22년 10월 6일 오후 7시 경에 모아모아 서비스의 DB 가 DROP 되는 문제가 발생하였다.
물론 우리 모아모아 서비스가 실질적으로 매시간마다 트래픽이 발생하는 서비스가 아니기 때문에 크게 문제가 되지 않았지만 만약 실시간으로 트래픽이 발생하는 서비스였다고 하면 그리고 테이블에 고객들의 중요 정보가 담겨있었고, DB DROP 으로 인해 복구가 힘들었다면 큰 문제가 되었을 것이다. 따라서 해당 문제를 겪고 어떻게 복구하였는지 그리고 앞으로 이러한 일이 발생했을 때를 대처하기 위해 어떤 준비를 했는지 기록해보려고 한다.
문제 상황
먼저 문제 원인을 간단히 정리하고 가려고 한다.
간단히 설명해서 우리 main 아래 존재하는 application.yml이 spring.sql.init.mode 가 always 로 관리되고 있었고, 서버쪽에서는 별도의 application.yml을 작성해 관리해주고 있었다.
이와 같이 해줄 수 있는 이유는 다음과 같다.
일반적으로 외부 설정 파일인 application.yml(application.properties) 는 환경 변수, java 명령어 argument 등 키&값의 형태로 정의되어 있는 다양한 외부 설정을 지원하는데, application.yml의 경우 가장 구체적이고 가까운 위치에 있는 설정의 우선순위가 높다.
참고: 백기선님의 우아한 스프링 부트

즉, 위의 설정보다는 위치적으로 더 가까운 아래의 설정이 먹히게 되었는데 해당 부분이 always 로 설정이 되어 있었다.
기존에 우리는 init mode 가 always 였고, "/exec/config" 부분에 별도로 application.yml을 작성해주고 있어 이제까지 문제가 되지 않았던 것이다. 그런데 이를 간과하고 "/deploy" 아래 있는 즉 배포된 application.yml을 복사하여 실행시켰고, DB DROP 으로 이어지게 된 것이다.

베루스와 내가 함께 배포하고 있었는데 한동안 원인을 찾지 못했다. 왜냐하면 모든 테이블이 드랍된 것이 아니었기 때문에 배포 과정에서 문제가 생겼다고 생각했기 때문이다.
모든 테이블이 드랍되지 않은 이유는 구체적으로는 잘 모르겠지만 아마 foreign key 제약 조건 등으로 인해서 드랍되지 않았다고 판단하였다.
그나마 다행인 것은 우리에게 있어서 가장 중요한 데이터는 member 즉 회원 데이터와 함께 스터디에 기본적인 정보를 담고 있는 study 테이블 그리고 스터디에 게시판, 공지사항과 같은 중요한 글들이 담긴 notice, community 였다.
다행히도 study와 member 와 같은 테이블은 남아있었지만 notice, community 등은 모두 데이터가 날라가 있는 상태였다.
그렇지만 이 또한 문제가 되지 않은 것은 우리가 이번 배포에 포함했던 내용이 기존에 notice, community 테이블을 하나로 합치고 type을 통해 구분하게 되면서 새롭게 만든 article 테이블을 추가하게 되었고 해당 테이블은 DROP되지 않았다는 것이다.
우리는 해당 테이블로 데이터를 옮기기 위해서 notice, community 를 살려둔 상태에서 해당 데이터를 복제해서 article 테이블로 옮겨둔 상태였기 때문에 notice 와 community 테이블이 DROP 된 것이 큰 문제가 되지 않았다.
binary log 를 통한 복구
해당 문제를 해결하기 위해서 여러가지 방법을 모색하던 도중에 binary log 를 통한 복구 방법이 있다는 것을 알게 되었다.
Mysql 은 log-bin 옵션이 활성화 되어 있으면 주기적으로 binary log를 남기며 해당 로그에는 create, drop 과 같은 DDL 분만 아니라 insert 등과 같은 MDL 문등에 대한 이벤트들이 기록되어 있다.
이러한 로그 파일은 다음과 같이 조회해볼 수 있다.
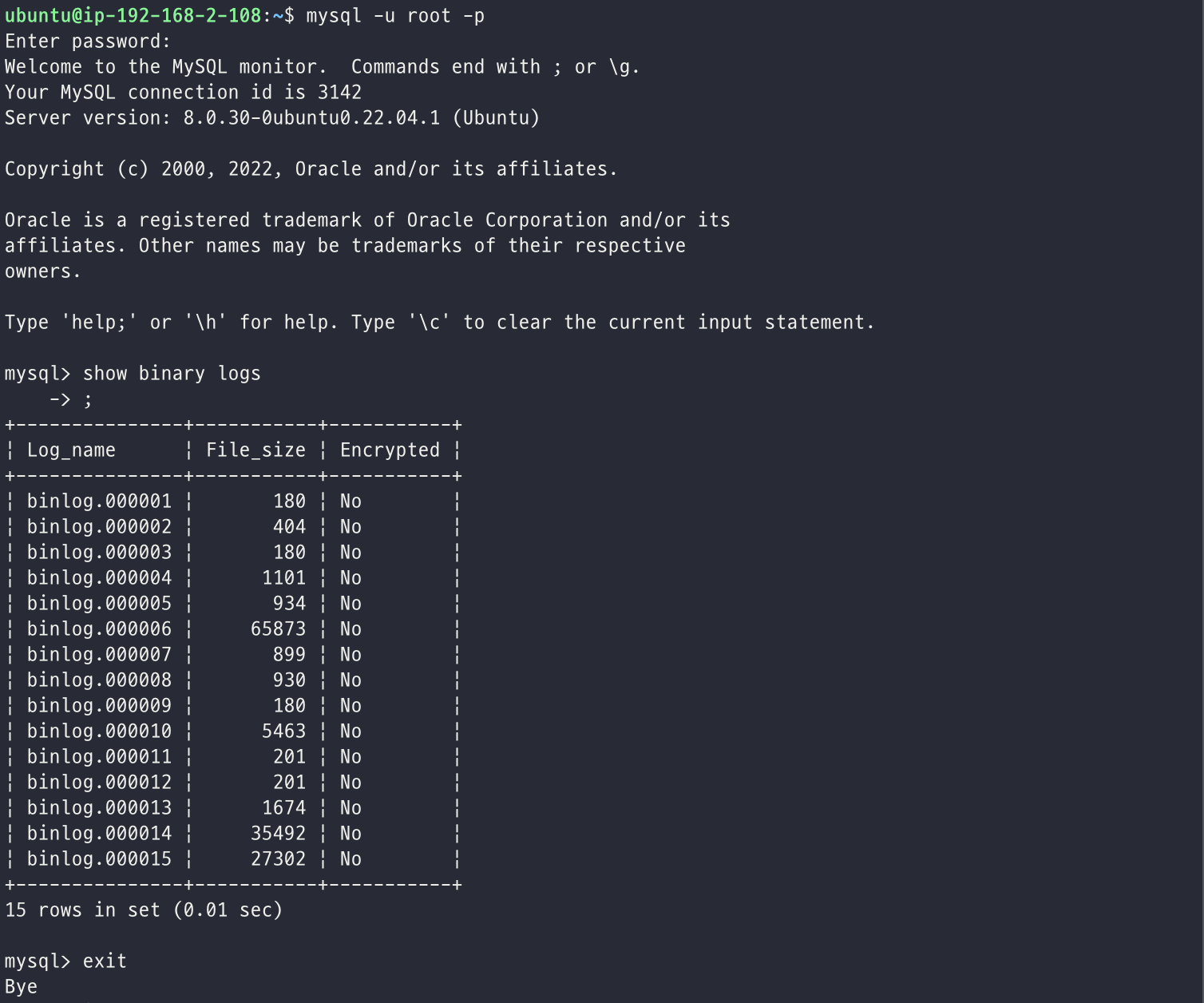
그런데 여기서 치명적인 실수를 했다. 이와 같은 상황에 처음 놓여보았기 때문에 당황한 마음에 급하게 복구하려는 데에만 집중하고 있었고, 참고한 블로그의 명령어를 따라서 작성하고 있었는데 다음과 같은 명령어를 작성해버린 것이다.
