는 한 번 멈칫하게 되었다.
하지만 그래도 우리 프로젝트에 대한 욕심이 있어서 그런지 static import 나 extract 사용, Dirty Checking 으로 인한 불필요한 save 호출 등 에 대해서 최대한 많은 의견을 내려고 했고, 코드를 읽어가며 생긴 의문점에 대해서도 질문하였다.
그래도 리뷰를 받는 입장에 비해서 해주는 입장이 되어보니 어색하게 느껴지고 쉽지만은 않다는 느낌을 받았다.
그러던 중 코드 리뷰의 목적은 성장이어야 한다 라고 하는 글을 읽게 되었다. 우리가 코드 리뷰를 왜하는지에 대해서, 그리고 어떤 코드리뷰가 좋은 코드리뷰인지에 대해서 작성한 글이었다. 코드리뷰에 대한 경험이 많지 않고, 어떻게 리뷰를 해주면 좋을지에 대해서 고민하고 있던 나에게 좋은 글이었다. 특히, 질문도 리뷰 라는 문단은 생각보다 괜찮게 리뷰를 해주고 있구나라고 하는 약간의 자신감을 얻게해주었다.
조금 다른 맥락으로 우리는 Github PR 에 코멘트를 다는 것 이외에도 회의실에서 모여 자신이 작성한 코드에 대해서 다른 팀원들에게 설명해주고 질문을 받는 시간을 가지는데, 이러한 작업을 통해서 내가 짰던 코드에 대해서 다시 한 번 보게 되고 말하기를 함으로써 더 확실하게 기억하고, 서로의 생각을 자세히 들여다 볼 수 있었는데, 매우 가치있는 작업이었다고 생각한다.
마지막으로 스프린트2 동안 코드리뷰를 서로 해주면서 코드양이 많아 꼼꼼한 리뷰를 해주기가 쉽지 않다는 것을 팀원들 모두 느끼고 나서, 우리는 작업이 완료되지는 않더라도 매일매일 자신이 작성한 코드를 올려, 시간이 되는 팀원들은 그날 그날 작업한 내용을 확인할 수 있게 개선하기로 하였다.
아쉬운 점
Spring Rest Docs
스프린트2 기간 동안 Spring Rest Docs 를 적용하여 API 문서화를 자동화하려고 하였었다.
우리 팀에서 Spring Rest Docs를 선택한 이유
하지만, 이번 데모데이의 요구사항인 쉘 스크립트 또는 CI 도구를 활용한 배포 자동화 와 EC2 배포, 기능 요구사항을 구현하다보니 시간이 부족하여 해당 작업을 진행하지 못했다.
현재 우리팀은 Github Wiki 를 통해서 API 문서를 관리하고 있는데, 그러다보니 가끔 회의에서 나온 사항들이 문서에 반영되지 않거나 실제 Product 코드에서 주고 받고 있는 API와 문서에 명세되어 있는 API가 일치하지 않는 문제가 있었다.
(빠른 동기화가 되지 않는 문제)
이러한 경험을 하면서 빠르게 API 문서화를 자동화하고 싶다는 생각이 강하게 들었다.
그래서 개인적으로는 Spring Rest Docs에 비해서 비교적 간단하게 도입이 가능한 Swagger 라도 도입을 하고 Controller 프로덕트 코드에는 영향이 없게 Config 만 설정해둘걸 그랬나 하는 아쉬운 생각이 든다.
Jenkins
우리는 CI/CD 환경을 앞서 언급한 것과 같이 Github Actions와 파이썬 프로그램 을 이용하여 구축하였다.
그러다보니 Jenkins에 대해서는 학습할 기회가 없어졌다.
이러한 부분이 조금 아쉬운 부분으로 남는 것 같다. 물론 이 또한 학습하는 입장에서 굉장히 중요한 경험이라고 생각하긴 하지만 가장 대중적으로 많이 쓰이는 Jenkins 라는 툴의 사용을 경험해보지 못한 것이 이번 스프린트의 조금 아쉬운 부분으로 남는 것 같다.
잘한 점
사용자 스토리나 CI/CD 배포 환경 구축, 그리고 엔티티 매핑 방법 등 이전에 시도해보지 못한 방법으로 새로운 시도를 해본 것이 이번 스프린트동안 우리팀이 가장 잘한 경험이지 않나 생각이 든다.
특히 다른 팀들은 모두 Jenkins를 써서 CI/CD 환경을 구축하는 와중에도 우리팀만의 방식으로 CI/CD 환경을 구축했다는 점이 가장 뿌듯하다.
다음으로는 우리팀에서 주도적으로 (유일하게) 스토리 포인트를 산출해서 일정을 관리하고 있다는 점이 우리의 개발문화인 우리가 주체적으로 일정을 컨트롤하자 와도 부합하며 이번 스프린트 기간동안 잘한 점 중 하나인 것 같다.
마지막으로는 기존의 우리들에게 익숙한 엔티티를 통한 매핑이 아닌 식별자를 통해 매핑을 하면서 JPA를 활용하고, 우리 나름대로 조회와 CUD 의 분리가 필요한 이유를 찾아가고 있다는 점이 뿌듯하다.
우리가 조회와 CUD를 분리하는 이유에 대한 정리된 글이라 인용한다!
객체 지향으로 도메인 모델을 구현할 때 주로 사용하는 ORM 기법은 도메인의 상태 변경을 구현하는 데는 적합하지만, 여러 애그리거트에서 데이터를 가져와 출력하는 기능을 구현하기에는 고려할 것들이 많아서 구현을 복잡하게 만드는 원인이 된다.
DDD(Domain Driven Design)