purge master logs to 'binlog.xx';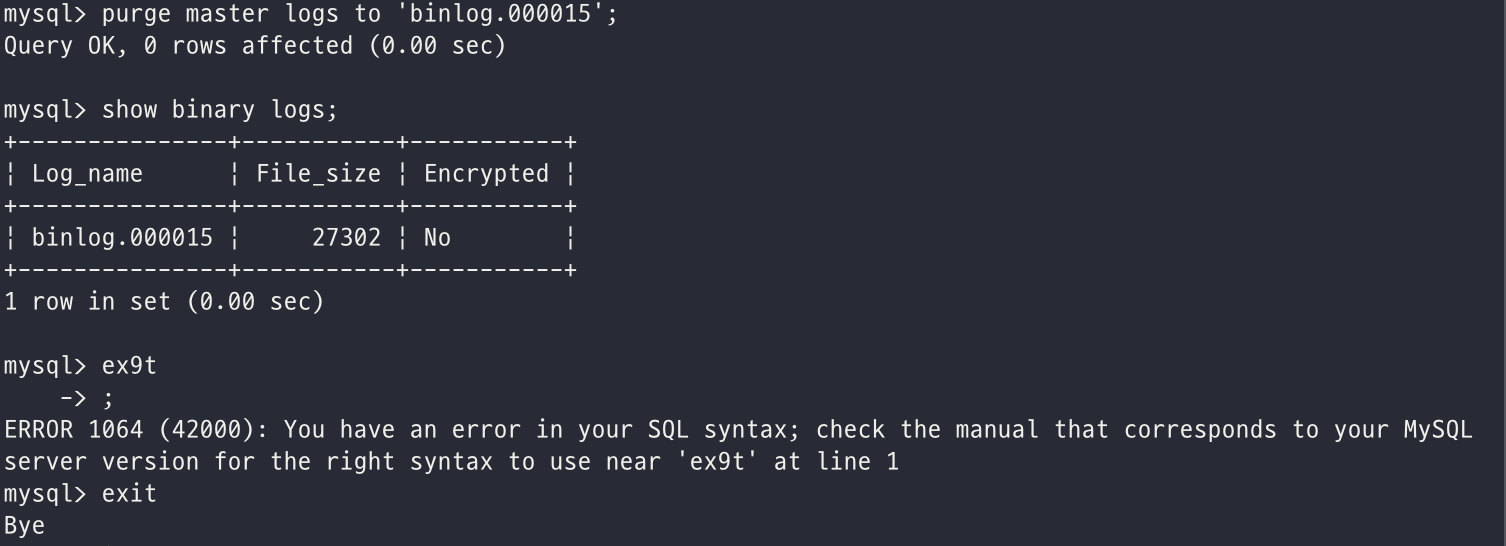
위 명령어는 binlog 뒤에 오는 번호를 통해서 해당 로그 이전 데이터를 모두 지우는 명령어다...나는 binlog.000015 를 입력해서 14번까지의 binlog 들이 모두 지워졌다.
purge의 제거하다라는 뜻이 있다는 것만 알았어도 이런일이 발생하지는 않았을 텐데..
따라서 mysqlbinlog 유틸리티를 이용해서 바이너리 로그를 통한 복구도 불가능해지게 되었다. 일반적으로 해당 유틸리티를 이용해서 모든 DB 데이터를 복구할 수 있는데, 이 경우에는 최초 DB가 실행되던 시점부터 정상적으로 기록되어 있는 경우에만 사용할 수 있다. 하지만 나는 앞서 보인 것과 같이 이미 파일들을 모두 날렸기 때문에..해당 방법으로 제대로 복구할 수 없었다.
mysqlbinlog binlog.000015 > textlog.sql
mysql -uroot -p < textlog.sql결국 나는 수작업으로 복구를 진행해주었다. 앞서 언급한 것과 같이 중요한 테이블의 데이터는 모두 살아있어 다행이었지만, study와 member 사이의 다대다 연관을 풀어내기 위해서 존재했던 study_member 테이블과 같은 테이블은 모두 드랍된 상태였고, 따라서 특정 스터디 조회시 스터디에 참여한 회원 수는 6명이지만 누가 참여했는지 확인할 수 없는 문제가 발생하였다. (스터디의 방장을 제외하고는 study_member 테이블이 DROP 되어 조회할 수 없었다.)
다행히 현재 우리 서비스는 우아한테크코스 4기 크루들을 대상으로 운영되고 있었기 때문에 일일이..크루들의 양해를 구해서 스터디원을 확인하고 직접 member 테이블에서 id를 보고 넣어주는 식으로 복구를 진행해주었다.
백업의 필요성
이전에 ddl-auto 의 create 속성 등과 같은 설정으로 인해 Production DB 가 드랍될 수 있으므로 주의를 요한다 라는 말을 JPA 강의나 책에서 많이 보았던 기억이 난다. 해당 글이나 강의를 들으면서 누가 이런 실수를 할까? 실제로 일어나긴 하는 걸까? 하며 이러한 휴먼 에러를 간과하던 나 자신이 기억이 난다.
하지만 이번 배포에서 ddl-auto 로 인한 문제는 아니었지만 init-mode 와 같은 비슷한 옵션으로 인해서 같은 문제를 겪게 되었고, 물론 이번에는 운이 좋아서 크게 문제가 되지는 않았지만 또 이러한 실수를 안할까? 에는 의문이 들었다.
따라서 나는 위와같은 문제를 겪고 나니 DB 백업에 대한 필요성을 절실히 느끼게 되었고, 해결방법을 모색해보았다.
내가 생각해낸 방법은 주기적으로 DB의 현재 상태를 백업 떠두는 것이다. 그리고 만약 문제가 발생하면 가장 최근에 백업을 해두었던 상태로 되돌려 일부 데이터(백업을 떠둔 이후 시점)는 손실이 나겠지만, 일관성을 유지하고 있는 특정 상태로 되돌릴 순 있게 된다. (앞서 이번에 내가 했던 복구는 study, member 테이블은 잘 살아 있었지만, study_member 테이블은 모두 드랍되었고, 손수 일일이 데이터르 집어넣어 주었다. 즉, DB의 일관성이 지켜지지 않는 상태로 복구한 것이다.)
다행히 아이디어는 금방 떠올랐다. 리눅스에서 제공하는 시간 기반의 스케쥴러인 crontab 과 mysqldump 명령을 이용하여 주기적으로 특정 시간마다 db 의 테이블들을 dump 떠 놓는 것이다.
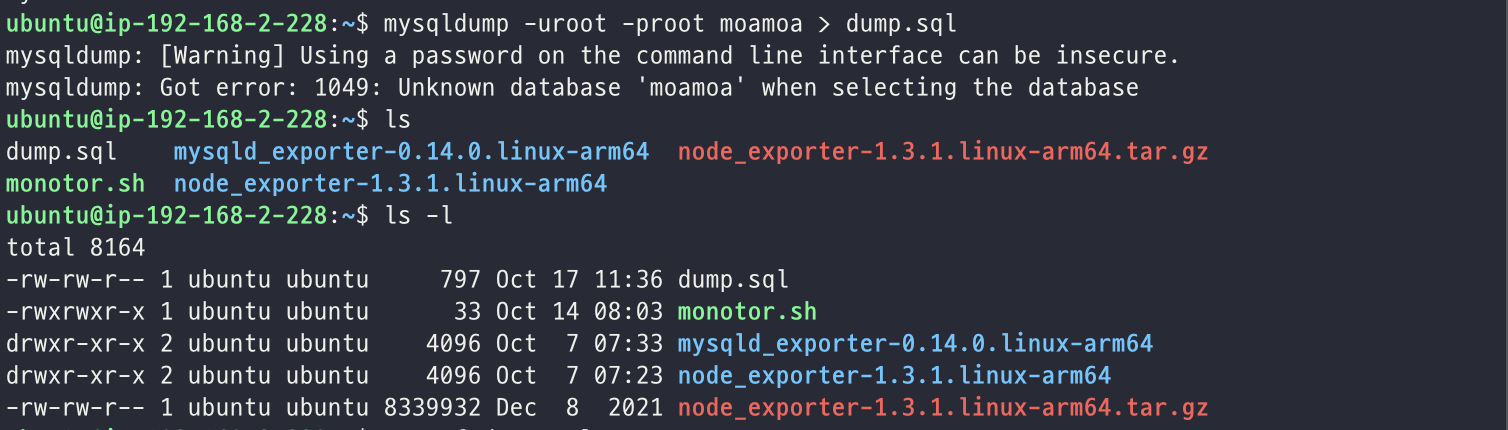
우선 mysqldump 명령어가 제대로 동작하는지 확인해보았다.
mysqldump -uroot -proot moamoa > dump.sql위 명령어를 실행한 이후에 ls 를 통해서 dump.sql 파일이 제대로 생성된 것을 확인해볼 수 있었다.
이후에는 crontab을 이용해서 주기적으로 mysqldump 명령어가 동작할 수 있도록 쉘을 작성하였다. (쉘 스크립트 작성에는 미숙해서 구글링을 통해서 필요한 쉘 스크립트를 가져왔다.)

DATE는 현재 날짜를 가져와 할당하는 것이고, BACKUP_DIR 은 백업을 떠둔 파일을 저장할 디렉터리 위치이다.
나는 mysqldump 명령어를 앞서 지정해둔 BACKUP_DIR 밑에 현재 날짜를 포함한 파일을 만들어 저장해 둘 수 있도록 쉘을 작성하였다.

그리고 앞서 작성한 쉘을 crontab을 통해서 등록해주었다.
매일 00시마다 해당 쉘을 동작시키도록 하였다.
그런데 문제는 이렇게 매일 dump를 뜨게 되면 한달만 지나도 30개의 파일이 생성된다는 것이다. 그리고 만약 문제가 발생해 되돌리게 된다면 하루 전의 dump를 떠둔 파일로 되돌리지 25일 전 상태로 되돌릴 것 같지는 않았다. 즉 시간이 지남에 따라 불필요한 dump파일들이 많아지는 문제가 있었다.
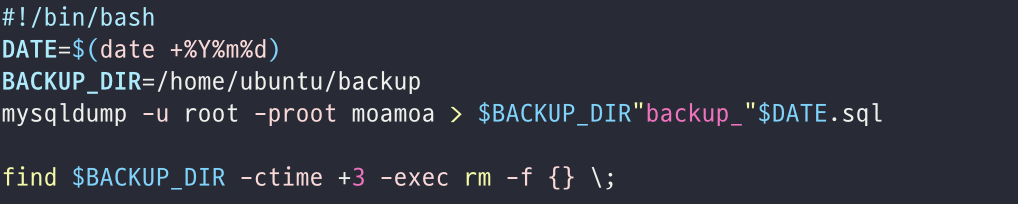
다행히 구글링을 조금 더 해보니 3일 이상된 파일에 대해서 제거를 해주는 방법이 있었고, 위와 같이 마지막 줄에 BACKUP_DIR 에서 3일 이상된 파일을 제거해주는 명령어를 추가하여 많으면 최대 3개 파일만 저장해놓고 관리할 수 있도록 해줄 수 있었다.
DB Replication
사실 위의 crontab 방법을 제일 처음 떠올린 것은 아니었다. DB 백업, 복제 하면 가장 먼저 떠오르는 것이 DB Replication이기 때문이다.
하지만 Replication 을 통해서는 앞서 만났던 문제를 해결할 수 없었다. Replication 은 말그대로 DB 를 복제하는 것으로 동기화를 맞추기 위해서 Replica 서버에서 Source 서버를 추적하며 동기를 계속해서 맞추게 되는데, 여기서 문제가 발생한다.
만약 Source 서버가 DROP 을 하게 되면 Replica 서버도 함께 DROP을 하게 되는 것이다. 즉 내가 원하는 백업을 할 수는 없게 되는 것이다. 따라서 앞선 crontab 방법을 고려하게 된 것이다.
하지만 이번 문제를 겪고 Replication 에 대한 필요성도 느껴볼 수 있었다.
DROP 이 아닌 Source 서버 자체가 먹통이 되면 어떻게 하지? Mysql의 로컬(세션) 메모리 영역으로 인해 메모리가 부족해져서 서버가 멈출 수도 있고, 화재등으로 인해 내가 사용하는 EC2 서버가 생각보다 장시간 먹통이 될 수도 있다.
그런데 이 때, 별도의 IDC에 기존 Mysql 서버를 복제해둔 서버가 있다면 WAS가 해당 DB를 바라보도록 수정해줌으로써 쉽게 서비스 복구가 가능해지게 된다.
(물론 우아한테크코스에서 제공해주는 AWS 지원에는 한계까 있기 때문에 별도의 다른 IDC에 복제를 구축해보지는 못했다.)
따라서 나는 앞서 crontab을 등록하면서 함께 레플리카 서버도 구축하게 되었다.
싱글 레플리카 복제 구성
보통은 레플리카 구성이라고 하면 CUD 와 R 의 분리, 즉 Source 서버를 통해서 CUD를 수행하고 조회에 대한 부하는 Replica로 분산시키는 방법을 떠올린다. (일반적인 웹 서비스의 부하를 고려해보면 CUD보다 조회에 대한 요청 빈도가 훨씬 많으며 그렇기 때문에 우리가 CUD 성능을 포기하더라도 DB Index 를 등록해 조회 성능을 높이는 이유도 같은 이유이다.)
그런데, 내가 레플리카를 구성하려고 한 목적은 이와는 다르다. 현재 우리 서비스는 충분히 DB 한대로도 원하는 응답시간(100ms) 에 부합하는 응답을 보내주고 있으며 아직까지는 성능상 부하를 분산시킬 필요성을 느끼지 못했다.
내가 레플리카를 구성하려는 이유는 Source 서버가 어떠한 이유가 장애가 발생하였을 때 이를 위한 대비책으로 만들어 두려는 것이었고, 따라서 싱글 레플리카 복제 구성 이면 충분했다.
그럼 다음과 같은 질문을 할 수도 있을 것 같다. 싱글 레플리카 복제 구성 이어도 CUD와 R에 대한 부하를 분산시킬 수 있지 않나요? Source 서버로 CUD 요청을 보내고, Replica에 R 요청을 보내도록요!
여기에 대한 답은 RealMySql8.0 책의 16장에 나와있다. 책의 내용을 비려 답해보면 다음과 같다.
싱글 레플리카와 같은 복제 형태에서는 보통 애플리케이션 서버는 소스 서버에만 직접적으로 접근해 사용하고 레플리카 서버에는 접근하지 않으며, 레플리카 서버는 소스 서버에서 장애가 발생했을 때 사용될 수 있는 예비 서버 및 데이터 백업 수행을 위한 용도로 많이 사용된다. 만약 이 같은 형태에서 애플리케이션 서버가 레플리카 서버에서도 서비스용 읽기 쿼리를 실행한다고 하면 레플리카 서버가 문제가 발생한 경우 서비스 장애 상황이 도래할 수 있다. 따라서 이렇게 소스 서버와 레플리카 서버가 일대일로 구성된 형태에서는 레플리카 서버를 정말 예비용 서버로서만 사용하는게 제일 적합하다고 할 수 있다.
즉, 레플리카 서버로 조회에 대한 부하를 분산시켜 WAS 에서 레플리카 서버로 읽기 쿼리 요청을 보내게 되면 레플리카 서버가 문제가 발생했을 때 대비책이 없다는 것이다. 일반적으로 여러대의 Replica 서버(최소 2개 이상)를 구성하게 되면 한 대의 Replica 서버가 장애가 나면 다른 Replica 서버를 사용하면 된다. 하지만 지금과 같이 싱글 레플리카 복제 구성일 때는 대비가 없다는 것이다.
물론 싱글 레플리카 복제 구성에서도 Source 서버가 장애가 나는 경우에 대해서는 Replica 서버를 Master 로 승격시킴으로써 문제가 해결 될 수는 있다. (물론 내 생각에 이 경우에도 Replica 서버가 Master로 승격되면 조회 쿼리는 또 다른 Replica 서버를 필요로할 텐데 어떻게 해결하지? 와 같은 의문이 들기는 한다.)
구축 과정
앞서 레플리카 서버를 도입하는 이유 그리고 여러가지 구성 방법 중 싱글 레플리카 복제 구성 을 선택한 이유와 이렇게 구축함으로써 쿼리를 분산시키지 않은 이유에 대해서 설명하였으므로 이제 실제로 어떻게 레플리카 서버를 구축하였는지에 대해서 정리해보려고 한다.
그 전에 복제 아키텍쳐에 대해서 정리하자. (내용은 Real MySQl8.0 을 참고하였습니다.)
복제 아키텍쳐
앞서 언급한 것과 같이 MySQL 서버는 서버에서 발생하는 모든 변경 사항은 별도의 로그 파일에 순서대로 기록하게 되며 이를 Binary Log 라고 한다. (이는 데이터의 변경과 관련된 내용 뿐 아니라 계정이나 권한에 대한 변경 정보까지 모두 저장된다.)
복제도 binary log 를 이용해서 이루어지게 되는데 소스 서버에서 생성된 바이너리 로그가 레플리카 서버로 전송되고 레플리카 서버에서는 해당 내용을 로컬 디스크에 저장한 뒤에 자신이 가진 데이터에 반영하는 식으로 데이터 동기화가 이루어진다.
여기에 사용되는 쓰레드는 소스 서버의 바이너리 로그 덤프 쓰레드, 레플리카 서버의 레플리케이션 I/O 쓰레드 와 레플리케이션 SQL 쓰레드 가 사용된다.
일반적으로는 로그 파일 위치 기반의 복제를 많이 사용하게 되는데 레플리카 서버에서 소스 서버의 바이너리 로그 파일명과 파일 내에서의 위치를 기반으로 로그 이벤트를 식별해서 복제가 진행되는 형태를 말한다.
처음 구축할 때는 레플리카 서버에 소스 서버의 어떤 이벤트부터 동기화를 수행할 것이낙에 대한 정보를 설정해주어야하며 레플리카 서버는 소스 서버의 어느 이벤트까지 읽어왔고 적용했는지를 관리하게 된다. 따라서 소스 서버에서는 각 이벤트에 대한 식별이 반드시 필요하다.
일반적으로 이벤트 하나하나를 바이너리 로그 파일명과 파일 내에서의 위치 값(File Offset)의 조합으로 식별한다.
이제 실제로 구축을 진행해보자. 우선 복제 구성원들은 각 MySQL 서버가 고유한 server_id 값을 가져야한다. (8.0부터는 바이너리 로그가 기본적으로 활성화되어 자동으로 생성된다.)
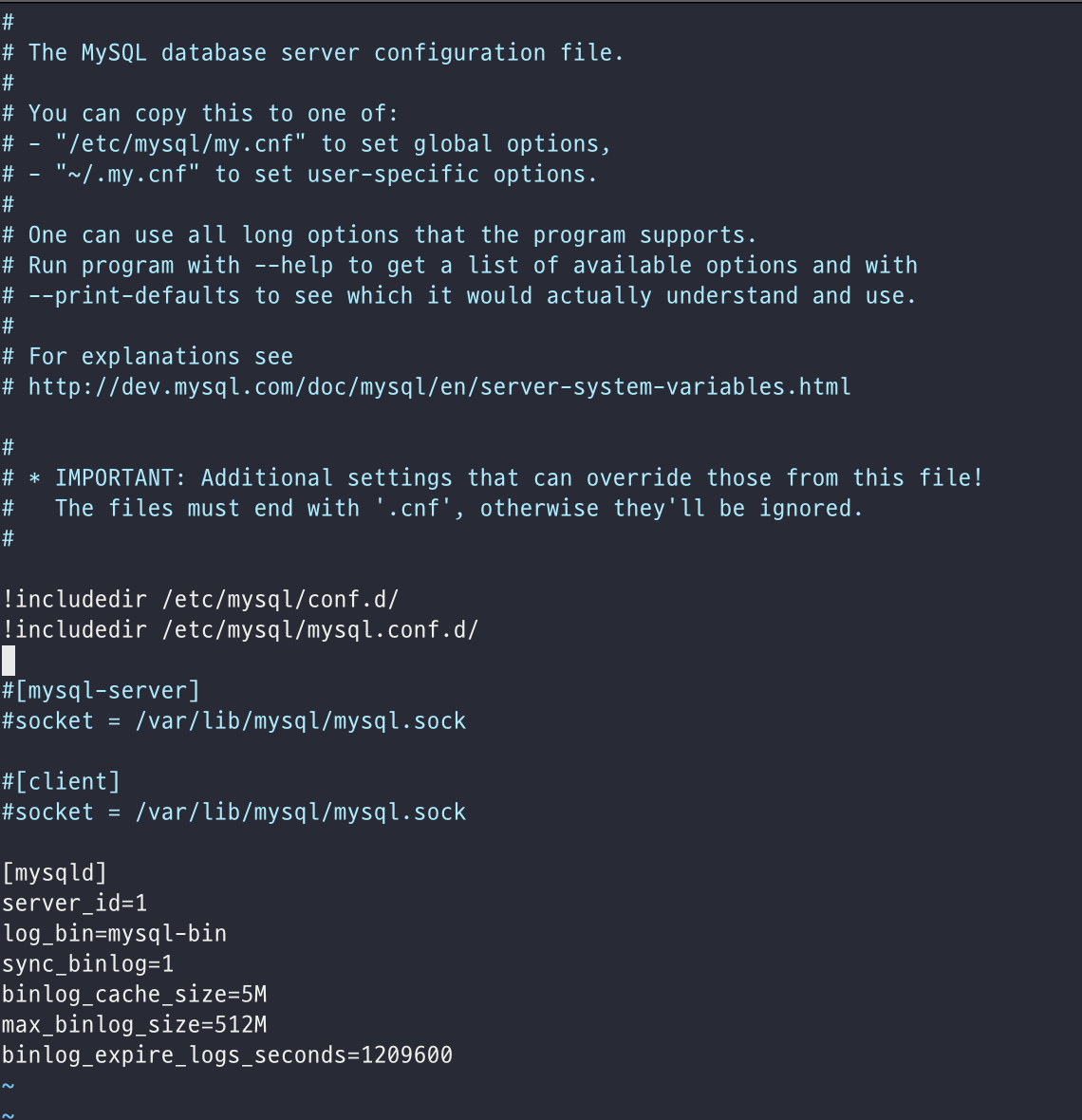
따라서 Source 서버의 configuration file 의 설정을 다음과 같이 해준다.
여기서 log_bin은 로그 파일이 기록될 로그 파일 위치나 파일명을 설정해준 시스템 변수이며 바이너리 로그 캐시 사이즈와 바이너리 로그 동기화 방식 그리고 최대 바이너리 로그 파일 크기 등을 설정해주었다.
Mysql 서버가 어떤 경로의 config file을 우선순위로 해서 설정하는지는 mysql --help 를 통해서 다음과 같이 확인해줄 수 있다.

mysql 버전도 중요한데 레플리카 서버가 소스 서버보다 버전이 높거나 같아야 한다.
나의 경우에는 동일한 버전을 사용해주었다.

소스 서버에서 바이너리 로그가 정상적으로 기록되고 있는지는 다음과 같이 소스 서버에 로그인해서 SHOW MASTER STATUS 명령어를 활용해볼 수 있다.

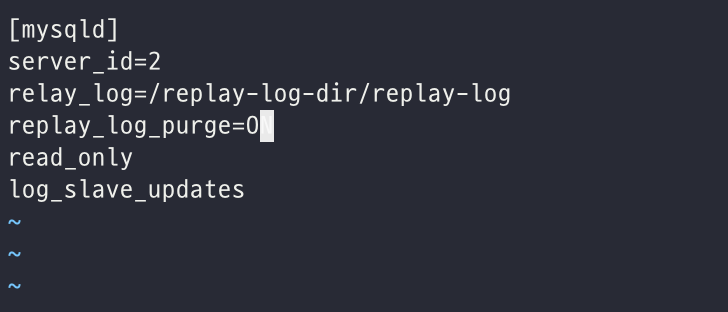
이제 레플리카 서버도 설정을 진행해보자. 앞서와 마찬가지로 server_id 를 지정해주는데 중복되지 않게 설정해야하므로 2라는 값을 주었으며 replay_log_purge 를 ON 으로 해주었다. 이렇게 되면 릴레이 로그에 기록된 이벤트가 레플리카 서버에 적용되면 더 이상 필요하지 않게 되고, 이렇게 필요없어진 릴레이 로그 파일은 레플리카 서버가 자동으로 삭제한다. 해당 시스템 변수를 OFF로 설정하는 경우에는 레플리카 서버의 디스크 여유 공간이 부족하지 않은지 꾸준하게 모니터링 해주는 것이 좋다.
또한 레플리카 서버에 혹시나 CUD 요청이 가는 것을 막기위해서 우선 read_only 설정도 추가해주었고, 추후 소스 서버의 장애로 이 레플리카 서버가 소스 서버로 승격될 수 있으므로 승격을 위해 log_slave_updates 설정도 추가해주었다.
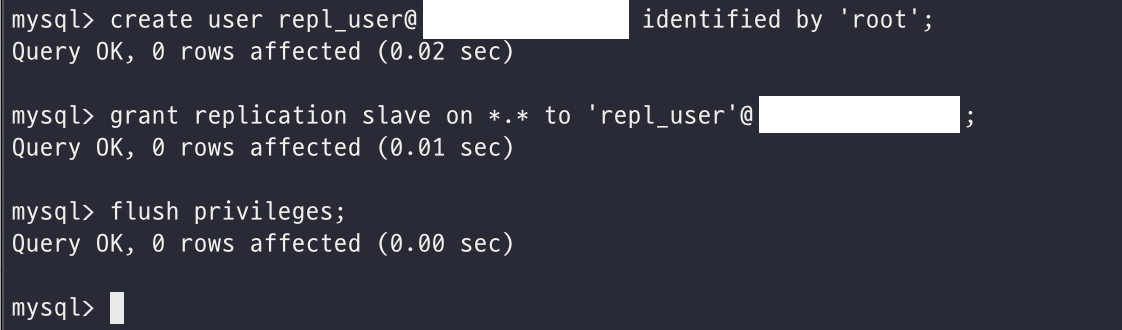
이제 레플리카 서버에서 소스 서버에 접속해서 바이너리 로그를 가져오기 위한 용도의 계정을 준비해주어야 하며 다음과 같이 유저를 생성하고 REPLICATION SLAVE 권한을 주고 flush 해주었다. 해당 권한은 복제에 사용되는 권한만 주는 것이다.
그리고 나서는 레플리카 서버를 소스 서버와 동기화를 해주어야하는데, 이 때 dump를 해주어야한다. 그리고 소스 서버의 데이터를 덤프할 때는 --single-transaction 과 --master-data 라는 두 옵션을 반드시 사용해주어야 한다. (이 부분을 모르고 있었어서 레플리케이션이 제대로 이루어지지 않아서 삽질을 좀 했었다....)
--single-transaction 옵션은 데이터를 덥프할 때 하나의 트랜잭션을 이용해 덤프가 진행되게 해서 mysqldump가 테이블이나 레코드에 잠금을 걸지 않고 InnoDB 테이블들에 대해 일관된 데이터를 덤프받을 수 있게 한다.
다음으로 --mstart-data 옵션은 덤프 시작 시점의 소스 서버의 바이너리 로그 파일명과 위치 정보를 포함하는 복제 설정 구문이 덤프 파일 헤더에 기록되게 하는 옵션이다.
mysqldump -uroot -p --single-transaction --master-data=2 --opt --routines --triggers --hex-blob --all-databases > source_data.sql
이를 scp와 같은 파일 전송을 이용해서 레플리카 서버로 옮겨준 후에는 다음 명령어를 통해서 레플리카 서버에 적재 명령을 실행해주었따.
mysql -uroot -p < /home/ubuntu/source_data.sql다음으로 본격적인 복제를 위해서 소스 서버의 호스트명과 포트, 복제용 계정등 복제 설정 명령을 입력해준다.
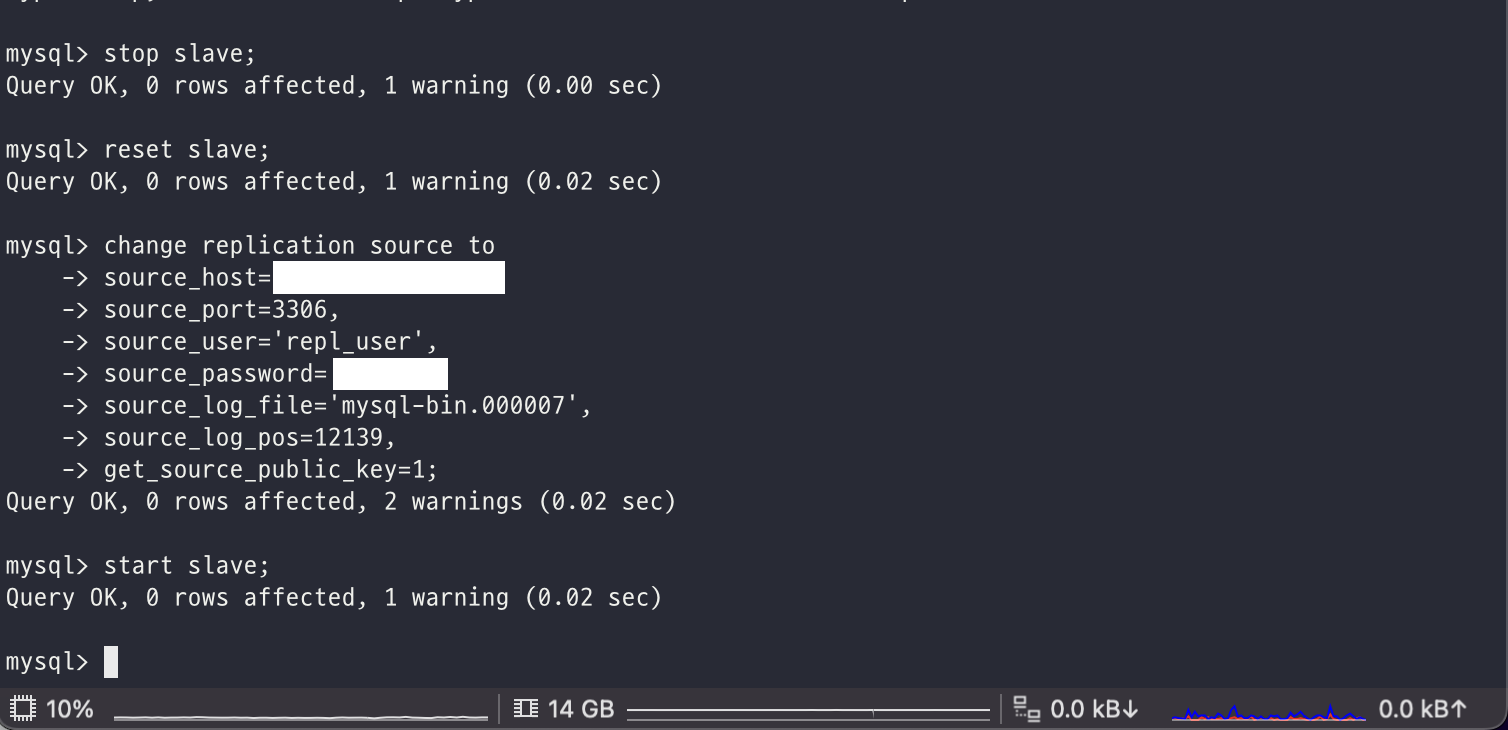
이전에 삽질을 한 영향으로 인해서 slave 초기화를 해준 것이고 처음 설정을 진행해주는 것이라면 change replication source 명령부터 시작하면 될 것이다.
여기에는 복제에 연결할 소스 서버의 정보와 함께 앞서 권한을 주었던 user 그리고 SHOW MASTER STATUS 명령으로 확인한 현재 소스서버의 바이너리 로그 파일의 위치를 입력해주면 된다.
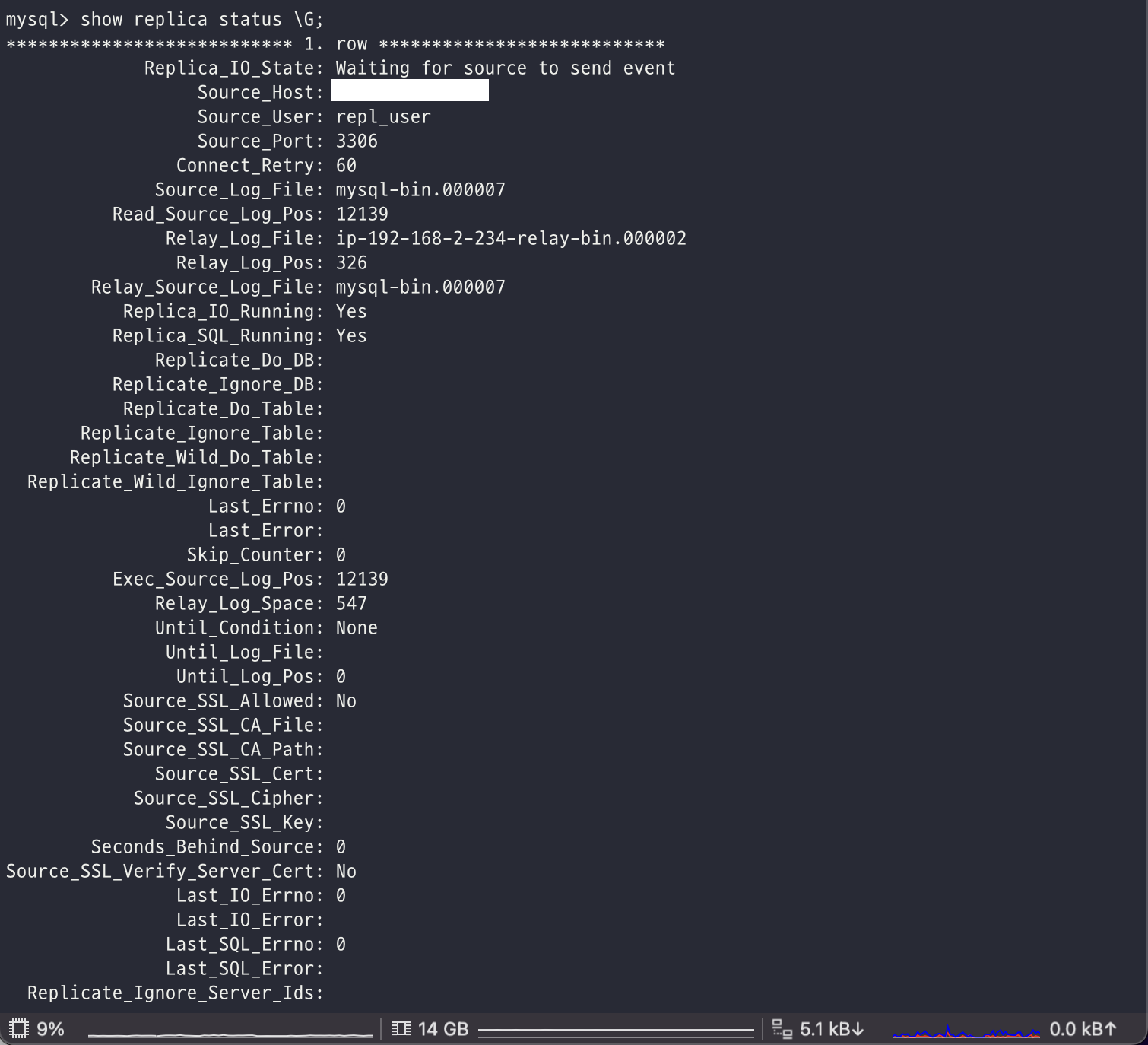
정상적으로 레플리케이션 설정이 되었다면 레플리카 서버에서 show replica status \G 명령을 통해서 확인해 볼 수 있는데, Replica_IO_Running 과 Replica_SQL_Running 이 Yes 인 것으로 봐서 복제 관련 정보가 등록되어 있고 동기화가 시작되었음을 알 수 있다.
만약 복제가 제대로 이뤄지지 않았거나 동기화를 위한 덤프를 앞서 보인 것과 같은 mysqldump 명령어로 수행하지 않은 경우에는 다음과 같은 에러를 만날 수 있으니 앞선 과정을 차근차근 다시 해보길 권장한다.


Source 서버에서도 마찬가지로 제대로 복제를 위해 연결이 되어 있는지를 다음과 같이 확인해볼 수 있다. (show processlist\G;)
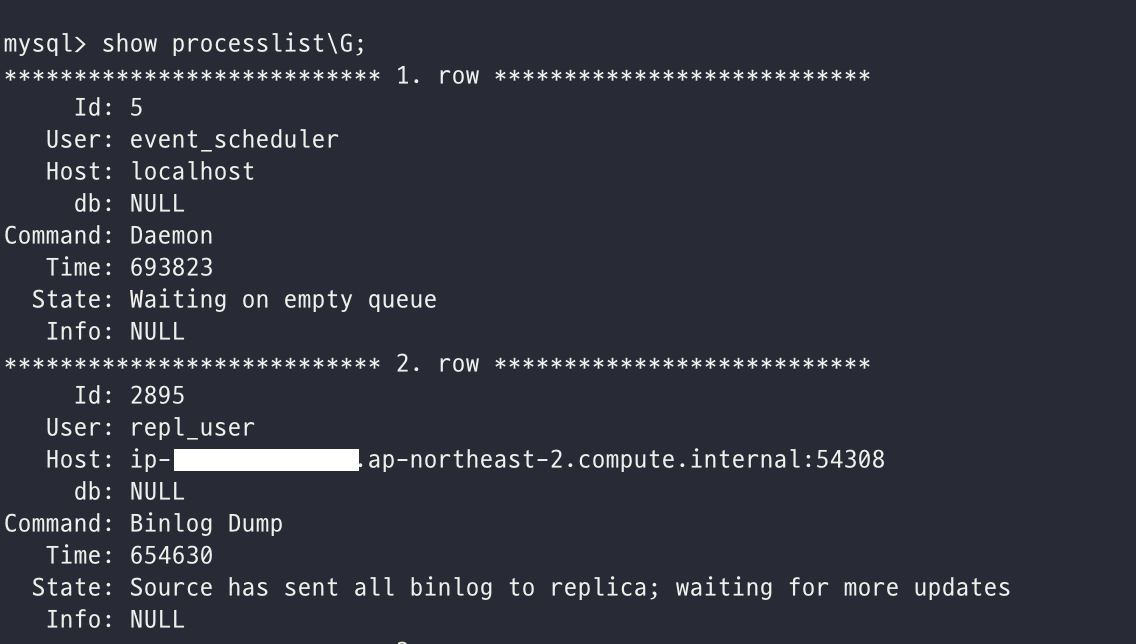
state에 Source has sent all binlog to replica; waiting for more updates 를 확인해볼 수 있다.
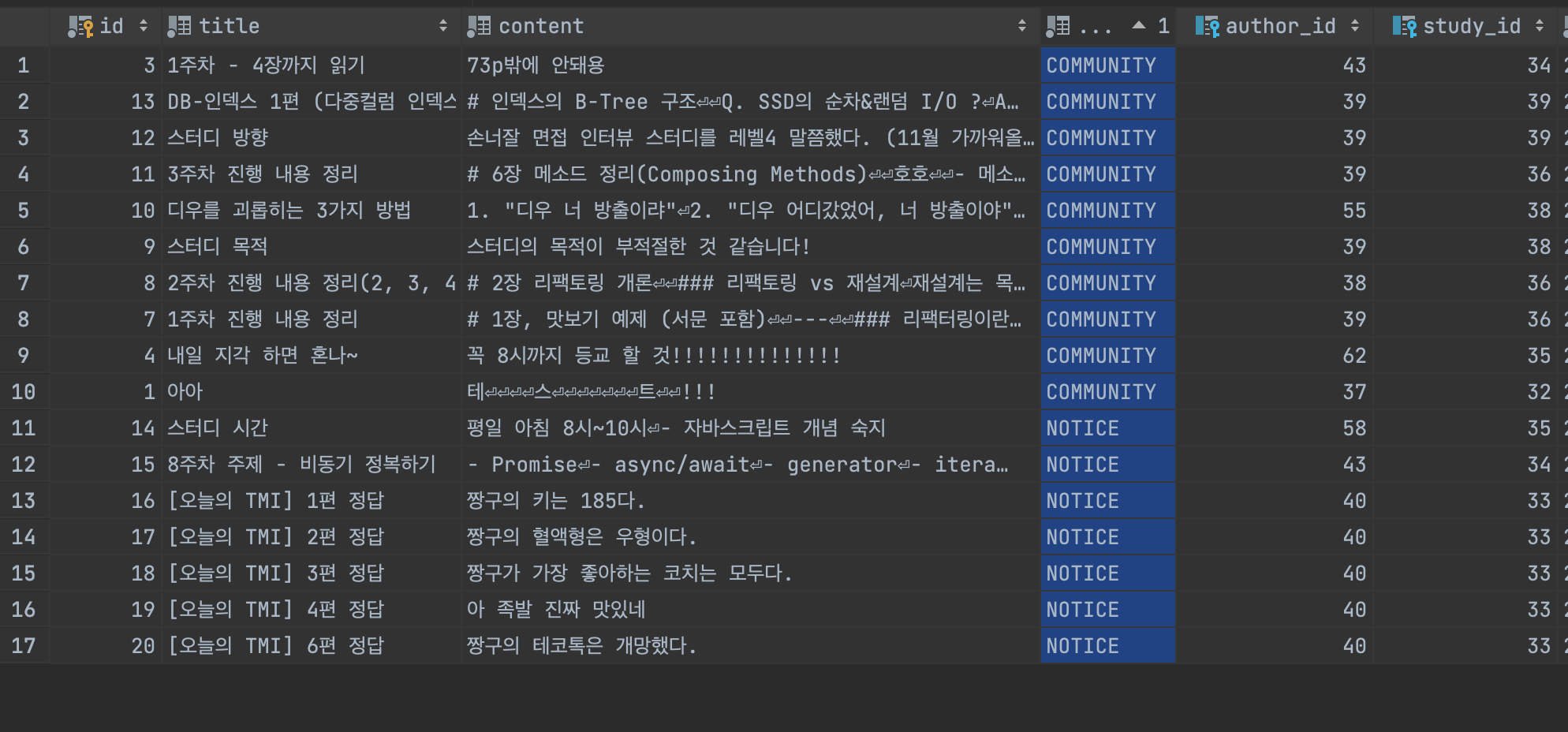
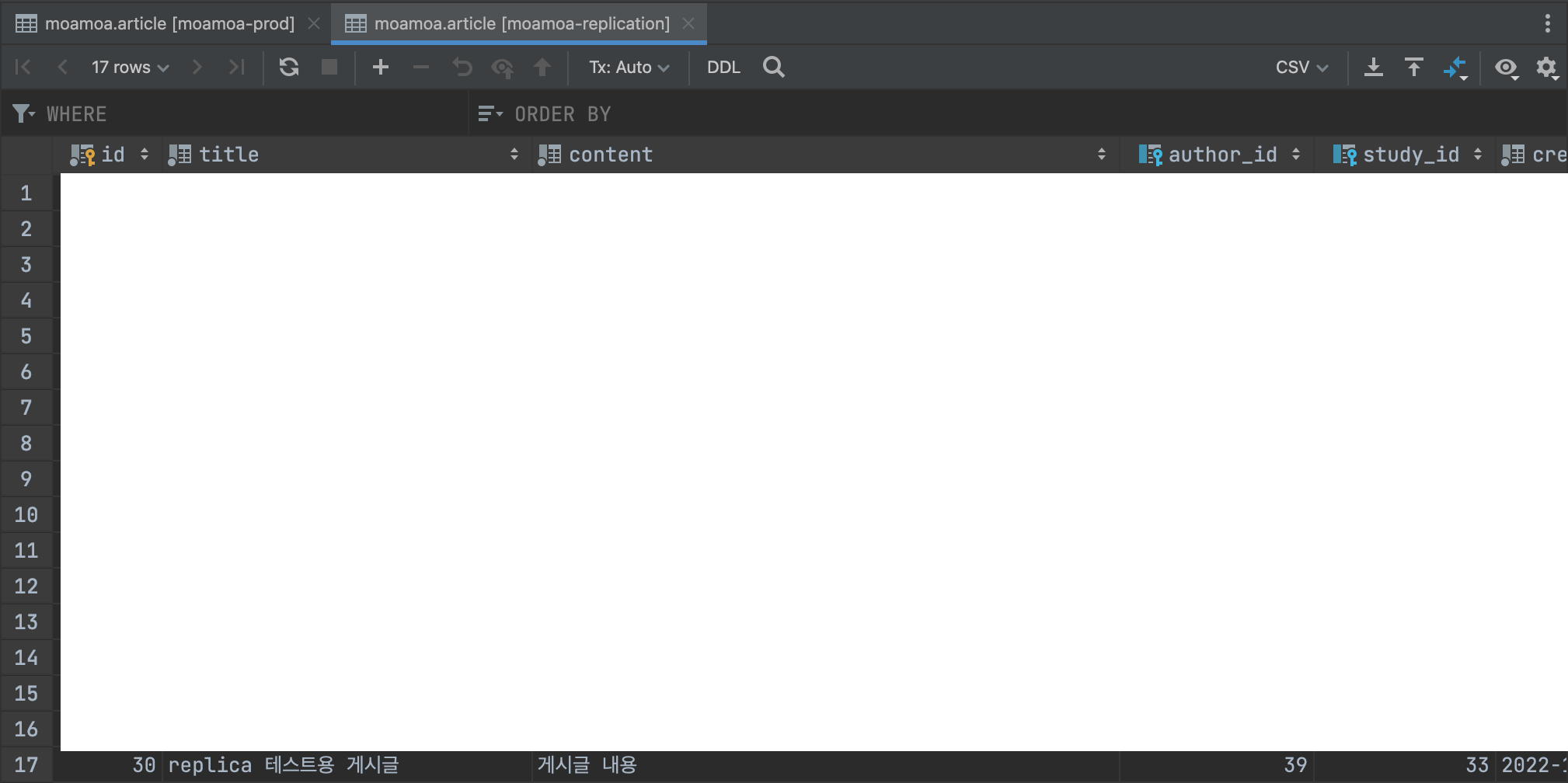
나는 최종적으로 제대로 복제가 이루어지는지를 눈으로 직접 확인해보았는데, 새로운 글을 테스트 용으로 다음과 같이 작성하였고
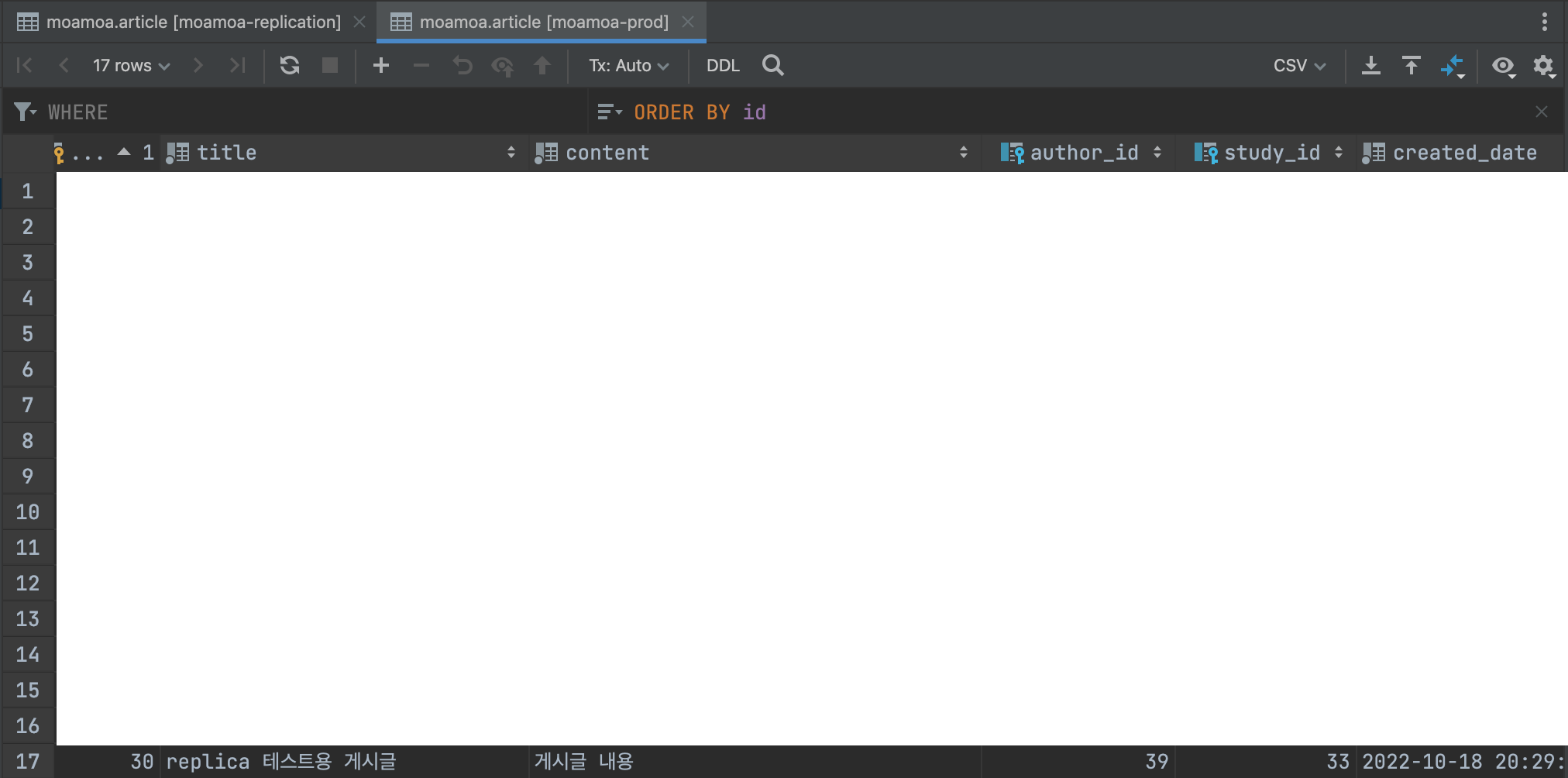
레플리카 서버에도 동일하게 데이터가 추가되어 있는지 즉 복제를 해서 동기화를 맞추고 잇는지를 다음과 같이 확인해보았다. (동일한 것을 확인한 것처럼 보이지만 스크린샷의 위의 tab을 보면 각각 moamoa-prod DB 서버와 moamoa-replication DB 서버임을 확인할 수 있다.)
추가적으로 레플리케이션 구성 이후에 임시 저장 에 대한 요구사항을 구현하면서 temp_article 이라는 테이블이 추가되었는데 위에 보여지는 것과 같은 DML 뿐만 아니라 DDL에 대해서도 동기화를 맞춰주고 있음을 아래와 같이 확인할 수 있다.